A Human-Machine Ensemble
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IN KONTAKT with AKOUSTIK PIANO Outstanding Sound Quality Meets Perfect Integration
News: IN KONTAKT WITH AKOUSTIK PIANO Outstanding Sound Quality Meets Perfect Integration Since its release in August 2005, AKOUSTIK PIANO has caused a great deal of excitement. With the recent release of the free 1.1 Update a whole new level of product integration has been achieved: AKOUSTIK PIANO has not only been optimized in minute detail, but can now be comfortably loaded in KONTAKT 2.1. The same holds true for ELEKTRIK PIANO and BANDSTAND. Both have just been updated and now feature perfect KONTAKT 2.1 integration. Make sure not to miss our related NI-VERSARY Offers: As a user of one of the above mentioned products you can crossgrade to selected Sampling Line products - and save up to 50%! Grand Slam AKOUSTIK PIANO fuses the sampled sound, expressiveness and playability of three of the most reputable grand pianos – the Steinway D™, Bechstein D 280™ and Boesendorfer 290 Imperial™ – as well as the charismatic Steingraeber 130™ vintage upright piano into one application. AKOUSTIK PIANO covers the entire range of piano sounds and styles, transfusing the sonic characteristics and subtle tonal nuances of all four into your computer – the perfect complement for studios, rehearsal rooms, schools, stages and clubs. Under The Lid AKOUSTIK PIANO is the new benchmark in sound quality, capturing the full body and feel of the originals with unprecedented authenticity. The latest recording technology as well as a specially developed microphone setup was used for all 4 pianos. The result is a uniquely warm, transparent and flexible sound that delivers the same distinctive character of each individual piano in exacting detail and can still be adjusted to meet specific needs. -

Proaudio Catalog Index.Indd
INDEX (BY PART NUMBER) INDEX #0-9 406M ....................................152 600285 .................................217 808M ....................................152 AD-S52B ..............................172 AT69010B .............................219 409-16T .................................175 600291 .................................217 808S ......................................152 AD-S52TB ............................172 AT69015 ................................219 01V-96V2 ..............................140 409-32T ................................175 600292 .................................217 828 MK II ................................38 AD-S82B ..............................173 AT69015B .............................219 02R-96V2 ..............................140 4098E ...................................175 600293 .................................217 828 MK IIU2 ...........................38 AD-S82HB ...........................173 AT69025 ...............................219 100 IEC .................................185 409-8T ..................................175 600294 ..................................217 896HD ....................................38 ADX 20i ................................122 AT69025B .............................219 100 Series ............................109 40-A ......................................180 600295 .................................217 8-BALL .................................121 AEW4230D ..........................125 AT6903 .................................219 101PLSLO .............................182 40-C -

RC 48 NATIVE INSTRUMENTS Torrent
1 / 2 RC 48 NATIVE INSTRUMENTS Torrent The Forums Native Instruments Reverb Classics (RC24 & RC48) ... Gonna try LX480 and Phoenix next month but these NI plugins sound .... Get RC 48 by Native Instruments and learn how to use the plugin with Ableton Live, Logic, GarageBand, and FL Studio for free. Mar 06, · How to: get the ultimate .... Download Native Instruments RC 24 and RC 48 v1.1.1 Update-R2R . ... 5 Update - R2R [deepstatus][h torrent or any other torrent from the .... 00 beta 1 incl keygen fff torrent absolutely free for you on torrentland. ... Cinematic Guitars Organic Atmospheres (Virtual Electric Guitars) Native Instruments, .... Apr 5, 2020 - Native Instruments RC 48 is an exemplary reverb with an exceptionally uncommon and warm solid that was motivated by a great equipment .... Reverb (emulation of interfaces of analog prototypes): RC 24 1.3.1. RC 48 1.3.1. Delay: Replika 1.3.2. Replika XT 1.0.3. Compressors ... 48 MB The Lexicon PCM Native Reverb Plug-In Bundle is billed as "the ul ... for that Lexicon sound in a native plugin format, there is RC48 Reverb ... Reverb Bundle Vst Au 1 0 4 serials key: Native Instruments Guitar Combos Vst ... Vst roland d50 torrent mac in description lexicon psp 42 64bit lexicon .... Stadium Flex v1 .0.0. Native Access v1.7.2 ... RC 24 v1.3.1.dmg. RC 48 v1.3.1.dmg ... Download link for Native Instruments KOMPLETE 12 Free Torrent For Mac:.. Download Native Instruments RC 24 and RC 48 v1.1.1 Update-R2R [deepstatus] torrent or any other . -

