Szekeres Washington 0250E 2
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hacking the Web
Hacking the Web (C) 2009-2020 Arun Viswanathan Ellis Horowitz Marco Papa 1 Table of Contents } General Introduction } Authentication Attacks } Client-Side Attacks } Injection Attacks } Recent Attacks } Privacy Tools 2 (C) 2009-2020 Arun Viswanathan Ellis Horowitz Marco Papa Why secure the Web? } The Web has evolved into an ubiquitous entity providing a rich and common platform for connecting people and doing business. } BUT, the Web also offers a cheap, effective, convenient and anonymous platform for crime. } To get an idea, the Web has been used for the following types of criminal activities (source: The Web Hacking Incidents Database (WHID) http://projects.webappsec.org/w/page/13246995/Web-Hacking-Incident-Database) } Chaos (Attack on Russian nuclear power websites amid accident rumors (5Jan09) } Deceit (SAMY XSS Worm – Nov 2005) } Extortion (David Aireys domain hijacked due to a CSRF (cross site request forgery) flaw in Gmail – 30Dec2007) } Identity Theft (XSS on Yahoo! Hot jobs – Oct 2008) } Information Warfare (Israeli Gaza War - Jan 2009 / Balkan Wars – Apr 2008 ) } Monetary Loss (eBay fraud using XSS) } Physical Pain (Hackers post on epilepsy forum causes migraines and seizures – May 2008) } Political Defacements (Hacker changes news release on Sheriffs website – Jul 2008) (Obama, Oreilly and Britneys Twitter accounts hacked and malicious comments posted – Jan 09) } Chinese Gaming sites hacked (Dec. 2011) 3 Copyright(C) 2009 (c) -20092020- 2019Arun Arun Viswanathan Viswanathan Ellis HorowitzEllis Horowitz Marco Marco Papa Papa -

Improved Density-Based Spatio–Textual Clustering on Social Media
SUBMITTED TO IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING 1 Improved Density-Based Spatio–Textual Clustering on Social Media Minh D. Nguyen and Won-Yong Shin, Senior Member, IEEE Abstract—DBSCAN may not be sufficient when the input data type is heterogeneous in terms of textual description. When we aim to discover clusters of geo-tagged records relevant to a particular point-of-interest (POI) on social media, examining only one type of input data (e.g., the tweets relevant to a POI) may draw an incomplete picture of clusters due to noisy regions. To overcome this problem, we introduce DBSTexC, a newly defined density-based clustering algorithm using spatio–textual information. We first characterize POI-relevant and POI-irrelevant tweets as the texts that include and do not include a POI name or its semantically coherent variations, respectively. By leveraging the proportion of POI-relevant and POI-irrelevant tweets, the proposed algorithm demonstrates much higher clustering performance than the DBSCAN case in terms of F1 score and its variants. While DBSTexC performs exactly as DBSCAN with the textually homogeneous inputs, it far outperforms DBSCAN with the textually heterogeneous inputs. Furthermore, to further improve the clustering quality by fully capturing the geographic distribution of tweets, we present fuzzy DBSTexC (F-DBSTexC), an extension of DBSTexC, which incorporates the notion of fuzzy clustering into the DBSTexC. We then demonstrate the robustness of F-DBSTexC via intensive experiments. The computational complexity of our algorithms is also analytically and numerically shown. Index Terms—Density-based clustering, fuzzy clustering, geo-tagged tweet, point-of-interest (POI), spatio–textual information. -

Securing Information in a Mobile World
Securing Information in a Mobile World Thu, Jan 21 | 2:00 p.m. – 3:30 p.m. PRESENTED BY: Charlie LeBlanc, William Figures, and Blad Slavens Schedulers & Dispatchers Conference | Tampa, FL | January 19 – 22, 2016 A Brief History of Computing and Software for Schedulers and Dispatchers Systems in the 80’s and early 90’s were computer- centric and pretty secure…. Why ????? And then came the Internet !!!! Highly technical description of the Internet “The Internet is a data network that connects “everything” together” (kind of like the phone system !) - William Figures 2007 The ‘Net(work) as a computing platform- Using WEB Services WEB SERVICES=FARS Is it safe to use public Wi-Fi? 6 Security challenges when using public Wi-Fi Some things to know about public Wi-Fi hotspots • Unlike your home Wi-Fi access point, most public Wi-Fi hotspots at hotels, restaurants, coffee shops, airports, etc. do not use encrypted communication. • This means that all your data may be sent in clear-text across the wireless network. Anyone with a “sniffer” could then snoop on your connection. • In order to secure their Wi-Fi properly, a business owner would have to issue a password to connect to the hotspot. To be truly secure, this password would be unique to a single person. • Since this isn’t feasible, you need to take other precautions to secure your data when using a public hotspot. Sources: http://www.networkworld.com/article/2904439/wi-fi/is-it-safe-to-use-public-wi-fi-networks.html 7 Case Study: Firesheep browser extension Coder exposed risk to Facebook users at public hotspots • To call attention to glaring security vulnerabilities with both Facebook – and other sites – and public Wi-Fi, a “white hat” hacker developed a Firefox extension that allowed a user to hijack the Facebook account of anyone logged into the same Wi-Fi hotspot. -

