Next-Generation of Recurrent Neural Network Models for Cognition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Elements of DSAI: Game Tree Search, Learning Architectures
Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Elements of DSAI AlphaGo Part 2: Game Tree Search, Learning Architectures Search & Learn: A Recipe for AI Action Decisions J¨orgHoffmann Winter Term 2019/20 Hoffmann Elements of DSAI Game Tree Search, Learning Architectures 1/49 Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Competitive Agents? Quote AI Introduction: \Single agent vs. multi-agent: One agent or several? Competitive or collaborative?" ! Single agent! Several koalas, several gorillas trying to beat these up. BUT there is only a single acting entity { one player decides which moves to take (who gets into the boat). Hoffmann Elements of DSAI Game Tree Search, Learning Architectures 3/49 Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Competitive Agents! Quote AI Introduction: \Single agent vs. multi-agent: One agent or several? Competitive or collaborative?" ! Multi-agent competitive! TWO players deciding which moves to take. Conflicting interests. Hoffmann Elements of DSAI Game Tree Search, Learning Architectures 4/49 Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Agenda: Game Search, AlphaGo Architecture Games: What is that? ! Game categories, game solutions. Game Search: How to solve a game? ! Searching the game tree. Evaluation Functions: How to evaluate a game position? ! Heuristic functions for games. AlphaGo: How does it work? ! Overview of AlphaGo architecture, and changes in Alpha(Go) Zero. Hoffmann Elements of DSAI Game Tree Search, Learning Architectures 5/49 Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Positioning in the DSAI Phase Model Hoffmann Elements of DSAI Game Tree Search, Learning Architectures 6/49 Introduction Games Game Search Evaluation Fns AlphaGo/Zero Summary Quiz References Which Games? ! No chance element. -

Discrete Sequential Prediction of Continu
Under review as a conference paper at ICLR 2018 DISCRETE SEQUENTIAL PREDICTION OF CONTINU- OUS ACTIONS FOR DEEP RL Anonymous authors Paper under double-blind review ABSTRACT It has long been assumed that high dimensional continuous control problems cannot be solved effectively by discretizing individual dimensions of the action space due to the exponentially large number of bins over which policies would have to be learned. In this paper, we draw inspiration from the recent success of sequence-to-sequence models for structured prediction problems to develop policies over discretized spaces. Central to this method is the realization that com- plex functions over high dimensional spaces can be modeled by neural networks that predict one dimension at a time. Specifically, we show how Q-values and policies over continuous spaces can be modeled using a next step prediction model over discretized dimensions. With this parameterization, it is possible to both leverage the compositional structure of action spaces during learning, as well as compute maxima over action spaces (approximately). On a simple example task we demonstrate empirically that our method can perform global search, which effectively gets around the local optimization issues that plague DDPG. We apply the technique to off-policy (Q-learning) methods and show that our method can achieve the state-of-the-art for off-policy methods on several continuous control tasks. 1 INTRODUCTION Reinforcement learning has long been considered as a general framework applicable to a broad range of problems. However, the approaches used to tackle discrete and continuous action spaces have been fundamentally different. In discrete domains, algorithms such as Q-learning leverage backups through Bellman equations and dynamic programming to solve problems effectively. -
![Arxiv:2107.04562V1 [Stat.ML] 9 Jul 2021 ¯ ¯ Θ∗ = Arg Min `(Θ) Where `(Θ) = `(Yi, Fθ(Xi)) + R(Θ)](https://docslib.b-cdn.net/cover/5758/arxiv-2107-04562v1-stat-ml-9-jul-2021-%C2%AF-%C2%AF-arg-min-where-yi-f-xi-r-285758.webp)
Arxiv:2107.04562V1 [Stat.ML] 9 Jul 2021 ¯ ¯ Θ∗ = Arg Min `(Θ) Where `(Θ) = `(Yi, Fθ(Xi)) + R(Θ)
The Bayesian Learning Rule Mohammad Emtiyaz Khan H˚avard Rue RIKEN Center for AI Project CEMSE Division, KAUST Tokyo, Japan Thuwal, Saudi Arabia [email protected] [email protected] Abstract We show that many machine-learning algorithms are specific instances of a single algorithm called the Bayesian learning rule. The rule, derived from Bayesian principles, yields a wide-range of algorithms from fields such as optimization, deep learning, and graphical models. This includes classical algorithms such as ridge regression, Newton's method, and Kalman filter, as well as modern deep-learning algorithms such as stochastic-gradient descent, RMSprop, and Dropout. The key idea in deriving such algorithms is to approximate the posterior using candidate distributions estimated by using natural gradients. Different candidate distributions result in different algorithms and further approximations to natural gradients give rise to variants of those algorithms. Our work not only unifies, generalizes, and improves existing algorithms, but also helps us design new ones. 1 Introduction 1.1 Learning-algorithms Machine Learning (ML) methods have been extremely successful in solving many challenging problems in fields such as computer vision, natural-language processing and artificial intelligence (AI). The main idea is to formulate those problems as prediction problems, and learn a model on existing data to predict the future outcomes. For example, to design an AI agent that can recognize objects in an image, we D can collect a dataset with N images xi 2 R and object labels yi 2 f1; 2;:::;Kg, and learn a model P fθ(x) with parameters θ 2 R to predict the label for a new image. -

