Rapid Classification of TESS Planet Candidates with Convolutional
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Detection and Characterization of Hot Subdwarf Companions of Massive Stars Luqian Wang
Georgia State University ScholarWorks @ Georgia State University Physics and Astronomy Dissertations Department of Physics and Astronomy 8-13-2019 Detection And Characterization Of Hot Subdwarf Companions Of Massive Stars Luqian Wang Follow this and additional works at: https://scholarworks.gsu.edu/phy_astr_diss Recommended Citation Wang, Luqian, "Detection And Characterization Of Hot Subdwarf Companions Of Massive Stars." Dissertation, Georgia State University, 2019. https://scholarworks.gsu.edu/phy_astr_diss/119 This Dissertation is brought to you for free and open access by the Department of Physics and Astronomy at ScholarWorks @ Georgia State University. It has been accepted for inclusion in Physics and Astronomy Dissertations by an authorized administrator of ScholarWorks @ Georgia State University. For more information, please contact [email protected]. DETECTION AND CHARACTERIZATION OF HOT SUBDWARF COMPANIONS OF MASSIVE STARS by LUQIAN WANG Under the Direction of Douglas R. Gies, PhD ABSTRACT Massive stars are born in close binaries, and in the course of their evolution, the initially more massive star will grow and begin to transfer mass and angular momentum to the gainer star. The mass donor star will be stripped of its outer envelope, and it will end up as a faint, hot subdwarf star. Here I present a search for the subdwarf stars in Be binary systems using the International Ultraviolet Explorer. Through spectroscopic analysis, I detected the subdwarf star in HR 2142 and 60 Cyg. Further analysis led to the discovery of an additional 12 Be and subdwarf candidate systems. I also investigated the EL CVn binary system, which is the prototype of class of eclipsing binaries that consist of an A- or F-type main sequence star and a low mass subdwarf. -
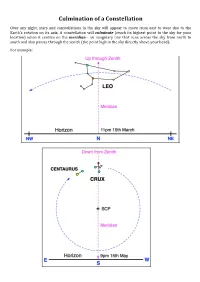
Culmination of a Constellation
Culmination of a Constellation Over any night, stars and constellations in the sky will appear to move from east to west due to the Earth’s rotation on its axis. A constellation will culminate (reach its highest point in the sky for your location) when it centres on the meridian - an imaginary line that runs across the sky from north to south and also passes through the zenith (the point high in the sky directly above your head). For example: When to Observe Constellations The taBle shows the approximate time (AEST) constellations will culminate around the middle (15th day) of each month. Constellations will culminate 2 hours earlier for each successive month. Note: add an hour to the given time when daylight saving time is in effect. The time “12” is midnight. Sunrise/sunset times are rounded off to the nearest half an hour. Sun- Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec Rise 5am 5:30 6am 6am 7am 7am 7am 6:30 6am 5am 4:30 4:30 Set 7pm 6:30 6pm 5:30 5pm 5pm 5pm 5:30 6pm 6pm 6:30 7pm And 5am 3am 1am 11pm 9pm Aqr 5am 3am 1am 11pm 9pm Aql 4am 2am 12 10pm 8pm Ara 4am 2am 12 10pm 8pm Ari 5am 3am 1am 11pm 9pm Aur 10pm 8pm 4am 2am 12 Boo 3am 1am 11pm 9pm 7pm Cnc 1am 11pm 9pm 7pm 3am CVn 3am 1am 11pm 9pm 7pm CMa 11pm 9pm 7pm 3am 1am Cap 5am 3am 1am 11pm 9pm 7pm Car 2am 12 10pm 8pm 6pm Cen 4am 2am 12 10pm 8pm 6pm Cet 4am 2am 12 10pm 8pm Cha 3am 1am 11pm 9pm 7pm Col 10pm 8pm 4am 2am 12 Com 3am 1am 11pm 9pm 7pm CrA 3am 1am 11pm 9pm 7pm CrB 4am 2am 12 10pm 8pm Crv 3am 1am 11pm 9pm 7pm Cru 3am 1am 11pm 9pm 7pm Cyg 5am 3am 1am 11pm 9pm 7pm Del -

