Visage: a Face Interpretation Engine for Smartphone Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
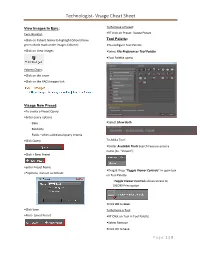
Technologist- Visage Cheat Sheet
Technologist- Visage Cheat Sheet View Images In Epic: To Remove a Preset: Tech Worklist: •RT click on Preset- Delete Preset •Click on Patient Name to highlight (Should have Tool Palette: green check mark under Images Column) •To configure Tool Palette •Click on View Images •Select File-Preferences-Tool Palette •Tool Palette opens Patient Chart: •Click on the exam •Click on the PACS Images link. Visage New Preset: •To create a Preset Query •Enter query options ◦Date •Select Show Both ◦Modality ◦Fields –offers additional query criteria •Click Query To Add a Tool: •Under Available Tools Search Feature-enter a name (Ex. “Viewer”) •Click + New Preset •Enter Preset Name •Drag & Drop “Toggle Viewer Controls” in open box •*Options- Can set as Default on Tool Palette ◦Toggle Viewer Controls allows access to DICOM Print option •Click OK to Save •Click Save To Remove a Tool: •Note- Saved Preset •RT Click on Tool in Tool Palette •Select Remove •Click OK to Save P a g e 1 | 3 Technologist- Visage Cheat Sheet Mark Images for Removal: DICOM Send: •Pull the image into the Active Viewer •Search for patient via the Visage Study Browser •RT click on image & choose Permanent Text Label ◦Name, MRN#, ACC# from Tool Palette *This is Permanent •Click on Accession # to send entire exam •Click the + beside the patient name to open series •Click on the Series that need sent •Draw a box over the image ◦To select multiple series, hold the Ctrl key •Type in DELETE in pop-up box •Change font size to a larger size •Click on Save Modified Images •Click Save •Click Save -
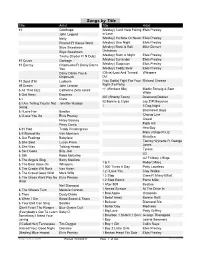
Songs by Title
Songs by Title Title Artist Title Artist #1 Goldfrapp (Medley) Can't Help Falling Elvis Presley John Legend In Love Nelly (Medley) It's Now Or Never Elvis Presley Pharrell Ft Kanye West (Medley) One Night Elvis Presley Skye Sweetnam (Medley) Rock & Roll Mike Denver Skye Sweetnam Christmas Tinchy Stryder Ft N Dubz (Medley) Such A Night Elvis Presley #1 Crush Garbage (Medley) Surrender Elvis Presley #1 Enemy Chipmunks Ft Daisy Dares (Medley) Suspicion Elvis Presley You (Medley) Teddy Bear Elvis Presley Daisy Dares You & (Olivia) Lost And Turned Whispers Chipmunk Out #1 Spot (TH) Ludacris (You Gotta) Fight For Your Richard Cheese #9 Dream John Lennon Right (To Party) & All That Jazz Catherine Zeta Jones +1 (Workout Mix) Martin Solveig & Sam White & Get Away Esquires 007 (Shanty Town) Desmond Dekker & I Ciara 03 Bonnie & Clyde Jay Z Ft Beyonce & I Am Telling You Im Not Jennifer Hudson Going 1 3 Dog Night & I Love Her Beatles Backstreet Boys & I Love You So Elvis Presley Chorus Line Hirley Bassey Creed Perry Como Faith Hill & If I Had Teddy Pendergrass HearSay & It Stoned Me Van Morrison Mary J Blige Ft U2 & Our Feelings Babyface Metallica & She Said Lucas Prata Tammy Wynette Ft George Jones & She Was Talking Heads Tyrese & So It Goes Billy Joel U2 & Still Reba McEntire U2 Ft Mary J Blige & The Angels Sing Barry Manilow 1 & 1 Robert Miles & The Beat Goes On Whispers 1 000 Times A Day Patty Loveless & The Cradle Will Rock Van Halen 1 2 I Love You Clay Walker & The Crowd Goes Wild Mark Wills 1 2 Step Ciara Ft Missy Elliott & The Grass Wont Pay -

