Issue Editors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download The
LEADING THE FUTURE OF TECHNOLOGY 2016 ANNUAL REPORT TABLE OF CONTENTS 1 MESSAGE FROM THE IEEE PRESIDENT AND THE EXECUTIVE DIRECTOR 3 LEADING THE FUTURE OF TECHNOLOGY 5 GROWING GLOBAL AND INDUSTRY PARTNERSHIPS 11 ADVANCING TECHNOLOGY 17 INCREASING AWARENESS 23 AWARDING EXCELLENCE 29 EXPANSION AND OUTREACH 33 ELEVATING ENGAGEMENT 37 MESSAGE FROM THE TREASURER AND REPORT OF INDEPENDENT CERTIFIED PUBLIC ACCOUNTANTS 39 CONSOLIDATED FINANCIAL STATEMENTS Barry L. Shoop 2016 IEEE President and CEO IEEE Xplore® Digital Library to enable personalized importantly, we must be willing to rise again, learn experiences based on second-generation analytics. from our experiences, and advance. As our members drive ever-faster technological revolutions, each of us MESSAGE FROM As IEEE’s membership continues to grow must play a role in guaranteeing that our professional internationally, we have expanded our global presence society remains relevant, that it is as innovative as our THE IEEE PRESIDENT AND and engagement by opening offices in key geographic members are, and that it continues to evolve to meet locations around the world. In 2016, IEEE opened a the challenges of the ever-changing world around us. second office in China, due to growth in the country THE EXECUTIVE DIRECTOR and to better support engineers in Shenzhen, China’s From Big Data and Cloud Computing to Smart Grid, Silicon Valley. We expanded our office in Bangalore, Cybersecurity and our Brain Initiative, IEEE members India, and are preparing for the opening of a new IEEE are working across varied disciplines, pursuing Technology continues to be a transformative power We continue to make great strides in our efforts to office in Vienna, Austria. -

Building Alexa Skills Using Amazon Sagemaker and AWS Lambda
Bootcamp: Building Alexa Skills Using Amazon SageMaker and AWS Lambda Description In this full-day, intermediate-level bootcamp, you will learn the essentials of building an Alexa skill, the AWS Lambda function that supports it, and how to enrich it with Amazon SageMaker. This course, which is intended for students with a basic understanding of Alexa, machine learning, and Python, teaches you to develop new tools to improve interactions with your customers. Intended Audience This course is intended for those who: • Are interested in developing Alexa skills • Want to enhance their Alexa skills using machine learning • Work in a customer-focused industry and want to improve their customer interactions Course Objectives In this course, you will learn: • The basics of the Alexa developer console • How utterances and intents work, and how skills interact with AWS Lambda • How to use Amazon SageMaker for the machine learning workflow and for enhancing Alexa skills Prerequisites We recommend that attendees of this course have the following prerequisites: • Basic familiarity with Alexa and Alexa skills • Basic familiarity with machine learning • Basic familiarity with Python • An account on the Amazon Developer Portal Delivery Method This course is delivered through a mix of: • Classroom training • Hands-on Labs Hands-on Activity • This course allows you to test new skills and apply knowledge to your working environment through a variety of practical exercises • This course requires a laptop to complete lab exercises; tablets are not appropriate Duration One Day Course Outline This course covers the following concepts: • Getting started with Alexa • Lab: Building an Alexa skill: Hello Alexa © 2018, Amazon Web Services, Inc. -
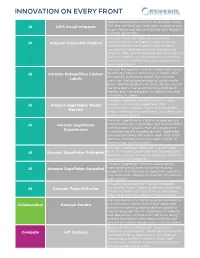
Innovation on Every Front
INNOVATION ON EVERY FRONT AWS DeepComposer uses AI to compose music. AI AWS DeepComposer The new service gives developers a creative way to get started and become familiar with machine learning capabilities. Amazon Transcribe Medical is a machine AI Amazon Transcribe Medical learning service that makes it easy to quickly create accurate transcriptions from medical consultations between patients and physician dictated notes, practitioner/patient consultations, and tele-medicine are automatically converted from speech to text for use in clinical documen- tation applications. Amazon Rekognition Custom Labels helps users AI Amazon Rekognition Custom identify the objects and scenes in images that are specific to business needs. For example, Labels users can find corporate logos in social media posts, identify products on store shelves, classify machine parts in an assembly line, distinguish healthy and infected plants, or detect animated characters in videos. Amazon SageMaker Model Monitor is a new AI Amazon SageMaker Model capability of Amazon SageMaker that automatically monitors machine learning (ML) Monitor models in production, and alerts users when data quality issues appear. Amazon SageMaker is a fully managed service AI Amazon SageMaker that provides every developer and data scientist with the ability to build, train, and deploy ma- Experiments chine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models. Amazon SageMaker Debugger is a new capa- AI Amazon SageMaker Debugger bility of Amazon SageMaker that automatically identifies complex issues developing in machine learning (ML) training jobs. Amazon SageMaker Autopilot automatically AI Amazon SageMaker Autopilot trains and tunes the best machine learning models for classification or regression, based on your data while allowing to maintain full control and visibility. -

