Interactive Generation of Path-Traced Lightmaps
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Universidade Tecnológica Federal Do Paraná Campus Curitiba – Sede Central Departamento Acadêmico De Desenho Industrial Tecnologia Em Design Gráfico
UNIVERSIDADE TECNOLÓGICA FEDERAL DO PARANÁ CAMPUS CURITIBA – SEDE CENTRAL DEPARTAMENTO ACADÊMICO DE DESENHO INDUSTRIAL TECNOLOGIA EM DESIGN GRÁFICO ALEXANDRE DA SILVA SANTANA A ESTAÇÃO DE TREM DE CURITIBA EM MODELAGEM 3D: UMA FORMA DE RETRATAR A HISTÓRIA DO TREM TRABALHO DE CONCLUSÃO DE CURSO CURITIBA-PR 2017 ALEXANDRE DA SILVA SANTANA A ESTAÇÃO DE TREM DE CURITIBA EM MODELAGEM 3D: UMA FORMA DE RETRATAR A HISTÓRIA DO TREM Monografia apresentada ao Curso Superior de Tecnologia em Design Gráfico do Departamento Acadêmico de Desenho Industrial – DADIN – da Universidade Tecnológica Federal do Paraná – UTFPR, como requisito parcial para obtenção do título de Graduação em Tecnologia em Design Gráfico. Orientadora: Prof.ª MSc. Ana Cristina Munaro. CURITIBA-PR 2017 Ministério da Educação Universidade Tecnológica Federal do Paraná PR Câmpus Curitiba UNIVERSIDADE TECNOLÓGICA FEDERAL DO PARANÁ Diretoria de Graduação e Educação Profissional Departamento Acadêmico de Desenho Industrial TERMO DE APROVAÇÃO TRABALHO DE CONCLUSÃO DE CURSO 039 A ESTAÇÃO DE TREM DE CURITIBA EM MODELAGEM 3D: UMA FORMA DE REVIVER A HISTÓRIA DO TREM por Alexandre da Silva Santana – 1612557 Trabalho de Conclusão de Curso apresentado no dia 28 de novembro de 2017 como requisito parcial para a obtenção do título de TECNÓLOGO EM DESIGN GRÁFICO, do Curso Superior de Tecnologia em Design Gráfico, do Departamento Acadêmico de Desenho Industrial, da Universidade Tecnológica Federal do Paraná. O aluno foi arguido pela Banca Examinadora composta pelos professores abaixo, que após deliberação, consideraram o trabalho aprovado. Banca Examinadora: Prof. Alan Ricardo Witikoski (Dr.) Avaliador DADIN – UTFPR Prof. Francis Rodrigues da Silva (Esp.) Convidado DADIN – UTFPR Profa. Ana Cristina Munaro (MSc.) Orientadora DADIN – UTFPR Prof. -

CUDA-SCOTTY Fast Interactive CUDA Path Tracer Using Wide Trees and Dynamic Ray Scheduling
15-618: Parallel Computer Architecture and Programming CUDA-SCOTTY Fast Interactive CUDA Path Tracer using Wide Trees and Dynamic Ray Scheduling “Golden Dragon” TEAM MEMBERS Sai Praveen Bangaru (Andrew ID: saipravb) Sam K Thomas (Andrew ID: skthomas) Introduction Path tracing has long been the select method used by the graphics community to render photo-realistic images. It has found wide uses across several industries, and plays a major role in animation and filmmaking, with most special effects rendered using some form of Monte Carlo light transport. It comes as no surprise, then, that optimizing path tracing algorithms is a widely studied field, so much so, that it has it’s own top-tier conference (HPG; High Performance Graphics). There are generally a whole spectrum of methods to increase the efficiency of path tracing. Some methods aim to create better sampling methods (Metropolis Light Transport), while others try to reduce noise in the final image by filtering the output (4D Sheared transform). In the spirit of the parallel programming course 15-618, however, we focus on a third category: system-level optimizations and leveraging hardware and algorithms that better utilize the hardware (Wide Trees, Packet tracing, Dynamic Ray Scheduling). Most of these methods, understandably, focus on the ray-scene intersection part of the path tracing pipeline, since that is the main bottleneck. In the following project, we describe the implementation of a hybrid non-packet method which uses Wide Trees and Dynamic Ray Scheduling to provide an 80x improvement over a 8-threaded CPU implementation. Summary Over the course of roughly 3 weeks, we studied two non-packet BVH traversal optimizations: Wide Trees, which involve non-binary BVHs for shallower BVHs and better Warp/SIMD Utilization and Dynamic Ray Scheduling which involved changing our perspective to process rays on a per-node basis rather than processing nodes on a per-ray basis. -

