Popculture — Wikipedia As a Mirror of Society
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cultural Anthropology Through the Lens of Wikipedia: Historical Leader Networks, Gender Bias, and News-Based Sentiment
Cultural Anthropology through the Lens of Wikipedia: Historical Leader Networks, Gender Bias, and News-based Sentiment Peter A. Gloor, Joao Marcos, Patrick M. de Boer, Hauke Fuehres, Wei Lo, Keiichi Nemoto [email protected] MIT Center for Collective Intelligence Abstract In this paper we study the differences in historical World View between Western and Eastern cultures, represented through the English, the Chinese, Japanese, and German Wikipedia. In particular, we analyze the historical networks of the World’s leaders since the beginning of written history, comparing them in the different Wikipedias and assessing cultural chauvinism. We also identify the most influential female leaders of all times in the English, German, Spanish, and Portuguese Wikipedia. As an additional lens into the soul of a culture we compare top terms, sentiment, emotionality, and complexity of the English, Portuguese, Spanish, and German Wikinews. 1 Introduction Over the last ten years the Web has become a mirror of the real world (Gloor et al. 2009). More recently, the Web has also begun to influence the real world: Societal events such as the Arab spring and the Chilean student unrest have drawn a large part of their impetus from the Internet and online social networks. In the meantime, Wikipedia has become one of the top ten Web sites1, occasionally beating daily newspapers in the actuality of most recent news. Be it the resignation of German national soccer team captain Philipp Lahm, or the downing of Malaysian Airlines flight 17 in the Ukraine by a guided missile, the corresponding Wikipedia page is updated as soon as the actual event happened (Becker 2012. -

Hacking Motivation
Hacking Life • Hacking Life Chapter 4: Hacking Motivation Joseph Reagle Published on: Apr 03, 2019 Updated on: Apr 09, 2019 Hacking Life • Hacking Life Chapter 4: Hacking Motivation On a lovely summer day, I headed to San Francisco’s Presidio Park for a picnic unlike any other I have attended. The small gathering was for fans of the motivation app Beeminder, and Nick Winter, author of The Motivation Hacker, was the special guest. Winter is the “founder/hacker” behind Skritter, an app for learning Chinese characters, and CodeCombat, a platform that gamifies learning to code. It’s clear that despite being someone who sometimes spends many hours in front of a computer, like Ferriss and Tynan, he isn’t content with the skinny-nerd stereotype. Winter’s webpage features a picture of him doing a single-arm handstand: he’s wearing a Google T-shirt, thin-soled “five-finger” shoes—also preferred by Tynan—and a surprisingly serene expression for someone who is upside down (figure 4.1). When I met at him at the picnic, he was wearing the same nonshoes and tossing a Frisbee. 2 Hacking Life • Hacking Life Chapter 4: Hacking Motivation Nick Winter doing a handstand, 2013, http://www.nickwinter.net/. Used with permission. The Motivation Hacker is a lab report of self-experimentation and a tutorial on how to maximize motivation. Winter’s goal had been to write the book in three months “while simultaneously 3 Hacking Life • Hacking Life Chapter 4: Hacking Motivation skydiving, learn three thousand new Chinese characters, go on ten romantic dates with his -

Teacher Guide: Meet the Proboscideans
Teacher Guide: Meet the Proboscideans Concepts: • Living and extinct animals can be classified by their physical traits into families and species. • We can often infer what animals eat by the size and shape of their teeth. Learning objectives: • Students will learn about the relationship between extinct and extant proboscideans. • Students will closely examine the teeth of a mammoth, mastodon, and gomphothere and relate their observations to the animals’ diets. They will also contrast a human’s jaw and teeth to a mammoth’s. This is an excellent example of the principle of “form fits function” that occurs throughout biology. TEKS: Grade 5 § 112.16(b)7D, 9A, 10A Location: Hall of Geology & Paleontology (1st Floor) Time: 10 minutes for “Mammoth & Mastodon Teeth,” 5 minutes for “Comparing Human & Mammoth Teeth” Supplies: • Worksheet • Pencil • Clipboard Vocabulary: mammoth, mastodon, grazer, browser, tooth cusps, extant/extinct Pre-Visit: • Introduce students to the mammal group Proboscidea, using the Meet the Proboscideans worksheets. • Review geologic time, concentrating on the Pleistocene (“Ice Age”) when mammoths, mastodons, and gomphotheres lived in Texas. • Read a short background book on mammoths and mastodons with your students: – Mammoths and Mastodons: Titans of the Ice Age by Cheryl Bardoe, published in 2010 by Abrams Books for Young Readers, New York, NY. Post-Visit Classroom Activities: • Assign students a short research project on living proboscideans (African and Asian elephants) and their conservation statuses (use http://www.iucnredlist.org/). Discuss the possibilities of their extinction, and relate to the extinction events of mammoths and mastodons. Meet the Proboscideans Mammoths, Mastodons, and Gomphotheres are all members of Proboscidea (pro-bo-SID-ia), a group which gets its name from the word proboscis (the Latin word for nose), referring to their large trunks. -

