The VVV Templates Project Towards an Automated Classification of VVV
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download Chapter (PDF)
The CoRoT Legacy Book c The authors, 2016 DOI: 10.1051/978-2-7598-1876-1.c031 III.1 Transit features detected by the CoRoT/Exoplanet Science Team M. Deleuil1, C. Moutou1, J. Cabrera2, S. Aigrain3, F. Bouchy1, H. Deeg4, P. Bord´e5, and the CoRoT Exoplanet team 1 Aix Marseille Universite,´ CNRS, LAM (Laboratoire d’Astrophysique de Marseille) UMR 7326, 13388, Marseille, France 2 Institute of Planetary Research, German Aerospace Center, Rutherfordstrasse 2, 12489 Berlin, Germany 3 Department of Physics, Denys Wilkinson Building Keble Road, Oxford, OX1 3RH 4 Instituto de Astrofisica de Canarias, 38205 La Laguna, Tenerife, Spain and Universidad de La Laguna, Dept. de Astrof´ısica, 38206 La Laguna, Tenerife, Spain 5 Institut d’astrophysique spatiale, Universite´ Paris-Sud 11 & CNRS (UMR 8617), Bat.ˆ 121, 91405 Orsay, France While this is reliable on a statistical point of view, individ- 1. Introduction ual targets could be misclassified (Damiani et al. this book) CoRoT has observed 26 stellar fields located in two oppo- and these numbers are mostly indicative of the overall stel- site directions for transiting planet hunting. The fields ob- lar population properties. They show however that, in a served near 6h 50m in right ascension are referred as (galac- given field, classes V and IV represent the majority of the tic) \anti-center fields”, and those near 18h 50m as \center targets. Figure III.1.2 displays how these stars classified fields”. The observing strategy consisted in staring a given as class IV and V distribute over spectral types F, G, K, star field for durations that ranged from 21 to 152 days. -

The False Positive Probability of Corot and Kepler Planetary Candidates
EPSC Abstracts Vol. 6, EPSC-DPS2011-1243, 2011 EPSC-DPS Joint Meeting 2011 c Author(s) 2011 The False Positive probability of CoRoT and Kepler planetary candidates. R.F. Díaz (1,2), J.M. Almenara (3), A. Bonomo (3), F. Bouchy (1,2), M. Deleuil (3), G. Hébrard (1,2), C. Moutou (3) and A. Santerne (3) (1) Institut d’astrophysique de Paris, FRANCE, (2) Observatoire de Haute-Provence, FRANCE, (3) Laboratoire d’Astrophysique de Marseille, FRANCE ([email protected]) Abstract tified, similarly to what is done for planet candidates detected from RV surveys, a fraction of which are in We estimate the False Positive Probability of CoRoT actuality low-mass objects in low-inclination orbits. and Kepler planetary candidates, and review critically Therefore, since the rapidly-growing number of previous results present in the literature. The ob- transiting planet candidates makes it increasingly dif- tained estimates are compared with the results from ficult to confirm each one individually by means of RV the ground-based radial velocity follow-up carried out measurements, a precise and reliable estimation of the with the HARPS and SOPHIE spectrographs for these FPP is of great importance to obtain the greatest sci- two space missions. entific return from the data acquired by CoRoT and Kepler, as well as to fully exploit the data that will be 1. Introduction obtained from future missions, like PLATO. The CoRoT and Kepler space missions are dedicated to finding transit-like events caused by extrasolar plan- 2. The False Positives ets in orbits aligned with the line of sight from Earth. -

The Trilogy Is Complete -- Gigagalaxy Zoom Phase 3 28 September 2009
