Inside Macintosh: Text Describes How You Can Use That Support to Put Superior Text Capabilities Into Your Software
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Thoughts on Flash
Apple has a long relationship with Adobe. In fact, we met Adobe’s founders when they were in their proverbial garage. Apple was their first big customer, adopting their Postscript language for our new Laserwriter printer. Apple invested in Adobe and owned around 20% of the company for many years. The two companies worked closely together to pioneer desktop publishing and there were many good times. Since that golden era, the companies have grown apart. Apple went through its near death experience, and Adobe was drawn to the corporate market with their Acrobat products. Today the two companies still work together to serve their joint creative customers – Mac users buy around half of Adobe’s Creative Suite products – but beyond that there are few joint interests. I wanted to jot down some of our thoughts on Adobe’s Flash products so that customers and critics may better understand why we do not allow Flash on iPhones, iPods and iPads. Adobe has characterized our decision as being primarily business driven – they say we want to protect our App Store – but in reality it is based on technology issues. Adobe claims that we are a closed system, and that Flash is open, but in fact the opposite is true. Let me explain. First, there’s “Open”. Adobe’s Flash products are 100% proprietary. They are only available from Adobe, and Adobe has sole authority as to their future enhancement, pricing, etc. While Adobe’s Flash products are widely available, this does not mean they are open, since they are controlled entirely by Adobe and available only from Adobe. -

Stylewriter II 1992.Pdf
~ ., ('D ~ (/)~ .........~ 0... t ('D • •.• , .: ... .. .. --;, .. :. ....;. -~·~ ;-·-·: ~'"1\l; 1 r,• .;"':· :· ,,.!\.._.,.,1.. .:~"· 1.. ·1. ~ · : '. •,\ . : (t~~ .... ~... ~}'°.... '_.;•)·l~ -~'"st-if.~ ~,. ·! ..ti.. -.. r. ,::-.~ },.... :r1'··'} .~~\;.tot"' '" ·'~ ' -·:/' "·~ ~ ......\':!...·, .. -;,.lo :"< ,,.~:.--. ·~·;.~·."it~·,, . ;,-~>l'!"y.. ... .·;:~~;~t;l - ..-r:.~!.'-~ (tl jf:· -~";t''!f.{: . ·;.,. .. - 14~:.... / " .v;; .. <) ?~ ~-..~ ~,,... ~ { "~·-~ r-J~1 ~-.;:r~i: ~~~ ; .. .J,-:.;~~~·;1.)~ ;~·~::t:!{.1i..~: -~. ti Apple Computer, Inc. Apple, the Apple logo, AppleTalk, LaserWriter, Macintosh, MuhiFinder, and StyleWriter are trademarks of Apple Computer, Inc., registered in che U.S. and other countries. This manual and the software described in it are copyrighted, with all rights reserved. Balloon Help, Finder, and Syscem 7 arc trademarks of Apple Computer, Inc. Under the copyright laws, this manual or the software may not be copied, in whole or pan, without written consent of Apple, except in the normal use of the software or to Adobe, Adobe Illustrator, and PostScript are trademarks of Adobe Systems Incorporated, make a backup copy of the software. The same proprietary and copyright notices must registered in the United States. Adobe Photoshop is a trademark of Adobe Systems be affixed to any permitted copies as were affixed to che original. This excepcion does Incorporated. not allow copies to be made for ochers, whether or noc sold, but all of the macerial Exposure is a registered trademark of Preferred Publishers, Inc. purchased (with all backup copies) may be sold, given, or loaned to another person. Under the law, copying includes translacing into another language or format. ITC Zapf Dingbats is a registered trademark of Internacional lypcface Corporal ion. You may use the software on any compmer owned by you, but extra copies cannot be MacPaint is a registered trademark of Claris Corporation. -

