Ltrcsum: Telugu Human-Annotated Abstractive Summarization Corpus Collection and Evaluation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Press Coverage
PRESS COVERAGE Ion Exchange Inaugurates its New R&D Centre in Patancheru, Telangana 1 Sr.no Date Publication Headline PRINT 1 09-Aug-19 Financial Express Ion Exchange invests Rs 30 cr for R&D centre The Hindu Business 2 09-Aug-19 Line Ion Exchange sets up new R&D unit 3 09-Aug-19 The Times of India Ion Exchange opens new R&D facility in Hyd 4 09-Aug-19 New Indian Express New R&D centre at Patancheru The Hindu Business 5 09-Aug-19 Line Ion Exchange sets up R&D centre 6 09-Aug-19 Andhra Jyothi Ion Exchange R & D expansion to Hyderabad 7 09-Aug-19 Andhra Prabha Aiming to pure water 8 09-Aug-19 Deccan Chronicle Ion Exchange launches R&D centre in city 9 09-Aug-19 Eenadu Ion exchange R & D facility center at Patancheru 10 09-Aug-19 Hans India Ion Exchange sets up rs30 cr for R&D centre 11 09-Aug-19 Namaste Telangana Ion exchange facility center at Patancheru 12 09-Aug-19 Nava Telangana R & D center at Hyderabad 13 09-Aug-19 Praja Sakti Aiming to 50% growth in current year. 14 09-Aug-19 Sakshi Ion exchange R & D center in Hyderabad 15 09-Aug-19 Suryaa Ion exchange R & D center 16 09-Aug-19 Telangana Today Ion Exchange sets up R&D centre in Hyd 17 09-Aug-19 The Pioneer Ion Exchange opens new R&D centre in Patancheru 18 09-Aug-19 Velugu Ion exchange R & D center in Hyderabad ONLINE 1 09-Aug-19 Business Standard Ion Exchange sets up R&D Centre in Hyderabad The Hindu Business 2 09-Aug-19 Line Ion Exchange India sets up new R&D facility in Hyderabad Ion Exchange Inaugurates its New R&D Centre in Patancheru, 3 09-Aug-19 Energetica India Telangana -

Press Release 2018
S.no Status Publication Headlines/Notes Mumbai Diary: Thursday Dossier: A sunshine 1 PUBLISHED Midday fest 2 PUBLISHED United News of India Serendipity Arts announces charpoi Challenge Serendipity Arts announces 'Charpai 3 PUBLISHED WebIndia 123 - UNI Challenge' A special Charpai Challenge’with ADI and 4 PUBLISHED Punekar News Serendipity Arts Foundation at Creaticity A special Charpai Challenge’with ADI and 5 PUBLISHED NRI News 24x7 Serendipity Arts Foundation at Creaticity Sunshine Pune - A special Charpai Challenge with ADI and 6 PUBLISHED Blogspot Serendipity Arts Foundation at Creaticity Indulge, The New Curtain raiser: Serendipity Arts Festival 2018 7 PUBLISHED Indian Express opens with grand performance, art dialogue Pune Mirror, The 8 PUBLISHED Future weave Times of India A special Charpai Challenge’with ADI and 9 PUBLISHED Pune Diary.com Serendipity Arts Foundation at Creaticity 10 PUBLISHED Mint lounge Small cities, bigger art shows Serendipity Arts Festival Announces the 11 PUBLISHED Matters of Art Charpai Challenge Everything You Need To Do In Mumbai This 12 PUBLISHED Whats Hot Week : Sept 17 To 20 The New Indian 13 PUBLISHED They too have stories to tell Express Serendipity Arts Festival 2018 curtain raiser 14 PUBLISHED United News of India event 15 PUBLISHED Sunday Midday Serendipity At The Royal Opera House Ahmedabad Mirror, 16 PUBLISHED Picking up the ropes of charpai challenge The Times of India Goa’s Serendipity Arts Festival to Hold 17 PUBLISHED Eaves Rock Curtain Raiser Events in Mumbai Business Standard - Goa's Serendipity -

5329920318.Pdf
