Posh: a Data-Aware Shell
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Assignment of Master's Thesis
ASSIGNMENT OF MASTER’S THESIS Title: WebAssembly Approach to Client-side Web Development using Blazor Framework Student: Bc. Matěj Lang Supervisor: Ing. Marek Skotnica Study Programme: Informatics Study Branch: Web and Software Engineering Department: Department of Software Engineering Validity: Until the end of summer semester 2019/20 Instructions The majority of applications we use every day shifted from the desktop to the web. And with this transition, there was an explosion of approaches to the client-side development. The most recent advancement is a WebAssembly technology which allows executing low-level code in a web browser. A goal of this thesis is to create a proof-of-concept application using this technology and evaluate its strengths and weaknesses. Steps to take: Review the WebAssembly technology and the Blazor framework. Compare Blazor to the state-of-the-art client-side web development approaches. Design and create a proof-of-concept application in Blazor. Evaluate Blazor's strengths and weaknesses and its readiness to develop modern web applications. References Will be provided by the supervisor. Ing. Michal Valenta, Ph.D. doc. RNDr. Ing. Marcel Jiřina, Ph.D. Head of Department Dean Prague December 10, 2018 Czech Technical University in Prague Faculty of Information Technology Department of Web and Software Engineer- ing Master's thesis WebAssembly Approach to Client-side Web Development using Blazor Framework Bc. MatˇejLang Supervisor: Ing. Marek Skotnica 7th May 2019 Acknowledgements In this place I want to thank Bc. Katerina Cern´ıkov´aandˇ Mgr. Jakub Klement for language corrections. I want to thank my master thesis supervisor - Ing. Marek Skotnica for his patience and advice. -

Typescript-Handbook.Pdf
This copy of the TypeScript handbook was created on Monday, September 27, 2021 against commit 519269 with TypeScript 4.4. Table of Contents The TypeScript Handbook Your first step to learn TypeScript The Basics Step one in learning TypeScript: The basic types. Everyday Types The language primitives. Understand how TypeScript uses JavaScript knowledge Narrowing to reduce the amount of type syntax in your projects. More on Functions Learn about how Functions work in TypeScript. How TypeScript describes the shapes of JavaScript Object Types objects. An overview of the ways in which you can create more Creating Types from Types types from existing types. Generics Types which take parameters Keyof Type Operator Using the keyof operator in type contexts. Typeof Type Operator Using the typeof operator in type contexts. Indexed Access Types Using Type['a'] syntax to access a subset of a type. Create types which act like if statements in the type Conditional Types system. Mapped Types Generating types by re-using an existing type. Generating mapping types which change properties via Template Literal Types template literal strings. Classes How classes work in TypeScript How JavaScript handles communicating across file Modules boundaries. The TypeScript Handbook About this Handbook Over 20 years after its introduction to the programming community, JavaScript is now one of the most widespread cross-platform languages ever created. Starting as a small scripting language for adding trivial interactivity to webpages, JavaScript has grown to be a language of choice for both frontend and backend applications of every size. While the size, scope, and complexity of programs written in JavaScript has grown exponentially, the ability of the JavaScript language to express the relationships between different units of code has not. -

The Journey of Visual Studio Code
The Journey of Visual Studio Code Erich Gamma Envision new paradigms for online developer tooling that will be as successful as the IDE has been for the desktop 2012 2011 Eat your own dogfood hp 2011 2012 2012 2013 Meanwhile Microso; Changes Run on Windows Run everywhere Edit in Visual Studio Use your favorite editor Black box compilers Open Language Service APIs Proprietary Open Source Hacker News: Microso “Hit List” h@ps://hn.algolia.com/?query=MicrosoH Pivot or Persevere? Visual Studio A tool that combines the simplicity of a code editor withCode what developers need for the core code-build-debug-commit cycle editor IDE lightweight/fast project systems keyboard centered code understanding file/folders debug many languages integrated build many workflows File>New, wizards designers lightweight/fast ALM integraon file/folders with project conteXt plaorm tools many languages ... keyboard centered code understanding debug task running Inside Visual Studio Code – OSS in AcGon Electron, Node TypeScript Monaco Editor It’s fun to program in JavaScript Compensating patterns for classes, modules and namespaces. Refactoring JavaScript code is difficult! Code becomes read only Defining and documentation of APIs is difficult. Type information in comments are not checked TypeScript OpVonal stac types – be@er tooling: IntelliSense, Refactoring Be@er APIs docs More safety delete this.markers[range.statMarkerId]; // startMarkerId Use features from the future (ES6, ES7) today Growing the Code VS Code Preview – April 2015 Extensions Eclipse Everything is… -