Keyboards for Mac Computers
Keyboards For Mac Computers 1 / 5 Keyboards For Mac Computers 2 / 5 3 / 5 Currently, Apple offers only three keyboards via Bluetooth: Magic Keyboard (silver only), and Magic Keyboard with Numeric Keypad (silver or space gray).. The Apple Keyboard is a keyboard designed by Apple Inc First for the Apple line, then the Macintosh line of computers. 1. keyboards computers 2. colorful keyboards computers 3. creative keyboard computer Slide the switch to turn on the device (green coloring becomes visible) Earlier Apple Wireless Keyboard models have a power button on the right side of the device.. Connectivity Options: Wired and Wireless The simplest way to connect a wired keyboard to your PC.. Slide the switch to turn on the device On the Magic Mouse, the green LED briefly lights up.. Your device isn't recognized by your MacFollow these steps if your mouse, keyboard, or trackpad isn't recognized by your Mac.. Make sure that your device has been set up to work with your MacLearn how to pair your Magic Mouse 2, Magic Keyboard, Magic Keyboard with Numeric Keypad, Magic Trackpad 2 and earlier models of Apple wireless devices with your Mac. keyboards computers keyboards computers, flat keyboards computers, colorful keyboards computers, left handed keyboards computers, creative keyboard computer, small keyboards computers, best keyboards computers, cool keyboards computers, keyboards for apple computers, cute keyboards for computers, computer science keyboards, keyboards for computers at walmart, keyboards canada computers, keyboards for computers at best buy, keyboards for computers amazon, keyboards for computers usb Rtl8211bl Drivers For Mac Dozens of models have been released over time, including the Apple Extended Keyboard. -

ISO Basic Latin Alphabet
ISO basic Latin alphabet The ISO basic Latin alphabet is a Latin-script alphabet and consists of two sets of 26 letters, codified in[1] various national and international standards and used widely in international communication. The two sets contain the following 26 letters each:[1][2] ISO basic Latin alphabet Uppercase Latin A B C D E F G H I J K L M N O P Q R S T U V W X Y Z alphabet Lowercase Latin a b c d e f g h i j k l m n o p q r s t u v w x y z alphabet Contents History Terminology Name for Unicode block that contains all letters Names for the two subsets Names for the letters Timeline for encoding standards Timeline for widely used computer codes supporting the alphabet Representation Usage Alphabets containing the same set of letters Column numbering See also References History By the 1960s it became apparent to thecomputer and telecommunications industries in the First World that a non-proprietary method of encoding characters was needed. The International Organization for Standardization (ISO) encapsulated the Latin script in their (ISO/IEC 646) 7-bit character-encoding standard. To achieve widespread acceptance, this encapsulation was based on popular usage. The standard was based on the already published American Standard Code for Information Interchange, better known as ASCII, which included in the character set the 26 × 2 letters of the English alphabet. Later standards issued by the ISO, for example ISO/IEC 8859 (8-bit character encoding) and ISO/IEC 10646 (Unicode Latin), have continued to define the 26 × 2 letters of the English alphabet as the basic Latin script with extensions to handle other letters in other languages.[1] Terminology Name for Unicode block that contains all letters The Unicode block that contains the alphabet is called "C0 Controls and Basic Latin". -

Unicode and Code Page Support
Natural for Mainframes Unicode and Code Page Support Version 4.2.6 for Mainframes October 2009 This document applies to Natural Version 4.2.6 for Mainframes and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © Software AG 1979-2009. All rights reserved. The name Software AG, webMethods and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA, Inc. Other company and product names mentioned herein may be trademarks of their respective owners. Table of Contents 1 Unicode and Code Page Support .................................................................................... 1 2 Introduction ..................................................................................................................... 3 About Code Pages and Unicode ................................................................................ 4 About Unicode and Code Page Support in Natural .................................................. 5 ICU on Mainframe Platforms ..................................................................................... 6 3 Unicode and Code Page Support in the Natural Programming Language .................... 7 Natural Data Format U for Unicode-Based Data ....................................................... 8 Statements .................................................................................................................. 9 Logical -