CHL LIMITED BOARD OF DIRECTORS 39th Annual General Meeting Dr. L. K. Malhotra - Chairman & Managing Director Mr. Luv Malhotra - Joint Managing Director Date : 19th September, 2018 Mr. Gagan Malhotra - Executive Director Mr. A. K. Malhotra Day : Wednesday Ms. Kajal Malhotra Mr. Subhash Ghai Time : 12.30 PM Mr. R. C. Sharma Mr. Lalit Bhasin Place : Hotel The Suryaa Mr. Yash Kumar Sehgal Community Centre Mr. Alkesh Tacker New Friends Colony Company Secretary New Delhi-110 025 Mr. G. J. Varadarajan E-mail : [email protected] Vice-President Finance & CFO Mr. N.K. Goel Email: [email protected] Statutory Auditors INDEX PAGE NO. DGA & Co. Chartered Accountants G-6, Dhawandeep Apartment CHL Limited 6, Jantar Mantar Road New Delhi-110 001 Notice 2 Email: [email protected] Notes 3 Internal Auditors Directors' Report 7 Gulvardhan Malik and Co. Chartered Accountants Auditors' Report 35 G.F., F-54 Dilshad Colony Delhi -110095 Balance Sheet 40 Email: [email protected] Profit & Loss Account 41 Bankers Notes to the Financial Statements 43 Andhra Bank Bank of Baroda HDFC Bank Ltd. ICICI Bank Consolidated Registrar and Share Transfer Agent Auditors' Report 62 Beetal Financial & Computer Services Pvt. Ltd. rd Balance Sheet 64 Beetal House, 3 Floor, 99, Madangir Profit & Loss Account 65 Behind Local Shopping Centre New Delhi - 110 062 Notes to the Financial Statements 67 Phone : 91-11-29961281-83 Fax : 91-11-29961284 E mail : [email protected] Regd. Office Attendance Slip/Proxy 85 Hotel The Suryaa Route Map 86 Community Centre New Friends Colony New Delhi-110 025 Phone : 91-11-2683 5070, 4780 8080 Fax : 91-11-2683 6288, 4780 8081 E-mail : [email protected] Website : http://www.chl.co.in NOTICE NOTICE is hereby given that the 39th Annual General Meeting of the Members of CHL Limited will be held on Wednesday, the 19th September, 2018 at 12.30 P.M. -

Annual Report 2018-19 Rims
ANNUAL REPORT 2018-19 RIMS Dr. Harsh Vardhan, Hon'ble Union Minister, Ministry of Health & Family Walfare, Government of India Sh. Ashwini Kumar Choubey Minister of State Ministry of Health & Family Walfare Government of India LISTS OF PRINCIPLE/DIRECTOR PRINCIPAL, RMC Dr. P.D. Mathur - 23.09.72 – 31.10.74 Dr. R. Goswami - 01.11.74 – 30.11.76 Dr. S.D. Nishith - 01.12.76 – 11.10.77 Dr. O. Lyngdoh - 12.10.77 – 13.10.78 Dr. S.D. Nishith - 14.10.78 – 12.05.80 Dr. B.K Jha i/c - 13.05.80 – 24.04.81 Dr. O. Lyngdoh - 25.04.81 – 29.12.81 Dr. G.P. Sharma - 30.12.81 – 13.03.85 Dr. B.K. Omar - 14.03.85 – 17.07.86 Dr. E. Kulachaja Singh - 18.07.86 – 06.10.89 Dr. C. Das - 07.10.89 – 31.03.95 DIRECTOR, RIMS Dr. C. Das - 01.04.95 – 31.05.96 Dr. N.B. Singh - 01.06.96 – 05.02.03 Dr. Y. Ibotomba Singh i/c - 05.02.03 – 22.12.03 Dr. Fimate - 22.12.03 – 20.06.10 Dr. W. Gyaneshwar Singh - 21.06.10 – 13.09.10 Dr. S. Shekharjit Singh - 14.09.10 – 25.08.14 Prof. Ch. Arunkumar Singh - 26.08.14 – 26.04.15 Prof. S. Rita Devi - 27.04.15 – 26.04.16 Prof. Ch. Arunkumar Singh - 27.04.16 – 28.02.17 Shri R.K. Dinesh Singh - 04.04.17 – 31.07.17 Prof. A. Santa Singh - 17.08.17 – LISTS OF MEDICAL SUPERINTENDENT GENERAL HOSPITAL Dr. -

December 2019 24 Pages for Private Circulation Only
