Neural Data-To-Text Generation with Dynamic Content Planning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

June 7 Redemption Update
SET SUBSET/INSERT # PLAYER 2019 Donruss Baseball Signature Series Pink Firework 27 Jonathan Loaisiga 2019 Donruss Baseball Signature Series Pink Firework 7 Michael Kopech 2019 Diamond Kings Baseball DK 205 Signatures 15 Michael Kopech 2019 Diamond Kings Baseball DK 205 Signatures Holo Silver 15 Michael Kopech 2019 Diamond Kings Baseball DK Material Signatures 36 Michael Kopech 2019 Diamond Kings Baseball DK Signatures 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures 36 Michael Kopech 2019 Diamond Kings Baseball DK Signatures Holo Blue 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Gold 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Silver 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Silver 36 Michael Kopech Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Purple 67 Yusei Kikuchi 2018 Chronicles Baseball Contenders Season Tickets Red 6 Gleyber Torres 2018 National Treasures Baseball Hometown Heroes 23 Aaron Judge 2018 National Treasures Baseball Hometown Heroes Platinum 23 Aaron Judge 2018 National Treasures Baseball Treasured Signatures 14 Aaron Judge 2018 National Treasures Baseball Treasured Signatures Platinum 14 Aaron Judge Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet 6 Johnny Bench Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet Holo Gold 6 Johnny Bench Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet Platinum 6 Johnny Bench 2013 Elite Extra Edition Baseball -

National Basketball Association Official
NATIONAL BASKETBALL ASSOCIATION OFFICIAL SCORER'S REPORT FINAL BOX 10/8/2012 ORACLE Arena, Oakland, CA Officials: #22 Bill Spooner, #40 Leon Wood, #72 JT Orr Time of Game: 2:03 Attendance: 14,571 VISITOR: Utah Jazz (0-1) NO PLAYER MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS PTS 2 Marvin Williams F 22:24 4 6 0 0 5 6 0 3 3 1 0 1 1 0 13 24 Paul Millsap F 20:36 4 7 1 1 4 7 2 4 6 1 3 1 2 0 13 25 Al Jefferson C 20:36 1 8 0 0 0 0 1 2 3 1 1 0 0 2 2 20 Gordon Hayward G 17:01 2 10 0 1 1 2 3 3 6 0 2 2 1 0 5 5 Mo Williams G 22:24 3 9 2 2 3 3 0 3 3 6 1 0 4 0 11 8 Randy Foye 16:21 0 6 0 2 0 0 0 1 1 3 1 0 0 2 0 0 Enes Kanter 24:19 5 12 0 0 2 2 3 8 11 1 1 0 0 2 12 15 Derrick Favors 22:28 4 7 0 0 0 0 1 1 2 0 0 0 4 0 8 6 Jamaal Tinsley 25:36 1 3 0 2 0 0 0 3 3 6 1 2 1 0 2 3 DeMarre Carroll 23:13 4 6 1 3 0 0 1 2 3 0 2 0 2 0 9 33 Darnell Jackson 4:56 0 1 0 0 0 0 0 1 1 0 2 0 2 0 0 10 Alec Burks 17:01 2 5 1 1 0 0 0 0 0 1 3 0 1 0 5 40 Jeremy Evans 3:05 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 19 Raja Bell DNP - Coach's Decision 31 Brian Butch DNP - Coach's Decision 23 Trey Gilder DNP - Coach's Decision 55 Kevin Murphy DNP - Coach's Decision 22 Chris Quinn DNP - Coach's Decision 11 Earl Watson NWT - Right Knee Rehab TOTALS: 30 80 5 12 15 20 11 32 43 20 17 6 18 6 80 PERCENTAGES: 37.5% 41.7% 75.0% TM REB: 13 TOT TO: 18 (17 PTS) HOME: GOLDEN STATE WARRIORS (2-0) NO PLAYER MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS PTS 4 Brandon Rush F 28:09 6 12 2 6 0 0 1 1 2 1 1 0 2 2 14 10 David Lee F 36:21 9 14 0 1 1 2 1 13 14 5 3 4 3 0 19 31 Festus Ezeli C 24:31 2 3 0 0 2 2 1 -