Anatomy of Data Breaches and Its Impact on Security
International Journal of Science and Research (IJSR) ISSN (Online): 2319-7064 Index Copernicus Value (2013): 6.14 | Impact Factor (2013): 4.438 Anatomy of Data Breaches and Its Impact on Security Anshu1, Monika Sharma2 1M.Tech Scholar, Computer Science Department, TIT & S, Bhiwani, India 2Assistant Professor, Information Technology Department, TIT & S, Bhiwani, India Abstract: In cloud computing, the word cloud is used as a metaphor for "the Internet," so the phrase cloud computing means "a type of Internet-based computing," where different services - such as servers, storage and applications -- are delivered to an organization's computers and devices through the Internet [14]. Every user access cloud services through internet without knowing the security aspects. Today security threats are increasing rapidly and data breach is top of them. Breach in the security of any component in the cloud can be both disaster for the organization and the provider. In this research paper we focus on main security issue in cloud like data breach, different forms of data breaches and how it occurs in cloud. It also explore where major breaches occur in cloud in past years. Keywords: cloud, data breaches, security 1. Data Breaches two categories i.e. accidental breach or intentional breach The term data breach means when an unauthorized user or a) Accidental breach: also called as employee error when hacker or an attacker attacks an authorized data, access or an employee by mistake sends data to wrong receipts, retrieves it by an individual or service without the and by not understanding security protocols and permission. A data breach results in loss of sensitive, procedures. -

Darpa Starts Sleuthing out Disloyal Troops
UNCLASSIFIED (U) FBI Tampa Division CI Strategic Partnership Newsletter JANUARY 2012 (U) Administrative Note: This product reflects the views of the FBI- Tampa Division and has not been vetted by FBI Headquarters. (U) Handling notice: Although UNCLASSIFIED, this information is property of the FBI and may be distributed only to members of organizations receiving this bulletin, or to cleared defense contractors. Precautions should be taken to ensure this information is stored and/or destroyed in a manner that precludes unauthorized access. 10 JAN 2012 (U) The FBI Tampa Division Counterintelligence Strategic Partnership Newsletter provides a summary of previously reported US government press releases, publications, and news articles from wire services and news organizations relating to counterintelligence, cyber and terrorism threats. The information in this bulletin represents the views and opinions of the cited sources for each article, and the analyst comment is intended only to highlight items of interest to organizations in Florida. This bulletin is provided solely to inform our Domain partners of news items of interest, and does not represent FBI information. In the JANUARY 2012 Issue: Article Title Page NATIONAL SECURITY THREAT NEWS FROM GOVERNMENT AGENCIES: American Jihadist Terrorism: Combating a Complex Threat p. 2 Authorities Uncover Increasing Number of United States-Based Terror Plots p. 3 Chinese Counterfeit COTS Create Chaos For The DoD p. 4 DHS Releases Cyber Strategy Framework p. 6 COUNTERINTELLIGENCE/ECONOMIC ESPIONAGE THREAT ITEMS FROM THE PRESS: United States Homes In on China Spying p. 6 Opinion: China‟s Spies Are Catching Up p. 8 Canadian Politician‟s Chinese Crush Likely „Sexpionage,‟ Former Spies Say p. -

NAVIGATING the CYBERSECURITY STORM
NAVIGATING the CYBERSECURITY STORM A Guide for Directors and Officers BY PAUL A. FERRILLO EDITED BY BILL BROWN published by sponsored by sponsored by 1 © 2015 by Paul A. Ferrillo. All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopy, recording, or any other information storage or retrieval system without prior written permission. To use the information contained in this book for a greater purpose or application, contact Paul A. Ferrillo via [email protected] 2 Is your company protected from the Internet of RiskSM? With CyberEdge® cyber insurance solutions you can enjoy the Business Opportunity of Things. 20 billion objects are connected to the Internet, what everyone is calling the Internet of Things. This hyperconnectivity opens the door both to the future of things, and to greater network vulnerabilities. CyberEdge end-to-end cyber risk management solutions are designed to protect your company from this new level of risk. So that you can turn the Internet of Things into the next big business opportunity. To learn more and download the free CyberEdge Mobile App, visit www.AIG.com/CyberEdge Insurance, products and services are written or provided by subsidiaries or affiliates of American International Group, Inc. Insurance and services may not be available in all jurisdictions, and coverage is subject to actual policy language. For additional information, please visit our website at www.AIG.com. ABOUT PAUL A. FERRILLO Paul Ferrillo is counsel in Weil’s Litigation Department, where he focuses on complex securities and business litigation, and internal investigations. -

