The Art of Unit Testing, Second Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Programmer's Guide to C
Download from Wow! eBook <www.wowebook.com> For your convenience Apress has placed some of the front matter material after the index. Please use the Bookmarks and Contents at a Glance links to access them. Contents at a Glance Preface ����������������������������������������������������������������������������������������������������������������������� xxv About the Author ����������������������������������������������������������������������������������������������������� xxvii About the Technical Reviewer ����������������������������������������������������������������������������������� xxix Acknowledgments ����������������������������������������������������������������������������������������������������� xxxi Introduction ������������������������������������������������������������������������������������������������������������� xxxiii ■■Chapter 1: C# and the .NET Runtime and Libraries �����������������������������������������������������1 ■■Chapter 2: C# QuickStart and Developing in C# ����������������������������������������������������������3 ■■Chapter 3: Classes 101 ����������������������������������������������������������������������������������������������11 ■■Chapter 4: Base Classes and Inheritance ������������������������������������������������������������������19 ■■Chapter 5: Exception Handling ����������������������������������������������������������������������������������33 ■■Chapter 6: Member Accessibility and Overloading ���������������������������������������������������47 ■■Chapter 7: Other Class Details �����������������������������������������������������������������������������������57 -

Solid Code Ebook
PUBLISHED BY Microsoft Press A Division of Microsoft Corporation One Microsoft Way Redmond, Washington 98052-6399 Copyright © 2009 by Donis Marshall and John Bruno All rights reserved. No part of the contents of this book may be reproduced or transmitted in any form or by any means without the written permission of the publisher. Library of Congress Control Number: 2008940526 Printed and bound in the United States of America. 1 2 3 4 5 6 7 8 9 QWT 4 3 2 1 0 9 Distributed in Canada by H.B. Fenn and Company Ltd. A CIP catalogue record for this book is available from the British Library. Microsoft Press books are available through booksellers and distributors worldwide. For further infor mation about international editions, contact your local Microsoft Corporation office or contact Microsoft Press International directly at fax (425) 936-7329. Visit our Web site at www.microsoft.com/mspress. Send comments to [email protected]. Microsoft, Microsoft Press, Active Desktop, Active Directory, Internet Explorer, SQL Server, Win32, Windows, Windows NT, Windows PowerShell, Windows Server, and Windows Vista are either registered trademarks or trademarks of the Microsoft group of companies. Other product and company names mentioned herein may be the trademarks of their respective owners. The example companies, organizations, products, domain names, e-mail addresses, logos, people, places, and events depicted herein are fictitious. No association with any real company, organization, product, domain name, e-mail address, logo, person, place, or event is intended or should be inferred. This book expresses the author’s views and opinions. The information contained in this book is provided without any express, statutory, or implied warranties. -

Licensing Information User Manual Release 9.1 F13415-01
Oracle® Hospitality Cruise Fleet Management Licensing Information User Manual Release 9.1 F13415-01 August 2019 LICENSING INFORMATION USER MANUAL Oracle® Hospitality Fleet Management Licensing Information User Manual Version 9.1 Copyright © 2004, 2019, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error- free. If you find any errors, please report them to us in writing. If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -
Create Mobile Apps with HTML5, Javascript and Visual Studio
Create mobile apps with HTML5, JavaScript and Visual Studio DevExtreme Mobile is a single page application (SPA) framework for your next Windows Phone, iOS and Android application, ready for online publication or packaged as a store-ready native app using Apache Cordova (PhoneGap). With DevExtreme, you can target today’s most popular mobile devices with a single codebase and create interactive solutions that will amaze. Get started today… ・ Leverage your existing Visual Studio expertise. ・ Build a real app, not just a web page. ・ Deliver a native UI and experience on all supported devices. ・ Use over 30 built-in touch optimized widgets. Learn more and download your free trial devexpress.com/mobile All trademarks or registered trademarks are property of their respective owners. Untitled-4 1 10/2/13 11:58 AM APPLICATIONS & DEVELOPMENT SPECIAL GOVERNMENT ISSUE INSIDE Choose a Cloud Network for Government-Compliant magazine Applications Geo-Visualization of SPECIAL GOVERNMENT ISSUE & DEVELOPMENT SPECIAL GOVERNMENT ISSUE APPLICATIONS Government Data Sources Harness Open Data with CKAN, OData and Windows Azure Engage Communities with Open311 THE DIGITAL GOVERNMENT ISSUE Inside the tools, technologies and APIs that are changing the way government interacts with citizens. PLUS SPECIAL GOVERNMENT ISSUE APPLICATIONS & DEVELOPMENT SPECIAL GOVERNMENT ISSUE & DEVELOPMENT SPECIAL GOVERNMENT ISSUE APPLICATIONS Enhance Services with Windows Phone 8 Wallet and NFC Leverage Web Assets as Data Sources for Apps APPLICATIONS & DEVELOPMENT SPECIAL GOVERNMENT ISSUE ISSUE GOVERNMENT SPECIAL DEVELOPMENT & APPLICATIONS Untitled-1 1 10/4/13 11:40 AM CONTENTS OCTOBER 2013/SPECIAL GOVERNMENT ISSUE OCTOBER 2013/SPECIAL GOVERNMENT ISSUE magazine FEATURES MOHAMMAD AL-SABT Editorial Director/[email protected] Geo-Visualization of Government KENT SHARKEY Site Manager Data Sources MICHAEL DESMOND Editor in Chief/[email protected] Malcolm Hyson .......................................... -