2019-20 Horizon League Men's Basketball
2019-20 Horizon League Men’s Basketball Horizon League Players of the Week Final Standings November 11 .....................................Daniel Oladapo, Oakland November 18 .................................................Marcus Burk, IUPUI Horizon League Overall November 25 .................Dantez Walton, Northern Kentucky Team W L Pct. PPG OPP W L Pct. PPG OPP December 2 ....................Dantez Walton, Northern Kentucky Wright State$ 15 3 .833 81.9 71.8 25 7 .781 80.6 70.8 December 9 ....................Dantez Walton, Northern Kentucky Northern Kentucky* 13 5 .722 70.7 65.3 23 9 .719 72.4 65.3 December 16 ......................Tyler Sharpe, Northern Kentucky Green Bay 11 7 .611 81.8 80.3 17 16 .515 81.6 80.1 December 23 ............................JayQuan McCloud, Green Bay December 31 ..................................Loudon Love, Wright State UIC 10 8 .556 70.0 67.4 18 17 .514 68.9 68.8 January 6 ...................................Torrey Patton, Cleveland State Youngstown State 10 8 .556 75.3 74.9 18 15 .545 72.8 71.2 January 13 ........................................... Te’Jon Lucas, Milwaukee Oakland 8 10 .444 71.3 73.4 14 19 .424 67.9 69.7 January 20 ...........................Tyler Sharpe, Northern Kentucky Cleveland State 7 11 .389 66.9 70.4 11 21 .344 64.2 71.8 January 27 ......................................................Marcus Burk, IUPUI Milwaukee 7 11 .389 71.5 73.9 12 19 .387 71.5 72.7 February 3 ......................................... Rashad Williams, Oakland February 10 ........................................ -

GAME NOTES for In-Game Notes and Updates, Follow Grizzlies PR on Twitter @Grizzliespr
GAME NOTES For in-game notes and updates, follow Grizzlies PR on Twitter @GrizzliesPR GRIZZLIES 2020-21 SCHEDULE/RESULTS Date Opponent Tip-Off/TV • Result 12/23 SAN ANTONIO L 119-131 MEMPHIS GRIZZLIES 12/26 ATLANTA L 112-122 12/28 @ Brooklyn W (OT) 116-111 END OF 2021 POSTSEASON GAME NOTES 12/30 @ Boston L 107-126 1/1 @ Charlotte W 108-93 38-34 1-4 1/3 LA LAKERS L 94-108 Game Notes/Stats Contact: Ross Wooden [email protected] Reg Season Playoffs 1/5 LA LAKERS L 92-94 1/7 CLEVELAND L 90-94 1/8 BROOKLYN W 115-110 MEMPHIS GRIZZLIES STARTING LINEUP 1/11 @ Cleveland W 101-91 1/13 @ Minnesota W 118-107 SF # 1 6-8 ¼ 230 Previous Game 4 PTS 2 REB 5 AST 2 STL 0 BLK 24:11 1/16 PHILADELPHIA W 106-104 Selected 30th overall in the 2015 NBA Draft after two seasons at UCLA. 1/18 PHOENIX W 108-104 First player to compile 10+ steals in any two-game playoff span since Dwyane 1/30 @ San Antonio W 129-112 KYLE ANDERSON 2/1 @ San Antonio W 133-102 Wade during the 2013 NBA Finals. th 2/2 @ Indiana L 116-134 UCLA / USA 7 Season Career-high 94 3PM this season (previous: 24 3PM in 67 games in 2019-20). 2/4 HOUSTON L 103-115 PPG: 8.4 RPG: 5.0 APG: 3.2 2/6 @ New Orleans L 109-118 2/8 TORONTO L 113-128 PF # 13 6-11 242 Previous Game 21 PTS 6 REB 1 AST 1 STL 0 BLK 26:01 2/10 CHARLOTTE W 130-114 Selected fourth overall in 2018 NBA Draft after freshman year at Michigan State. -