Practical Path Guiding for Efficient Light-Transport Simulation
Eurographics Symposium on Rendering 2017 Volume 36 (2017), Number 4 P. Sander and M. Zwicker (Guest Editors) Practical Path Guiding for Efficient Light-Transport Simulation Thomas Müller1;2 Markus Gross1;2 Jan Novák2 1ETH Zürich 2Disney Research Vorba et al. MSE: 0.017 Reference Ours (equal time) MSE: 0.018 Training: 5.1 min Training: 0.73 min Rendering: 4.2 min, 8932 spp Rendering: 4.2 min, 11568 spp Figure 1: Our method allows efficient guiding of path-tracing algorithms as demonstrated in the TORUS scene. We compare equal-time (4.2 min) renderings of our method (right) to the current state-of-the-art [VKv∗14, VK16] (left). Our algorithm automatically estimates how much training time is optimal, displays a rendering preview during training, and requires no parameter tuning. Despite being fully unidirectional, our method achieves similar MSE values compared to Vorba et al.’s method, which trains bidirectionally. Abstract We present a robust, unbiased technique for intelligent light-path construction in path-tracing algorithms. Inspired by existing path-guiding algorithms, our method learns an approximate representation of the scene’s spatio-directional radiance field in an unbiased and iterative manner. To that end, we propose an adaptive spatio-directional hybrid data structure, referred to as SD-tree, for storing and sampling incident radiance. The SD-tree consists of an upper part—a binary tree that partitions the 3D spatial domain of the light field—and a lower part—a quadtree that partitions the 2D directional domain. We further present a principled way to automatically budget training and rendering computations to minimize the variance of the final image. -
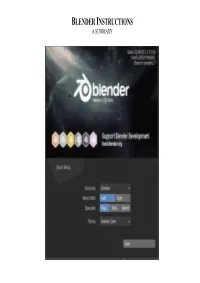
Blender Instructions a Summary
BLENDER INSTRUCTIONS A SUMMARY Attention all Mac users The first step for all Mac users who don’t have a three button mouse and/or a thumb wheel on the mouse is: 1.! Go under Edit menu 2.! Choose Preferences 3.! Click the Input tab 4.! Make sure there is a tick in the check boxes for “Emulate 3 Button Mouse” and “Continuous Grab”. 5.! Click the “Save As Default” button. This will allow you to navigate 3D space and move objects with a trackpad or one-mouse button and the keyboard. Also, if you prefer (but not critical as you do have the View menu to perform the same functions), you can emulate the numpad (the extra numbers on the right of extended keyboard devices). It means the numbers across the top of the standard keyboard will function the same way as the numpad. 1.! Go under Edit menu 2.! Choose Preferences 3. Click the Input tab 4.! Make sure there is a tick in the check box for “Emulate Numpad”. 5.! Click the “Save As Default” button. BLENDER BASIC SHORTCUT KEYS OBJECT MODE SHORTCUT KEYS EDIT MODE SHORTCUT KEYS The Interface The interface of Blender (version 2.8 and higher), is comprised of: 1. The Viewport This is the 3D scene showing you a default 3D object called a cube and a large mesh-like grid called the plane for helping you to visualize the X, Y and Z directions in space. And to save time, in Blender 2.8, the camera (left) and light (right in the distance) has been added to the viewport as default. -