The trilogy is complete -- GigaGalaxy Zoom Phase 3 28 September 2009 "globules" and the most prominent ones have been catalogued by the astronomer Edward Emerson Barnard. The Lagoon Nebula hosts the young open stellar cluster known as NGC 6530. This is home for 50 to 100 stars and twinkles in the lower left portion of the nebula. Observations suggest that the cluster is slightly in front of the nebula itself, though still enshrouded by dust, as revealed by reddening of the starlight, an effect that occurs when small dust particles scatter light. The third image of ESO's GigaGalaxy Zoom project is an amazing vista of the Lagoon Nebula taken with the 67-million-pixel Wide Field Imager attached to the MPG/ESO 2.2-meter telescope at the La Silla Observatory in Chile. The image covers more than one and a half square degree -- an area eight times larger than that of the Full Moon -- with a total of about 370 million pixels. It is based on images acquired using three different broadband filters (B, V, R) and one narrow- band filter (H-alpha). Credit: ESO The newly released image extends across a field of view of more than one and a half square degree — an area eight times larger than that of the full Moon — and was obtained with the Wide Field Imager attached to the MPG/ESO 2.2-metre telescope at the La Silla Observatory in Chile. This 67-million-pixel camera has already created several of ESO's iconic pictures. The intriguing object depicted here — the Lagoon Nebula — is located four to five thousand light- years away towards the constellation of Sagittarius The three images of ESO’s GigaGalaxy Zoom project (the Archer). -

HATS-3B: an Inflated Hot Jupiter Transiting an F-Type Star
Draft version January 5, 2018 A Preprint typeset using LTEX style emulateapj v. 5/2/11 HATS-3b: AN INFLATED HOT JUPITER TRANSITING AN F-TYPE STAR D. Bayliss1, G. Zhou1, K. Penev2,3, G. A.´ Bakos2,3,⋆,⋆⋆, J. D. Hartman2,3, A. Jordan´ 4, L. Mancini5, M. Mohler5, V. Suc4, M. Rabus4, B. Beky´ 3, Z. Csubry2,3, L. Buchhave6, T. Henning5, N. Nikolov5, B. Csak´ 5, R. Brahm4, N. Espinoza4, R. W. Noyes3, B. Schmidt1, P. Conroy1, D. J. Wright,7,8, C. G. Tinney,7,8, B. C. Addison,7,8, P. D. Sackett,1, D. D. Sasselov3, J. Laz´ ar´ 9, I. Papp9, P. Sari´ 9 Draft version January 5, 2018 ABSTRACT We report the discovery by the HATSouth survey of HATS-3b, a transiting extrasolar planet orbiting a V=12.4 F dwarf star. HATS-3b has a period of P =3.5479d, mass of Mp =1.07 MJ, and radius of Rp =1.38 RJ. Given the radius of the planet, the brightness of the host star, and the stellar rotational 1 velocity (v sin i = 9.0kms− ), this system will make an interesting target for future observations to measure the Rossiter-McLaughlin effect and determine its spin-orbit alignment. We detail the low/medium-resolution reconnaissance spectroscopy that we are now using to deal with large numbers of transiting planet candidates produced by the HATSouth survey. We show that this important step in discovering planets produces log g and Teff parameters at a precision suitable for efficient candidate vetting, as well as efficiently identifying stellar mass eclipsing binaries with radial velocity 1 semi-amplitudes as low as 1 km s− . -

Variable Star Classification and Light Curves Manual