Bridging Imagination and Reality for Model-Based Deep Reinforcement Learning
Bridging Imagination and Reality for Model-Based Deep Reinforcement Learning Guangxiang Zhu⇤ Minghao Zhang⇤ IIIS School of Software Tsinghua University Tsinghua University [email protected] [email protected] Honglak Lee Chongjie Zhang EECS IIIS University of Michigan Tsinghua University [email protected] [email protected] Abstract Sample efficiency has been one of the major challenges for deep reinforcement learning. Recently, model-based reinforcement learning has been proposed to address this challenge by performing planning on imaginary trajectories with a learned world model. However, world model learning may suffer from overfitting to training trajectories, and thus model-based value estimation and policy search will be prone to be sucked in an inferior local policy. In this paper, we propose a novel model-based reinforcement learning algorithm, called BrIdging Reality and Dream (BIRD). It maximizes the mutual information between imaginary and real trajectories so that the policy improvement learned from imaginary trajectories can be easily generalized to real trajectories. We demonstrate that our approach improves sample efficiency of model-based planning, and achieves state-of-the-art performance on challenging visual control benchmarks. 1 Introduction Reinforcement learning (RL) is proposed as a general-purpose learning framework for artificial intelligence problems, and has led to tremendous progress in a variety of domains [1, 2, 3, 4]. Model- free RL adopts a trail-and-error paradigm, which directly learns a mapping function from observations to values or actions through interactions with environments. It has achieved remarkable performance in certain video games and continuous control tasks because of its simplicity and minimal assumptions about environments. -
A Public Data Set for Energy Disaggregation Research
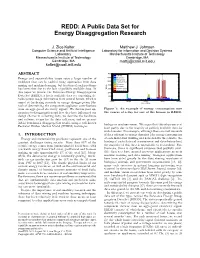
REDD: A Public Data Set for Energy Disaggregation Research J. Zico Kolter Matthew J. Johnson Computer Science and Artificial Intelligence Laboratory for Information and Decision Systems Laboratory Massachusetts Institute of Technology Massachusetts Institute of Technology Cambridge, MA Cambridge, MA [email protected] [email protected] ABSTRACT 7000 Lighting 6000 Electronics Energy and sustainability issues raise a large number of Refrigerator problems that can be tackled using approaches from data 5000 Bathroom GFI 4000 Dishwaser mining and machine learning, but traction of such problems Microwave has been slow due to the lack of publicly available data. In Watts 3000 Kitchen Outlets Washer Dryer this paper we present the Reference Energy Disaggregation 2000 Data Set (REDD), a freely available data set containing de- 1000 tailed power usage information from several homes, which is 0 00:00 06:00 12:00 18:00 00:00 aimed at furthering research on energy disaggregation (the Time of Day task of determining the component appliance contributions from an aggregated electricity signal). We discuss past ap- Figure 1: An example of energy consumption over proaches to disaggregation and how they have influenced our the course of a day for one of the houses in REDD. design choices in collecting data, we describe the hardware and software setups for the data collection, and we present initial benchmark disaggregation results using a well-known biology or machine vision. We argue that this situation is at Factorial Hidden Markov Model (FHMM) technique. least partly due to the scarcity of publicly available data for such domains. For example, although there are vast amounts 1. -