Songs by Title
Karaoke Song Book Songs by Title Title Artist Title Artist #1 Nelly 18 And Life Skid Row #1 Crush Garbage 18 'til I Die Adams, Bryan #Dream Lennon, John 18 Yellow Roses Darin, Bobby (doo Wop) That Thing Parody 19 2000 Gorillaz (I Hate) Everything About You Three Days Grace 19 2000 Gorrilaz (I Would Do) Anything For Love Meatloaf 19 Somethin' Mark Wills (If You're Not In It For Love) I'm Outta Here Twain, Shania 19 Somethin' Wills, Mark (I'm Not Your) Steppin' Stone Monkees, The 19 SOMETHING WILLS,MARK (Now & Then) There's A Fool Such As I Presley, Elvis 192000 Gorillaz (Our Love) Don't Throw It All Away Andy Gibb 1969 Stegall, Keith (Sitting On The) Dock Of The Bay Redding, Otis 1979 Smashing Pumpkins (Theme From) The Monkees Monkees, The 1982 Randy Travis (you Drive Me) Crazy Britney Spears 1982 Travis, Randy (Your Love Has Lifted Me) Higher And Higher Coolidge, Rita 1985 BOWLING FOR SOUP 03 Bonnie & Clyde Jay Z & Beyonce 1985 Bowling For Soup 03 Bonnie & Clyde Jay Z & Beyonce Knowles 1985 BOWLING FOR SOUP '03 Bonnie & Clyde Jay Z & Beyonce Knowles 1985 Bowling For Soup 03 Bonnie And Clyde Jay Z & Beyonce 1999 Prince 1 2 3 Estefan, Gloria 1999 Prince & Revolution 1 Thing Amerie 1999 Wilkinsons, The 1, 2, 3, 4, Sumpin' New Coolio 19Th Nervous Breakdown Rolling Stones, The 1,2 STEP CIARA & M. ELLIOTT 2 Become 1 Jewel 10 Days Late Third Eye Blind 2 Become 1 Spice Girls 10 Min Sorry We've Stopped Taking Requests 2 Become 1 Spice Girls, The 10 Min The Karaoke Show Is Over 2 Become One SPICE GIRLS 10 Min Welcome To Karaoke Show 2 Faced Louise 10 Out Of 10 Louchie Lou 2 Find U Jewel 10 Rounds With Jose Cuervo Byrd, Tracy 2 For The Show Trooper 10 Seconds Down Sugar Ray 2 Legit 2 Quit Hammer, M.C. -

Top 40 Singles Top 40 Albums
21 June 1981 CHART #288 Top 40 Singles Top 40 Albums Love Will Tear Us Apart The Bridge Unknown Pleasures Vienna 1 Joy Division 21 Deane Waretini 1 Joy Division 21 Ultravox Last week 41 / 2 weeks RTC Last week 19 / 20 weeks Gold / CBS Last week - / 1 weeks Gold / RTC Last week 31 / 20 weeks FESTIVAL Stars On 45 Boom Boom Faith Another Ticket 2 Stars on 45 22 Black Slate 2 The Cure 22 Eric Clapton Last week 5 / 3 weeks POLYGRAM Last week 16 / 11 weeks POLYGRAM Last week 1 / 4 weeks Gold / CBS Last week - / 1 weeks POLYGRAM Bette Davis Eyes Baggy Trousers Ep Sucking In The Seventies Zebop! 3 Kim Carnes 23 Madness 3 Rolling Stones 23 Santana Last week 3 / 5 weeks EMI Last week 28 / 7 weeks POLYGRAM Last week 11 / 2 weeks Gold / EMI Last week 23 / 2 weeks CBS (Morning Train) Nine To Five Just The Two Of Us Reveries Journeys To Glory 4 Sheena Easton 24 Grover Washington Jnr 4 Richard Clayderman 24 Spandau Ballet Last week 1 / 6 weeks EMI Last week 39 / 3 weeks WEA Last week 5 / 13 weeks Platinum / WEA Last week 20 / 3 weeks FESTIVAL This Ole House Fade To Grey Waiata Hotter Than July 5 Shakin' Stevens 25 Visage 5 Split Enz 25 Stevie Wonder Last week 4 / 6 weeks CBS Last week 10 / 12 weeks UNIVERSAL Last week 2 / 9 weeks Platinum / POLYGRAM Last week 16 / 27 weeks Platinum / EMI How 'Bout Us Ant Music Being With You Shades 6 Champaign 26 Adam and the Ants 6 Smokey Robinson 26 JJ Cale Last week 6 / 5 weeks CBS Last week 21 / 17 weeks CBS Last week 7 / 6 weeks EMI Last week 21 / 6 weeks FESTIVAL On The Inside Blam Blam Blam EP Making Movies Seventeen -