Variable Star Classification and Light Curves An AAVSO course for the Carolyn Hurless Online Institute for Continuing Education in Astronomy (CHOICE) This is copyrighted material meant only for official enrollees in this online course. Do not share this document with others. Please do not quote from it without prior permission from the AAVSO. Table of Contents Course Description and Requirements for Completion Chapter One- 1. Introduction . What are variable stars? . The first known variable stars 2. Variable Star Names . Constellation names . Greek letters (Bayer letters) . GCVS naming scheme . Other naming conventions . Naming variable star types 3. The Main Types of variability Extrinsic . Eclipsing . Rotating . Microlensing Intrinsic . Pulsating . Eruptive . Cataclysmic . X-Ray 4. The Variability Tree Chapter Two- 1. Rotating Variables . The Sun . BY Dra stars . RS CVn stars . Rotating ellipsoidal variables 2. Eclipsing Variables . EA . EB . EW . EP . Roche Lobes 1 Chapter Three- 1. Pulsating Variables . Classical Cepheids . Type II Cepheids . RV Tau stars . Delta Sct stars . RR Lyr stars . Miras . Semi-regular stars 2. Eruptive Variables . Young Stellar Objects . T Tau stars . FUOrs . EXOrs . UXOrs . UV Cet stars . Gamma Cas stars . S Dor stars . R CrB stars Chapter Four- 1. Cataclysmic Variables . Dwarf Novae . Novae . Recurrent Novae . Magnetic CVs . Symbiotic Variables . Supernovae 2. Other Variables . Gamma-Ray Bursters . Active Galactic Nuclei 2 Course Description and Requirements for Completion This course is an overview of the types of variable stars most commonly observed by AAVSO observers. We discuss the physical processes behind what makes each type variable and how this is demonstrated in their light curves. Variable star names and nomenclature are placed in a historical context to aid in understanding today’s classification scheme. -

Search for Wide Substellar Companions to Young Nearby Stars with the VISTA Hemisphere Survey
Highlights on Spanish Astrophysics X, Proceedings of the XIII Scientific Meeting of the Spanish Astronomical Society held on July 16 – 20, 2018, in Salamanca, Spain. B. Montesinos, A. Asensio Ramos, F. Buitrago, R. Schödel, E. Villaver, S. Pérez-Hoyos, I. Ordóñez-Etxeberria (eds.), 2019 Search for wide substellar companions to young nearby stars with the VISTA Hemisphere Survey. P. Chinchilla1;2, V.J.S. B´ejar1;2, N. Lodieu1;2, M.R. Zapatero Osorio3, B. Gauza4, R. Rebolo1;2;5, and A. P´erezGarrido6 1 Instituto de Astrof´ısicade Canarias (IAC), c/V´ıaL´acteaS/N, 38200 La Laguna, Tenerife, Spain 2 Dpto. de Astrof´ısica,Universidad de La Laguna (ULL), 38206 La Laguna, Tenerife, Spain 3 Centro de Astrobiolog´ıa(CSIC-INTA), Ctra. de Ajalvir km 4, 28850 Torrej´onde Ardoz, Madrid, Spain 4 Dpto. de Astronom´ıa,Universidad de Chile, Camino el Observatorio 1515, Casilla 36-D, Las Condes, Santiago, Chile 5 Consejo Superior de Investigaciones Cient´ıficas(CSIC), Spain 6 Dpto. de F´ısicaAplicada, Universidad Polit´ecnicade Cartagena, 30202 Cartagena, Murcia, Spain Abstract We have performed a search for substellar objects as common proper motion companions to young nearby stars (including members of the Young Moving Groups AB Doradus, TW Hydrae, Tucana-Horologium and Beta Pictoris, and the Upper Scorpius young association) up to separations of 50,000 AU, using the VISTA Hemisphere Survey and 2MASS astro- metric and photometric data. We have found tens of candidates with spectral types from M to L, and estimated masses from low-mass stars to the deuterium-burning limit mass. -

Letter of Interest La Silla Schmidt Southern Survey