Volume 1 Issue 4 December 2019 24 pages For Private Circulation Only A tourism industry communication by Indian Association of Tour Operators Milestones in 2019 Recommendations for UNION BUDGET ANNUAL GENERAL MEETING HIGHLIGHTS IATO urges all its members and their vendors to fully support Prime Minister Narendra Modi's initiatives: SWACHH BHARAT ABHIYAN (Clean India Mission) BAN ON SINGLE-USE PLASTIC Contents New Year Wishes arm greetings Wto all our IATO members! An eventful year has gone by, and we are at the threshold E M Najeeb of a New Year which Sr Vice - President will open up challenges and new opportunities for us. Let us be determined to meet our challenges Explore Inside and grab the opportunities. Tourism, travel and hospitality industry should be resilient enough to move forward Pg. 5 AGM 2019 towards a brighter future. It is time Annual General Meeting to unite our hands with new resolve highlights and strengthen our great fraternity. The year 2020 is the beginning year Pg. 9 ACHIEVEMENTS of a new decade. It is a landmark year IATO’s milestones in 2019 in our professional journey. Let us be 5 confident, enthusiastic and cheerful. Pg. 10 THEN & NOW Wishing you all a very happy and Beyond the horizon bright New Year, 2020. Pg. 12 TAXING TIMES Quick tips and updates ishing you all a Wvery happy, pros- on GST perous and purpose- ful 2020. India firmly Pg. 13 IATO ALBUM believes in peace and IATO bids farewell to 14 Rajiv Mehra harmony and this will Suman Billa Vice - President surely translate into a good business for all. -
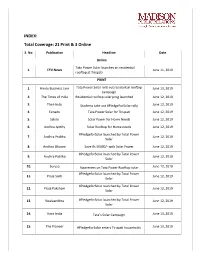
Total Coverage: 21 Print & 3 Online
INDEX: Total Coverage: 21 Print & 3 Online S. No. Publication Headline Date Online Tata Power Solar launches an residential 1. ETV News June 11, 2019 rooftop at Tirupati PRINT 1. Hindu Business Line Tata Power Solar rolls out residential rooftop June 13, 2019 campaign 2. The Times of India Residential rooftop solar prog launched June 12, 2019 3. The Hindu Students take out #PledgeForSolar rally June 12, 2019 4. Eenadu Tata Power Solar for Tirupati June 12, 2019 5. Sakshi Solar Power for Home Needs June 12, 2019 6. Andhra Jyothy Solar Rooftop for Home needs June 12, 2019 #PledgeforSolar launched by Total Power 7. Andhra Prabha June 12, 2019 Solar 8. Andhra Bhoomi Save Rs 50000/- with Solar Power June 12, 2019 #PledgeforSolar launched by Total Power 9. Andhra Patrika June 12, 2019 Solar 10. Suryaa Awareness on Tata Power Rooftop solar June 12, 2019 #PledgeforSolar launched by Total Power 11. Praja Sakti June 12, 2019 Solar #PledgeforSolar launched by Total Power 12. Praja Paksham June 12, 2019 Solar 13. Visalaandhra #PledgeforSolar launched by Total Power June 12, 2019 Solar 14. Hans India Tata’s Solar Campaign June 13, 2019 15. The Pioneer #PledgeForSolar enters Tirupati households June 13, 2019 ONLINE The Hindu Business Tata Power Solarrolls out residential rooftop 1. June 12, 2019 Line campaign 2. The Hindu Students take out #PledgeForSolar rally June 12, 2019 Tata Power Solar unveils its residential solar 3. Equity Bulls June 11, 2019 rooftop campaign #PledgeForSolar Tata Power Solar unveils its residential solar 4. PV Magazine June 12, 2019 rooftop campaign Tata Power’s arm launches residential solar 5. -

PGPM PLACEMENT BROCHURE CLASS of 2019 Creating a New Generation of Leaders Who Care, Believe and Have the Determination to Take Their Ideas to the World