Analysis of Electroacoustic Works with Music and Language Intersections
ANALYSIS OF ELECTROACOUSTIC WORKS WITH MUSIC AND LANGUAGE INTERSECTIONS Rodrigo Segnini Bruno Ruviaro Center for Computer Research Center for Computer Research in Music and Acoustics (CCRMA) in Music and Acoustics (CCRMA) Stanford University Stanford University ABSTRACT 2. METHODOLOGY We have selected 15 pieces that invite fundamental This paper proposes a theoretical model for the analysis questions about the boundaries between music and of music and language intersections in contemporary speech. Each piece meets the following criteria: music. This model is tested on a repertoire of • Vocal sounds in any imaginable form should play a electroacoustic and acoustic pieces, providing examples relevant role in it. Synthetic sounds that emulate of blurred boundaries between music and speech. We speech or other vocal behaviors also qualify. have defined two axes representing possible dimensions • It should be representative of the various post-tonal of this relationship: intelligibility and music/speech musical structuring processes that flourished qualities. The resulting sonic space provides a visual throughout the 20th century. account that can serve as a “travel guide” in the music- speech continuum. We envision applications of this Composer Piece * model in the fields of composition, musicology, and SCHOENBERG, Arnold Pierrot Lunaire (1912) 1v + cognitive studies. (1874-1951) ins SCHWITTERS, Kurt Ursonate (1922-32) 1v (1887-1948) 1. INTRODUCTION SCHAEFFER, Pierre (1910- Symphonie pour ea The human voice has played a significant role in -

VISAGE 2016.1 Installation Guide
VISAGE Version 2016.1 VISAGE Proprietary notice Copyright © 2016 Schlumberger. All rights reserved. Reproduction or alteration without prior written permission is prohibited, except as allowed under applicable law. Use of this product is governed by the License Agreement. Schlumberger makes no warranties, express, implied, or statutory, with respect to the product described herein and disclaims without limitations any warranties of merchantability or fitness for a particular purpose. Trademarks & service marks "Schlumberger," the Schlumberger logotype, and other words or symbols used to identify the products and services described herein are either trademarks, trade names, or service marks of Schlumberger and its licensors, or are the property of their respective owners. These marks may not be copied, imitated, or used, in whole or in part, without the express prior written permission of their owners. In addition, covers, page headers, custom graphics, icons, and other design elements may be service marks, trademarks, and/or trade dress of Schlumberger and may not be copied, imitated, or used, in whole or in part, without the express prior written permission of Schlumberger. Security notice The software described herein is configured to operate with at least the minimum specifications set out by Schlumberger. You are advised that such minimum specifications are merely recommendations and not intended to be limiting to configurations that may be used to operate the software. Similarly, you are advised that the software should be operated in a secure environment whether such software is operated across a network, on a single system and/or on a plurality of systems. It is up to you to configure and maintain your networks and/or system(s) in a secure manner. -

Broken Hopes of a Waster Youth (CD Album – Advoxya Records) - Revie
Larva – Broken Hopes Of A Waster Youth (CD Album – Advoxya Records) - revie ... Página 1 de 8 Not logged in Log-In Register • NEWS • APP • INDUSTRIAL MUSIC FORUM • TWITTER • G+ • FACEBOOK • SPOTIFY • @ Search Larva – Broken Hopes Of A Waster Youth (CD Album – Advoxya Records) Posted on 11/05/13 Industrial Music CDs at eBay USA | eBay UK | eBay DE Like Send Be the first of your friends to like this. Genre/Influences: Dark-electro. Content: The previous work I heard of Larva never totally convinced me. The dark-electronics of this Spanish formation were missing some substance and especially some cohesion. After an album released on Danse Macabre they got back to Advoxya Records releasing their 4th official album to date. This new work remains a pure dark-electro composition, which simply can be defined as ‘hell-electro’. The inspiration clearly comes from a band like Suicide Commando. The originality inside Larva is far to find, but when a band appears to be an efficient emulator of a leading name of the scene I think no one will start to complain. And that’s precisely what this album is all about. From start to finish you easily can recognize the Suicide Commando-input which appears in the dark sequences and icy melodies. Both debut songs are captivating and promising . Some calmer pieces are awakening spirits of the late 90s electro generation, but here again Larva is a quite efficient copier. The 2nd part of the album is a tiny less interesting as the songs now become quieter and more into haunting atmospheres . -