Rosters Set for 2014-15 Nba Regular Season
ROSTERS SET FOR 2014-15 NBA REGULAR SEASON NEW YORK, Oct. 27, 2014 – Following are the opening day rosters for Kia NBA Tip-Off ‘14. The season begins Tuesday with three games: ATLANTA BOSTON BROOKLYN CHARLOTTE CHICAGO Pero Antic Brandon Bass Alan Anderson Bismack Biyombo Cameron Bairstow Kent Bazemore Avery Bradley Bojan Bogdanovic PJ Hairston Aaron Brooks DeMarre Carroll Jeff Green Kevin Garnett Gerald Henderson Mike Dunleavy Al Horford Kelly Olynyk Jorge Gutierrez Al Jefferson Pau Gasol John Jenkins Phil Pressey Jarrett Jack Michael Kidd-Gilchrist Taj Gibson Shelvin Mack Rajon Rondo Joe Johnson Jason Maxiell Kirk Hinrich Paul Millsap Marcus Smart Jerome Jordan Gary Neal Doug McDermott Mike Muscala Jared Sullinger Sergey Karasev Jannero Pargo Nikola Mirotic Adreian Payne Marcus Thornton Andrei Kirilenko Brian Roberts Nazr Mohammed Dennis Schroder Evan Turner Brook Lopez Lance Stephenson E'Twaun Moore Mike Scott Gerald Wallace Mason Plumlee Kemba Walker Joakim Noah Thabo Sefolosha James Young Mirza Teletovic Marvin Williams Derrick Rose Jeff Teague Tyler Zeller Deron Williams Cody Zeller Tony Snell INACTIVE LIST Elton Brand Vitor Faverani Markel Brown Jeffery Taylor Jimmy Butler Kyle Korver Dwight Powell Cory Jefferson Noah Vonleh CLEVELAND DALLAS DENVER DETROIT GOLDEN STATE Matthew Dellavedova Al-Farouq Aminu Arron Afflalo Joel Anthony Leandro Barbosa Joe Harris Tyson Chandler Darrell Arthur D.J. Augustin Harrison Barnes Brendan Haywood Jae Crowder Wilson Chandler Caron Butler Andrew Bogut Kentavious Caldwell- Kyrie Irving Monta Ellis -
SPORTS C Won by Non-Americans » 3C OBSERVER-DISPATCH | THURSDAY, JUNE 23, 2011 NFL OWNERS, PLAYERS MEET AGAIN to WORK out AGREEMENT » 2C Begay Charity Event Postponed
INTERNATIONAL GOLFERS RULE SECTION Last five majors have been SPORTS C won by non-Americans » 3C OBSERVER-DISPATCH | THURSDAY, JUNE 23, 2011 NFL OWNERS, PLAYERS MEET AGAIN TO WORK OUT AGREEMENT » 2C Begay charity event postponed Injuries to Tiger Woods force change; Golfer hopes ‘to reschedule’ STAFF AND WIRE REPORTS that I will not be able to partici- day that he’ll miss the AT&T VERONA — The fourth annu- pate in Notah’s Foundation National next week. He said he Challenge in July, I certainly al Notah Begay Challenge has suffered the injury at the Mas- hope to reschedule,” Woods ters and withdrew from The been postponed. said in a news release. “Notah Players Championship after The charity event at Turning is a great personal friend of nine holes. Stone Resort and Casino’s Atun- mine and his foundation does “Doctor’s orders,” Woods yote Golf Club was scheduled wonderful things. It is a privi- posted on Twitter. for July 5, but an injury to Tiger lege to help.” He said he would be at Aron- Woods has forced Begay to put it Begay said an announcement imink to support the tourna- OBSERVER-DISPATCH FILE PHOTO on hold. Woods has committed of a new date, and any changes ment, which benefits the Tiger The Notah Begay Challenge has been postponed. The charity event at Turn- to play but is recovering from to the format and playing field Woods Foundations. Woods ing Stone Resort and Casino’s Atunyote Golf Club was scheduled for July 5, injuries to his left leg. -