Snowmass2021 - Letter of Interest La Silla Schmidt Southern Survey Thematic Areas: (check all that apply /) (CF1) Dark Matter: Particle Like (CF2) Dark Matter: Wavelike (CF3) Dark Matter: Cosmic Probes (CF4) Dark Energy and Cosmic Acceleration: The Modern Universe (CF5) Dark Energy and Cosmic Acceleration: Cosmic Dawn and Before (CF6) Dark Energy and Cosmic Acceleration: Complementarity of Probes and New Facilities (CF7) Cosmic Probes of Fundamental Physics (Other) [Please specify frontier/topical group] Contact Information: Peter Nugent (LBNL) [[email protected]]: Collaboration: LS4 Authors: Greg Aldering (LBNL) [email protected]; Thomas Diehl (FNAL) [email protected]; Alex Kim (LBNL) [email protected]; Antonella Palmese (FNAL) [email protected]; Saul Perlmutter (LBNL) [email protected]; David Schlegel (LBNL) [email protected]; Yuanyuan Zhang (FNAL) [email protected] Abstract: We are proposing a 5-year public, wide-field, optical survey using an upgraded 20 square degree QUEST Camera on the ESO Schmidt Telescope at the La Silla Observatory in Chile – The La Silla Schmidt Southern Survey (LS4). We will use LBNL fully-depleted CCDs to maximize the sensitivity in the optical up to 1 micron. This survey will complement the Legacy Survey of Space and Time (LSST) being conducted at the Vera C. Rubin Observatory in two ways. First, it will provide a higher cadence than the LSST over several thousand square degrees of sky each night, allowing a more accurate characterization of brighter and faster evolving transients to 21st magnitude. Second, it will open up a new phase-space for discovery when coupled with the LSST by probing the sky between 12–16th magnitude – a region where the Rubin Observatory saturates. -

Transiting Exoplanets from the Corot Space Mission-XIX. Corot-23B: A
Astronomy & Astrophysics manuscript no. corot-23b˙v5 c ESO 2018 November 8, 2018 Transiting exoplanets from the CoRoT space mission ⋆ XIX. CoRoT-23b: a dense hot Jupiter on an eccentric orbit Rouan, D.1, Parviainen, H.2,20, Moutou, C.4, Deleuil, M.4, Fridlund, M.5, A. Ofir6, Havel, M.7, Aigrain, S.8, Alonso, R.15, Auvergne, M.1, Baglin, A.1, Barge, P.4, Bonomo, A.4, Bord´e, P.9, Bouchy, F.10,11, Cabrera, J.3, Cavarroc, C.9, Csizmadia, Sz.3, Deeg, H.J.2,20, Diaz, R.F.4, Dvorak, R.12, Erikson, A.3, Ferraz-Mello, S.13, Gandolfi, D.5, Gillon, M.15, Guillot, T.7, Hatzes, A.14, H´ebrard, G.10,11, Jorda, L.4, L´eger, A.9, Llebaria, A.4, Lammer, H.19, Lovis, C.15, Mazeh, T.6, Ollivier, M.9, P¨atzold, M.17, Queloz, D.15, Rauer, H.3, Samuel, B.1, Santerne, A.4, Schneider, J.16, Tingley, B.2,20, and Wuchterl, G.14 (Affiliations can be found after the references) v5 - Received August 23, 2011; accepted October 4, 2011 ABSTRACT We report the detection of CoRoT-23b, a hot Jupiter transiting in front of its host star with a period of 3.6314 ± 0.0001 days. This planet was discovered thanks to photometric data secured with the CoRoT satellite, combined with spectroscopic radial velocity (RV) measurements. A photometric search for possible background eclipsing binaries conducted at CFHT and OGS concluded with a very low risk of false positives. The usual techniques of combining RV and transit data simultaneously were used to derive stellar and planetary parameters. -
![Arxiv:2006.10868V2 [Astro-Ph.SR] 9 Apr 2021 Spain and Institut D’Estudis Espacials De Catalunya (IEEC), C/Gran Capit`A2-4, E-08034 2 Serenelli, Weiss, Aerts Et Al](https://docslib.b-cdn.net/cover/3592/arxiv-2006-10868v2-astro-ph-sr-9-apr-2021-spain-and-institut-d-estudis-espacials-de-catalunya-ieec-c-gran-capit-a2-4-e-08034-2-serenelli-weiss-aerts-et-al-1213592.webp)
Arxiv:2006.10868V2 [Astro-Ph.SR] 9 Apr 2021 Spain and Institut D’Estudis Espacials De Catalunya (IEEC), C/Gran Capit`A2-4, E-08034 2 Serenelli, Weiss, Aerts Et Al