Improving the Gating Mechanism of Recurrent
Under review as a conference paper at ICLR 2020 IMPROVING THE GATING MECHANISM OF RECURRENT NEURAL NETWORKS Anonymous authors Paper under double-blind review ABSTRACT Gating mechanisms are widely used in neural network models, where they allow gradients to backpropagate more easily through depth or time. However, their satura- tion property introduces problems of its own. For example, in recurrent models these gates need to have outputs near 1 to propagate information over long time-delays, which requires them to operate in their saturation regime and hinders gradient-based learning of the gate mechanism. We address this problem by deriving two synergistic modifications to the standard gating mechanism that are easy to implement, introduce no additional hyperparameters, and improve learnability of the gates when they are close to saturation. We show how these changes are related to and improve on alternative recently proposed gating mechanisms such as chrono-initialization and Ordered Neurons. Empirically, our simple gating mechanisms robustly improve the performance of recurrent models on a range of applications, including synthetic memorization tasks, sequential image classification, language modeling, and reinforcement learning, particularly when long-term dependencies are involved. 1 INTRODUCTION Recurrent neural networks (RNNs) have become a standard machine learning tool for learning from sequential data. However, RNNs are prone to the vanishing gradient problem, which occurs when the gradients of the recurrent weights become vanishingly small as they get backpropagated through time (Hochreiter et al., 2001). A common approach to alleviate the vanishing gradient problem is to use gating mechanisms, leading to models such as the long short term memory (Hochreiter & Schmidhuber, 1997, LSTM) and gated recurrent units (Chung et al., 2014, GRUs). -

Training Plastic Neural Networks with Backpropagation
Differentiable plasticity: training plastic neural networks with backpropagation Thomas Miconi 1 Jeff Clune 1 Kenneth O. Stanley 1 Abstract examples. By contrast, biological agents exhibit a remark- How can we build agents that keep learning from able ability to learn quickly and efficiently from ongoing experience, quickly and efficiently, after their ini- experience: animals can learn to navigate and remember the tial training? Here we take inspiration from the location of (and quickest way to) food sources, discover and main mechanism of learning in biological brains: remember rewarding or aversive properties of novel objects synaptic plasticity, carefully tuned by evolution and situations, etc. – often from a single exposure. to produce efficient lifelong learning. We show Endowing artificial agents with lifelong learning abilities that plasticity, just like connection weights, can is essential to allowing them to master environments with be optimized by gradient descent in large (mil- changing or unpredictable features, or specific features that lions of parameters) recurrent networks with Heb- are unknowable at the time of training. For example, super- bian plastic connections. First, recurrent plastic vised learning in deep neural networks can allow a neural networks with more than two million parameters network to identify letters from a specific, fixed alphabet can be trained to memorize and reconstruct sets to which it was exposed during its training; however, au- of novel, high-dimensional (1,000+ pixels) nat- tonomous learning abilities would allow an agent to acquire ural images not seen during training. Crucially, knowledge of any alphabet, including alphabets that are traditional non-plastic recurrent networks fail to unknown to the human designer at the time of training. -