Automatic Refactoring of Large Codebases
Masaryk University Faculty of Informatics Automatic Refactoring of Large Codebases Master’s Thesis Bc. Matúš Pietrzyk Brno, Fall 2015 Replace this page with a copy of the official signed thesis assignment and the copy of the Statement of an Author. Declaration Hereby I declare that this paper is my original authorial work, which I have worked out by my own. All sources, references and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Bc. Matúš Pietrzyk Advisor: Bruno Rossi, PhD i Acknowledgement I would like to thank my supervisor Bruno Rossi, PhD for his contin- uous feedback and support during the writing of this thesis. I would also like to thank Viktor Jablonský from FNZ for his support during practical part of the thesis. ii Abstract The aim of this thesis is to investigate different techniques for code refactoring using semi-automatic and automatic refactoring tools. The practical part focuses on providing automatic refactoring support for legacy source code using Roslyn compiler. iii Keywords Refactoring, Roslyn, Compiler, Code Smells, Legacy Code, SOLID, Design Smells, Large Codebase iv Contents 1 Introduction ............................1 1.1 Thesis Structure ........................1 2 Issue Description .........................2 2.1 About FNZ ..........................2 2.2 Current State of the Codebase .................2 3 Refactoring ............................4 3.1 Key Advantages of Refactoring ................5 3.2 Refactoring Strategies .....................6 3.3 Design Smells .........................7 3.3.1 Rigidity . .8 3.3.2 Fragility . .8 3.3.3 Immobility . .8 3.3.4 Viscosity . .8 3.3.5 Needless Complexity . -

Adding Self-Healing Capabilities to the Common Language Runtime
Adding Self-healing capabilities to the Common Language Runtime Rean Griffith Gail Kaiser Columbia University Columbia University [email protected] [email protected] Abstract systems can leverage to maintain high system availability is to perform repairs in a degraded mode of operation[23, 10]. Self-healing systems require that repair mechanisms are Conceptually, a self-managing system is composed of available to resolve problems that arise while the system ex- four (4) key capabilities [12]; Monitoring to collect data ecutes. Managed execution environments such as the Com- about its execution and operating environment, performing mon Language Runtime (CLR) and Java Virtual Machine Analysis over the data collected from monitoring, Planning (JVM) provide a number of application services (applica- an appropriate course of action and Executing the plan. tion isolation, security sandboxing, garbage collection and Each of the four functions participating in the Monitor- structured exception handling) which are geared primar- Analyze-Plan-Execute (MAPE) loop consumes and pro- ily at making managed applications more robust. How- duces knowledgewhich is integral to the correct functioning ever, none of these services directly enables applications of the system. Over its execution lifetime the system builds to perform repairs or consistency checks of their compo- and refines a knowledge-base of its behavior and environ- nents. From a design and implementation standpoint, the ment. Information in the knowledge-base could include preferred way to enable repair in a self-healing system is patterns of resource utilization and a “scorecard” tracking to use an externalized repair/adaptation architecture rather the success of applying specific repair actions to detected or than hardwiring adaptation logic inside the system where it predicted problems. -

Getting Started with Testcomplete 7
* Windows and the Windows logo are trademarks of the Microsoft group of companies. 2 Table of Contents Table of Contents INTRODUCING AUTOMATED TESTING AND TESTCOMPLETE .....................................................3 Automated Testing......................................................................................................................................3 Test Types ...................................................................................................................................................3 TestComplete Projects and Project Items...................................................................................................4 TestComplete User Interface......................................................................................................................5 TestComplete Test Object Model................................................................................................................6 Checkpoints and Stores ..............................................................................................................................8 CREATING YOUR FIRST TEST..................................................................................................................9 1. Creating a Test Project.........................................................................................................................10 2. Defining Applications to Test ...............................................................................................................11 3. Planning -

