Arxiv:2004.10645V2 [Cs.CL] 5 Oct 2020 the Evidence in Wikipedia
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

TV/Series Lost: (Re)Garder L'île
TV/Series Lost: (re)garder l’île Guillaume Dulong To cite this version: Guillaume Dulong. TV/Series Lost: (re)garder l’île. TV/Series, GRIC - Groupe de recherche Identités et Cultures, 2016, 10.4000/tvseries.4371. hal-02901641 HAL Id: hal-02901641 https: //hal-u-bordeaux-montaigne.archives-ouvertes.fr/hal-02901641 Submitted on 17 Jul 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. TV/Series Hors séries 1 | 2016 Lost: (re)garder l'île The Leftovers, the Lost fever Double frénésie en séries pour Damon Lindelof Guillaume Dulong Édition électronique URL : http://journals.openedition.org/tvseries/4371 DOI : 10.4000/tvseries.4371 ISSN : 2266-0909 Éditeur GRIC - Groupe de recherche Identités et Cultures Référence électronique Guillaume Dulong, « The Leftovers, the Lost fever », TV/Series [En ligne], Hors séries 1 | 2016, mis en ligne le 30 juin 2020, consulté le 02 juillet 2020. URL : http://journals.openedition.org/tvseries/4371 ; DOI : https://doi.org/10.4000/tvseries.4371 Ce document a été généré automatiquement le 2 juillet 2020. TV/Series est mis à disposition selon les termes de la licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Pas de Modification 4.0 International. -

Daring Deceit
FINAL-1 Sun, Oct 25, 2015 11:52:55 PM tvupdateYour Weekly Guide to TV Entertainment For the week of November 1 - 7, 2015 Daring deceit Priyanka Chopra INSIDE stars in “Quantico” •Sports highlights Page 2 •TV Word Search Page 2 •Hollywood Q&A Page 3 •Family Favorites Page 4 The plot thickens as Alex Parrish (Priyanka Chopra, “Fashion,” 2008) struggles to prove she wasn’t behind a terrorist attack in New York City in a new episode of “Quantico,” airing Sunday, Nov. 1, on ABC. Flashbacks recount Parrish’s time at the FBI academy, where she trained alongside a diverse group of recruits. As the flashbacks unfold, it becomes clear that no one is what they seem, and everyone has something to hide. RICHARD’S New, Used&Vintage FURNITURE 0% Reclining SALE *Sofas *Love Seats *Sectionals *Chairs NO INTEREST ON LOANS *15% off Custom Orders Only! Group Page Shell Richards 5 x 3” at 1 x 3” CASH FOR GOLD Ends Nov14th Remember TRADE INS arewelcome 527 S. Broadway,Salem, NH www.richardsfurniture.com (On the Methuen Line above Enterprise Rent-A-Car) 25 WaterStreet 603-898-2580 •OPEN 7DAYSAWEEK Lawrence,MA WWW.CASHFORGOLDINC.COM 978-686-3903 FINAL-1 Sun, Oct 25, 2015 11:52:56 PM COMCAST ADELPHIA 2 Sports Highlights Kingston CHANNEL Atkinson Countdown to Green Live NESN Bruins Face-Off Live Sunday 8:00 p.m. (25) Baseball MLB World (7) Salem Londonderry Series Live (25) College Football Pre-game Live 7:00 p.m. ESPN Football NCAA Live Windham 9:00 a.m. (25) Fox NFL Sunday Live Sandown ESPN Basketball NBA New York Knicks ESPN College Football Scoreboard NESN Hockey NHL Boston Bruins at Pelham, 9:30 a.m. -