Bayesian Policy Selection Using Active Inference
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Ghent University Academic Bibliography Published in the proceedings of the Workshop on “Structure & Priors in Reinforcement Learning” at ICLR 2019 BAYESIAN POLICY SELECTION USING ACTIVE INFERENCE Ozan C¸atal, Johannes Nauta, Tim Verbelen, Pieter Simoens, & Bart Dhoedt IDLab, Department of Information Technology Ghent University - imec Ghent, Belgium [email protected] ABSTRACT Learning to take actions based on observations is a core requirement for artificial agents to be able to be successful and robust at their task. Reinforcement Learn- ing (RL) is a well-known technique for learning such policies. However, current RL algorithms often have to deal with reward shaping, have difficulties gener- alizing to other environments and are most often sample inefficient. In this pa- per, we explore active inference and the free energy principle, a normative theory from neuroscience that explains how self-organizing biological systems operate by maintaining a model of the world and casting action selection as an inference problem. We apply this concept to a typical problem known to the RL community, the mountain car problem, and show how active inference encompasses both RL and learning from demonstrations. 1 INTRODUCTION Active inference is an emerging paradigm from neuroscience (Friston et al., 2017), which postulates that action selection in biological systems, in particular the human brain, is in effect an inference problem where agents are attracted to a preferred prior state distribution in a hidden state space. Contrary to many state-of-the art RL algorithms, active inference agents are not purely goal directed and exhibit an inherent epistemic exploration (Schwartenbeck et al., 2018). -

Simultaneous Unsupervised and Supervised Learning of Cognitive
Simultaneous unsupervised and supervised learning of cognitive functions in biologically plausible spiking neural networks Trevor Bekolay ([email protected]) Carter Kolbeck ([email protected]) Chris Eliasmith ([email protected]) Center for Theoretical Neuroscience, University of Waterloo 200 University Ave., Waterloo, ON N2L 3G1 Canada Abstract overcomes these limitations. Our approach 1) remains func- tional during online learning, 2) requires only two layers con- We present a novel learning rule for learning transformations of sophisticated neural representations in a biologically plau- nected with simultaneous supervised and unsupervised learn- sible manner. We show that the rule, which uses only infor- ing, and 3) employs spiking neuron models to reproduce cen- mation available locally to a synapse in a spiking network, tral features of biological learning, such as spike-timing de- can learn to transmit and bind semantic pointers. Semantic pointers have previously been used to build Spaun, which is pendent plasticity (STDP). currently the world’s largest functional brain model (Eliasmith et al., 2012). Two operations commonly performed by Spaun Online learning with spiking neuron models faces signifi- are semantic pointer binding and transmission. It has not yet been shown how the binding and transmission operations can cant challenges due to the temporal dynamics of spiking neu- be learned. The learning rule combines a previously proposed rons. Spike rates cannot be used directly, and must be esti- supervised learning rule and a novel spiking form of the BCM mated with causal filters, producing a noisy estimate. When unsupervised learning rule. We show that spiking BCM in- creases sparsity of connection weights at the cost of increased the signal being estimated changes, there is some time lag signal transmission error. -

Meta-Learning Deep Energy-Based Memory Models
Published as a conference paper at ICLR 2020 META-LEARNING DEEP ENERGY-BASED MEMORY MODELS Sergey Bartunov Jack W Rae Simon Osindero DeepMind DeepMind DeepMind London, United Kingdom London, United Kingdom London, United Kingdom [email protected] [email protected] [email protected] Timothy P Lillicrap DeepMind London, United Kingdom [email protected] ABSTRACT We study the problem of learning an associative memory model – a system which is able to retrieve a remembered pattern based on its distorted or incomplete version. Attractor networks provide a sound model of associative memory: patterns are stored as attractors of the network dynamics and associative retrieval is performed by running the dynamics starting from a query pattern until it converges to an attractor. In such models the dynamics are often implemented as an optimization procedure that minimizes an energy function, such as in the classical Hopfield network. In general it is difficult to derive a writing rule for a given dynamics and energy that is both compressive and fast. Thus, most research in energy- based memory has been limited either to tractable energy models not expressive enough to handle complex high-dimensional objects such as natural images, or to models that do not offer fast writing. We present a novel meta-learning approach to energy-based memory models (EBMM) that allows one to use an arbitrary neural architecture as an energy model and quickly store patterns in its weights. We demonstrate experimentally that our EBMM approach can build compressed memories for synthetic and natural data, and is capable of associative retrieval that outperforms existing memory systems in terms of the reconstruction error and compression rate. -

