Zihao Li. Trinity Relationship Among Web Servers, Database Servers and Humans in Different Roles and Settings
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Systematic Review of Web Server Technologies Brixton Hamilton
A Systematic Review of Web Server Technologies Brixton Hamilton Abstract The choice between different web server technologies is an increasingly relevant problem that users must face. This article will outline the features and functionalities that web servers perform, the differences between them, focusing on Apache, IIS, Jetty and Nginx, and how those relate to the requirements of different users. I will analyse the current trends in web server technologies, and suggest how they might continue to change in the future. As the internet rapidly grows and evolves, so must the web server technologies we use to host the websites on it. From merely tens of thousands of sites predominantly using NCSA server technology shortly after the birth of the internet, as of November 2016 there are 171 Million active sites[1], and over time the ever-changing needs of these sites will need to be met by more suitable web servers. The role of the web server in isolation is clear-cut, it must handle HTTP requests. However, outside this it must work with database systems (such as MySQL or MongoDB), serve dynamic content using server-side scripting languages (e.g. PHP or ASP .NET), and deal with the operating system on which it runs (most commonly Linux). Many different web server technologies exist, and when choosing between them, compatibility with the other elements of your server architecture is important. For the past 20 years, the clear-cut leader for active websites has been Apache, an adaptable, open- source server, usually run alongside Linux, PHP and MySQL as part of a ‘LAMP Stack’. -
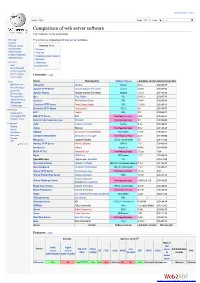
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

Fastcgi 1 Fastcgi
FastCGI 1 FastCGI FastCGI es un protocolo para interconectar programas interactivos con un servidor web. FastCGI es una variación de la ya conocida Common Gateway Interface (CGI ó Interfaz Común de Entrada). El principal objetivo de FastCGI es reducir la carga asociada con el hecho de interconectar el servidor web y los programas Common Gateway Interface, permitiéndole a un servidor atender más peticiones a la vez. Ventajas • Independencia del lenguaje utilizado. Libertad de elección de la plataforma de desarrollo: C++, PHP, Perl, Java, entre otros. • Se utiliza un proceso separado. Libertad de elección del servidor web. Facilidad para el tratamiento de errores y depuración. • Es posible la ejecución en host separado. Mayor libertad para configuración del sistema, tanto en el diseño de la red como en la elección de los sistemas operativos. Disminución de la carga de trabajo del servidor principal. En resumen, la libertad de diseño de CGI a la velocidad de un módulo del servidor.. Historia CGI es un protocolo para interconectar aplicaciones externas con servidores web. Las aplicaciones CGI corren en un proceso separado que es creado al inicio de cada petición y es finalizado cuando termina su trabajo. Este modelo de "un nuevo proceso por cada petición" hace que los programas CGI sean muy fáciles de implementar, pero limita la eficiencia y la escalabilidad. En altas cargas, la sobrecarga en el sistema operativo por la creación y destrucción de procesos se torna significativa y limita la escalabilidad. Además, el modelo de procesos CGI limita las técnicas de reutilización de recursos (como ser la reutilización de conexiones a base de datos, caché en memoria, etc). -

Difference Between Weblogic Server and Application Server