What to Watch
What MOVIES to watch YOU’LL LOVE SUNDAY All times Eastern. Start times can vary based on cable/satellite provider. Confi rm times on your on-screen guide. ‘Sixteen Candles’ NASCAR Cup Series: STEVE KAGAN Championship 4 Sixteen Candles (1984, Comedy) NBC, 3 p.m. Live Molly Ringwald, Anthony Michael ‘Moonbase 8’ Hall CMT, 6:30 p.m. The four remaining drivers eligible for the NASCAR Cup Series season championship A24 FILMS duke it out at Phoenix Raceway, with the best fi nisher among them claiming the title. Rady), who helps her heal and fi nd love during NCIS: Los Angeles the holidays. CBS, 8:30 p.m. Season Premiere CATCH The Simpsons In the Season 12 premiere episode “The By Whatever Means A CLASSIC FOX, 8 p.m. Bear,” a Russian bomber fl ying over the U.S. In the new episode “The 7 Beer Itch,” Homer goes missing, sending Sam (LL Cool J) and Necessary: The Times (voice of Dan Castellaneta) falls under the Callen (Chris O’Donnell) on a mission to track spell of a British femme fatale (guest voice of it down and secure its weapons and intel. of Godfather of Harlem EPIX, 10 p.m. New Docuseries Olivia Colman). Bob’s Burgers This four-part docuseries is inspired by the Christmas FOX, 9 p.m. music and subjects featured in Godfather of Harlem. It brings alive the dramatic true story With the Darlings Tina (voice of Dan Mintz) is put in charge of of Harlem and its music during the 1960s the Wagsta School time capsule project, Hallmark Channel, 8 p.m. -
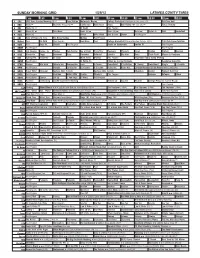
Sunday Morning Grid 1/29/12 Latimes.Com/Tv Times
SUNDAY MORNING GRID 1/29/12 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Morning (N) Å Face/Nation Motorcycle Racing College Basketball Michigan at Ohio State. (N) PGA Tour Golf 4 NBC News Å Meet the Press (N) Å Conference Wall Street House Bull Riding PBR Tour. (N) Å Figure Skating 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) Å News (N) Å News Å Vista L.A. NBA Basketball 9 KCAL News (N) Prince Mike Webb Joel Osteen Shook Paid Program 11 FOX Hour of Power (N) (TVG) Fox News Sunday Midday Paid Program 13 MyNet Paid Tm Wrld Paid Program Best Buys Paid College Basketball Miami at Boston College. (TVG) 700 Club Super Telethon 18 KSCI Paid Hope Hr. Church Paid Program Hecho en Guatemala Iranian TV Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Sid Science Curios -ity Thomas Bob Builder Joy of Paint Paint This Dewberry Wyland’s Sara’s Kitchen Kitchen Mexican 28 KCET Hands On Raggs Busytown Peep Pancakes Pufnstuf Lidsville Hey Kids Taste Chefs Field Moyers & Company 30 ION Turning Pnt. Discovery In Touch Mark Jeske Beyond Paid Program Inspiration Today Camp Meeting 34 KMEX Paid Program Al Punto (N) Fútbol de la Liga Mexicana República Deportiva 40 KTBN Rhema Win Walk Miracle-You Redemption Love In Touch PowerPoint It Is Written B. Conley From Heart King Is J. -

Annual Report 2014–2015 Contents
ANNUAL REPORT 2014–2015 CONTENTS MESSAGE FROM THE CEO & PRESIDENT 2 HIGHLIGHTS 2014–2015 FINANCIAL STATEMENTS 2014 2014 HIGHLIGHTS INDEPENDENT AUDITOR’S REPORT 6 42 2015 HIGHLIGHTS FINANCIAL STATEMENT 8 43 OUR WORK INVESTORS NEWS MEDIA MILLION DOLLAR LIFETIME CLUB 10 46 ENTERTAINMENT FOUNDATIONS 14 46 TH 25 ANNUAL GLAAD MEDIA AWARDS CORPORATE PARTNERS 17 47 26TH ANNUAL GLAAD MEDIA AWARDS LEGACY CIRCLE 21 48 TRANSGENDER MEDIA SHAREHOLDERS CIRCLE 25 49 GLOBAL VOICES 29 DIRECTORY SOUTHERN STORIES 32 GLAAD STAFF SPANISH-LANGUAGE & LATINO MEDIA 54 35 GLAAD NATIONAL YOUTH BOARD OF DIRECTORS 38 55 LEADERSHIP COUNCILS 55 My first year as GLAAD’s CEO & President was an unforgettable one as it was marked by significant accomplishments for the LGBT movement. Marriage equality is now the law of the land, the Boy Scouts ended its discriminatory ban based on sexual orientation, and an LGBT group marched in New York City’s St. Patrick’s Day Parade for the very first time. And as TIME noted, our nation has reached a “transgender tipping point.” Over 20 million people watched Caitlyn Jenner come out, and ABC looked to GLAAD as a valued resource for that game-changing interview. MESSAGE FROM THE CEO & PRESIDENT But even with these significant advancements, at GLAAD, we still see a dangerous gap between historic policy advancements and the hearts and minds of Americans—in other words, a gap between equality and acceptance. To better understand this disparity, GLAAD commissioned a Harris Poll to measure how Americans really feel about LGBT people. The results, released in our recent Accelerating Acceptance report, prove that beneath legislative progress lies a dangerous layer of discomfort and discrimination. -