Static Typescript
1 Static TypeScript 56 2 57 3 An Implementation of a Static Compiler for the TypeScript Language 58 4 59 5 60 6 Thomas Ball Peli de Halleux Michał Moskal 61 7 Microsoft Research Microsoft Research Microsoft Research 62 8 Redmond, WA, United States Redmond, WA, United States Redmond, WA, United States 63 9 [email protected] [email protected] [email protected] 64 10 Abstract 65 11 66 12 While the programming of microcontroller-based embed- 67 13 dable devices typically is the realm of the C language, such 68 14 devices are now finding their way into the classroom forCS 69 15 education, even at the level of middle school. As a result, the 70 16 use of scripting languages (such as JavaScript and Python) 71 17 for microcontrollers is on the rise. 72 18 We present Static TypeScript (STS), a subset of TypeScript (a) (b) 73 19 (itself, a gradually typed superset of JavaScript), and its com- 74 20 piler/linker toolchain, which is implemented fully in Type- Figure 1. Two Cortex-M0 microcontroller-based educational 75 21 Script and runs in the web browser. STS is designed to be use- devices: (a) the BBC micro:bit has a Nordic nRF51822 MCU 76 22 ful in practice (especially in education), while being amenable with 16 kB RAM and 256 kB flash; (b) Adafruit’s Circuit Play- 77 23 to static compilation targeting small devices. A user’s STS ground Express (https://adafruit.com/products/3333) has an 78 24 program is compiled to machine code in the browser and Atmel SAMD21 MCU with 32 kB RAM and 256 kB flash. -

Profile Stavros Mavrokefalidis
Profile Stavros Mavrokefalidis Software Development and Consulting Microsoft .NET teamstep GmbH Frankenstraße 14, 46487 Wesel (DE) Tel.: +49 2859 9098809 Fax: +49 2859 901458 Mobile: +49 151 14934862 www.teamstep-gmbh.de [email protected] Date of Birth: 01/03/1971 Place of Birth: Thessaloniki / Greece Marital Status: Married, one son Languages: German & Greek (fluent), English (good) IT-Experience: 21 Years Rate: negotiable Focus • Software design and development with Microsoft Technologies • Visual Studio, Azure DevOps, TFS, Git, SQL-Server • Object-oriented analysis and design • N-Tier and Client/Server, Microservices • SCRUM and Waterfall based methodologies • Development of requirements, estimates, functional and technical specifications. Technological Environment • .NET, C# • ASP.NET / .Net Core, WPF, MVC, WebAPI, WCF, IIS • Entity Framework, ADO.NET, LINQ, XML, JSON • HTML5, JavaScript, CSS, Angular, TypeScript, jQuery, AngularJS • GUI technologies (ASP.NET, Angular, .Net Core, Windows Forms, WPF, Silverlight) • MS SQL Server • UML, OOA, OOD, Design Patterns, MVC, MVVM Certificates • MCPD Microsoft Certified Professional Developer - Web Development o Exam 70-513: Windows Communication Foundation Development with Microsoft .Net Framework 4 o Exam 70-516: Accessing Data with Microsoft .Net Framework 4 o Exam 70-515: Web Applications Development with Microsoft .NET Framework 4 o Exam 70-519: Designing and Developing Web Applications Using Microsoft .NET Framework 4 • Exam 70-480: Programming in HTML5 with JavaScript and CSS3 Project History Consumer industry Extension of the project management software INVEST 3 months Development and extension of an existing internal application for planning of project budgets and management investment. 01/07/2020 – 18/09/2020 • Partial UI modernization of the web frontend based on bootstrap 4 • Extension of project management with planning functionality. -