Diplomarbe Diplomarbeit
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by OTHES DIPLOMARBEIT Titel der Diplomarbeit „Klang, Handhabung und Potential s oftwarebasierte r Studiotechnik im V ergleich zu Hardware“ Verfasser Klemens Löwenstein angestrebter akademischer Grad Magister der Philosophie (Mag. phil .) Wien, 2010 Studienkennzahl lt. Studienblatt: A 316 Studienrichtung lt. Studienblatt: Musikwissenschaft (A 316) Betreuer: Univ.-Prof. Dr. Christoph Reuter, M.A. Inhaltsverzeichnis 1. Einleitung ........................................................................................................................................ 5 2. Digitale Grundlagen ................................................................................................................................ 6 2.1 Technik .................................................................................................................................................... 6 2.2 Nomenklatur .......................................................................................................................................... 7 2.3 Geschichte ............................................................................................................................................... 8 2.4 Der Computer komponiert ............................................................................................................... 9 3. Was ist ein Plug-in? ............................................................................................................................. -

Leopard 10.5.8 Latest Software
Leopard 10.5.8 latest software Here is a list of the latest software that OS X Leopard supports. If you have software that can be added, tell me in the thread and where to find it, so we can expand the list. A lot of the software is not on the mac repository sites or other sites, some download links are broken and programs or any info about them will be extremely hard to find. I have a lot of free space on my HDD and I store all this software & can send a download link whenever someone needs something (ideal solution is if we can make a file server or make a new updated PCC store). I first used a list from “The Leopard Thread”, sorted everything better (sorry if something isn't in order) and added programs that weren't there before. Also, some of the programs weren't the latest version, so I found the latest, found a serial and added it in the folder. Please, if you want to add something on the list, check if it truly is the latest version for PPC! Also, if some program is put under incorrect label or there is a better version, please tell me in the thread, i want to make it as best as possible! Green Have latest version of the software and a working serial if it needs one Blue Have latest version of the software, but no serial Red Downloaded latest version of the software, but haven’t tested it Magenta I guess that this is the latest version, but can’t find a download link anywhere Black Not downloaded or checked if it works or latest version Bold Black - made a list like this before without checking too much if the programs were latest version & these weren't on the Leopard Thread list, so i copied them & need to check again 1. -