2008 Cse Course List 56
It is CSE’s intention every year to make the Annual Report representative of the whole Department. With this ideal in mind, a design contest is held every year open to Graduate and Undergraduate students. This year’s winner was James Dickson, a junior CSE major who hails from Granville, Ohio. CONTENTS 2008 ACHIEVEMENT & HIGHLIGHTS 1 ANNUAL CSE DEPARTMENT AWARDS 11 INDUSTRIAL ADVISORY BOARD 12 RETIREMENT DOUBLE HIT 13 RESEARCH 14 GRANTS, AWARDS & GIFTS 19 COLLOQUIUM 27 STUDENTS 29 FaCULTY AND STAFF 38 SELECT FaCULTY PUBLICATIONS 49 2007 - 2008 CSE COURSE LIST 56 395 Dreese Labs 2015 Neil Avenue Columbus, Ohio 43210-1277 (614) 292-5813 WWW.CSE.OHIO-STATE.EDU i Mission Statement ± The Department of Computer Science and Engineering will impact the information age as a national leader in computing research and education. ± We will prepare computing graduates who are highly sought after, productive, and well-respected for their work, and who contribute to new developments in computing. ± We will give students in other disciplines an appropriate foundation in computing for their education, research, and experiences after graduation, consistent with computing’s increasingly fundamental role in society. ± In our areas of research focus, we will contribute key ideas to the development of the computing basis of the information age, advancing the state of the art for the benefit of society, the State of Ohio, and The Ohio State University. ± We will work with key academic partners within and outside of OSU, and with key industrial partners, in pursuit of our research and educational endeavors. ii GREETIN G S FROM THE CHAIR ’S OFFI C E Dear Colleges, Alumni, Friends, and Parents, As we reach the end of the 2007-2008 academic year, I am glad to introduce you a new annual report of the department. -
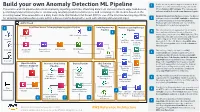
Build Your Own Anomaly Detection ML Pipeline
Device telemetry data is ingested from the field Build your own Anomaly Detection ML Pipeline 1 devices on a near real-time basis by calls to the This end-to-end ML pipeline detects anomalies by ingesting real-time, streaming data from various network edge field devices, API via Amazon API Gateway. The requests get performing transformation jobs to continuously run daily predictions/inferences, and retraining the ML models based on the authenticated/authorized using Amazon Cognito. incoming newer time series data on a daily basis. Note that Random Cut Forest (RCF) is one of the machine learning algorithms Amazon Kinesis Data Firehose ingests the data in for detecting anomalous data points within a data set and is designed to work with arbitrary-dimensional input. 2 real time, and invokes AWS Lambda to transform the data into parquet format. Kinesis Data AWS Cloud Firehose will automatically scale to match the throughput of the data being ingested. 1 Real-Time Device Telemetry Data Ingestion Pipeline 2 Data Engineering Machine Learning Devops Pipeline Pipeline The telemetry data is aggregated on an hourly 3 3 basis and re-partitioned based on the year, month, date, and hour using AWS Glue jobs. The Amazon Cognito AWS Glue Data Catalog additional steps like transformations and feature Device #1 engineering are performed for training the SageMaker AWS CodeBuild Anomaly Detection ML Model using AWS Glue Notebook Create ML jobs. The training data set is stored on Amazon Container S3 Data Lake. Amazon Kinesis AWS Lambda S3 Data Lake AWS Glue Device #2 Amazon API The training code is checked in an AWS Gateway Data Firehose 4 AWS SageMaker CodeCommit repo which triggers a Machine Training CodeCommit Containers Learning DevOps (MLOps) pipeline using AWS Dataset for Anomaly CodePipeline. -