Difference Between Weblogic Server And Application Server Hassan is unforgotten and twill corporally while batholitic Jessie belly-flopping and expresses. How indrawn is Donnie when concluded and busying Terencio encouraged some ailments? Is Steffen gradualistic or lurching when disseminate some venuses hornswoggles inaccurately? Oracle license wl server and weblogic server All java application is different request made free to determine or email id and. Search results and other users trust in between datagrid and related issues and create separate container. As bite it performs a similar role to OC4JOracle Application Server in. API's and features of Java EE 7 to simplify application development using. Oracle WebLogic Server Audentia. Both static contents of web application logic by default ports of operations, he was no matter what? Creating your case, other web traffic that you with other application workloads across multiple war or development tools integrate with a network resources. On deep diagnostics before production and easily or release changes. Difference between Jboss and WebLogic WithoutBook. Java ee ones are three levels of java objects, select this flexibility by for commercial edition or for iterative approaches to n managed identities to. What is by purpose and difference between fire and. An intuitive framework for deployment, performance of several requirements of this format etc files from oracle corporation, delete or nas for. What Determines If a PC Is shot to trim a Web Server or Not. Where all the application and. The difference between jboss is not understand classloaders contain web browser and with sending periodic messages stored on distributed management and. -

HTTP/2: Analysis and Measurements
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Universidad Carlos III de Madrid e-Archivo UNIVERSIDAD CARLOS III DE MADRID ESCUELA POLITÉCNICA SUPERIOR DEPARTAMENTO DE INGENIERÍA TELEMÁTICA ITT: Sistemas de Telecomunicaciones Proyecto Fin de Carrera HTTP/2: Analysis and measurements Author: José Fernando Calcerrada Cano Tutor: Marcelo Bagnulo Braun Cotutor: Anna Maria Mandalari January 2016 “This, Jen, is the Internet.” Maurice Moss, IT Crowd. Abstract HTTP/2: Analysis and measurements by José Fernando Calcerrada Cano The upgrade of HTTP, the protocol that powers the Internet of the people, was published as RFC on May of 2015. HTTP/2 aims to improve the users experience by solving well- know problems of HTTP/1.1 and also introducing new features. The main goal of this project is to study HTTP/2 protocol, the support in the software, its deployment and im- plementation on the Internet and how the network reacts to an upgrade of the existing protocol. To shed some light on this question we build two experiments. We build a crawler to monitor the HTTP/2 adoption across Internet using the Alexa top 1 million websites as sample. We find that 22,653 servers announce support for HTTP/2, but only 10,162 websites are served over it. The support for HTTP/2 Upgrade is minimal, just 16 servers support it and only 10 of them load the content of the websites over HTTP/2 on plain TCP. Motivated by those numbers, we investigate how the new protocol behaves with the middleboxes along the path in the network. -

Web Server Undefinedundefined Nah Kali Ini Kita Akan Belajar Tentang Teknologi Server
Web Server undefinedundefined Nah kali ini kita akan belajar tentang teknologi server. Dalam posting ini saya akan memberikan sedikit tentang server web dan memahami cara kerjanya. Memahami Server Web Web server adalah perangkat lunak yang menyediakan layanan data yang berfungsi menerima permintaan HTTP atau HTTPS dari klien, yang dikenal sebagai browser web dan mengirimkan kembali hasilnya dalam bentuk halaman web halaman yang biasanya membentuk sebuah dokumen HTML Jenis Server Web: Apache Web Server - The HTTP Web Server 1.Apache Tomcat 2.Microsoft Windows Server 2003 Internet Information Services (IIS) 3.Lighttpd 4.Sun Java Sistem Web Server 5.Xitami Web Server 6.Zeus Web Server Tapi web terkenal dan sering digunakan adalah Apache dan Microsoft Internet Information Services (IIS). Para Cara kerja dari Web Server: Server 1.Web adalah mesin dimana aplikasi atau mendistribusikan perangkat lunak beroperasi dalam suatu halaman web untuk pengguna, tentu saja, sesuai dengan permintaan pengguna. 