Visual Studio 2010 Tools for Sharepoint Development
Visual Studio 2010 for SharePoint Open XML and Content Controls COLUMNS Toolbox Visual Studio 2010 Tools for User Interfaces, Podcasts, Object-Relational Mappings SharePoint Development and More Steve Fox page 44 Scott Mitchell page 9 CLR Inside Out Profi ling the .NET Garbage- Collected Heap Subramanian Ramaswamy & Vance Morrison page 13 Event Tracing Event Tracing for Windows Basic Instincts Collection and Array Initializers in Visual Basic 2010 Generating Documents from SharePoint Using Open XML Adrian Spotty Bowles page 20 Content Controls Data Points Eric White page 52 Data Validation with Silverlight 3 and the DataForm John Papa page 30 Cutting Edge Data Binding in ASP.NET AJAX 4.0 Dino Esposito page 36 Patterns in Practice Functional Programming Core Instrumentation Events in Windows 7, Part 2 for Everyday .NET Developers MSDN Magazine Dr. Insung Park & Alex Bendetov page 60 Jeremy Miller page 68 Service Station Building RESTful Clients THIS MONTH at msdn.microsoft.com/magazine: Jon Flanders page 76 CONTRACT-FIRST WEB SERVICES: Schema-Based Development Foundations with Windows Communication Foundation Routers in the Service Bus Christian Weyer & Buddihke de Silva Juval Lowy page 82 TEST RUN: Partial Anitrandom String Testing Concurrent Affairs James McCaffrey Four Ways to Use the Concurrency TEAM SYSTEM: Customizing Work Items Runtime in Your C++ Projects Rick Molloy page 90 OCTOBER Brian A. Randell USABILITY IN PRACTICE: Getting Inside Your Users’ Heads 2009 Charles B. Kreitzberg & Ambrose Little Vol 24 No 10 Vol OCTOBER 2009 VOL 24 NO 10 OCTOBER 2009 VOLUME 24 NUMBER 10 LUCINDA ROWLEY Director EDITORIAL: [email protected] HOWARD DIERKING Editor-in-Chief WEB SITE MICHAEL RICHTER Webmaster CONTRIBUTING EDITORS Don Box, Keith Brown, Dino Esposito, Juval Lowy, Dr. -

Test-Driving ASP.NET MVC Dino Esposito, Page 6 Keith Burnell
Untitled-10 1 6/6/12 11:32 AM THE MICROSOFT JOURNAL FOR DEVELOPERS JULY 2012 VOL 27 NO 7 Pragmatic Tips for Building Better COLUMNS Windows Phone Apps CUTTING EDGE Andrew Byrne .......................................................................... 24 Mobile Site Development, Part 2: Design Test-Driving ASP.NET MVC Dino Esposito, page 6 Keith Burnell ............................................................................ 36 DATA POINTS Create and Consume Writing a Compass Application JSON-Formatted OData for Windows Phone Julie Lerman, page 10 Donn Morse ............................................................................ 48 FORECAST: CLOUDY Mixing Node.js into Your Hadoop on Windows Azure Windows Azure Solution Joseph Fultz, page 16 Lynn Langit .............................................................................. 54 TEST RUN How to Handle Relational Data Classifi cation and Prediction Using Neural Networks in a Distributed Cache James McCaffrey, page 74 Iqbal Khan ............................................................................... 60 THE WORKING A Smart Thermostat on the Service Bus PROGRAMMER The Science of Computers Clemens Vasters ....................................................................... 66 Ted Neward and Joe Hummel, page 80 TOUCH AND GO Windows Phone Motion and 3D Views Charles Petzold, page 84 DON’T GET ME STARTED The Patient Knows What’s Wrong With Him David Platt, page 88 Start a Revolution Refuse to choose between desktop and mobile. With the brand new NetAdvantage for .NET, you can create awesome apps with killer data visualization today, on any platform or device. Get your free, fully supported trial today! www.infragistics.com/NET Infragistics Sales US 800 231 8588 • Europe +44 (0) 800 298 9055 • India +91 80 4151 8042 • APAC (+61) 3 9982 4545 Copyright 1996-2012 Infragistics, Inc. All rights reserved. Infragistics and NetAdvantage are registered trademarks of Infragistics, Inc. The Infragistics logo is a trademark of Infragistics, Inc. -