PGPM Post Graduate Programme in Management PGPM PLACEMENT BROCHURE CLASS OF 2019 Creating a new generation of leaders who care, believe and have the determination to take their ideas to the world LEADERS WITH COURAGE AND HEART PGPM Post Graduate Programme in Management 2019 4 SPJIMR PGPM CLASS OF 2019 06 ABOUT SPJIMR 34 BATCH OF 2019 106 OUR RECRUITERS Guiding Philosophy, Heritage Batch Demographics, Past Recruiters and Legacy, SPJIMR Advantage, Experience, Incoming Domain Dean’s Message / Function 12 ABOUT PGPM 40 FINANCE 107 PLACEMENT Program Details Learning Batch and Course Details, PROCESS Goals, PGPM Advantage, Educational Background, Placement Process, Innovative Pedagogy, Incoming Sector, Profiles Placement Office & Committee International Immersion Details 22 LEADERSHIP 50 INFORMATION TEAM MANAGEMENT Leadership Team, SPJIMR Batch and Course Details, Advisory Board, Faculty Educational Background, Incoming Sector, Profiles 26 INDUSTRY MEETS 74 MARKETING ACADEMIA Batch and Course Details, Educational Background, Samavesh, Guest Lectures, Incoming Sector, Profiles Live Projects 30 BEYOND THE 86 OPERATIONS AND PGPM BATCH OF 2019 CLASSROOM SUPPLY CHAIN SPJIMR, Dadabhai Road, Clubs, Committees, Student- Batch and Course Details, Munshi Nagar, Andheri West, driven Activities Educational Background, Mumbai 400 058 Incoming Sector, Profiles CONTENTS PGPM CLASS OF 2019 SPJIMR 5 6 SPJIMR PGPM CLASS OF 2019 OUR GUIDING PHILOSOPHY Influencing Practice and Promoting Value-based Growth SPJIMR AT A GLANCE 38 years legacy amongst the top 10 Partners, 50+ Member of of management business schools Global Partners Bharatiya Vidya education Global and National Innovative and Bhavan, a not- 15+ years of Accreditations socially responsible for-profit trust of executive education Over 9000 alumni, school of national eminence Consistently ranked 100+ Corporate management founded in 1938 PGPM CLASS OF 2019 SPJIMR 7 OUR HERITAGE & LEGACY PJIMR is a constituent Dr. -

DIN Name CIN Company Name 01050011 KALRA SUNITA U74899DL1967PTC004762 R K INTERNATIOONAL PRIVATE 01050016 GUPTA VIVEK U51109OR20
DIN Name CIN Company Name 01050011 KALRA SUNITA U74899DL1967PTC004762 R K INTERNATIOONAL PRIVATE 01050016 GUPTA VIVEK U51109OR2006PTC009068 MAHAKASH RENEWABLES (INDIA) 01050022 BHANDARI PARAMBIR SINGH U51909DL1999PTC100363 AKILA OVERSEAS PRIVATE LIMITED 01050036 BHUPENDRA GUPTA U65990MH1991PTC059930 GALAXY ESTATE AND 01050036 BHUPENDRA GUPTA U70100MH1995PTC086049 SUNDER BUILDERS AND 01050064 KIRITKUMAR MERCHANT SHISHIR U51900MH2000PTC127408 HANS D TO R SOLUTIONS PRIVATE 01050071 AGARWAL BINDU U45201WB1997PTC084989 PRINCE SAGAR KUTIR PRIVATE 01050072 BIJOY HARIPRIYA JAIN U01403MH2008PTC182992 GREEN VALLEY AGRICULTURE 01050072 BIJOY HARIPRIYA JAIN U70109MH2008PTC180213 SAAT RASTA PROPERTIES PRIVATE 01050082 JAI KARUNADEVI PRITHVIRAJ U36993KA1999PTC025485 RODEO DRIVE LUXURY PRODUCTS 01050126 DEEPCHAND JAIN PRITHVIRAJ U36993KA1999PTC025485 RODEO DRIVE LUXURY PRODUCTS 01050174 JOGINDER SANDHU SINGH U67120CH2004PTC027291 JAGUAR CONSULTANTS PRIVATE 01050177 RAJESH VERMA U24232DL1999PTC100334 S K MEDICOS PVT LTD 01050220 NARAYANAMURTHY U15421TN2006PLC060417 BHIMAAS SUGARS AND CHEMICALS 01050224 JITENDRA MEHTA U51109TN2007PTC062423 MOOLRAJ VYAPAR PRIVATE 01050227 KALRA RAMESH U74899DL1967PTC004762 R K INTERNATIOONAL PRIVATE 01050251 PRAKASH SRIVASTAVA U72300DL2007PTC160451 ProDigii ECall Private Limited 01050251 PRAKASH SRIVASTAVA U63040DL2008PTC180031 Reaching Wild Life Tourism Services 01050252 JADHAV RAJAN SHANKAR U55101PN2004PTC018986 HOTEL PUSHKAR GROUP PRIVATE 01050257 LALITKUMAR MERCHANT URMIL U51900MH2000PTC127408 HANS D TO R SOLUTIONS -

International Coverage Source Headline Country URL