Around $ 2 Medium 2-Topping Pizzas5 8” Individual $1-Topping99 Pizza 5And 16Each Oz
NEED A TRIM? AJW Landscaping 910-271-3777 September 8 - 14, 2018 Mowing – Edging – Pruning – Mulching Licensed – Insured – FREE Estimates 00941084 Carry Out ‘Kidding’ MANAGEr’s SPECIAL WEEKDAY SPECIAL around $ 2 MEDIUM 2-TOPPING Pizzas5 8” Individual $1-Topping99 Pizza 5and 16EACH oz. Beverage Jim Carrey stars (Additional toppings $1.40 each) in “Kidding” Monday Thru Friday from 11am - 4pm 1352 E Broad Ave. 1227 S Main St. Rockingham, NC 28379 Laurinburg, NC 28352 (910) 997-5696 (910) 276-6565 *Not valid with any other offers Joy Jacobs, Store Manager 234 E. Church Street Laurinburg, NC 910-277-8588 www.kimbrells.com Page 2 — Saturday, September 8, 2018 — Laurinburg Exchange Funny, not funny: Jim Carrey’s ‘Kidding’ mixes comedy and drama By Kyla Brewer ular television series role. At the to prepare the show to go on with- TV Media time of the announcement, Show- out him. At the same time, Deidre time executive David Nevins had grapples with her own challenging irst, there was Howdy Doody. high praise for the star. personal and professional issues. FThen came Captain Kangaroo, “No one inhabits a character like On the homefront, Jeff’s wife, Jill, the beloved Mr. Rogers and so on. Jim Carrey, and this role — which is has hit a rebellious streak. Cheerful, wise and kind, children’s like watching Humpty Dumpty after A show about a children’s enter- entertainers such as these have in- the fall — is going to leave televi- tainer is well timed, considering the spired generations of kids. A new sion audiences wondering how they current wave of Mr. -

'AVENGING ANGEL' CAST BIOS KEVIN SORBO (Preacher) – for Seven Years, Kevin Sorbo Played the Hulking, Heroic Lead in USA Ne
‘AVENGING ANGEL’ CAST BIOS KEVIN SORBO (Preacher) – For seven years, Kevin Sorbo played the hulking, heroic lead in USA Network’s “Hercules: The Legendary Journeys,” a role that made him a star. But the self-described jock from Minnetonka, Minnesota (the home of Tonka Toys), the fourth of five kids, got the acting bug at age 11 seeing something quite different – the musical “Oklahoma” and Shakespeare’s “The Merchant of Venice” at Minneapolis’s famed Guthrie Theater. Though he made his first commercial - for Target - while attending the University of Minnesota, Sorbo graduated from Moorehead State University in Fargo, North Dakota, with a dual degree in advertising and marketing. In 1982, after college, Kevin moved to Texas, where he began studying acting in earnest. A model friend there convinced him to travel to Europe, where he stayed for three years, building a tremendous commercial reel, with spots shot in cities from Milan and Munich to Paris and London. Within days of his return to the States in 1985, he shipped off to Australia for new commercial assignments, returning to L.A. six months later. Sorbo remained in demand through the early 90s, for both television and commercial work – he estimates appearing in 57 spots in the three years prior to being cast as Hercules. After appearing in such series as “Murder, She Wrote,” “Cheers” and “The Commish,” and after seven call backs with producer Sam Raimi, Kevin was given the role of Hercules. The character appeared first in a series of two hour movies as part of USA Network’s “The Action Pack,” alongside William Shatner’s “Tek Wars” and others – Hercules being the sole survivor of the group and landing its own series. -