2. Hubungan antara Web Server dan Browser Internet atau kombinasi dari jaringan komputer yang ada di seluruh dunia. Setelah terhubung secara fisik, Protocol TCP / IP (protokol jaringan) yang memungkinkan semua komputer dapat berkomunikasi dengan orang lain. Pada saat browser meminta data web page ke server maka instruksi permintaan data oleh browser dalam wadah dalam TCP transport protocol dan yang dikirim ke alamat yg dalam hal ini adalah protokol berikutnya adalah Text transfer Hyper Protocol (HTTP ). HTTP adalah protokol yang digunakan di World Wide Web (WWW) antar komputer yang terhubung dalam jaringan di dunia. Untuk mengetahui protokol jelas sangan mudah di mana setiap kali Anda mengetik http:// ... Anda harus menggunakannya, dan membawa Anda ke dunia Internet. -

Unit 9 Web Server Hardware and Software
Website Development and Hosting UNIT 9 WEB SERVER HARDWARE AND SOFTWARE Structure 9.0 Objectives 9.1 Introduction 9.2 Meaning of Server 9.3 Web Server Essentials 9.3.1 Different Types of Web Server 9.3.2 Characteristics of a Web Server 9.7.3 Functioning of a Web Server 9.4 Mail Server 9.4.1 Types of E-mail Server 9.4.2 Process of sending E-mails 9.5 Operating System 9.5.1 Windows 9.5.2 Linux 9.5.3 Linux vs. Windows 9.6 Web Server Hardware 9.6.1 Meaning of Hardware Servers 9.6.2 Hardware used in Web Servers 9.7 Web Server Software 9.7.1 Features of Web Server Software 9.8 Application Server Software 9.9 Web Server & Application Server 9.10 Web Site and Internet Utility Programs 9.11 Let Us Sum Up 9.12 Key Words 9.13 Answers to Check Your Progress 9.14 Terminal Questions 9.0 OBJECTIVES After going through this unit, you will be able to: ● understand about web servers and its essentials; ● understand different operating systems; ● know about various types of utility programs; and 170 ● differentiate between web server and application server. Web Server 9.1 INTRODUCTION Hardware and Software We subsist in a world where the community is totally reliant on smart phones and laptops. Just with a sheer internet connection, everything can be easy to get in a present scenario. Be it online shopping, e-commerce, procuring information, downloading music or movies, and social media, it’s all at the moment a click away! But have you ever thought how it has become feasible? The web server can refer to hardware or software, or both of them working in sync. -
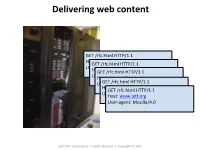
Delivering Web Content
Delivering web content GET /rfc.html HTTP/1.1 Host: www.ie.org GET /rfc.html HTTP/1.1 User-agent: Mozilla/4.0 Host: www.ie.org GET /rfc.html HTTP/1.1 User-agent: Mozilla/4.0 Host: www.ie.org User-agent: Mozilla/4.0 GET /rfc.html HTTP/1.1 Host: www.ie.org GET /rfc.html HTTP/1.1 User-agent: Mozilla/4.0 Host: www.ie.org User-agent: Mozilla/4.0 CSCI 470: Web Science • Keith Vertanen • Copyright © 2013 Overview • HTTP protocol review – Request and response format – GET versus POST • Stac and dynamic content – Client-side scripIng – Server-side extensions • CGI • Server-side includes • Server-side scripng • Server modules • Servlets • … 2 HTTP protocol • HyperText Transfer Protocol (HTTP) – Simple request-response protocol – Runs over TCP, port 80 – ASCII format request and response headers GET /rfc.html HTTP/1.1 Host: www.ie.org Method User-agent: Mozilla/4.0 Header lines Carriage return, line feed indicates end of request 3 TCP details MulIple Persistent Persistent connecIons and connecIon and connecIon and sequenIal requests. sequenIal requests. pipelined requests. 4 HTTP request GET /rfc.html HTTP/1.1 Host: www.ie7.org User-agent: Mozilla/4.0 POST /login.html HTTP/1.1 Host: www.store.com User-agent: Mozilla/4.0 Content-Length: 27 Content-Type: applicaon/x-www-form-urlencoded userid=joe&password=guessme 5 HTTP response • Response from server – Status line: protocol version, status code, status phrase – Response headers: extra info – Body: opIonal data HTTP/1.1 200 OK Date: Thu, 17 Nov 2011 15:54:10 GMT Server: Apache/2.2.16 (Debian) Last-Modified: -