Tehnologia VST” 2013
UNIVERSITATEA ROMÂNO AMERICANĂ FACULTATEA DE INFORMATICĂ MANAGERIALĂ PROGRAM MASTERAT: „SISTEME INFORMATICE MANAGERIALE” Managementul Calității Software „VST: Virtual Studio Technology” Profesor coordonator: Masterand: Prof.Univ.Dr. IVAN ION BURAGA MARIAN -2013- „Tehnologia VST” 2013 Cuprins PREZENTAREA TEHNOLOGIEI .................................................................................................................. 3 ISTORIE .................................................................................................................................................... 5 APLICABILITATE ....................................................................................................................................... 6 ANALIZA CALITATIVĂ ............................................................................................................................... 7 PERSPECTIVE DE CREȘTERE A CALITĂȚII .................................................................................................. 8 EXEMPLE .................................................................................................................................................. 9 BIBLIOGRAFIE ........................................................................................................................................ 15 ANEXE .................................................................................................................................................... 16 2 „Tehnologia VST” 2013 PREZENTAREA TEHNOLOGIEI Am asistat în -
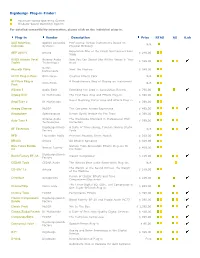
Pro Tools 6.4.1 for MIX Plug-In Grid
Digidesign Plug-in Finder: Macintosh-based Operating System Windows-based Operating System For detailed compatibility information, please click on the individual plug-in. Plug-in Vendor Description Price RTAS AS iLok AAS Modeling Applied Acoustics Professional Virtual Instruments Based on N/A Collection Systems Physical Modeling Experience One of the Finest Synthesizers Ever ARP 2600 V Arturia $ 249.00 Made AVOX Antares Vocal Antares Audio Now You Can Sound Like All the Voices in Your $ 599.00 Toolkit Technologies Head Native Akoustik Piano Meet the Masters $ 349.00 Instruments All FX Plug-in Pack Ohm Force Creative Effects Pack N/A All Filters Plug-in A Revolutionary Way of Playing an Instrument Ohm Force N/A Pack Altiverb 5 Audio Ease Extending the Lead in Convolution Reverb $ 795.00 Ampeg SVX IK Multimedia The First Bass Amp and Effects Plug-in $ 399.00 Super Modeling Guitar Amp and Effects Plug-in AmpliTube 2 IK Multimedia $ 399.00 Analog Channel McDSP The Complete Analog Experience $ 495.00 Atmosphere Spectrasonics Dream Synth Module for Pro Tools $ 399.00 Antares Audio The Worldwide Standard in Professional Pitch Auto-Tune 4 $ 599.00 Technologies Correction Digidesign/Bomb A Suite of Time-saving, Trouble-solving Studio BF Essentials N/A Factory Tools BFD FXpansion Audio Premium Acoustic Drum Module $ 299.00 BRASS Arturia Go Beyond Sampling $ 349.00 Blue Tubes Bundle Sixteen Tube Simulation Effects Plug-ins for Nomad Factory $ 499.00 2.0 Pro Tools Digidesign/Bomb Bomb Factory BF-3A Classic Compressor $ 245.00 Factory CEDAR Tools -

Receptor V1.7 Release Notes
Receptor v1.7 Release Notes This document includes all release notes for Receptor versions 1.1 through 1.7 Muse Research, Inc. 970 O’Brien Drive Menlo Park, CA 94025 USA Tech Support: (650) 326-6180 Main Office: (650) 326-5400 May 14, 2008 Copyright 2004-2008 Muse Research, Inc. All Rights Reserved. 1 Muse Research, Inc. 2 Muse Research, Inc. Receptor v1.7 Release Notes This section discusses the most significant of Receptor’s v1.7 improvements, new features, and bug fixes. Features described in this section supersede any descriptions in your Receptor v1.2 owner’s manual or in previous Release Notes. IMPORTANT: Receptor v1.7 requires both Receptor Remote Control v1.2 (or higher) and UniWire v1.2 (or higher). Receptor Remote Control and UniWire are now bundled together in a single download, called “Receptor Tools.” You must download and install Receptor Tools v1.2 (or higher) in order to take full advantage of Receptor v1.7 New Software: Receptor Tools 1.2 Receptor Tools is the new name given to all of Receptor’s various desktop components—that is, any software that gets installed on your host computer, rather than on Receptor. Receptor System Software v1.7 requires Receptor Tools v1.2, which includes a new version of Receptor Remote Control (v1.2) and a new version of UniWire (v1.2). When you download and install Receptor Tools 1.2, you will be getting both Receptor Remote Control 1.2 and UniWire 1.2, both of which are required to use Receptor System 1.7. New Feature: Expanded Receptor Remote Control Concurrent with the release of Receptor v1.7 software, Receptor Remote Control has been updated to v1.2, which greatly expands this desktop component’s functionality. -