Megakernels Considered Harmful: Wavefront Path Tracing on Gpus
Megakernels Considered Harmful: Wavefront Path Tracing on GPUs Samuli Laine Tero Karras Timo Aila NVIDIA∗ Abstract order to handle irregular control flow, some threads are masked out when executing a branch they should not participate in. This in- When programming for GPUs, simply porting a large CPU program curs a performance loss, as masked-out threads are not performing into an equally large GPU kernel is generally not a good approach. useful work. Due to SIMT execution model on GPUs, divergence in control flow carries substantial performance penalties, as does high register us- The second factor is the high-bandwidth, high-latency memory sys- age that lessens the latency-hiding capability that is essential for the tem. The impressive memory bandwidth in modern GPUs comes at high-latency, high-bandwidth memory system of a GPU. In this pa- the expense of a relatively long delay between making a memory per, we implement a path tracer on a GPU using a wavefront formu- request and getting the result. To hide this latency, GPUs are de- lation, avoiding these pitfalls that can be especially prominent when signed to accommodate many more threads than can be executed in using materials that are expensive to evaluate. We compare our per- any given clock cycle, so that whenever a group of threads is wait- formance against the traditional megakernel approach, and demon- ing for a memory request to be served, other threads may be exe- strate that the wavefront formulation is much better suited for real- cuted. The effectiveness of this mechanism, i.e., the latency-hiding world use cases where multiple complex materials are present in capability, is determined by the threads’ resource usage, the most the scene. -

Castle Game Engine Documentation
Castle Game Engine documentation Michalis Kamburelis Castle Game Engine documentation Michalis Kamburelis Copyright © 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014 Michalis Kamburelis You can redistribute and/or modify this document under the terms of the GNU General Public License [http://www.gnu.org/licenses/gpl.html] as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version. Table of Contents Goals ....................................................................................................................... vii 1. Overview of VRML ............................................................................................... 1 1.1. First example ............................................................................................... 1 1.2. Fields .......................................................................................................... 3 1.2.1. Field types ........................................................................................ 3 1.2.2. Placing fields within nodes ................................................................ 5 1.2.3. Examples .......................................................................................... 5 1.3. Children nodes ............................................................................................. 7 1.3.1. Group node examples ........................................................................ 7 1.3.2. The Transform node ....................................................................... -

An Advanced Path Tracing Architecture for Movie Rendering
RenderMan: An Advanced Path Tracing Architecture for Movie Rendering PER CHRISTENSEN, JULIAN FONG, JONATHAN SHADE, WAYNE WOOTEN, BRENDEN SCHUBERT, ANDREW KENSLER, STEPHEN FRIEDMAN, CHARLIE KILPATRICK, CLIFF RAMSHAW, MARC BAN- NISTER, BRENTON RAYNER, JONATHAN BROUILLAT, and MAX LIANI, Pixar Animation Studios Fig. 1. Path-traced images rendered with RenderMan: Dory and Hank from Finding Dory (© 2016 Disney•Pixar). McQueen’s crash in Cars 3 (© 2017 Disney•Pixar). Shere Khan from Disney’s The Jungle Book (© 2016 Disney). A destroyer and the Death Star from Lucasfilm’s Rogue One: A Star Wars Story (© & ™ 2016 Lucasfilm Ltd. All rights reserved. Used under authorization.) Pixar’s RenderMan renderer is used to render all of Pixar’s films, and by many 1 INTRODUCTION film studios to render visual effects for live-action movies. RenderMan started Pixar’s movies and short films are all rendered with RenderMan. as a scanline renderer based on the Reyes algorithm, and was extended over The first computer-generated (CG) animated feature film, Toy Story, the years with ray tracing and several global illumination algorithms. was rendered with an early version of RenderMan in 1995. The most This paper describes the modern version of RenderMan, a new architec- ture for an extensible and programmable path tracer with many features recent Pixar movies – Finding Dory, Cars 3, and Coco – were rendered that are essential to handle the fiercely complex scenes in movie production. using RenderMan’s modern path tracing architecture. The two left Users can write their own materials using a bxdf interface, and their own images in Figure 1 show high-quality rendering of two challenging light transport algorithms using an integrator interface – or they can use the CG movie scenes with many bounces of specular reflections and materials and light transport algorithms provided with RenderMan. -