Ethical Hacking
Ethical Hacking Alana Maurushat University of Ottawa Press ETHICAL HACKING ETHICAL HACKING Alana Maurushat University of Ottawa Press 2019 The University of Ottawa Press (UOP) is proud to be the oldest of the francophone university presses in Canada and the only bilingual university publisher in North America. Since 1936, UOP has been “enriching intellectual and cultural discourse” by producing peer-reviewed and award-winning books in the humanities and social sciences, in French or in English. Library and Archives Canada Cataloguing in Publication Title: Ethical hacking / Alana Maurushat. Names: Maurushat, Alana, author. Description: Includes bibliographical references. Identifiers: Canadiana (print) 20190087447 | Canadiana (ebook) 2019008748X | ISBN 9780776627915 (softcover) | ISBN 9780776627922 (PDF) | ISBN 9780776627939 (EPUB) | ISBN 9780776627946 (Kindle) Subjects: LCSH: Hacking—Moral and ethical aspects—Case studies. | LCGFT: Case studies. Classification: LCC HV6773 .M38 2019 | DDC 364.16/8—dc23 Legal Deposit: First Quarter 2019 Library and Archives Canada © Alana Maurushat, 2019, under Creative Commons License Attribution— NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) https://creativecommons.org/licenses/by-nc-sa/4.0/ Printed and bound in Canada by Gauvin Press Copy editing Robbie McCaw Proofreading Robert Ferguson Typesetting CS Cover design Édiscript enr. and Elizabeth Schwaiger Cover image Fragmented Memory by Phillip David Stearns, n.d., Personal Data, Software, Jacquard Woven Cotton. Image © Phillip David Stearns, reproduced with kind permission from the artist. The University of Ottawa Press gratefully acknowledges the support extended to its publishing list by Canadian Heritage through the Canada Book Fund, by the Canada Council for the Arts, by the Ontario Arts Council, by the Federation for the Humanities and Social Sciences through the Awards to Scholarly Publications Program, and by the University of Ottawa. -

Dragnet Surveillance Nation How Data Brokers Sold out America
Dragnet Surveillance Nation How Data Brokers Sold Out America January 2017 Author: James Scott (Senior Fellow – Institute for Critical Infrastructure Technology) 1 Contents Introduction - Corporate Dragnet Surveillance Has Brought Adversaries “Home to Roost” ................... 3 Information is Power ................................................................................................................................ 5 The Next-Generation of Hybrid Information Warfare Is Here .................................................................. 9 The Product is “You” ............................................................................................................................... 11 Americans Are Targeted More Successfully because America Lags Behind Global Privacy Initiatives .. 12 Who Are Data Brokers? .......................................................................................................................... 15 Problem 1: Data Brokers Operate in the Shadows ................................................................................. 19 Where Do Brokers Acquire Data? ....................................................................................................... 21 Problem 2: Fact: Data Brokers are Historically Negligent ....................................................................... 29 ChoicePoint (2004, 2006) .................................................................................................................... 29 Dun & Bradstreet, LexisNexis , and Kroll Background -

Lecture 2 Attacks from the Real World
ENEE 457: Computer Systems Security 8/29/18 Lecture 2 Attacks from the Real World Charalampos (Babis) Papamanthou Department of Electrical and Computer Engineering University of Maryland, College Park Attacks in the real world Dropbox data loss • Problem: Not sufficient back-ups • How can you prevent this? • ERROR CORRECTING CODES Error correcting codes • Given blocks b1,b2,…,bn, we want to store them with redundancy • If we just duplicate them and store copies c1,c2,…,cn, it is no good. The attacker can just delete 2 blocks (e.g., b1 and c1) and cause damage • Alternatively, consider the polynomial p(x) = (x – b1 )(x – b2 )…(x – bn) • Store b1,b2,…,bn and p(r1),p(r2),…,p(rn) for random r1,r2,…,rn • Now even if the attacker deletes any n – 1 out of 2n blocks that we have stored, we can always recover our initial data • How? Polynomial interpolation! • As long as n + 1 out of 2n points are stored intact, we can always recover the initial data LinkedIn passwords leaked • In June 2012, it was announced that almost 6.5 million LinkedIn passwords were leaked and posted on a hacker site • http://www.huffingtonpost.com/2012/06/07/linkedin-password-hack- check_n_1577184.html • Problem: Linkedin did not use salt when hashing the passwords! • http://www.stormpath.com/blog/how-linkedin-could-have-secured-hacked-passwords • How can you prevent this? • ALWAYS USE SALT (when using salting, one cannot use preexisting tables to crack passwords easily) Teaser question about passwords • Can you log into Google without sending your password over? • Zero-knowledge -