Concrete Types for Typescript
Concrete Types for TypeScript Gregor Richards1, Francesco Zappa Nardelli2, and Jan Vitek3 1 University of Waterloo 2 Inria 3 Northeastern University Abstract TypeScript extends JavaScript with optional type annotations that are, by design, unsound and, that the TypeScript compiler discards as it emits code. This design point preserves programming idioms developers are familiar with, and allows them to leave their legacy code unchanged, while offering a measure of static error checking in annotated parts of the program. We present an alternative design for TypeScript that supports the same degree of dynamism but that also allows types to be strengthened to provide correctness guarantees. We report on an implementation, called StrongScript, that improves runtime performance of typed programs when run on a modified version of the V8 JavaScript engine. 1998 ACM Subject Classification F.3.3 Type structure Keywords and phrases Gradual typing, dynamic languages Digital Object Identifier 10.4230/LIPIcs.ECOOP.2015.999 1 Introduction Perhaps surprisingly, a number of modern computer programming languages have been de- signed with intentionally unsound type systems. Unsoundness arises for pragmatic reasons, for instance, Java has a covariant array subtype rule designed to allow for a single polymor- phic sort() implementation. More recently, industrial extensions to dynamic languages, such as Hack, Dart and TypeScript, have featured optional type systems [5] geared to ac- commodate dynamic programming idioms and preserve the behavior of legacy code. Type annotations are second class citizens intended to provide machine-checked documentation, and only slightly reduce the testing burden. Unsoundness, here, means that a variable an- notated with some type T may, at runtime, hold a value of a type that is not a subtype of T due to unchecked casts, covariant subtyping, and untyped code. -

Building Next Generation Apps with Typescript
Building Next Generation Apps with TypeScript Rachel Appel Appel Consulting http://RachelAppel.com http://Twitter.com/RachelAppel http://Linkedin.com/rachelappel Agenda • TypeScript Intro • Tools • Compilation • Types • Classes • Inheritance • Debugging • Web and Apps Get TypeScript http://www.typescriptlang.org TypeScript in the Wild • Bing • Monaco TypeScript Features Superset of ES5 / ES6 JavaScript Visual Studio Type Checking Webstorm Browser tools Syntactic Next-gen Sugar JavaScript for the enterprise Generics & Arrow Classes Functions Dot notation for properties Why use TypeScript? More and more server side JavaScript was logic using JavaScript SPA App designed for a (Node.JS) model sapling DOM tree JavaScript apps are becoming C# coders forced into quite complex OOP is easier JavaScript http://www.typescriptlang.org/playground Web/HTML/ASP.NET Visual Studio Windows Store JavaScript Program organizationProgram Module Module Class Class Method Members Property Class Members Class Class Members Members DEMO • TypeScript programs in Visual Studio TypeScript Compilation TypeScript .ts Compiler JavaScript .js TypeScript compilation Types • Primitive and Object • Any • Number • Boolean • String • Null * • Undefined * • Object • Void * • HTMLElement • Functions • Enum Type annotations • Argument types • Return types • Type inference DEMO • Types and annotations Classes TS JS Classes: Constructors TS JS Classes: Members TS JS Enums Classes: Access modifiers Accessing a Class and its members DEMO • Creating and using a class Inheritance TS JS DEMO • Inheritance Debugging TypeScript DEMO • Debugging Web and Apps • HTML • ASP.NET WebForms and ASP.NET MVC • Windows Store JavaScript apps http://bit.ly/15iOfFt Thank You! Rachel Appel [email protected] http://RachelAppel.com http://Twitter.com/RachelAppel http://LinkedIn.com/RachelAppel http://bit.ly/RachNOW Use code APPEL-13 for a 14 day free trial! . -
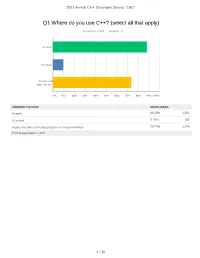
Q1 Where Do You Use C++? (Select All That Apply)
2021 Annual C++ Developer Survey "Lite" Q1 Where do you use C++? (select all that apply) Answered: 1,870 Skipped: 3 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 88.29% 1,651 At school 9.79% 183 In personal time, for hobby projects or to try new things 73.74% 1,379 Total Respondents: 1,870 1 / 35 2021 Annual C++ Developer Survey "Lite" Q2 How many years of programming experience do you have in C++ specifically? Answered: 1,869 Skipped: 4 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 7.60% 142 3-5 years 20.60% 385 6-10 years 20.71% 387 10-20 years 30.02% 561 >20 years 21.08% 394 TOTAL 1,869 2 / 35 2021 Annual C++ Developer Survey "Lite" Q3 How many years of programming experience do you have overall (all languages)? Answered: 1,865 Skipped: 8 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 1.02% 19 3-5 years 12.17% 227 6-10 years 22.68% 423 10-20 years 29.71% 554 >20 years 34.42% 642 TOTAL 1,865 3 / 35 2021 Annual C++ Developer Survey "Lite" Q4 What types of projects do you work on? (select all that apply) Answered: 1,861 Skipped: 12 Gaming (e.g., console and.. -
Powerapps Component Framework ● Developers Were Getting Bored ● Makers Were Getting Bored ● Everyone Was Asking for Microsoft to Come up with Something Cool ● And
PowerApps component framework ● Developers were getting bored ● Makers were getting bored ● Everyone was asking for Microsoft to come up with something cool ● And... PowerApps component framework has come! About myself Name: Alex Shlega Title: Dynamics 365 Consultant/Developer/Solution Architect Blog: https://www.itaintboring.com Linkedin: https://www.linkedin.com/in/alexandershlega/ Twitter: https://twitter.com/ashlega https://powerapps.microsoft.com/en-us/blog/announcing-the-general-availability-of-the-powerapps-component-framework-for-model- driven-applications-and-powerapps-cli/ Example: N:N in a TreeView ● Regular N:N ● Mapped to a TreeView ● All related records are still traceable through the N:N (Advanced Find, reporting, etc) Why PCF? ● Reusable & configurable (properties/values/configuration) ● Solution-Aware ● No iframes anymore, no additional form scripts to control the iframe, much less related “plumbing” ● Can be developed by developers and easily re-used by makers What’s involved Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine npm makes it easy for JavaScript developers to share and reuse code, and makes it easy to update the code that you’re sharing, so you can build amazing things. ● JavaScript ● JQuery ● Solutions ● React ● Angular It is a strict syntactical superset of JavaScript ● PowerShell that adds optional static typing to the language Limitations ● Components should bundle all code including external library content into the primary code bundle ● Sharing libraries across components using -