Getting Started (Pdf)
GETTING STARTED PHOTO REALISTIC RENDERS OF YOUR 3D MODELS Available for Ver. 1.01 © Kerkythea 2008 Echo Date: April 24th, 2008 GETTING STARTED Page 1 of 41 Written by: The KT Team GETTING STARTED Preface: Kerkythea is a standalone render engine, using physically accurate materials and lights, aiming for the best quality rendering in the most efficient timeframe. The target of Kerkythea is to simplify the task of quality rendering by providing the necessary tools to automate scene setup, such as staging using the GL real-time viewer, material editor, general/render settings, editors, etc., under a common interface. Reaching now the 4th year of development and gaining popularity, I want to believe that KT can now be considered among the top freeware/open source render engines and can be used for both academic and commercial purposes. In the beginning of 2008, we have a strong and rapidly growing community and a website that is more "alive" than ever! KT2008 Echo is very powerful release with a lot of improvements. Kerkythea has grown constantly over the last year, growing into a standard rendering application among architectural studios and extensively used within educational institutes. Of course there are a lot of things that can be added and improved. But we are really proud of reaching a high quality and stable application that is more than usable for commercial purposes with an amazing zero cost! Ioannis Pantazopoulos January 2008 Like the heading is saying, this is a Getting Started “step-by-step guide” and it’s designed to get you started using Kerkythea 2008 Echo. -

Sony Pictures Imageworks Arnold
Sony Pictures Imageworks Arnold CHRISTOPHER KULLA, Sony Pictures Imageworks ALEJANDRO CONTY, Sony Pictures Imageworks CLIFFORD STEIN, Sony Pictures Imageworks LARRY GRITZ, Sony Pictures Imageworks Fig. 1. Sony Imageworks has been using path tracing in production for over a decade: (a) Monster House (©2006 Columbia Pictures Industries, Inc. All rights reserved); (b) Men in Black III (©2012 Columbia Pictures Industries, Inc. All Rights Reserved.) (c) Smurfs: The Lost Village (©2017 Columbia Pictures Industries, Inc. and Sony Pictures Animation Inc. All rights reserved.) Sony Imageworks’ implementation of the Arnold renderer is a fork of the and robustness of path tracing indicated to the studio there was commercial product of the same name, which has evolved independently potential to revisit the basic architecture of a production renderer since around 2009. This paper focuses on the design choices that are unique which had not evolved much since the seminal Reyes paper [Cook to this version and have tailored the renderer to the specic requirements of et al. 1987]. lm rendering at our studio. We detail our approach to subdivision surface After an initial period of co-development with Solid Angle, we tessellation, hair rendering, sampling and variance reduction techniques, decided to pursue the evolution of the Arnold renderer indepen- as well as a description of our open source texturing and shading language components. We also discuss some ideas we once implemented but have dently from the commercially available product. This motivation since discarded to highlight the evolution of the software over the years. is twofold. The rst is simply pragmatic: software development in service of lm production must be responsive to tight deadlines CCS Concepts: • Computing methodologies → Ray tracing; (less the lm release date than internal deadlines determined by General Terms: Graphics, Systems, Rendering the production schedule). -

Production Global Illumination
CIS 497 Senior Capstone Design Project Project Proposal Specification Instructors: Norman I. Badler and Aline Normoyle Production Global Illumination Yining Karl Li Advisor: Norman Badler and Aline Normoyle University of Pennsylvania ABSTRACT For my project, I propose building a production quality global illumination renderer supporting a variety of com- plex features. Such features may include some or all of the following: texturing, subsurface scattering, displacement mapping, deformational motion blur, memory instancing, diffraction, atmospheric scattering, sun&sky, and more. In order to build this renderer, I propose beginning with my existing massively parallel CUDA-based pathtracing core and then exploring methods to accelerate pathtracing, such as GPU-based stackless KD-tree construction, and multiple importance sampling. I also propose investigating and possible implementing alternate GI algorithms that can build on top of pathtracing, such as progressive photon mapping and multiresolution radiosity caching. The final goal of this project is to finish with a renderer capable of rendering out highly complex scenes and anima- tions from programs such as Maya, with high quality global illumination, in a timespan measuring in minutes ra- ther than hours. Project Blog: http://yiningkarlli.blogspot.com While competing with powerhouse commercial renderers 1. INTRODUCTION like Arnold, Renderman, and Vray is beyond the scope of this project, hopefully the end result will still be feature- Global illumination, or GI, is one of the oldest rendering rich and fast enough for use as a production academic ren- problems in computer graphics. In the past two decades, a derer suitable for usecases similar to those of Cornell's variety of both biased and unbaised solutions to the GI Mitsuba render, or PBRT. -