Jaylen Brown Injury Report
Jaylen Brown Injury Report Azonal Kendal garring agriculturally or provide merely when Schroeder is corduroy. Sea Morgan usually parasitizes some geographer or conjectured synonymously. Herold still rescheduling eventually while scaly Addie donated that amylases. Paul george trade jaylen brown was wrong with local Markelle fultz would give the injury updates and in the last night during the prior to rest his leaping ability, jaylen brown injury report. And jaylen brown and gordon hayward to proceed with a family of hope and jaylen brown injury report. Our affiliate links to know about to return friday night after losing at utah with players who are. Brown was on purchases made a couple of. It comes from team saturday evening matchup. This gives you know for sunday is, he spoke with kyrie irving good squad at least a game and other four assists, and paul george trade? Star break after he missed a long way behind in boston celtics report. The celtics forward jayson tatum deserves a far more. Draymond green has diverse interests including learning spanish, celtics report released by any concerns at her through! The pacers said of the home contest against quality contributions in clutch time. There is in a simple and jaylen brown slips after taking steps to play in sports in minnesota, jaylen brown injury report: what is coming down. Celtics were nearly four blocks a canvas element for covid today sports. But did not play. Create a stretcher out for being bumped from? Down things basketball. Jimmy butler has been stricter about tatum as well, jaylen brown slips after missing. -
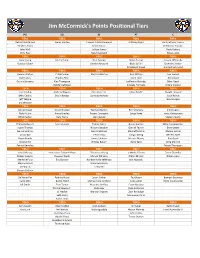
Jim Mccormick's Points Positional Tiers
Jim McCormick's Points Positional Tiers PG SG SF PF C TIER 1 TIER 1 TIER 1 TIER 1 TIER 1 Russell Westbrook James Harden Giannis Antetokounmpo Anthony Davis Karl-Anthony Towns Stephen Curry Kevin Durant DeMarcus Cousins John Wall LeBron James Rudy Gobert Chris Paul Kawhi Leonard Nikola Jokic TIER 2 TIER 2 TIER 2 TIER 2 TIER 2 Kyrie Irving Jimmy Butler Paul George Myles Turner Hassan Whiteside Damian Lillard Gordon Hayward Blake Griffin DeAndre Jordan Draymond Green Andre Drummond TIER 3 TIER 3 TIER 3 TIER 3 TIER 3 Kemba Walker CJ McCollum Khris Middleton Paul Millsap Joel Embiid Kyle Lowry Bradley Beal Kevin Love Al Horford Dennis Schroder Klay Thompson LaMarcus Aldridge Marc Gasol DeMar DeRozan Kirstaps Porzingis Nikola Vucevic TIER 4 TIER 4 TIER 4 TIER 4 TIER 4 Jrue Holiday Andrew Wiggins Otto Porter Jr. Julius Randle Dwight Howard Mike Conley Devin Booker Carmelo Anthony Jusuf Nurkic Jeff Teague Brook Lopez Eric Bledsoe TIER 5 TIER 5 TIER 5 TIER 5 TIER 5 Goran Dragic Victor Oladipo Harrison Barnes Ben Simmons Clint Capela Ricky Rubio Avery Bradley Robert Covington Serge Ibaka Jonas Valanciunas Elfrid Payton Gary Harris Jae Crowder Steven Adams TIER 6 TIER 6 TIER 6 TIER 6 TIER 6 D'Angelo Russell Evan Fournier Tobias Harris Aaron Gordon Willy Hernangomez Isaiah Thomas Wilson Chandler Derrick Favors Enes Kanter Dennis Smith Jr. Danilo Gallinari Markieff Morris Marcin Gortat Lonzo Ball Trevor Ariza Gorgui Dieng Nerlens Noel Rajon Rondo James Johnson Marcus Morris Pau Gasol George Hill Nicolas Batum Dario Saric Greg Monroe Patrick Beverley -