Block B Album Download Block B Members Profile
block b album download Block B Members Profile. Block B (블락비) currently consists of: Zico, Taeil, B-Bomb, Jaehyo, U-Kwon, Kyung, and P.O . Leader Zico left the company on November 23, 2018, however according to Seven Seasons , the future of the band as a 7-members band is still under discussion. The band debuted on April 13, 2011, under Stardom Entertainment. In 2013, they left their agency and signed with Seven Seasons, a subsidiary label to KQ Entertainment. Block B Fandom Name: BBC (Block B Club) Block B Official Fan Color: Black and Yellow Stripes. Block B Official Accounts: Twitter: @blockb_official Facebook: BlockBOfficial Instagram: @blockb_official_ Fan cafe: BB-Club. Block B Members Profile: Zico Stage Name: Zico (지코) Birth Name: Woo Ji Ho (우지호) Position: Leader, Main Rapper, Vocalist, Face of the Group Birthday: September 14, 1992 Zodiac Sign: Virgo Birthplace: Seoul, South Korea Height: 181 cm (5’11”) Weight: 65 kg (143 lbs) Blood Type: O Twitter: @ZICO92 Instagram: @woozico0914. Zico Facts: – He was born in Mapo, Seoul, South Korea. – He has an older brother, Woo Taewoon, who was a former member of idol group Speed. – He was a Vocal Performance major at Seoul Music High School. – Zico studied at the Dong-Ah Institute of Media and Arts University (between 2013 -2015). – Specialties: Freestyle rap, composing, weaving melody lines. – He auditioned for S.M. Entertainment as a teenager. – He joined Stardom Entertainment in 2009. – Zico lived abroad in Japan for three years. – On November 7, 2014, Zico released his official solo debut single entitled “Tough Cookie” featuring the rapper Don Mills – He, along with Kyung have produced all of Block B’s albums. -

Shixiang (Shane) Gu
Shixiang (Shane) Gu Jesus College, Jesus Lane Cambridge, Cambridgeshire CB5 8BL, United Kingdoms [email protected] website: http://sg717.user.srcf.net/ RESEARCH INTERESTS Deep Learning, Reinforcement Learning, Robotics, Probabilistic Models and Approximate Inference, Causality, and other Machine Learning topics. EDUCATION PhD in Machine Learning 2014—Present University of Cambridge, UK. Advised by Prof. Richard E. Turner and Prof. Zoubin Ghahramani FRS. Max Planck Institute for Intelligent Systems, Germany. Advised by Prof. Bernhard Schoelkopf. BASc in Engineering Science, Electrical and Computer major 2009–2013 University of Toronto, Canada. CGPA: 3.93. Highest Rank 1st of 264 students (2010 Winter). Recipient of Award of Excellence 2013 (awarded to top 5 graduating students from the program). High School, Vancouver, Canada. 2006–2009 Middle School, Shanghai, China. 2002–2006 Primary School, Tokyo, Japan. 1997–2002 PROFESSIONAL EXPERIENCE Google Brain, Google Research, Mountain View, CA. PhD Intern June 2015—Jan. 2016, June 2016–Sept. 2016, June 2017–Sept. 2017 Supervisors & collaborators: Ilya Sutskever, Sergey Levine, Vincent Vanhoucke, Timothy Lillicrap. • Published 1 NIPS, 2 ICML, 3 ICLR, and 1 ICRA papers as a result of internships. • Worked part-time during Feb. 2016—May 2016 at Google DeepMind under Timothy Lillicrap. • Developed the state-of-the-art methods for deep RL in continuous control, and demonstrated the robots learning door opening under 3 hours. Panasonic Silicon Valley Lab, Panasonic R&D Company of America, Cupertino,