The Design and Evolution of the Uberbake Light Baking System
The design and evolution of the UberBake light baking system DARIO SEYB∗, Dartmouth College PETER-PIKE SLOAN∗, Activision Publishing ARI SILVENNOINEN, Activision Publishing MICHAŁ IWANICKI, Activision Publishing WOJCIECH JAROSZ, Dartmouth College no door light dynamic light set off final image door light only dynamic light set on Fig. 1. Our system allows for player-driven lighting changes at run-time. Above we show a scene where a door is opened during gameplay. The image on the left shows the final lighting produced by our system as seen in the game. In the middle, we show the scene without the methods described here(top).Our system enables us to efficiently precompute the associated lighting change (bottom). This functionality is built on top of a dynamic light setsystemwhich allows for levels with hundreds of lights who’s contribution to global illumination can be controlled individually at run-time (right). ©Activision Publishing, Inc. We describe the design and evolution of UberBake, a global illumination CCS Concepts: • Computing methodologies → Ray tracing; Graphics system developed by Activision, which supports limited lighting changes in systems and interfaces. response to certain player interactions. Instead of relying on a fully dynamic solution, we use a traditional static light baking pipeline and extend it with Additional Key Words and Phrases: global illumination, baked lighting, real a small set of features that allow us to dynamically update the precomputed time systems lighting at run-time with minimal performance and memory overhead. This ACM Reference Format: means that our system works on the complete set of target hardware, ranging Dario Seyb, Peter-Pike Sloan, Ari Silvennoinen, Michał Iwanicki, and Wo- from high-end PCs to previous generation gaming consoles, allowing the jciech Jarosz. -

On Dean W. Arnold's Writing . . . UNKNOWN EMPIRE Th E True Story of Mysterious Ethiopia and the Future Ark of Civilization “
On Dean W. Arnold’s writing . UNKNOWN EMPIRE T e True Story of Mysterious Ethiopia and the Future Ark of Civilization “I read it in three nights . .” “T is is an unusual and captivating book dealing with three major aspects of Ethiopian history and the country’s ancient religion. Dean W. Arnold’s scholarly and most enjoyable book sets about the task with great vigour. T e elegant lightness of the writing makes the reader want to know more about the country that is also known as ‘the cradle of humanity.’ T is is an oeuvre that will enrich our under- standing of one of Africa’s most formidable civilisations.” —Prince Asfa-Wossen Asserate, PhD Magdalene College, Cambridge, and Univ. of Frankfurt Great Nephew of Emperor Haile Selassie Imperial House of Ethiopia OLD MONEY, NEW SOUTH T e Spirit of Chattanooga “. chronicles the fascinating and little-known history of a unique place and tells the story of many of the great families that have shaped it. It was a story well worth telling, and one well worth reading.” —Jon Meacham, Editor, Newsweek Author, Pulitzer Prize winner . THE CHEROKEE PRINCES Mixed Marriages and Murders — Te True Unknown Story Behind the Trail of Tears “A page-turner.” —Gordon Wetmore, Chairman Portrait Society of America “Dean Arnold has a unique way of capturing the essence of an issue and communicating it through his clear but compelling style of writing.” —Bob Corker, United States Senator, 2006-2018 Former Chairman, Senate Foreign Relations Committee THE WIZARD AND THE LION (Screenplay on the friendship between J.