Pro Wpf in C# 2010: Windows Presentation Foundation in .Net 4 Pdf, Epub, Ebook
PRO WPF IN C# 2010: WINDOWS PRESENTATION FOUNDATION IN .NET 4 PDF, EPUB, EBOOK Matthew MacDonald | 1216 pages | 30 Apr 2010 | aPress | 9781430272052 | English | New York, United States Pro WPF in C# 2010: Windows Presentation Foundation in .Net 4 PDF Book Peter Seibel. Anirvan Chakraborty. Mark Pilgrim. The most complete book on WPF. These cookies are necessary to provide our site and services and therefore cannot be disabled. Follow us. To see what your friends thought of this book, please sign up. Harry Potter. Using Binding Mode as TwoWay, the object can be constructed and this object can be send back to the Data access using CommandParameter. Goodreads helps you keep track of books you want to read. Cookies are used to provide, analyse and improve our services; provide chat tools; and show you relevant content on advertising. C LINQ. In this article, we will explain this technique with an application. Add to basket. TypeScript Angular. Media is an important namespace in WPF. No trivia or quizzes yet. Documents Pages MacDonald, Matthew. More filters. We use cookies to improve this site Cookies are used to provide, analyse and improve our services; provide chat tools; and show you relevant content on advertising. Goodbye Xamarin. Friend Reviews. Return to Book Page. Forms, Hello. Multithreading Pages MacDonald, Matthew. Pro WPF in C# 2010: Windows Presentation Foundation in .Net 4 Writer Stockfish rated it it was amazing Mar 17, Rory Lewis. Read more Using WPF 4. Vlad Bezden rated it it was amazing Aug 15, In this article, we will explore these features. Abstract: In this article, I have described a scenario where a WPF application is trying to use the task parallel library to load data. -