Subgiants As Probes of Galactic Chemical Evolution
Astronomy & Astrophysics manuscript no. Thoren September 9, 2018 (DOI: will be inserted by hand later) Subgiants as probes of galactic chemical evolution ⋆, ⋆⋆, ⋆⋆⋆ Patrik Thor´en, Bengt Edvardsson and Bengt Gustafsson Department of Astronomy and Space Physics, Uppsala Astronomical Observatory, Box 515, S-751 20 Uppsala, Sweden Received 12 March 2004 / Accepted 28 May 2004 Abstract. Chemical abundances for 23 candidate subgiant stars have been derived with the aim at exploring their usefulness for studies of galactic chemical evolution. High-resolution spectra from ESO CAT-CES and NOT- SOFIN covered 16 different spectral regions in the visible part of the spectrum. Some 200 different atomic and molecular spectral lines have been used for abundance analysis of ∼ 30 elemental species. The wings of strong, pressure-broadened metal lines were used for determination of stellar surface gravities, which have been compared with gravities derived from Hipparcos parallaxes and isochronic masses. Stellar space velocities have been derived from Hipparcos and Simbad data, and ages and masses were derived with recent isochrones. Only 12 of the stars turned out to be subgiants, i.e. on the “horizontal” part of the evolutionary track between the dwarf- and the giant stages. The abundances derived for the subgiants correspond closely to those of dwarf stars. With the possible exceptions of lithium and carbon we find that subgiant stars show no “chemical” traces of post-main-sequence evolution and that they are therefore very useful targets for studies of galactic chemical evolution. Key words. stars:abundances – stars:evolution – galaxy:abundances – galaxy:evolution 1. Introduction The volume is limited by the low luminosities of the dwarfs used in the surveys, and by the limited view in cer- Abundance patterns in stellar populations have proven to tain directions through the galactic disk. -

$ E^\Pm $ Excesses in the Cosmic Ray Spectrum and Possible Interpretations
November 6, 2018 14:34 WSPC/INSTRUCTION FILE electron-positron International Journal of Modern Physics D c World Scientific Publishing Company e± Excesses in the Cosmic Ray Spectrum and Possible Interpretations Yi-Zhong Fan Department of Physics and Astronomy, University of Nevada, Las Vegas, NV 89119, USA; Purple Mountain Observatory, Chinese Academy of Sciences, 210008, Nanjing, China Bing Zhang Department of Physics and Astronomy, University of Nevada, Las Vegas, NV 89119, USA Jin Chang Purple Mountain Observatory, Chinese Academy of Sciences, 210008, Nanjing, China Received Day Month Year Revised Day Month Year Communicated by Managing Editor The data collected by ATIC, PPB-BETS, FERMI-LAT and HESS all indicate that there is an electron/positron excess in the cosmic ray energy spectrum above ∼ 100 GeV, although different instrumental teams do not agree on the detailed spectral shape. PAMELA also reported a clear excess feature of the positron fraction above several GeV, but no excess in anti-protons. Here we review the observational status and theoretical models of this interesting observational feature. We pay special attention to various physical interpretations proposed in the literature, including modified supernova rem- nant models for the e± background, new astrophysical sources, and new physics (the dark matter models). We suggest that although most models can make a case to inter- pret the data, with the current observational constraints the dark matter interpretations, especially those invoking annihilation, require much more exotic assumptions than some astrophysical interpretations. Future observations may present some “smoking-gun” ob- servational tests to differentiate among different models and to identify the correct in- arXiv:1008.4646v1 [astro-ph.HE] 27 Aug 2010 terpretation to the phenomenon. -

Kinematics of Hipparcos Visual Binaries. I. Stars Whit Orbital Solutions
Baltic Astronomy, vol. 10, 481-587, 2001. KINEMATICS OF HIPPARCOS VISUAL BINARIES. I. STARS WITH ORBITAL SOLUTIONS * A. Bartkevicius and A. Gudas Institute of Theoretical Physics and Astronomy, Gostauto 12, Vilnius 2600, Lithuania Received June 15, 2001. Abstract. A sample consisting of 570 binary systems is compiled from several sources of visual binary stars with well-known orbital elements. High-precision trigonometric parallaxes (mean relative er- ror about 5%) and proper motions (mean relative error about 3%) are extracted from the Hipparcos Catalogue or from the reprocessed Hipparcos data. However, 13% of the sample stars lack radial ve- locity measurements. Computed galactic velocity components and other kinematic parameters are used to divide the sample stars into kinematic age groups. The majority (89%) of the sample stars, with known radial velocities, are the thin disk stars, 9.5% binaries have thick disk kinematics and only 1.4% are halo stars. 85% of thin disk binaries are young or medium age stars and almost 15% are old thin disk stars. There is an urgent need to increase the number of the iden- tified halo binary stars with known orbits and substantially improve the situation with their radial velocity data. Key words: stars: binaries: visual, kinematics - Galaxy: popula- tion - orbiting observatories: Hipparcos 1. INTRODUCTION The importance of the investigation of binary stars for under- standing stellar formation and evolution is well-known and described by many authors (cf. Duquennoy & Mayor 1991, Larson 2000). Bi- nary stars are the only source for the direct determination of stellar * Based on the data from the Hipparcos astrometry satellite, ESA 482 A. -