Noname manuscript No. (will be inserted by the editor) Weighing stars from birth to death: mass determination methods across the HRD Aldo Serenelli · Achim Weiss · Conny Aerts · George C. Angelou · David Baroch · Nate Bastian · Paul G. Beck · Maria Bergemann · Joachim M. Bestenlehner · Ian Czekala · Nancy Elias-Rosa · Ana Escorza · Vincent Van Eylen · Diane K. Feuillet · Davide Gandolfi · Mark Gieles · L´eoGirardi · Yveline Lebreton · Nicolas Lodieu · Marie Martig · Marcelo M. Miller Bertolami · Joey S.G. Mombarg · Juan Carlos Morales · Andr´esMoya · Benard Nsamba · KreˇsimirPavlovski · May G. Pedersen · Ignasi Ribas · Fabian R.N. Schneider · Victor Silva Aguirre · Keivan G. Stassun · Eline Tolstoy · Pier-Emmanuel Tremblay · Konstanze Zwintz Received: date / Accepted: date A. Serenelli Institute of Space Sciences (ICE, CSIC), Carrer de Can Magrans S/N, Bellaterra, E- 08193, Spain and Institut d'Estudis Espacials de Catalunya (IEEC), Carrer Gran Capita 2, Barcelona, E-08034, Spain E-mail: [email protected] A. Weiss Max Planck Institute for Astrophysics, Karl Schwarzschild Str. 1, Garching bei M¨unchen, D-85741, Germany C. Aerts Institute of Astronomy, Department of Physics & Astronomy, KU Leuven, Celestijnenlaan 200 D, 3001 Leuven, Belgium and Department of Astrophysics, IMAPP, Radboud University Nijmegen, Heyendaalseweg 135, 6525 AJ Nijmegen, the Netherlands G.C. Angelou Max Planck Institute for Astrophysics, Karl Schwarzschild Str. 1, Garching bei M¨unchen, D-85741, Germany D. Baroch J. C. Morales I. Ribas Institute of· Space Sciences· (ICE, CSIC), Carrer de Can Magrans S/N, Bellaterra, E-08193, arXiv:2006.10868v2 [astro-ph.SR] 9 Apr 2021 Spain and Institut d'Estudis Espacials de Catalunya (IEEC), C/Gran Capit`a2-4, E-08034 2 Serenelli, Weiss, Aerts et al. -
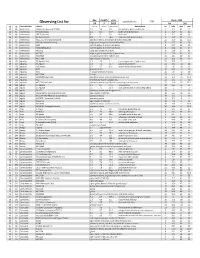
Observing List
day month year Epoch 2000 local clock time: 2.00 Observing List for 24 7 2019 RA DEC alt az Constellation object mag A mag B Separation description hr min deg min 39 64 Andromeda Gamma Andromedae (*266) 2.3 5.5 9.8 yellow & blue green double star 2 3.9 42 19 51 85 Andromeda Pi Andromedae 4.4 8.6 35.9 bright white & faint blue 0 36.9 33 43 51 66 Andromeda STF 79 (Struve) 6 7 7.8 bluish pair 1 0.1 44 42 36 67 Andromeda 59 Andromedae 6.5 7 16.6 neat pair, both greenish blue 2 10.9 39 2 67 77 Andromeda NGC 7662 (The Blue Snowball) planetary nebula, fairly bright & slightly elongated 23 25.9 42 32.1 53 73 Andromeda M31 (Andromeda Galaxy) large sprial arm galaxy like the Milky Way 0 42.7 41 16 53 74 Andromeda M32 satellite galaxy of Andromeda Galaxy 0 42.7 40 52 53 72 Andromeda M110 (NGC205) satellite galaxy of Andromeda Galaxy 0 40.4 41 41 38 70 Andromeda NGC752 large open cluster of 60 stars 1 57.8 37 41 36 62 Andromeda NGC891 edge on galaxy, needle-like in appearance 2 22.6 42 21 67 81 Andromeda NGC7640 elongated galaxy with mottled halo 23 22.1 40 51 66 60 Andromeda NGC7686 open cluster of 20 stars 23 30.2 49 8 46 155 Aquarius 55 Aquarii, Zeta 4.3 4.5 2.1 close, elegant pair of yellow stars 22 28.8 0 -1 29 147 Aquarius 94 Aquarii 5.3 7.3 12.7 pale rose & emerald 23 19.1 -13 28 21 143 Aquarius 107 Aquarii 5.7 6.7 6.6 yellow-white & bluish-white 23 46 -18 41 36 188 Aquarius M72 globular cluster 20 53.5 -12 32 36 187 Aquarius M73 Y-shaped asterism of 4 stars 20 59 -12 38 33 145 Aquarius NGC7606 Galaxy 23 19.1 -8 29 37 185 Aquarius NGC7009 -

Pulsating Variable Stars and the Hertzsprung-Russell Diagram