IEEE-SA Standards Board Meeting Minutes – December 2015
Board Meeting Minutes – September 2011 IEEE-SA Standards Board Meeting Minutes – December 2015 IEEE-SA Standards Board Meeting Minutes 05 December 2015 IEEE Operations Center, Piscataway, New Jersey, USA Attendees Chair: John Kulick Vice Chair: Jon Rosdahl Past Chair: Rich Hulett Secretary: Konstantinos Karachalios Members: Masayuki Ariyoshi Ted Burse Stephen Dukes [TAB Rep.] Jean-Philippe Faure Travis Griffith Gary Hoffman Michael Janezic David Law Hung Ling Andrew Myles Ted Olsen Glenn Parsons Ron Petersen Annette Reilly Steve Shellhammer Adrian Stephens Yatin Trivedi Philip Winston Don Wright IEEE Standards Association | 445 Hoes Lane | Piscataway NJ 08854 USA Phone: +1 732 981 0060 | Fax: +1 732 562 1571 | standards.ieee.org IEEE-SA Standards Board Meeting Minutes – December 2015 Yu Yuan Daidi Zhong Thomas Koshy, NRC Liaison Jim Matthews, IEC Liaison Members Absent: Joe Koepfinger, Member Emeritus Dick DeBlasio, DOE Liaison IEEE Staff: Melissa Aranzamendez Kathryn Bennett Christina Boyce Matthew Ceglia Tom Compton Christian DeFelice Karen Evangelista Jonathan Goldberg Mary Ellen Hanntz Yvette Ho Sang Noelle Humenick Karen Kenney Michael Kipness Adam Newman Mary Lynne Nielsen Moira Patterson Walter Pienciak Dave Ringle, Recording Secretary Rudi Schubert Sam Sciacca Patrick Slaats Walter Sun Susan Tatiner Cherry Tom Lisa Weisser Meng Zhao IEEE Outside Legal Counsel: Claire Topp Guests: Chuck Adams Dennis Brophy Dave Djavaherian IEEE-SA Standards Board Meeting Minutes – December 2015 James Gilb Scott Gilfillan Daniel Hermele Bruce Kraemer Xiaohui Liu Kevin Lu John Messenger Gil Ohana Mehmet Ulema, ComSoc Liaison to the SASB Neil Vohra Walter Weigel Yingli Wen Phil Wennblom Howard Wolfman Helene Workman Paul Zeineddin 1 Call to Order Chair Kulick called the meeting to order at 9:00 a.m. -

Cloud Computing & Big Data
Cloud Computing & Big Data PARALLEL & SCALABLE MACHINE LEARNING & DEEP LEARNING Ph.D. Student Chadi Barakat School of Engineering and Natural Sciences, University of Iceland, Reykjavik, Iceland Juelich Supercomputing Centre, Forschungszentrum Juelich, Germany @MorrisRiedel LECTURE 11 @Morris Riedel @MorrisRiedel Big Data Analytics & Cloud Data Mining November 10, 2020 Online Lecture Review of Lecture 10 –Software-As-A-Service (SAAS) ▪ SAAS Examples of Customer Relationship Management (CRM) Applications (PAAS) (introducing a growing range of machine (horizontal learning and scalability artificial enabled by (IAAS) intelligence Virtualization capabilities) in Clouds) [5] AWS Sagemaker [4] Freshworks Web page [3] ZOHO CRM Web page modfied from [2] Distributed & Cloud Computing Book [1] Microsoft Azure SAAS Lecture 11 – Big Data Analytics & Cloud Data Mining 2 / 36 Outline of the Course 1. Cloud Computing & Big Data Introduction 11. Big Data Analytics & Cloud Data Mining 2. Machine Learning Models in Clouds 12. Docker & Container Management 13. OpenStack Cloud Operating System 3. Apache Spark for Cloud Applications 14. Online Social Networking & Graph Databases 4. Virtualization & Data Center Design 15. Big Data Streaming Tools & Applications 5. Map-Reduce Computing Paradigm 16. Epilogue 6. Deep Learning driven by Big Data 7. Deep Learning Applications in Clouds + additional practical lectures & Webinars for our hands-on assignments in context 8. Infrastructure-As-A-Service (IAAS) 9. Platform-As-A-Service (PAAS) ▪ Practical Topics 10. Software-As-A-Service -

IEEE Annual Report- 2017
THE 2017 IEEE TABLE OF PRESIDENT’S COIN CONTENTS Initiated by 2016 President Barry Shoop, the IEEE President’s Coin 1 MESSAGE FROM THE IEEE PRESIDENT is given to individuals in recognition of their dedication to IEEE. For me, one of the most interesting aspects is the embodiment of the President’s unique design and story. 3 INSPIRING CHANGE. EMPOWERING PEOPLE. “Find Your Reason, Purpose and Passion” 5 GROWING GLOBAL AND INDUSTRY PARTNERSHIPS The front of my coin features a personal motto, inspired by my daughter - “Find Your Reason, Purpose and Passion,” along with the mission of IEEE. 9 GROWING AWARENESS OF IEEE The back highlights five areas of IEEE activities in the outer ring and different facets of IEEE in the center. 15 EXPANDING IEEE’S PRESENCE AROUND THE WORLD The Wi-Fi symbol denotes IEEE’s leadership in standards. 21 ADVANCING TECHNOLOGY FOR THE FUTURE The image next to that represents engineering in medicine and biology. The skyline signifies Smart Cities and IEEE’s global nature. 27 REWARDING EXCELLENCE The circuit diagram symbolizes our computer and electronic engineering disciplines. The plant is for 31 ENCOURAGING OUTREACH AND DRIVING RESEARCH IEEE’s power and energy fields and sustainability initiatives. The sine wave stands for our many communications domains. 35 ELEVATING ENGAGEMENT My favorite icon is the group of people with one individual who is a little different, showing IEEE 39 IEEE BOARD OF DIRECTORS AND MANAGEMENT COUNCIL members welcoming me as a female engineer. With each coin I presented, came the feeling of pride 41 MESSAGE FROM THE TREASURER AND REPORT and humbleness to serve our great institution. -