Apple Has Built a Solution Into Every Mac
Overview Mac OS X iPhone iPod + iTunes Resources Vision Mac OS X solutions VoiceOver from third parties. Browse the wide variety of To make it easier for the blind and those with low-vision to use a accessibility solutions supported computer, Apple has built a solution into every Mac. Called VoiceOver, by Mac OS X. Learn more it’s reliable, simple to learn, and enjoyable to use. In Depth Device Support Application Support Downloads VoiceOver Application Support VoiceOver. A unique solution for the vision-impaired. Every new Mac comes with Mac OS X and VoiceOver installed and includes a variety of accessible More than 50 reasons to use applications. You can also purchase additional Apple and third-party applications to use with VoiceOver. VoiceOver. Learn more While this page lists a few of the most popular applications, many more are available. If you use an application with VoiceOver that’s not on this list, and you would like to have it added, send email to [email protected]. Unlike traditional screen readers, VoiceOver is integrated into the operating system, so you can start using new accessible applications right away. You don’t need to buy an update to VoiceOver, install a new copy, or add the application to a “white list.” Moreover, VoiceOver commands work the same way in every application, so once you learn how to use them, you’ll be able to apply what you know to any accessible application. Apple provides developers with a Cocoa framework that contains common, reusable application components (such as menus, text fields, buttons, and sliders), so developers don’t have to re-create these elements each time they write a new application. -

IJCNLP 2011 Proceedings of the Workshop on Advances in Text Input Methods (WTIM 2011)
IJCNLP 2011 Proceedings of the Workshop on Advances in Text Input Methods (WTIM 2011) November 13, 2011 Shangri-La Hotel Chiang Mai, Thailand IJCNLP 2011 Proceedings of the Workshop on Advances in Text Input Methods (WTIM 2011) November 13, 2011 Chiang Mai, Thailand We wish to thank our sponsors Gold Sponsors www.google.com www.baidu.com The Office of Naval Research (ONR) Department of Systems Engineering and The Asian Office of Aerospace Research and Devel- Engineering Managment, The Chinese Uni- opment (AOARD) versity of Hong Kong Silver Sponsors Microsoft Corporation Bronze Sponsors Chinese and Oriental Languages Information Processing Society (COLIPS) Supporter Thailand Convention and Exhibition Bureau (TCEB) We wish to thank our sponsors Organizers Asian Federation of Natural Language National Electronics and Computer Technolo- Processing (AFNLP) gy Center (NECTEC), Thailand Sirindhorn International Institute of Technology Rajamangala University of Technology Lanna (SIIT), Thailand (RMUTL), Thailand Chiang Mai University (CMU), Thailand Maejo University, Thailand c 2011 Asian Federation of Natural Language Proceesing vii Preface Welcome to the IJCNLP Workshop on Advances in Text Input Methods (WTIM 2011)! Methods of text input have entered a new era. The number of people who have access to computers and mobile devices is skyrocketing in regions where people do not have a convenient method of inputting their native language. It has also become commonplace to input text not through a keyboard but through different modes such as voice and handwriting recognition. Even when people input text using a keyboard, it is done differently from only a few years ago – adaptive software keyboards, word auto- completion and prediction, and spell correction are just a few examples of such recent changes in text input experience. -