Ultimix 2015 Download
Ultimix 2015 download LINK TO DOWNLOAD 3) After a succesfull upload you'll receive a unique link to the download site, which you can place anywhere: on your homepage, blog, forum or send it via IM or e-mail to your friends. renuzap.podarokideal.ru is completely free, reliable and popular way to store files renuzap.podarokideal.ru://renuzap.podarokideal.ru Ultimix - Web - torrent download. Hash: EFFCDEDCBCD68DB0FA3DBFC3B6CBECBrenuzap.podarokideal.ru · Felix – Don’t You Want Me (Remix) (Ultimix by Strobe) Katy Tiz – Whistle (While You Work It) (Ultimix by Stacy Mier) Marlon Roudette – When The Beat Drops Out (Ultimix by Stacy Mier) Martin Garrix f. Usher – Don’t Look Down (Ultimix by Huda Hudia)renuzap.podarokideal.ru Ultimix () | VA – Ultimix () Indie, Alternative Dance, Electropop, Synthpop | Ultimix Records kbps | MP3 | unmixed | | | Mb renuzap.podarokideal.ru Tove Lo – Talking Body (Ultimix By Beat Thrillerz) Hooyeah! – Melbourne Drop (Ultimix By Huda Hudia & Tommy Who) Fall Out Boy – Uma Thurman (Ultimix By Mark Roberts) Va – Country’n The Mix #2 (Ultimix By Mark Roberts) mp3 download links: renuzap.podarokideal.ru Ultimix Vol () Password: renuzap.podarokideal.rups://renuzap.podarokideal.ru · Ultimix Dj Eccozinho () ZIPPYSHARE. DOWNLOAD. Enviar a mensagem por email BlogThis! ZIPPYSHARE Sameblood Studio - Os Primos Ruas (prod. by KC) () DOWNLOAD S Ziqo – Nita Sala Na Mani () Ziqo – Nita Sala Na Mani () Dady Mussagy DIRECTO DOWNLOAD (Mixtape) Hernâni da Silva - Músicas Perdidas 2 () renuzap.podarokideal.ru Ultimix Mega Collection/Ultimix -

THE COLLECTED POEMS of HENRIK IBSEN Translated by John Northam
1 THE COLLECTED POEMS OF HENRIK IBSEN Translated by John Northam 2 PREFACE With the exception of a relatively small number of pieces, Ibsen’s copious output as a poet has been little regarded, even in Norway. The English-reading public has been denied access to the whole corpus. That is regrettable, because in it can be traced interesting developments, in style, material and ideas related to the later prose works, and there are several poems, witty, moving, thought provoking, that are attractive in their own right. The earliest poems, written in Grimstad, where Ibsen worked as an assistant to the local apothecary, are what one would expect of a novice. Resignation, Doubt and Hope, Moonlight Voyage on the Sea are, as their titles suggest, exercises in the conventional, introverted melancholy of the unrecognised young poet. Moonlight Mood, To the Star express a yearning for the typically ethereal, unattainable beloved. In The Giant Oak and To Hungary Ibsen exhorts Norway and Hungary to resist the actual and immediate threat of Prussian aggression, but does so in the entirely conventional imagery of the heroic Viking past. From early on, however, signs begin to appear of a more personal and immediate engagement with real life. There is, for instance, a telling juxtaposition of two poems, each of them inspired by a female visitation. It is Over is undeviatingly an exercise in romantic glamour: the poet, wandering by moonlight mid the ruins of a great palace, is visited by the wraith of the noble lady once its occupant; whereupon the ruins are restored to their old splendour. -