The Inventory Ofthe Forest Whitaker Collection #1676
The Inventory ofthe Forest Whitaker Collection #1676 Howard Gotlieb Archival Research Center Whitaker, Forest #1676 10/7/08 Preliminary Listing I. Manuscripts. A. Scripts, TS screenplays unless noted. Box 1 1. "The Air I Breathe," by Jieho Lee and Bob de Rosa, 2 drafts, 115- 121 p., 8/8/05 - 12/29/05. [F. 1] 2. "American Gun," by Arie Avelino and Steven Bagatourian, 7 drafts, approx. 120 p. each, 1/14/08 - 6/29/04. [F. 2-8] 3. "Black Jab" (alternate title: "Mississippi Dawn"), by Alfred Gough, Miles Millar, and Dawnn Lewis, 3 drafts, 12/19/97, 3/30/98, 1/18/98, includes holograph notes. [F. 9-10] 4. "Door to Door," by William H. Macy and Steven Schachter, 104 p., 5/18/00. [F. 11] 5. "The Facts About Kate," by Lori Lakin, 5 drafts, approx. 120 p. each, 2/11/02 - 1/31/03. [F. 12-16] 6. "First Daughter," by Kate Kondell, 5 drafts, approx. 110 p., 4/1/02- 6/12/03. [F. 17-19] a. Mini-script, 103 p., 5/17/03. [E. 1] 7. "The Great Debaters," by Robert Eisele, 6 drafts, approx. 15-140 p., 5/1/07-5/14/07; includes holograph notes. [F. 20-24] Box2 a. Ibid. [F. 1] 8. "Hurricane Season," by Robert Eisele, 8 drafts, approx. 115 p. each, 2/14/08-June, 2008; includes holograph notes; correspondence. [F. 2-1 OJ a. 7 drafts, n.d. [F. 11-16] b. Text fragments with holograph notes, approx. 400 p. [F. 17-21] 9. "Last King of Scotland," by Peter Morgan, approx. -
After 79 Years, Peabody Vet Honored Swampscott Braces for Protest
THURSDAY, NOVEMBER 12, 2020 After 79 years, Swampscott Peabody vet braces for honored protest By Anne Marie Tobin ITEM STAFF By Guthrie Scrimgeour ITEM STAFF PEABODY — The city of Peabody has always SWAMPSCOTT — A statement released by taken a great deal of pride in the contributions of its many military veterans when they are the Select Board Wednesday condemned the honored on Veterans Day. rhetoric of the pro-Donald Trump protestors This year’s COVID-19 modi ed ceremony had who have been gathering weekly in Monument an added twist that was 79 years in the making Square. — the addition of a new name to the World War “These protestors’ presence in Swampscott II Memorial. Lynn woman’s efforts serves only to increase our community’s resolve Private Joseph Philip Sousa Jr., was on active and commitment to becoming a more accepting, duty at Camp Edwards on Cape Cod when he inclusive, and loving community that will work was killed in a motor vehicle accident on May tirelessly to conquer the hate and fear these 4, 1942 at the age of 21. At the time, Sousa was gain Oprah’s attention protestors represent,” the letter reads. believed to have been a Danvers resident, so his “These protestors may be speaking from Swampscott, but they do not, and will never, name was never added to the memorial. Until By Gayla Cawley Lynn speak for Swampscott.” Wednesday. ITEM STAFF resident Select Committee members Peter Spellios “His name was inadvertently never includ- Tommi LYNN — Lynn resident Tommi Hill has been (Chair), Polly Titcomb (Vice Chair), Donald ed on the memorial because he was believed Hill’s work working with the Lynn Shelter Association to Hause, David Grishman and Neal Duffy all to have been a Danvers resident, but through to support help transition homeless families into their new signed the statement. -