NCSA Telnet for the Macintosh User's Guide
NCSA Telnet for the Macintosh User’s Guide Version 2.6 • October 1994 National Center for Supercomputing Applications University of Illinois at Urbana-Champaign Contents Introduction Features of NCSA Telnet v Differences between Version 2.5 and Version 2.6 v New Features in Version 2.6 v Discontinued Features vi Bugs Fixed from Version 2.5 vi System Requirements vi Notational Conventions vi 1 Getting Started Installation Note 1-1 Beginning an NCSA Telnet Session 1-1 Opening and Closing a Connection 1-2 Opening a Connection 1-2 Logging on to Your Host 1-3 Setting the BACKSPACE/DELETE Key 1-3 Setting a VT Terminal Type 1-3 Emulating the VT Terminal Keyboard 1-4 Closing a Connection 1-4 Copying, Pasting, and Printing 1-5 Copy and Paste from the Edit Menu 1-5 Print from the File Menu 1-5 Ending an NCSA Telnet Session 1-6 2 Configuration Global Preferences 2-1 New Configuration System in Version 2.6 2-3 Default Configuration Records 2-3 Editing Configuration Records 2-3 Editing Terminal Configuration Records 2-4 Editing Session Configuration Records 2-5 Changing Configuration after Session Connected 2-9 Saved Sets 2-13 Saving a Set 2-14 Using a Saved Set 2-14 Loading a Saved Set 2-15 Macro Definitions 2-15 Reverting to Previous Macro Definitions 2-16 Saving Macros 2-16 3 Advanced Features Cursor Positioning with the Mouse 3-1 Multiple Connections 3-1 Opening More Than One Connection 3-1 Moving between Connections 3-1 Rules for Session Names 3-2 The Connections Menu 3-2 Naming Windows 3-2 Checking Session Status 3-2 Aborting Connection Attempts -
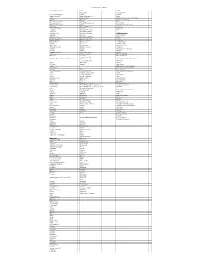
Software List (1-3-2017)
Software List (1-3-2017) Information Commons BU 104 LLCD Adobe Flash Academic online JVC Pro HD Manager Chrome Acrobat Adobe Reader DC Adobe Photoshop CS6 Adobe Itunes Adobe Reader XI Comprehensive Medical Terminology Maple 16 Drive M:\ Glencoe Keyboarding Microsoft Office 2016 Firefox Itunes Microsoft Publisher Irwin/GDP Keyboarding Kurzeil 3000 MS visual studio 2015 Itunes Microsoft Office Suite 2007 Quicktime Kurzweil 3000 v.12 Quick time SPSS for Windows Maple 16 Skills bank real player Microsoft Office 2016 Vista 3-Scanners MS platform installer Windows 7 & 10 Microsoft Visio 2016 Wellington Center sharepoint MS SQL Internet Explorer XPS viewer MS Visual Studio 2015 ITunes Express for desktop Quicken deluxe 2014 McAfee Express for Web VLC Media Player Quicktime MS silverlight Windows 10 " " Media Player Statdisk Scanner Mozilla Firefox Skype 2016 MS silverlight Adobe Reader XI windows dvd maker wolfram cdf player Windows 8 Onedrive Filezilla Microsoft Office Suite 2013 notepad++ Gimp 2 Maple 16 respounds/lockdown opera mobile emulator Statdisk 3D builder VM ware/ vsphere Wolfram CDF Player MS Azure wire shark VLC Media Player cisco packet tracker MACS Software (Information Commons) 3D builder Brunswick Front Desk Computers java development kit Windows 7 System project 2016 Adobe 9 Developer notepad++ Apple Itunes Utilities IBM Iseries access for windows Time Machine Intel Management and Security TextEdit UC 222 Iseries navigator System Preferences Acrobat Reader XI Malware Bytes Anti Malware Stickies Adult Clinical Simulation Mcaffe -