Standard Photometric Systems
7 Aug 2005 11:27 AR AR251-AA43-08.tex XMLPublishSM(2004/02/24) P1: KUV 10.1146/annurev.astro.41.082801.100251 Annu. Rev. Astron. Astrophys. 2005. 43:293–336 doi: 10.1146/annurev.astro.41.082801.100251 Copyright c 2005 by Annual Reviews. All rights reserved STANDARD PHOTOMETRIC SYSTEMS Michael S. Bessell Research School of Astronomy and Astrophysics, The Australian National University, Weston, ACT 2611, Australia; email: [email protected] KeyWords methods: data analysis, techniques: photometric, spectroscopic, catalogs ■ Abstract Standard star photometry dominated the latter half of the twentieth century reaching its zenith in the 1980s. It was introduced to take advantage of the high sensitivity and large dynamic range of photomultiplier tubes compared to photographic plates. As the quantum efficiency of photodetectors improved and the wavelength range extended further to the red, standard systems were modified and refined, and deviations from the original systems proliferated. The revolutionary shift to area detectors for all optical and IR observations forced further changes to standard systems, and the precision and accuracy of much broad- and intermediate-band photometry suffered until more suitable observational techniques and standard reduction procedures were adopted. But the biggest revolution occurred with the production of all-sky photometric surveys. Hipparcos/Tycho was space based, but most, like 2MASS, were ground-based, dedicated survey telescopes. It is very likely that in the future, rather than making a measurement of an object in some standard photometric system, one will simply look up the magnitudes and colors of most objects in catalogs accessed from the Virtual Observatory. -

Detection of Additional Be+ Sdo Systems from IUE Spectroscopy
Detection of additional Be+sdO systems from IUE spectroscopy Luqian Wang, Douglas R. Gies Center for High Angular Resolution Astronomy and Department of Physics and Astronomy, Georgia State University, P. O. Box 5060, Atlanta, GA 30302-5060, USA [email protected], [email protected] Geraldine J. Peters1 Space Sciences Center, University of Southern California, Los Angeles, CA 90089-1341, USA [email protected] ABSTRACT There is growing evidence that some Be stars were spun up through mass transfer in a close binary system, leaving the former mass donor star as a hot, stripped-down object. There are five known cases of Be stars with hot subd- warf (sdO) companions that were discovered through International Ultraviolet Explorer (IUE) spectroscopy. Here we expand the search for Be+sdO candi- dates using archival FUV spectra from IUE. We collected IUE spectra for 264 stars and formed cross-correlation functions (CCFs) with a model spectrum for a hot subdwarf. Twelve new candidate Be+sdO systems were found, and eight of these display radial velocity variations associated with orbital motion. The new plus known Be+sdO systems have Be stars with spectral subtypes of B0 to B3, and the lack of later-type systems is surprising given the large number of arXiv:1801.01066v1 [astro-ph.SR] 3 Jan 2018 cooler B-stars in our sample. We discuss explanations for the observed number and spectral type distribution of the Be+sdO systems, and we argue that there are probably many Be systems with stripped companions that are too faint for detection through our analysis. -