International Coverage Source Headline Country URL COVID-19 patients who undergo surgery are at increased risk of http://7thspace.com/headlines/1203887/covid_19_patients_who_undergo_surgery_are_at_increased_risk_of_postoper 7thSpace Netherlands postoperative death ative_death.html ABC.es - Agencias La COVID-19 eleva riesgo de sufrir complicaciones pulmonares tras operación Spain https://agencias.abc.es/noticia.asp?noticia=3393851 albertonews La COVID-19 eleva riesgo de sufrir complicaciones pulmonares tras operación Venezuela https://albertonews.com/internacionales/la-covid-19-eleva-riesgo-de-sufrir-complicaciones-pulmonares-tras-operacion/ Andhravilas COVID-19 patients who undergo surgery at high death risk: Lancet United States http://www.andhravilas.net/en/COVID-19-patients-who-undergo-surgery-at-high-death-risk-Lancet Study reveals COVID-19 patients who undergo surgery are at increased risk https://www.aninews.in/news/health/study-reveals-covid-19-patients-who-undergo-surgery-are-at-increased-risk-of- AniNews.in India of postoperative death postoperative-death20200531091419/ Arkansas Indian COVID-19 patients who undergo surgery at high death risk: Lancet India https://www.arkansasindian.com/desi/newsdetail.asp?id=558021 Patients who undergo surgery after COVID infection at increased death risk: Asian Age India http://ct.moreover.com/?a=42239719265&p=3bo&v=1&x=xzKDXzzwJVwVg0l8yZrhig Study ATT.com Death rate after elective surgery soars if a patient has Covid-19 United States https://currently.att.yahoo.com/att/death-rate-elective-surgery-soars-193801677.html -

NU Announces Early Admissions in Vijayawada
Media Coverage Dossier NU announces Early Admissions in Vijayawada October 23rd 2016 Press Release NU announces Early Admissions in Vijayawada - Unveils scholar search programme for meritorious students - Holds session on “Careers of the Future” Vijayawada, October 23, 2016: Established with a vision to bring about innovation in higher education and learning in emerging areas of the knowledge society, the not-for-profit NIIT University (NU), today announced Early Admission(EAD) for its four years full-time B.Tech Programmes in - Computer Science and Engineering, Electronics & Communication Engineering and Bio Technology in Vijayawada. The announcement was made by Mr. Vijay Thadani, Co-founder NIIT University and Prof V S Rao, President NIIT University while speaking on “Careers of the Future” during an event organized by NU in the city. During the seminar Mr. Thadani and Mr. Rao talked about the different types of future career aspects that would help the students choose the right field based on their interest and aptitude, and enlighten them on the plethora of career opportunities available. They also addressed the industry and career related questions and concerns of the students and their parents during the Q&A session. The career counselling was organized to help students understand the job opportunities available and skills required for a successful career post completion of the respective course. To apply for the B.Tech Programme at NU visit: www.niituniversity.in NIIT University imparts knowledge in technologies of the future through a cutting-edge curriculum using the core principles of providing industry-linked, technology- based, research-driven and seamless education. -

Sir Shadi Lal Enterprises Limited