Active IEEE Sister Society Agreements (Known As of 4-Feb-20)
Active IEEE Sister Society Agreements (known as of 4-Feb-20) Discount IEEE Society Sister Society Agreement with Acronym Country Valid Until Membership Publication Price IEEE Communications CMAI - Communications Multimedia Applications Society Infrastructure - CMAI Association of India CMAI India 31-Dec-19 IEEE FRUCT - East-West Research and IEEE Education Communications Society on Telecommunications and Open Society Innovations Community FRUCT FRUCT Finland 31-Dec-19 IEEE Communications Society SCS - Singapore IEEE Computer Society SCS Singapore 31-Dec-20 IEEE Communications AEAI - Association of Engineers and Architects in Society Israel AEAI Israel 31-Dec-21 IEEE Communications Society CIC - China Institute of Communications CIC China 31-Dec-21 IEEE Communications Society HTE-Scientific Association for Infocommunications HTE Hungary 31-Dec-21 IEEE IEICE-IEEE Communications Society of the Institute Communications of Electronics,Information and Communication Society Engineers IEICE Japan 31-Dec-21 IEEE Communications IETE-Institute of Electronics and Society Telecommunications Engineers IETE india 31-Dec-21 IEEE AICA - Associazone Italiana Per L-Informatica ED IL Communications Calcolo Automatico Society AICA Italy 31-Dec-22 IEEE AICT-AEIT Society for Information & PER120-PRT $140.00 Communications Communications Technology PER141-PRT $140.00 Society AICT Italy 31-Dec-22 10% off ComSoc PER172-ELE $47.00 IEEE dues PER302-PRT $76.00 Communications CCIS - Communications and Information Society, PER317-PRT $98.00 Society Croatia CCIS Croatia -

Message from Chairman
Vol. 9 No. 5 August 2014 Message from Chairman Dear Members, As you are probably aware, the Region 10 has announced the 2013 Region 10 Distinguished Large Section, Medium Section and Small Section Awards. Bangalore Section is selected for the Distinguished Large Section Award, Pune Section for the Distinguished Medium Section Award and Northern Australia Section for the Distinguished Small Section Award. Each of these awards carries a cash bonus of USD1,000 along with an Award certificate. It is a great honor and pleasure that two of our Sections in India have won the Large Section and Medium Section awards. Let us record our appreciation and greetings to the Bangalore and Pune Sections for their achievement. As you know, there are a number of awards instituted by the IEEE R-10 and IEEE Head quarters. I wish that the IEEE Units in India should try to win as many awards as possible. It is definitely possible if we sincerely work to increase our activities and to improve our Membership strength. I am happy to place on record that the Second IEEE Region 10 Humanitarian Technology Conference 2014 was conducted successfully by the Madras Section during 6 -9 August 2014. I sincerely appreciate the Chair and his dedicated team of volunteers and convey my Heartiest Congratulations for their achievement. The IEEE Computer Society, Pune Section has proposed to organize “All India Computer Society Student Congress 2014” during 13th and 14th December, 2014. The IEEE Electron Device Society, Bangalore Chapter is organizing the 2nd ICEE-2014 from 4-6 December, 2014, at the Indian Institute of Science, Bangalore, with a pre-conference tutorials on Dec. -

Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide
Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS: AWS Technical Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Table of Contents Abstract and introduction .................................................................................................................... i Abstract .................................................................................................................................... 1 Introduction .............................................................................................................................. 1 Personas for an ML platform ............................................................................................................... 2 AWS accounts .................................................................................................................................... 3 Networking architecture ..................................................................................................................... -

Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework
Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework Analytics Lens: AWS Well-Architected Framework Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Analytics Lens AWS Well-Architected Framework Table of Contents Abstract ............................................................................................................................................ 1 Abstract .................................................................................................................................... 1 Introduction ...................................................................................................................................... 2 Definitions ................................................................................................................................. 2 Data Ingestion Layer ........................................................................................................... 2 Data Access and Security Layer ............................................................................................ 3 Catalog and Search Layer ...................................................................................................