Download This Article in PDF Format
A&A 517, A24 (2010) Astronomy DOI: 10.1051/0004-6361/201014477 & c ESO 2010 Astrophysics Properties and nature of Be stars, 28. Implications of systematic observations for the nature of the multiple system with the Be star o Cassiopeæ and its circumstellar environment P. Koubský1,C.A.Hummel2,P.Harmanec3, C. Tycner4, F. van Leeuwen5,S.Yang6, M. Šlechta1,H.Božic´7, R. T. Zavala8,D.Ruždjak7, and D. Sudar7 1 Astronomical Institute, Academy of Sciences of the Czech Republic, 251 65 Ondrejov,ˇ Czech Republic e-mail: [email protected] 2 European Organisation for Astronomical Research in the Southern Hemisphere, Karl-Schwarzschild-Str. 2, 85748 Garching bei München, Germany 3 Astronomical Institute of the Charles University, Faculty of Mathematics and Physics, V Holešovickáchˇ 2, 180 00 Praha 8 - Troja, Czech Republic 4 Department of Physics, Central Michigan University, Mount Pleasant, MI 48859, USA 5 Institute of Astronomy, Madingley Road, Cambridge, UK 6 University of Victoria, Dept of Physics and Astronomy, PO Box 3055 Victoria, BC V8W 3P6, Canada 7 Hvar Observatory, Faculty of Geodesy, Zagreb University, Kacicevaˇ 26, 10000 Zagreb, Croatia 8 US Naval Observatory, Flagstaff Station, 10391 West Naval Observatory Road, Flagstaff, AZ 86001, USA Received 22 March 2010 / Accepted 19 April 2010 ABSTRACT The analysis of radial velocities of the Be star o Cas from spectra taken between 1992 and 2008 at the Ondrejovˇ Observatory and the Dominion Astrophysical Observatory allowed us to reconfirm the binary nature of this object, first suggested by Abt and Levy in 1978, but later refuted by several authors. -
The Science Cases for Building a Band 1 Receiver Suite for ALMA
The Science Cases for Building a Band 1 Receiver Suite for ALMA J. Di Francesco1;2, D. Johnstone1;2, B. Matthews1;2, N. Bartel3, L. Bronfman4, S. Casassus4, S. Chitsazzadeh2;5, H. Chou6, M. Cunningham7, G. Duch^ene8;9, J. Geisbuesch10, A. Hales11, P.T.P. Ho6 M. Houde5, D. Iono12, F. Kemper6, A. Kepley11, P.M. Koch6, K. Kohno13, R. Kothes10, S-P. Lai14, K.Y. Lin6, S.-Y. Liu6, B. Mason11, T.J. Maccarone15, N. Mizuno12, O. Morata6, G. Schieven1, A.M.M. Scaife16, D. Scott17, H. Shang6, M. Shimojo12, Y.-N. Su6, S. Takakuwa6, J. Wagg18;19, A. Wootten11, F. Yusef-Zadeh20 1National Research Council Canada, 5071 West Saanich Rd, Victoria, BC, V9E 2E7, Canada 2Dept. of Physics & Astronomy, University of Victoria, Victoria, BC, V8P 1A1, Canada 3Dept. of Physics and Astronomy, York University, Toronto, M3J 1P3, ON, Canada 4Dept. de Astronom´ıa,Universidad de Chile, Casilla 36-D, Santiago, Chile 5Dept. of Physics and Astronomy, The University of Western Ontario, London, ON, N6A 3K7, Canada 6Academia Sinica, Institute of Astronomy and Astrophysics, P.O. Box 23-141, Taipei 10617, Taiwan 7School of Physics, University of New South Wales, Sydney, NSW 20152, Australia 8Astronomy Dept., University of California, Berkeley, CA 94720-3411, USA 9Universit´eJoseph Fourier - Grenoble 1/CNRS, LAOG UMR 5571, BP 53, 38041 Grenoble, France 10National Research Council Canada, P.O. Box 248, Penticton, BC, V2A 6J9, Canada 11National Radio Astronomy Observatory, 520 Edgemont Road, Charlottesville, Virginia 22903, USA 12National Astronomical Observatory of Japan, 2-21-1 Osawa, Mitaka, Tokyo, 181-8588, Japan 13Institute of Astronomy, The University of Tokyo, 2-21-1 Osawa, Mitaka,Tokyo 181-0015, Japan 14Institute of Astronomy and Dept. -