86th ANNUAL REPORT 2019-2020 SIR SHADI LAL ENTERPRISES LIMITED SIR SHADI LAL ENTERPRISES LIMITED BOARD OF DIRECTORS : Shri Ramesh Chandra Sharma–Chairman (DIN No. 00023274) Shri Rajat Lal – Managing Director (DIN No. 00112489) Shri Vivek Viswanathan – Joint Managing Director (DIN No. 00141053) Shri Rahul Lal – Joint Managing Director (DIN No. 06575738) Shri Hemantpat Singhania – Non Executive Independent Director (DIN No. 00141096) Shri Onke Aggarwal – Non Executive Independent Director (DIN No. 00141124) Mrs. Radhika Viswanathan Hoon – Non Executive Director (DIN No. 06436444) Shri Ajit Hoon – Non Executive Director (DIN No. 00540300) Shri Neeraj Gupta - Non Executive Director (DIN No. 00317395) BANKERS : State Bank of India Punjab National Bank Zila Sahkari Bank Ltd. AUDITORS : M/S M. Sharan Gupta & Co. B-3, Ground Floor, Hotel Suryaa, New Friends Colony, New Delhi – 110 025 REGISTERED OFFICE : 4 – A, Hansalaya, 15, Barakhamba Road, New Delhi – 110 001 MANUFACTURING UNITS : Upper Doab Sugar Mills, Shamli – 247 776 (U.P.) Shamli Distillery & Chemical Works, Shamli – 247 776 (U.P.) 1 SIR SHADI LAL ENTERPRISES LIMITED SIR SHADI LAL ENTERPRISES LIMITED (Corporate Identity No. L51909DL1933PLC009509) Regd. Offi ce : 4 – A, Hansalaya, 15, Barakhamba Road, New Delhi – 110 001 Ph.:011 - 23316409 Fax: 011 - 23722193 Email Id: [email protected] Website: www.sirshadilal.com NOTICE FOR THE 86TH ANNUAL GENERAL MEETING NOTICE IS HEREBY GIVEN THAT THE 86TH ANNUAL this Annual General Meeting (‘AGM’) and in respect of whom GENERAL MEETING OF SIR SHADI LAL ENTERPRISES the Company has received a Notice in writing from a Member LIMITED WILL BE HELD THROUGH VIDEO under Section 160 of the Companies Act, 2013 proposing his CONFERENCING OR OTHER AUDIO VISUAL MEANS candidature for the offi ce of Director be and is hereby appointed ON MONDAY, SEPTEMBER 28, 2020 AT 11.00 A.M. -

India Media Outlets
India Media Directory India Newswire 1st Headlines A India News Aaj Tak Aajkaal Aajkal Adinor Sombad Adyar Times Afternoon Despatch and Courier Afternoon Voice Agra News Agri Watch Ahmedabad Mirror Ajir Asom Ajir Dainik Batori Ajit Akila Al Hindelyom All India News Amar Ujala Amar Ujala Ananda Bazar Patrika Ananda Vikatan Anandabazar Patrika Andaman Chronicle Andhra Bhoomi Andhra Jyothi Andhra News Andolana Anna Nagar Times Anweshanam Apna Samachar Arunachal Times Asia Times Asian Age Asomiya Pratidin Assam Live Assam Tribune Assamiya Khabor Aurangabad Times BTV IN Bangalore Mirror Bartaman Patrika Bengal Net Bharat Observer Big News Network Bihar Times Bombay News Bombay Samachar Business Line Business Standard Business Today Business World Business and Economy CNBC TV18 CNN IBN Cashmere News Central Chronicle Charhdikala Charhdikala Chennai Online Chennai Vision Chitralekha Chitralekha Chitralekha Citizen Matters Corporate India DD News DLA AM DNA Daily Aftab Daily Desher Katha Daily Thanthi Dainik Agradoot Dainik Aikya Dainik Bhaskar Dainik Bhaskar Dainik Ekmat Dainik Jagran Dainik Jagran Dainik Navajyoti Dainik Sandhya Prakash Dainik Statesman Dainik Suprovat Dalal Street Darjeeling Times Day After Deccan Chronicle Deccan Chronicle Deccan Herald Deepika Dehradun Classified Desh Videsh Times Deshabhimani Deshbandhu Deshonnati Dharitri Dinakaran Dinakaran Dinalipi Dinamalar Dinamani Dinathanthi Dinathanthi Divya Bhaskar Divya Bhaskar E Ahmadnagar E Pao Eastern Mirror Economic Times Economic Times Economic Times Economic and Political