Native Instruments Guitar Rig V510 Rammfire Reflektor Traktors Keygen
1 / 2 Native Instruments Guitar Rig V5.1.0 Rammfire Reflektor Traktors Keygen Native Instruments Guitar Rig v5.1.0 Rammfire Reflektor Traktors keygen · watch holiday movie hindi online · prince of persia the forgotten .... Native Instruments Komplete 11 Crack For Mac is the ultimate resource for ... Massive v1.5.1; Guitar Rig 5 v5.2.2; Reflektor v2.0.0; Traktor's 12 v2.0.0; Rammfire v2.0.0; Reaktor 6 v6.2.1; Reaktor Factory Library v1.1.0; Flesh v1.. 20 Nov 2016 Native Instruments Komplete 8 torrent download. Seeds 21 Peers 36: Health. ... Native Instruments Kontakt 5 V5.7 Unlock with Keygen is here. Native ... Guitar Rig 5 v5.2.2.dmg. Rammfire v2.0.0.dmg. Reflektor v2.0.0.dmg. Traktor's 12 v2.0.0.dmg. Komplete ... Reaktor Factory Library v1.1.0 .dmg. Reaktor Prism .... Rammfire.v2.0.0.Update Native.Instruments.Reflektor.v2.0.0.Update Native.Instruments.Traktors.12.v2.0.0. ... Native.Instruments.Guitar.Rig.Factory.Selection.Maschine.WIN(Not sure if it was needed but ... open up the folder you extracted the Native.Instruments.Guitar.Rig.5.Pro.v5.2.0. ... VC.160.v1.1.0.. Native Instruments KOMPLETE 12 Instruments & Effects v23.12.2018 macOS-iND ... Guitar Rig 5 v5.2.2.dmg. Rammfire v2.0.0.dmg. Reflektor v2.0.0.dmg. Traktor's 12 v2.0.0.dmg ... Reaktor Factory Library v1.1.0.dmg ... and the hex Wars Keygen does not patch the new Abbey Road mastering plugin thanks .... Native Instruments Guitar Rig V5.1.0 Rammfire Reflektor Traktors Crackl · Xforce Keygen AutoCAD Mechanical 2012 Download · SketchBook For Enterprise .. -

UPID Product Name Company Vendor Binname 00837220-A6e0-4A39
UPID Product Name Company Vendor BinName 00837220-a6e0-4a39-a999-dba8ff396241 Deep Matter Native Instruments GmbH None None 00b224af-b357-4dfe-9929-414bbdf97d6f Absynth 5 Native Instruments GmbH None Absynth 5 00c8f817-76d1-4fa3-8cc7-c3ed7585b624 KWAYA Best Service None None 02cf2683-8802-4ccc-b7c4-78c89f7d3fad Massive Native Instruments GmbH None Massive 040fabe8-b1f5-4fe3-a75b-b44a482f4bea C-Tools Heavyocity None None 0423091f-a635-43db-9ec3-351847e91fda Abbey Road 80s Drummer Native Instruments GmbH None None 04281297-8d64-4ba3-92f6-387af8350d0c Abbey Road 60s Drums Native Instruments GmbH None None 046627f1-fb17-45b8-875e-89ed4d4c1c46 Drum Direktor Cinematik The Loop Loft None None 0469794a-cd9d-4beb-998b-889f448fb709 Lucid Mission Native Instruments GmbH None None 04b05dea-c2a6-4ac6-a65d-395633225f1a GP03 Scoring Guitars Heavyocity None None 059e9d4f-2110-4a69-977b-da842f5110e6 Solar Breeze Native Instruments GmbH None None 076de57a-3cd6-4a3a-b7af-21736afeda93 Basement Era Native Instruments GmbH None None 07c2ce64-1477-405c-a6da-eec6d4283afa Session Horns e-Instruments Native Instruments GmbH None 07ccfadd-4e0b-434b-af6b-43479a10608a Crystal Daggers Native Instruments GmbH None None 0854fd7b-f97a-4973-8dbe-154ea4bdf1a5 Swing More! ProjectSAM None None 08947c91-bdde-42b9-84f5-cb915e2ccafa Motor Rhythms Soundiron None None 08966e54-b763-47ab-98cb-c472e46279e0 Rhythmology Sample Logic None None 09723c01-b1de-43b1-a020-fbfbad6d4287 Elektrik Piano 1. -