Ink, Touch, and Windows Presentation Foundation
9/2/2015 Ink, Touch, and Windows Presentation Foundation Lecture #4: Ink and WPF Joseph J. LaViola Jr. Fall 2015 Fall 2015 CAP 6105 – Pen-Based User Interfaces ©Joseph J. LaViola Jr. From Last Time Windows Presentation Foundation (WPF) integration of Ink multi-touch 2D Graphics 3D Graphics video and audio uses visual tree model component based XAML and C# code Important control – InkCanvas Fall 2015 CAP 6105 – Pen-Based User Interfaces ©Joseph J. LaViola Jr. 1 9/2/2015 Ink Environment Choices Microsoft traditional dev stream: Visual Studio, C#, WPF or (Mono+Xamarin) Pros: Mature platform with many online resources Cons: Can be deployed only on Windows ecosystem Using Mono+Xamarin can be deployed cross-platform Microsoft new dev stream: Visual Studio, JavaScript(or Typescript),HTML Pros: Can be deployed cross-platform(windows, android or IOS) Cons: Relatively new computing environment with new API Other alternatives, such as Python/Kivy, IOS, Android. Pros: Open-source with many online collaboration. Cons: Have little support on inking Fall 2015 CAP 6105 – Pen-Based User Interfaces ©Joseph J. LaViola Jr. Traditional Ink and Touch Ink SDK Before Windows 8.1: The inking API is System.Windows.Ink Online Sample code: Adventures into Ink API using WPF After Windows 8.1: The inking API is Windows.UI.Input.Inking Online Sample code: Input:Simplied ink sample You can find more articles or sample code resources from Microsoft Windows Dev Center or Code project Fall 2015 CAP 6105 – Pen-Based User Interfaces ©Joseph J. LaViola Jr. 2 9/2/2015 Important Ink Components InkCanvas – System.Windows.Controls receives and displays ink strokes starting point for ink applications stores ink in Strokes System.Windows.Ink Namespace contains classes to interact with and manipulate ink examples Stroke GestureRecognizer InkAnalyzer now separate (only on 32 bit) needs IACore.dll, IAWinFX.dll and IALoader.dll Fall 2015 CAP 6105 – Pen-Based User Interfaces ©Joseph J. -

How F# Learned to Stop Worrying and Love the Data
How F# Learned to Stop Worrying and Love the Data Tomas Petricek @tomaspetricek Conspirator behind http://fsharp.org software stacks trainings teaching F# user groups snippets mac and linux cross-platform books and tutorials F# Software Foundation F# community open-source MonoDevelop http://www.fsharp.org contributions research support consultancy mailing list The Data let wb = WorldBank() w b . [DEMO] Exploring WorldBank Data Asynchronous programming Asynchrony matters Node.js and C# 5.0 F# Async workflows Without inversion of control Exception handling and loops simple Sequential and parallel composition F# to JavaScript [DEMO] WorldBank App for the Web F# to JavaScript TypeScript type provider Import types for JS libraries Somebody else writes them! Libraries & frameworks Open source: FunScript and Pit Commercial: IntelliFactory WebSharper Accessing REST services REST (Representational State Transfer) is a style of software architecture for distributed systems such as the World Wide Web. REST has emerged as a predominant Web service design model. Accessing REST services [DEMO] Introducing Apiary Type Provider Apiary.io Type Provider Common REST conventions GET /movie/{id} Get movie summary GET /movie/{id}/casts Get cast details Types from JSON samples { "page": 1, "total_pages": 1, "total_results": 5, "results": [ { "title": "Skyfall", "id": 94221 } ] } [DEMO] The Movie Database App for the Web Type Providers in Action WorldBank Type Provider JSON Type Provider Apiary Type Provider TypeScript Type Provider [SUMMARY] Where to learn more? Online resources www.fsharp.org Information & community www.tryfsharp.org Interactive F# tutorials User groups and trainings Functional and F# trainings In London and New York Get in touch [email protected] F#unctional Londoners meetup http://meetup.com/FSharpLondon/ F#, Data and Services web other languages tool support extensibility code-first type script Love the Data REST unstructured data static typing inference schema and integration R language transparent java script .