Lisa Essary, Csa 323.610.1345
LISA ESSARY, CSA 323.610.1345 [email protected] CASTING HISTORY 06/-20/- Ongoing DAFT STATE Casting Director (Feature) Dir: Chad Bishoff 01/-20/-02-20 SIMONE Casting Director with Heidi Levitt (Feature) Dir: Betty Kaplan CAST: Esai Morales, Kunjue Li, Catarina Murino 09/19-11/19 BIG AMERICA Casting Director (Feature) Dir: David Moreton CAST: Robert Kazinsky, Joshua De Jesus, Willow Geer, Cody Longo, Martin Martinez, Margarita Reyes, Jake Jacobson, 05/19-09/19 THE GIFT Casting Director (Feature) Dir: Anna Chi CAST: Lisa Lu, Michelle Krusiec, Adrian Pasdar, Michelle Arthur, and Joely Fisher 02/19- 04/19 LA FLAMME ROUGE Casting Director with Heidi Levitt (Feature) Dir: The Maze Brothers CAST: Balthazar Getty, Todd Lowe, and Clint Howard 12/18- 01/19 THE LAST VICTIM Casting Consultant (Feature) Dir: Naveen A. Chathapuram CAST: Ali Larter, Ralph Ineson, and Ron Perlman 10/18- 12/18 SOVIET SLEEP STUDY Casting Director (Feature) Dir: Barry Andersson CAST: Eva De Dominici and Rafal Zawierucha 07/18- 10/18 SAM HU’S LAST DAY Casting Director (Short) Dir: Guy Malim CAST: James Kyson and Mike Doyle 05/18-07/18 DOWN TO NOTHING Casting Director (Short) Dir: Rory Kelly CAST: Sheryl Lee and Michael Traynor 01/18- 05/18 THE WRETCHED Casting Director (Feature) Dir: The Pierce Brothers CAST: John-Paul Howard, Piper Curda, Azie Tesfai, Kevin Bigley, Zarah Mahler 09/17-12/17 THE THINNING: NEW WORLD ORDER Casting Director (Feature) Dir: Michael Gallagher CAST: Peyton List, Logan Paul, Matthew Glave, Calum Worthy Charles Melton, Rome Flynn. 04/17-09/17 PURSUED -
Ages Ahead of Most of Us
Rio Americano Mentors Home to Top High Make a Difference PAGE 2 School Bands PAGE 3 VOLUME 39 • ISSUE 18 Serving Carmichael & Sacramento County since 1981 MAY 3, 2019 SEE SSWD to INSIDE Ages Ahead of Most of Us Invest $18 THOSE WITH Shriners Hospitals for Children Restoring Our Faith in Humanity ALZHEIMER’S Million NEED A FRIEND – A BEST FRIEND! in Water Infrastructure By SSWD staff SACRAMENTO, CA (MPG) - Sacramento Suburban Water District (SSWD) is slated to invest more than PAGE 13 $18 million into improving its water infrastructure sys- tem this year. This comes ROTARY FUNDS on top of the $19 million spent in 2018. The invest- TRAINING TO ment is part of the District’s ongoing commitment to PREVENT HUMAN replacing and upgrading its infrastructure so the District TRAFFICKING can continue to meet the needs of its customers. One of SSWD’s priori- Shriners Hospital Development Director Alan Anderson (center) receives a $2500 donation from the Carmichael Chamber of ties is upgrading its extensive Commerce. The gift represents 10 percent of proceeds from the Chamber’s recent Person of the Year fundraiser. Presenters are system of water mainlines. Mayor Kelli Foley (left), Directors Amanda Lambert and Virginia Stone and Chamber President Jim Alves. Photo courtesy of Susan Maxwell Skinner Water mainlines are the pipes that deliver water from pump- By Patrick Larenas for Children, Alan Anderson. Other more profit oriented institutions ing stations to the service line Because of the economic reces- do not devote funds with “this kind of pipe that connects to a home SACRAMENTO, CA (MPG) - Sacramento sion and rising health care costs, astonishing efficiency rate.” or business. -

From Marcus Welby, M.D. to the Resident: the Changing Portrayal of Physicians in Tv Medical Dramas
RMC Original JMM ISSN electrónico: 1885-5210 DOI: http://dx.doi.org/10.14201/rmc202016287102 FROM MARCUS WELBY, M.D. TO THE RESIDENT: THE CHANGING PORTRAYAL OF PHYSICIANS IN TV MEDICAL DRAMAS Desde Marcus Welby, M.D. hasta The resident: los cambios en las representaciones de los médicos en las series de televisión Irene CAMBRA-BADII1; Elena GUARDIOLA2; Josep-E. BAÑOS2 1Cátedra de Bioética. Universitat de Vic – Universitat Central de Catalunya.2 Facultad de Medicina. Universitat de Vic – Universitat Central de Catalunya (Spain). e-mail: [email protected] Fecha de recepción: 9 July 2019 Fecha de aceptación: 5 September 2019 Fecha del Avance On-Line: Fecha de publicación: 1 June 2020 Summary Over the years, the way medical dramas represent health professionals has changed. When the first medical dramas were broadcasted, the main characters were good, peaceful, intelligent, competent, empathic, and successful physicians. One of the most famous, even outside the US, was Marcus Welby M.D. (1969-1976) of David Victor –which this year marks 50 years since its first emission. This depiction began to change in the mid-1990s. While maintaining the over positive image of medical doctors, TV series started to put more emphasis on their negative characteristics and difficulties in their interpersonal relationships, such asER (TV) by Michael Crichton (United States) and House MD (TV) by David Shore (United States). In these series, physicians were portrayed as arrogant, greedy, and adulterous, and their diagnostic and therapeutic errors were exposed. The last two series are The Good Doctor (TV) by David Shore (United States), with a resident of surgery with autism and Savant syndrome, and The Resident (TV) by Amy Holden Jones, Hayley Schore and Roshan Sethi (United States), where serious institutional problems appear.