Visage Ease for Ipad, Iphone, and Ipod Touch
Getting Started – Visage Ease for iPad, iPhone, and iPod Touch Visage 7 is a client server solution for viewing medical images. It can be used for both primary reading of radiological images as well as image review by clinicians. Running the Visage Ease App on your iPad, iPhone, or iPod Touch gives you efficient access to key images and original images stored on a Visage 7 Server. Visage Ease is a powerful tool for patient education at the bedside. Compared to printed film or patient CDs, Visage Ease provides much richer and more efficient means of communication. Note that the intended use for Visage Ease is only image display for illustration and educational purpose and not diagnosis. It must not be used as a medical device. Connecting. Start Visage Ease and enter the address of the Visage 7 Server, user name and password. Use the same user credentials as for logging in with the Visage 7 Client. If you do not know the login details, please contact your system administrator. Press “Connect” to connect to the Visage 7 Server. If you switch on “Remember password”, Visage Ease remembers your password for future log ins. Consider using the Passcode lock or similar methods compliant with your local IT policies to prevent unauthorized access to your mobile device. Searching. After logging in, Visage Ease shows a list of search presets. Select one of the predefined searches, e.g. “All Studies”, to display a list of all studies accessible to you on the Visage 7 Server. You may sort the study list by patient name (default) or study date by pressing the respective button in the navigation bar. -

Eibeibunka 48
47 『英米文化』48, 47–60 (2018) ISSN: 0917–3536 “It’s a Service that I Kneel for to You”: Failure of Courtly Love in The Changeling TANAMACHI Atsushi Abstract This paper investigates the treatment of courtly love convention in the main plot of The Changeling to demonstrate how the convention is radically parodied in it. For this purpose, the paper explores the use of the word “service,” which bears multiple meanings, including those concerning the master-servant relationship as well as the relationship based on courtly love. An example of this play’s treatment of the courtly love convention can be seen when Beatrice drops her glove hoping that Alsemero would be the receiver. However, her plan is sabotaged by patriarchal interference, and her glove falls into the hands of Deflores, a ser- vant whom she despises. Moreover, since Deflores describes the glove as a “favour” from the socially superior lady, and later begs Beatrice that “[t]rue service merits mercy” (2.1.63), it is apparent that Deflores envisions himself as a courtly lover and attempts to reformulate his situation into that of a courtly lover offering an exalted kind of service to his lady. In this way, courtly love conventions undergo a breakdown and the expectations are frustrated until the climax of the play when they receive a final death blow. In the subplot of The Changeling (1622), a collaborative work of Thomas Middleton and William Rowley, a gentleman named Antonio disguises himself as a “changeling,” or an idiot, and infiltrates a mad-house in order to secretly approach and woo Isabella, the wife of the warden. -

Synthpop: Into the Digital Age Morrow, C (1999) Stir It Up: Reggae Album Cover Art
118 POPULAR MUSIC GENRES: AN INTRODUCTION Hebdige, D. (1987) Cut 'n' mix: Identity and Caribbean MUSIc. Comedia. CHAPTER 7 S. (1988) Black Culture, White Youth: The Reggae Tradition/romJA to UK. London: Macmillan. Synthpop: into the digital age Morrow, C (1999) StIr It Up: Reggae Album Cover Art. San Francisco: Chronicle Books. Potash, C (1997) Reggae, Rastafarians, Revolution: Jamaican Musicfrom Ska to Dub. London: Music Sales Limited. Stolzoff, N. C (2000) Wake the Town and Tell the People: Dancehall Culture in Jamaica. Durham, NC, and London: Duke University Press. Recommended listening Antecedents An overview of the genre Various (1989) The Liquidators: Join The Ska Train. In this chapter, we are adopting the term synthpop to deal with an era Various (1998) Trojan Rocksteady Box Set. Trojan. (around 1979-84) and style of music known by several other names. A more widely employed term in pop historiography has been 'New Generic texts Romantic', but this is too narrowly focused on clothing and fashion, Big Youth ( BurI).ing Spear ( and was, as is ever the case, disowned by almost all those supposedly part Alton (1993) Cry Tough. Heartbeat. of the musical 'movement'. The term New Romantic is more usefully King Skitt (1996) Reggae FIre Beat. Jamaican Gold. employed to describe the club scene, subculture and fashion associated K wesi Johnson, Linton (1998) Linton Kwesi Johnson Independam Intavenshan: with certain elements ofearly 1980s' music in Britain. Other terms used to The Island Anthology. Island. describe this genre included 'futurist' and 'peacock punk' (see Rimmer Bob Marley and The Wailers (1972) Catch A Fire.