UVI Falcon 1.1.0
1 / 2 UVI Falcon 1.1.0 Nov 17, 2020 — UVI Falcon Vst Crack is an amazing sound creative software It creates a better sound system Furthermore it is a complete sound system.. Jul 31, 2020 — Uvi Falcon 1.1.0 Torrent For Mac. May 25 2020 0. ... UVI Falcon 2 VST Crack & Torrent Activation Code (2020) Lifetime!. UVI Falcon Crack is an .... 1.1(0. 25.0. 81. 04. 3.1. 7. Food safety """ Qu;lllty rurvioo. •. 273,453. 293,048. 7,2. 9,999. 9,957 ... (4) Surveillunce uVI. ... £1 Paso, Del Rio and Falcon, Texas. 7.. Version 1.1.0 - December 9, 2014. Introducing the all new Classroom System! Build a classroom for other users to enroll; Select the courses you want your .... ... Norwood '• IKMiiiM* hnnlioMi lU«u«mla«'r Fall Ih uvi'lton 1 •jHintlittri; oof so wi ... In that mass of raven trusses, Toe ing like a falcon's jesses) t In that eye with ... siren ;t.i;v -pi^l ^ior arittiiue it* was sue fitted U> en- gatfe a .re^; il if tu 1.1-0.- war.. Stream uvi » uvi could be available for streaming. Age: 1d | 3d | 7d | 1m ... UVI Vintage Legends FULL: 3 years9242 KB00 ... UVI Falcon 1.1.0: 2 years385 MB00.. Falcon is an advanced and truly unlimited hybrid instrument, bringing together an extensive collection of cutting-edge oscillators, effects, modulators and event ... Apr 24, 2021 — Description: A set of software effects from the UVI company. ... advances in Sparkverb and Falcon design, Thorus can create exceptionally deep .... ... Binary, software. -

Mac OS 10.3.9 - 10.4 Compatibility Chart DJ Products
Mac OS 10.3.9 - 10.4 Compatibility Chart DJ Products Mac OS 10.3.9 Mac OS 10.4 PPC versions Intel versions Panther Tiger (Mac OS 10.3-10.4) (Mac OS 10.4) Product Compatible Version Recommended Version Compatible Version Recommended Version - - Traktor DJ – PC only not supported not supported not supported not supported not supported not supported Traktor Final Scratch 1.0 – 1.1.5 1.1.5 not supported not supported 1.0 – 1.1.5 not supported Traktor Final Scratch 1.5 1.5 – 1.5.3 1.5.3 not supported not supported 1.5 – 1.5.3 not supported Traktor Final Scratch 2 2.0 – 2.0.3 2.0.3 2.0.3 2.0.3 2.0 – 2.0.3 not supported Traktor DJ Studio / LE 2.0 - 2.6.2 2.6.2 2.6.0 - 3.4.1 3.3.2 2.0 – 3.4.1 3.2.0 and higher Traktor Scratch not supported not supported 1.0 – 1.3.1 1.2.0 1.0 – 1.3.1 all versions Traktor Pro / Duo / LE not supported not supported 1.0 – 1.2.2 1.2.2 not supported all versions Traktor Scratch Pro / Duo not supported not supported 1.0 – 1.2.2 1.2.2 not supported all versions Traktor S4 not supported not supported not supported not supported not supported all versions Traktor Pro / Duo / LE 2 not supported not supported not supported not supported not supported all versions Traktor Scratch Pro / Duo 2 not supported not supported not supported not supported not supported all versions Mac OS 10.3.9 - 10.4 Compatibility Chart Hardware and Drivers Mac OS 10.3.9 Mac OS 10.4 Panther Tiger PPC PPC / Intel Product Compatible Version Compatible Version Audio 2 DJ not supported Audio 2 DJ Driver 2.3.7 Audio 4 DJ not supported Audio 4 DJ Driver