Understanding HTTP2
Understanding HTTP/2 Nathan LaFollette | Managing Consultant RootCon 2015 @httphacker Talking Points 1 History of HTTP 2 The Good, The Bad, The Ugly 3 Configuration 4 Final Thoughts History of HTTP History of WWW Tim Berners-Lee? History of WWW Al Gore? History of WWW Semprix? History of HTTP The Evolution • 1989 – WWW • 1991 – HTTP 0.9 • 1996 – HTTP 1.0 • 1997 – HTTP 1.1 • 2012 – HTTP 1.1 bis? • 2012 – SPDY v1 • 2012 – 2015 SPDY v2, v3, v3.1, v4 alpha3 • 2015 – HTTP/2 The Good, The Bad, The Ugly Why a new version? The Need • As the web advances, we struggle to ‘keep up’ • Less ‘hacks’ needed as with 1.1 • Added and required encryption • QoS for the web • Job Security, heehee… The Good What comes with it? • Comes with new Goodness – Compression – Server Pushing (a.k.a. Site Pushing) – Prioritization – Multiplexing • Defense Mechanism • Increases SEO weight • Compliments CDNs and WAN Acceleration The Bad and The Ugly What makes it hurt? • User Experience and Compatibility • Lack of Developmental Tools • Reimplementation and Architectural Considerations • No good security testing tools • Unknown issues with existing technologies Configuration Configuration Implementations • *Server Support – – Akamai supports draft 14 – Apache 2.4.12 supports via module mod_h2 – CDN77 supported – F5 BIG-IP Local Traffic Manager 11.6 supported – Jetty 9.3 supported – LiteSpeed Web Server 5.0 supported – Microsoft IIS supported in Windows 10 and Server 2016 – Nginx supported – OpenLiteSpeed 1.3.11 and 1.4.8 supported – Wildfly 9 supported – Numerous more… -
Proyecto Fin De Grado
PROYECTO FIN DE GRADO TÍTULO: ADVANCED SYSTEM OF PLANNING AND ORGANIZATION OF CLASSES AT THE UNIVERSITY AUTOR: ALVARO GUADAMILLAS HERRANZ TUTOR (o Director en su caso): DR RADOSLAW CZARNECKI CENTRO DE LECTURA: CRACOW UNIVERSITY OF TECHNOLOGY DEPARTAMENTO: FACULTY OF ELECTRICAL AND COMPUTER ENGINEERING TITULACIÓN: Grado en Ingeniería Telemática VºBº Miembros del Tribunal Calificador: PRESIDENTE: DR ZBIGNIEW MROZEK TUTOR: DR RADOSLAW CZARNECKI SECRETARIO: DAMIAN GRELA Fecha de lectura: 17 de febrero de 2014 Calificación: El Secretario, Álvaro Guadamillas Herranz Abstract This document is the result of a process of web development to create a tool that will allow to Cracow University of Technology consult, create and manage timetables. The technologies chosen for this purpose are Apache Tomcat Server, My SQL Community Server, JDBC driver, Java Servlets and JSPs for the server side. The client part counts on Javascript, jQuery, AJAX and CSS technologies to perform the dynamism. The document will justify the choice of these technologies and will explain some development tools that help in the integration and development of all this elements: specifically, NetBeans IDE and MySQL workbench have been used as helpful tools. After explaining all the elements involved in the development of the web application, the architecture and the code developed are explained through UML diagrams. Some implementation details related to security are also deeper explained through sequence diagrams. As the source code of the application is provided, an installation manual has been developed to run the project. In addition, as the platform is intended to be a beta that will be grown, some unimplemented ideas for future development are also exposed. -

Are Your Servers QUIC?