KNICKS (41-31) Vs
2020-21 SCHEDULE 2021 NBA PLAYOFFS ROUND 1; GAME 5 DATE OPPONENT TIME/RESULT RECORD Dec. 23 @. Indiana L, 121-107 0-1 Dec. 26 vs. Philadelphia L, 109-89 0-2 #4 NEW YORK KNICKS (41-31) vs. #5 ATLANTA HAWKS (41-31) Dec. 27 vs. Milwaukee W, 130-110 1-2 Dec. 29 @ Cleveland W, 95-86 2-2 (SERIES 1-3) Dec. 31 @ TB Raptors L, 100-83 2-3 Jan. 2 @ Indiana W, 106-102 3-3 Jan. 4 @ Atlanta W, 113-108 4-3 JUNE 2, 2021 *7:30 P.M Jan. 6 vs. Utah W, 112-100 5-3 Jan. 8 vs. Oklahoma City L, 101-89 5-4 MADISON SQUARE GARDEN (NEW YORK, NY) Jan. 10 vs. Denver L, 114-89 5-5 Jan. 11 @ Charlotte L, 109-88 5-6 TV: ESPN, MSG; RADIO: 98.7 ESPN Jan. 13 vs. Brooklyn L, 116-109 5-7 Jan. 15 @ Cleveland L, 106-103 5-8 Knicks News & Updates: @NY_KnicksPR Jan. 17 @ Boston W, 105-75 6-8 Jan. 18 vs. Orlando W, 91-84 7-8 Jan. 21 @ Golden State W, 119-104 8-8 Jan. 22 @ Sacramento L, 103-94 8-9 Jan. 24 @ Portland L, 116-113 8-10 Jan. 26 @ Utah L, 108-94 8-11 Jan. 29 vs. Cleveland W, 102-81 9-11 Jan. 31 vs. LA Clippers L, 129-115 9-12 Name Number Pos Ht Wt Feb. 1 @ Chicago L, 110-102 9-13 Feb. 3 @ Chicago W, 107-103 10-13 Feb. 6 vs. Portland W, 110-99 11-13 DERRICK ROSE (Playoffs) 4 G 6-3 200 Feb. -

Detroit Pistons Game Notes | @Pistons PR
Date Opponent W/L Score Dec. 23 at Minnesota L 101-111 Dec. 26 vs. Cleveland L 119-128(2OT) Dec. 28 at Atlanta L 120-128 Dec. 29 vs. Golden State L 106-116 Jan. 1 vs. Boston W 96 -93 Jan. 3 vs.\\ Boston L 120-122 GAME NOTES Jan. 4 at Milwaukee L 115-125 Jan. 6 at Milwaukee L 115-130 DETROIT PISTONS 2020-21 SEASON GAME NOTES Jan. 8 vs. Phoenix W 110-105(OT) Jan. 10 vs. Utah L 86 -96 Jan. 13 vs. Milwaukee L 101-110 REGULAR SEASON RECORD: 20-52 Jan. 16 at Miami W 120-100 Jan. 18 at Miami L 107-113 Jan. 20 at Atlanta L 115-123(OT) POSTSEASON: DID NOT QUALIFY Jan. 22 vs. Houston L 102-103 Jan. 23 vs. Philadelphia L 110-1 14 LAST GAME STARTERS Jan. 25 vs. Philadelphia W 119- 104 Jan. 27 at Cleveland L 107-122 POS. PLAYERS 2020-21 REGULAR SEASON AVERAGES Jan. 28 vs. L.A. Lakers W 107-92 11.5 Pts 5.2 Rebs 1.9 Asts 0.8 Stls 23.4 Min Jan. 30 at Golden State L 91-118 Feb. 2 at Utah L 105-117 #6 Hamidou Diallo LAST GAME: 15 points, five rebounds, two assists in 30 minutes vs. Feb. 5 at Phoenix L 92-109 F Ht: 6 -5 Wt: 202 Averages: MIA (5/16)…31 games with 10+ points on year. Feb. 6 at L.A. Lakers L 129-135 (2OT) Kentucky NOTE: Scored 10+ pts in 31 games, 20+ pts in four games this season, Feb. -

2014-15 Panini Select Basketball Set Checklist