1991Apj. . .369. .515R the Astrophysical Journal, 369:515-528
.515R The Astrophysical Journal, 369:515-528,1991 March 10 © 1991. The American Astronomical Society. All rights reserved. Printed in U.S.A. .369. 1991ApJ. CRITERIA FOR THE SPECTRAL CLASSIFICATION OF B STARS IN THE ULTRAVIOLET Janet Rountree1 and George Sonneborn2 Laboratory for Astronomy and Solar Physics, NASA/Goddard Space Flight Center Received 1990 May 24; accepted 1990 August 29 ABSTRACT We have developed a set of criteria for the classification of B stars from ultraviolet spectra alone, using MK standards drawn from the optical region. The observational material consists of archival high-dispersion spectra obtained by the SWP camera on the IUE spacecraft. The spectra were resampled to a resolution of 0.25 Â, normalized, and plotted on a uniform scale of 10 Â cm-1. Approximately 100 stars having normal MK spectral types in the range B0-B8, III-V, have been classified. Only photospheric absorption lines were used as classification criteria; the Si n and Si m spectra were found to be particularly useful. The C iv, Si iv, and N v lines, which in early B stars originate in the stellar wind, were not used in the two-dimensional spectral type/luminosity classification, but the appearance of these stellar wind lines was compared with the corresponding lines in the standard stars, and some anomalies were noted. On the whole, the ultraviolet spec- tral types are very consistent with the optical MK types, implying that it is possible to do two-dimensional spectral classification in the ultraviolet without any knowledge of the optical spectrum. Subject headings: stars: early-type — stars: spectral classification — ultraviolet: spectra 1. -

Microfilms International
IM w sity Microfilms International V lalj* 1.0 Itt _ to. y£ 22 £ b£ 2.0 1.1 UL 11.25 111 1.4 1.6 MICROCOPY RESOLUTION TEST CHART NATIONAL BUREAU OF STANDARDS STANDARD REFERENCE MATERIAL 1010a (ANSI and ISO TEST CHART No. 2) University Microfilms Inc. 300 N. Zeeb Road, Ann Arbor, MI 48106 INFORMATION TO USERS This reproduction was made from a copy of a manuscript sent to us for publication and microfilming. While the most advanced technology has been used to pho tograph and reproduce this manuscript, the quality of the reproduction is heavily dependent upon the quality of the material submitted. Pages in any manuscript may have indistinct print. In all cases the best available copy has been filmed. The following explanation of techniques is provided to help clarify notations which may appear on this reproduction. 1. Manuscripts may not always be complete. When it is not possible to obtain missing pages, a note appears to indicate this. 2. When copyrighted materials are removed from the manuscript, a note ap pears to indicate this. 3. Oversize materials (maps, drawings, and charts) are photographed by sec tioning the original, beginning at the upper left hand comer and continu ing from left to right in equal sections with small overlaps. Each oversize page is also filmed as one exposure and is available, for an additional charge, as a standard 35mm slide or in black and white paper format.4 4. Most photographs reproduce acceptably on positive microfilm or micro fiche but lack clarify on xerographic copies made from the microfilm. -

Transits and Occultations of an Earth-Sized Planet in an 8.5-Hour
Astrophysical Journal, IN PRESS Preprint typeset using LATEX style emulateapj v. 5/2/11 TRANSITS AND OCCULTATIONS OF AN EARTH-SIZED PLANET IN AN 8.5-HOUR ORBIT ROBERTO SANCHIS-OJEDA1,SAUL RAPPAPORT1, JOSHUA N. WINN1, ALAN LEVINE2, MICHAEL C. KOTSON3,DAVID W. LATHAM4,LARS A. BUCHHAVE5, 6 Accepted for publication, 2013 July 11 ABSTRACT We report the discovery of an Earth-sized planet (1.16 ± 0.19 R⊕) in an 8.5-hour orbit around a late G-type star (KIC 8435766, Kepler-78). The object was identified in a search for short-period planets in the Kepler database and confirmed to be a transiting planet (as opposed to an eclipsing stellar system) through the absence of ellipsoidal light variations or substantial radial-velocity variations. The unusually short orbital period and the relative brightness of the host star (mKep = 11.5) enable robust detections of the changing illuminationof the visible hemisphere of the planet, as well as the occultations of the planet by the star. We interpret these signals as representing a combination of reflected and reprocessed light, with the highest planet dayside temperature in the range of 2300 K to 3100 K. Follow-up spectroscopy combined with finer sampling photometric observations will further pin down the system parameters and may even yield the mass of the planet. Subject headings: planetary systems—planets and satellites: detection, atmospheres 1. INTRODUCTION case comes from perusing the list of the active Kepler Objects 7 The work described here was motivated by our curiosity of Interest (KOI) . In this list we find only 17 active planet about planets with the shortest possible orbital periods.