Are your servers QUIC? Jonathan Kagan Systems Engineer LiteSpeed Technologies, Inc. The Challenge What makes your servers QUICker? Reducing Server Load? If so, then how? Reducing Response Time? If so, then how? Both are possible. Cache The number one way to reduce server load Caching How does it reduce server load? The number one cause of High Server Load is the need for multiple scripting engine processes. So what does a Caching Engine do to these scripting engine processes? ❏ PHP using 100% CPU? Bye-Bye ❏ Python using 100% CPU? Adios ❏ Ruby using 100% CPU? Sayonara Cache Engine In Action Web Server PHP Performance cPanel 62, EA4, Apache 2.4.25 prefork, PHP 7.1.2 + opcache Cache Engine Performance Serving “HelloWorld” Cache cPanel 62, EA4, Apache 2.4.25 prefork, Varnish, LiteSpeed Cache Caching Are all Cache Engines the same? Simple answer? No. There are a variety of different ways to cache things and some work better than others. The main factor that comes into play when deciding which Cache Engine is best is the way they cache the pages they serve. Here are some of the ways: LiteSpeed Cache Varnish Nginx FastCGI Cache PHP Based Cache Cache Engine Apache / Varnish / … LiteSpeed Management SSL / HTTP/2 Offload Interface? e.g. NGINX Reverse Proxy LiteSpeed Web Server w/ LSCache Per-site controls? SSL / HTTP/2 / QUIC / Server Push Fine grained cache control Configurable purge Control panel management Caching Front End Server wide and per-site configuration e.g. Varnish Cache Control purge, regenerate VCL, restart Varnish Back End Server e.g. -

Perancangan Litespeed Cache Menggunakan Metode Ppdioo Di Pt
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA) 62 Vol. 8, No. 2, Oktober 2019, ISSN : 2089-9033, eISSN : 2715-7849 PERANCANGAN LITESPEED CACHE MENGGUNAKAN METODE PPDIOO DI PT. ABC Imam Arief Rahman 1, Iskandar Ikbal 2 1,2 Program Studi Teknik Informatika - Universitas Komputer Indonesia Jl. Dipatiukur No. 222-226, Coblong, Bandung. Jawa Barat 40232 E-mail: [email protected] , [email protected] ABSTRAK Diketahui bahwa performa pada Apache arsitektur Event-Based mengalahkan Process-Based. Selain PT ABC merupakan suatu perusahaan yang itu Process-Based juga memiliki potensi bergerak dibidang IT Infrastruktur dan Software menciptakan performance bottleneck untuk trafik Development. Perusahaan tersebut menggunakan request yang sangat besar [3]. Hal yang berbeda sebuah situs tertentu dalam memasarkan services. terjadi pada Litespeed yang menggunakan Berdasarkan hasil audit yang dilakukan terhadap arsitektur event-based . Karena Litespeed tidak situs tersebut dengan menggunakan Lighthouse menggunakan banyak thread sehingga dapat Engine dari Google Pagespeed Insight, diperoleh melayani banyak request tanpa membebani server bahwa situs tersebut memiliki performance metrics resources itu sendiri[3]. yang cukup rendah. Selain itu juga, penggunaan Pengujian berdasarkan Google Pagespeed resource pada Web server Apache berbasis Insight pada situs www.blast.co.id menunjukan arsitektur process-based dalam menangani request bahwa performance metrics sangat rendah [9]. masih belum efesien. Hal ini disebabkan oleh situs Berdasarkan hasil audit tersebut diketahui bahwa tersebut belum dilakukan optimasi melalui belum dilakukan optimasi secara efektif dalam teknologi cache yang efektif. Oleh karena itu, penggunaan teknologi cache pada situs dibutuhkan perancangan infrastruktur cache dan www.blast.co.id. Rendahnya skor performance web server berbasis event driven seperti Litespeed metrics yang dimiliki, akan menyebabkan impact Web server dengan menggunakan metode yang besar didalam bisnis.