Buyers Guide Product Listings
BUYERS GUIDE PRODUCT LISTINGS Visual Studio Magazine Buyers’ Guide Product Listings The 2009 Visual Studio Magazine Buyers’ Guide listings comprise more than 700 individual products and services, ranging from developer tooling and UI components to Web hosting and instructor-led training. Included for each product is contact and pricing information. Keep in mind that many products come in multiple SKUs and with varied license options, so it’s always a good idea to contact vendors directly for specific pricing. The developer tools arena is a vast and growing space. As such, we’re always on the prowl for new tools and vendors. Know of a product our readers might want to learn more about? E-mail us at [email protected]. BUG & FEATURE TRACKING Gemini—CounterSoft Starts at $1189 • countersoft.com • +44 (0)1753 824000 Rational ClearQuest—IBM Rational Software $1,810 • ibm.com/rational • 888-426-3774 IssueNet Intercept—Elsinore Technologies Call for price • elsitech.com • 866-866-0034 FogBugz 7.0—Fog Creek Software $199 • fogcreek.com • 888-364-2849; 212-279-2076 SilkPerformer—Borland Call for price • borland.com • 800-632-2864; 512-340-2200 OnTime 2009 Professional—Axosoft Starts at $795 for five users • axosoft.com • 800-653-0024; SourceOffSite 4.2—SourceGear 480-362-1900 $239 • sourcegear.com • 217-356-0105 Alexsys Team 2.10—Alexsys Surround SCM 2009—Seapine Software Starts at $145 • alexcorp.com • 888-880-2539; 781-279-0170 Call for price • seapine.com • 888-683-6456; 513-754-1655 AppLife DNA—Kinetic Jump Software TeamInspector—Borland -

Proceedings of Hotos IX: the 9Th Workshop on Hot Topics in Operating Systems
USENIX Association Proceedings of HotOS IX: The 9th Workshop on Hot Topics in Operating Systems Lihue, Hawaii, USA May 18–21, 2003 THE ADVANCED COMPUTING SYSTEMS ASSOCIATION © 2003 by The USENIX Association All Rights Reserved For more information about the USENIX Association: Phone: 1 510 528 8649 FAX: 1 510 548 5738 Email: [email protected] WWW: http://www.usenix.org Rights to individual papers remain with the author or the author's employer. Permission is granted for noncommercial reproduction of the work for educational or research purposes. This copyright notice must be included in the reproduced paper. USENIX acknowledges all trademarks herein. Magpie: online modelling and performance-aware systems Paul Barham, Rebecca Isaacs, Richard Mortier, and Dushyanth Narayanan Microsoft Research Ltd., Cambridge, UK. Abstract A B Understanding the performance of distributed systems requires correlation of thousands of interactions be- Event Tracing Event Tracing tween numerous components — a task best left to a com- puter. Today’s systems provide voluminous traces from each component but do not synthesise the data into con- cise models of system performance. Models Models Performance We argue that online performance modelling should be Queries Query Engine a ubiquitous operating system service and outline sev- The diagram shows how requests move through different soft- eral uses including performance debugging, capacity ware components across multiple machines in a distributed sys- tem. Magpie synthesizes event traces from each machine into planning, system tuning and anomaly detection. We de- models that can be queried programatically. scribe the Magpie modelling service which collates de- tailed traces from multiple machines in an e-commerce Figure 1. -
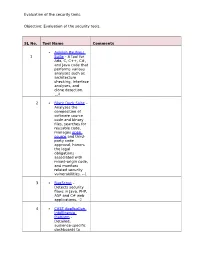
Evaluation of the Security Tools. SL No. Tool Name Comments 1
Evaluation of the security tools. Objective: Evaluation of the security tools. SL No. Tool Name Comments Axivion Bauhaus 1 Suite – A tool for Ada, C, C++, C#, and Java code that performs various analyses such as architecture checking, interface analyses, and clone detection. 4 2 Black Duck Suite – Analyzes the composition of software source code and binary files, searches for reusable code, manages open source and third- party code approval, honors the legal obligations associated with mixed-origin code, and monitors related security vulnerabilities. --1 3 BugScout – Detects security flaws in Java, PHP, ASP and C# web applications. -2 4 CAST Application Intelligence Platform – Detailed, audience-specific dashboards to Evaluation of the security tools. measure quality and productivity. 30+ languages, C, C++, Java, .NET, Oracle, PeopleSoft, SAP, Siebel, Spring, Struts, Hibernate and all major databases. 5 ChecKing – Integrated software quality portal that helps manage the quality of all phases of software development. It includes static code analyzers for Java, JSP, Javascript, HTML, XML, .NET (C#, ASP.NET, VB.NET, etc.), PL/SQL, embedded SQL, SAP ABAP IV, Natural/Adabas, C, C++, Cobol, JCL, and PowerBuilder. 6 ConQAT – Continuous quality assessment toolkit that allows flexible configuration of quality analyses (architecture conformance, clone detection, quality metrics, etc.) and dashboards. Supports Java, C#, C++, JavaScript, ABAP, Ada and many other languages. Evaluation of the security tools. 7 Coverity SAVE – A static code analysis tool for C, C++, C# and Java source code. Coverity commercialized a research tool for finding bugs through static analysis, the Stanford Checker, which used abstract interpretation to identify defects in source code.