Studio Ed Analisi Dell'information Security Nelle Organizzazioni: Casi A
Dipartimento di Impresa e Management Cattedra: Organizzazione dei sistemi informativi aziendali Studio ed analisi dell’information security nelle organizzazioni: casi a confronto RELATORE CANDIDATO Prof. Paolo Spagnoletti Giuseppe Catone 177161 ANNO ACCADEMICO 2014/2015 1 2 Sommario Abstract ............................................................................................................................................... 5 1. La sicurezza nelle organizzazioni. Aspetti generali. .............................................................. 7 2. Background teorico .................................................................................................................... 13 2.1 Incident risk analysis. ................................................................................................................ 13 2.2 TFI model. ................................................................................................................................... 16 2.3 Bilanciamento strategico tra prevenzione e risposta. ............................................................ 19 3. Analisi dei casi. ............................................................................................................................ 26 3.1 Metodi e finalità di ricerca ....................................................................................................... 26 3.2 Caso uno: TJX Companies, Inc. ............................................................................................... 27 3.3 Caso due: Target -
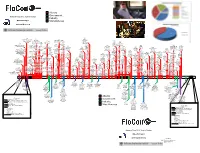
Network Flow 2012: Year in Review Industry @Geowarnagiris Miscellaneous [email protected]
Attacks Government Network Flow 2012: Year in Review Industry @GeoWarnagiris Miscellaneous [email protected] 6/7 1/17 2/4 4/1 Last.fm Justin Beiber’s web site 403 NASA Utah Dept. of Heath warns 40M hacked 200 accts 2/26 8/3 usernames and 500K personal records users to 8/9 dumped 2/10 UN (UNEP) Mat passwds posted 4/16 change pass Utah cia.gov DB leaked Honan’s 1/15 2/3 US Gov & LE computerized taken 3/31 digital life zappos.com customer Conf call re: Anon DDoS 6/6 1.5M 7/19 signs hacked 9/21 12/4 12/21 down 2/26 PBS hacked 4/29 destroyed details accessed between FBI and eHarmony $80K in Nike 8/21 USDA Swiss National Council on Wikileaks publishes 4/12 Yahoo and 5/28 9/18 10/25 Scotland Yard leaked passwd merchandise 8/9 Moscow defaced security agency Foreign 1/12 2/8 Stratfor emails 3/30 Another AOL email Flame 8/2 US Bank Israeli National 11/23 hashes stolen via Battle.net Court web warns of large Relations AlienVault releases Westboro Baptist 3/12 GlobalPayments FBI/MI6 breached announced MLB DDoSes network Some 2/2 dumped web site bug hacked site hacked 9/4 secret data leak poisoned details of Sykipot trojan taken down BBC announce call Facebook begin 9/26 disconnects GoDaddy Susan G. Komen for 5/26 Bitfloor 11/8 variant targeting 2/14 Persian breach 50k - leaked - 2 6/5 hijacked by Telvent 10/11 from civilian DNS hijacked 12/3 the Cure hacked U. -

Personal Information As an Attack Vector: Why Privacy Should Be an Operational Dimension of U.S
Personal Information as an Attack Vector: Why Privacy Should Be an Operational Dimension of U.S. National Security² Christopher K. Dearing* INTRODUCTION ..................................................... 352 I. HISTORICAL OVERVIEW OF PRIVACY LAW ......................... 354 II. ªTECHNOLOGICAL SOMNAMBULISMº ......................... 363 III. THE ECHO CHAMBER OF U.S. GOVERNMENT AND INDUSTRY INFORMATION PRACTICES ...................................... 366 IV. PERSONAL INFORMATION AS AN ATTACK VECTOR. 372 V. THE ªNEW NORMALº ................................... 375 A. Sony Pictures Entertainment ........................ 375 B. Yahoo Email .................................... 377 C. Starwood Guest Reservation Database. 377 D. Ransomware .................................... 378 E. Of®ce of Personnel Management Data Breach. 379 VI. FUTURE ATTACK VECTORS & APPROACHES ....................... 380 A. Vignette 1. Espionage, Counterintelligence, and Statecraft . 384 B. Vignette 2. In¯uence Operations ..................... 384 C. Vignette 3. Preparing the Battlespace . 385 D. Vignette 4. Attacks on Personal Information as a Force Multiplier in War. ................................ 387 VII. RECOMMENDATIONS. .......................................... 387 A. Privacy as an Operational Dimension of U.S. National Security ........................................ 390 1. Congressional Committees on Cybersecurity and Personal Information. .......................... 390 ² An attack vector is a pathway or means by which a hostile actor may gain unauthorized