Pooch Manual In
What’s New As of August 21, 2011, Pooch is updated to version 1.8.3 for use with OS X 10.7 “Lion”: Pooch users can renew their subscriptions today! Please see http://daugerresearch.com/pooch for more! On November 17, 2009, Pooch was updated to version 1.8: • Linux: Pooch can now cluster nodes running 64-bit Linux, combined with Mac • 64-bit: Major internal revisions for 64-bit, particularly updated data types and structures, for Mac OS X 10.6 "Snow Leopard" and 64-bit Linux • Sockets: Major revisions to internal networking to adapt to BSD Sockets, as recommended by Apple moving forward and required for Linux • POSIX Paths: Major revisions to internal file specification format in favor of POSIX paths, recommended by Apple moving forward and required for Linux • mDNS: Adapted usage of Bonjour service discovery to use Apple's Open Source mDNS library • Pooch Binary directory: Added Pooch binary directory support, making possible launching jobs using a remotely-compiled executable • Minor updates and fixes needed for Mac OS X 10.6 "Snow Leopard" Current Pooch users can renew their subscriptions today! Please see http://daugerresearch.com/pooch for more! On April 16, 2008, Pooch was updated to version 1.7.6: • Mac OS X 10.5 “Leopard” spurs updates in a variety of Pooch technologies: • Network Scan window • Preferences window • Keychain access • Launching via, detection of, and commands to the Terminal • Behind the Login window behavior • Other user interface and infrastructure adjustments • Open MPI support: • Complete MPI support using libraries -

Introduction to Apple Events 3
CHAPTER 3 Introduction to Apple Events 3 This chapter introduces Apple events and the Apple Event Manager. Later chapters describe how your application can use the Apple Event Manager to respond to and send Apple events, locate Apple event objects, and record Apple events. The interapplication communication (IAC) architecture for Macintosh computers consists of five parts: the Edition Manager, the Open Scripting Architecture (OSA), the Apple Event Manager, the Event Manager, and the Program-to-Program Communications (PPC) Toolbox. The chapter “Introduction to Interapplication Communication” in this book provides an overview of the relationships among these parts. The Apple Event Registry: Standard Suites defines both the actions performed by the standard Apple events, or “verbs,” and the standard Apple event object classes, which can be used to create “noun phrases” describing objects on which Apple events act. If your application uses the Apple Event Manager to respond to some of these standard Apple events, you can make it scriptable—that is, capable of responding to scripts written in a scripting language such as AppleScript. In addition, your application can 3 use the Apple Event Manager to create and send Apple events and to allow user actions Introduction to Apple Events in your application to be recorded as Apple events. Before you use this chapter or any of the other chapters about the Apple Event Manager, you should be familiar with the chapters “Event Manager” in Inside Macintosh: Macintosh Toolbox Essentials and “Process Manager” in Inside Macintosh: Processes. This chapter begins by describing Apple events and some of the data structures they contain. -

Latex on Macintosh
LaTeX on Macintosh Installing MacTeX and using TeXShop, as described on the main LaTeX page, is enough to get you started using LaTeX on a Mac. This page provides further information for experienced users. Tips for using TeXShop Forward and Inverse Search If you are working on a long document, forward and inverse searching make editing much easier. • Forward search means jumping from a point in your LaTeX source file to the corresponding line in the pdf output file. • Inverse search means jumping from a line in the pdf file back to the corresponding point in the source file. In TeXShop, forward and inverse search are easy. To do a forward search, right-click on text in the source window and choose the option "Sync". (Shortcut: Cmd-Click). Similarly, to do an inverse search, right-click in the output window and choose "Sync". Spell-checking TeXShop does spell-checking using Apple's built in dictionaries, but the results aren't ideal, since TeXShop will mark most LaTeX commands as misspellings, and this will distract you from the real misspellings in your document. Below are two ways around this problem. • Use the spell-checking program Excalibur which is included with MacTeX (in the folder / Applications/TeX). Before you start spell-checking with Excalibur, open its Preferences, and in the LaTeX section, turn on "LaTeX command parsing". Then, Excalibur will ignore LaTeX commands when spell-checking. • Install CocoAspell (already installed in the Math Lab), then go to System Preferences, and open the Spelling preference pane. Choose the last dictionary in the list (the third one labeled "English (United States)"), and check the box for "TeX/LaTeX filtering".