- !% ! $1!%" % Studying intrinsically pulsating variable stars plays a very important role in stellar evolution under- standing. The Hertzsprung-Russell diagram is a powerful tool to track which stage of stellar life is represented by a particular type of variable stars. Let's see what major pulsating variable star types are and learn about their place on the H-R diagram. This approach is very useful, as it also allows to make a decision about a variability type of a star for which the properties are known partially. The Hertzsprung-Russell diagram shows a group of stars in different stages of their evolution. It is a plot showing a relationship between luminosity (or abso- lute magnitude) and stars' surface temperature (or spectral type). The bottom scale is ranging from high-temperature blue-white stars (left side of the diagram) to low-temperature red stars (right side). The position of a star on the diagram provides information about its present stage and its mass. Stars that burn hydrogen into helium lie on the diagonal branch, the so-called main sequence. In this article intrinsically pulsating variables are covered, showing their place on the H-R diagram. Pulsating variable stars form a broad and diverse class of objects showing the changes in brightness over a wide range of periods and magnitudes. Pulsations are generally split into two types: radial and non-radial. Radial pulsations mean the entire star expands and shrinks as a whole, while non- radial ones correspond to expanding of one part of a star and shrinking the other. Since the H-R diagram represents the color-luminosity relation, it is fairly easy to identify not only the effective temperature Intrinsic variable types on the Hertzsprung–Russell and absolute magnitude of stars, but the evolutionary diagram. -

The Case for Irish Membership of the European Southern Observatory Prepared by the Institute of Physics in Ireland June 2014
The Case for Irish Membership of the European Southern Observatory Prepared by the Institute of Physics in Ireland June 2014 The Case for Irish Membership of the European Southern Observatory Contents Summary 2 European Southern Observatory Overview 3 European Extremely Large Telescope 5 Summary of ESO Telescopes and Instrumentation 6 Technology Development at ESO 7 Big Data and Energy-Efficient Computing 8 Return to Industry 9 Ireland and Space Technologies 10 Astrophysics and Ireland 13 Undergraduate Teaching 15 Outreach and Astronomy 17 Education and Training 19 ESO Membership Fee 20 Conclusions 22 References 24 1 Summary The European Southern Observatory (ESO) is universally acknowledged as being the world leading facility for observational astronomy. The astrophysics community in Ireland is united in calling for Irish membership of ESO believing that this action would strongly support the Irish government’s commitment to its STEM (science, technology, engineering and maths) agenda. An essential element of the government’s plans for the Irish economy is to substantially grow its high-tech business sector. Physics is a core part of that base, with 86,000 jobs in Ireland in this sector1 while astrophysics, in particular, is a key driver both of science interest and especially of innovation. To support this agenda, Irish scientists and engineers need access to the best research facilities and with this access comes the benefits of spin-off technology, contracts and the jobs which this can bring. ESO is currently expanding its membership to include Brazil and is considering some eastern European countries. The cost of membership will increase as more states join and as Ireland’s GDP increases.