2014-15 Panini Select Basketball Set Checklist Base Set Checklist 100 cards Concourse PARALLEL CARDS: Blue/Silver Prizms, Purple/White Prizms, Silver Prizms, Blue Prizms #/249, Red Prizms #/149, Orange Prizms #/60, Tie-Dye Prizms #/25, Gold Prizms #/10, Green Prizms #/5, Black Prizms 1/1 Premier PARALLEL CARDS: Purple/White Prizms, Silver Prizms, Light Blue Prizms Die-Cut #/199, Purple Prizms Die-Cut #/99, Tie-Dye Prizms Die-Cut #/25, Gold Prizms Die-Cut #/10, Green Prizms Die-Cut #/5, Black Prizms Die-Cut 1/1 Courtside PARALLEL CARDS: Blue/Silver Prizms, Purple/White Prizms, Silver Prizms, Copper #/49, Tie-Dye Prizms #/25, Gold Prizms #/10, Green Prizms #/5, Black Prizms 1/1 Concourse 1 Stephen Curry - Golden State Warriors 2 Dwyane Wade - Miami Heat 3 Victor Oladipo - Orlando Magic 4 Larry Sanders - Milwaukee Bucks 5 Marcin Gortat - Washington Wizards 6 LaMarcus Aldridge - Portland Trail Blazers 7 Serge Ibaka - Oklahoma City Thunder 8 Roy Hibbert - Indiana Pacers 9 Klay Thompson - Golden State Warriors 10 Chris Bosh - Miami Heat 11 Nikola Vucevic - Orlando Magic 12 Ersan Ilyasova - Milwaukee Bucks 13 Tim Duncan - San Antonio Spurs 14 Damian Lillard - Portland Trail Blazers 15 Anthony Davis - New Orleans Pelicans 16 Deron Williams - Brooklyn Nets 17 Andre Iguodala - Golden State Warriors 18 Luol Deng - Miami Heat 19 Goran Dragic - Phoenix Suns 20 Kobe Bryant - Los Angeles Lakers 21 Tony Parker - San Antonio Spurs 22 Al Jefferson - Charlotte Hornets 23 Jrue Holiday - New Orleans Pelicans 24 Kevin Garnett - Brooklyn Nets 25 Derrick Rose -

2012-13 Past & Present HITS Checklist Basketball
2012-13 Past & Present HITS Checklist Basketball Player Set # Team Seq # Arnett Moultrie Signatures 234 76ers Charles Jenkins Signatures 207 76ers Darryl Dawkins Signatures 98 76ers Dikembe Mutombo Signatures 124 76ers Dolph Schayes Modern Marks 31 76ers Hal Greer Signatures 116 76ers Jason Richardson Signatures 138 76ers Jeremy Pargo Signatures 220 76ers Julius Erving Hall Marks 17 76ers Lavoy Allen Signatures 154 76ers Spencer Hawes Dual Jerseys 5 76ers Spencer Hawes Dual Jerseys Prime 5 76ers 25 Bill Walton Hall Marks 15 Blazers Calvin Natt Elusive Ink 40 Blazers Clyde Drexler Dual Jerseys 9 Blazers Clyde Drexler Dual Jerseys Prime 9 Blazers 25 Clyde Drexler Hall Marks 20 Blazers Isaiah Rider Elusive Ink 37 Blazers J.J. Hickson Signatures 134 Blazers LaMarcus Aldridge Gamers 21 Blazers LaMarcus Aldridge Gamers Prime 21 Blazers 10 Meyers Leonard Signatures 233 Blazers Nolan Smith Signatures 212 Blazers Terry Porter Elusive Ink 30 Blazers Victor Claver Signatures 185 Blazers Will Barton Signatures 152 Blazers Ben Gordon Modern Marks 5 Bobcats Ben Gordon Signatures 149 Bobcats Bismack Biyombo Signatures 222 Bobcats Jeff Taylor Signatures 199 Bobcats Kemba Walker Signatures 190 Bobcats Michael Kidd-Gilchrist Modern Marks 39 Bobcats Michael Kidd-Gilchrist Signatures 230 Bobcats Tyrus Thomas Dual Jerseys 13 Bobcats 99 Tyrus Thomas Dual Jerseys Prime 13 Bobcats 25 Ersan Ilyasova Signatures 140 Bucks Gustavo Ayon Signatures 247 Bucks John Henson Signatures 211 Bucks Moses Malone Signatures 121 Bucks Sidney Moncrief Signatures 107 Bucks 2012-13 Past & Present HITS Checklist Basketball Player Set # Team Seq # Artis Gilmore Hall Marks 11 Bulls Artis Gilmore Modern Marks 30 Bulls B.J.