Community and Communication
Community and 12 Communication A large, diverse, and thriving group of volun- teers produces encyclopedia articles and administers Wikipedia. Over time, members of the Wikipedia community have developed conventions for interacting with each other, processes for managing content, and policies for minimizing disruptions and maximizing use- ful work. In this chapter, we’ll discuss where to find other contributors and how to ask for help with any topic. We’ll also explain ways in which community members interact with each other. Though most discussion occurs on talk pages, Wikipedia has some central community forums for debate about the site’s larger policies and more specific issues. We’ll also talk about the make-up of the community. First, however, we’ll outline aspects of Wikipedia’s shared culture, from key philosophies about how contributors How Wikipedia Works (C) 2008 by Phoebe Ayers, Charles Matthews, and Ben Yates should interact with each other to some long-running points of debate to some friendly practices that have arisen over time. Although explicit site policies cover content guidelines and social norms, informal philosophies and practices help keep the Wikipedia community of contributors together. Wikipedia’s Culture Wikipedia’s community has grown spontaneously and organically—a recipe for a baffling culture rich with in-jokes and insider references. But core tenets of the wiki way, like Assume Good Faith and Please Don’t Bite the Newcomers, have been with the community since the beginning. Assumptions on Arrival Wikipedians try to treat new editors well. Assume Good Faith (AGF) is a funda- mental philosophy, as well as an official guideline (shortcut WP:AGF) on Wikipedia. -

The Childs Elephant Free Download
THE CHILDS ELEPHANT FREE DOWNLOAD Rachel Campbell-Johnston | 400 pages | 03 Apr 2014 | Random House Children's Publishers UK | 9780552571142 | English | London, United Kingdom Rachel Campbell-Johnston Penguin 85th by Coralie Bickford-Smith. Stocking Fillers. The Childs Elephant the other The Childs Elephant of the scale, when elephants eat in one location and defecate in another, they function as crucial dispersers of seeds; many plants, trees, The Childs Elephant bushes would have a hard time surviving if their seeds didn't feature on elephant menus. Share Flipboard Email. I cannot trumpet this book loudly enough. African elephants are much bigger, fully grown males approaching six or seven tons making them the earth's largest terrestrial mammalscompared to only four or five tons for Asian elephants. As big as they are, elephants have an outsize influence on their habitats, uprooting trees, trampling ground underfoot, and even deliberately enlarging water holes so they can take relaxing baths. Events Podcasts Penguin Newsletter Video. If only we could all be Jane Goodall or Dian Fossey, and move to the jungle or plains and thoroughly dedicate our lives to wildlife. For example, an elephant can use its trunk to shell a peanut without damaging the kernel nestled inside or to wipe debris from its eyes or other parts of its body. Elephants are polyandrous and The Childs Elephant mating happens year-round, whenever females are in estrus. Habitat and Range. Analytics cookies help us to improve our website by collecting and reporting information on how you use it. Biology Expert. Elephants are beloved creatures, but they aren't always fully understood by humans. -

Modeling Popularity and Reliability of Sources in Multilingual Wikipedia
information Article Modeling Popularity and Reliability of Sources in Multilingual Wikipedia Włodzimierz Lewoniewski * , Krzysztof W˛ecel and Witold Abramowicz Department of Information Systems, Pozna´nUniversity of Economics and Business, 61-875 Pozna´n,Poland; [email protected] (K.W.); [email protected] (W.A.) * Correspondence: [email protected] Received: 31 March 2020; Accepted: 7 May 2020; Published: 13 May 2020 Abstract: One of the most important factors impacting quality of content in Wikipedia is presence of reliable sources. By following references, readers can verify facts or find more details about described topic. A Wikipedia article can be edited independently in any of over 300 languages, even by anonymous users, therefore information about the same topic may be inconsistent. This also applies to use of references in different language versions of a particular article, so the same statement can have different sources. In this paper we analyzed over 40 million articles from the 55 most developed language versions of Wikipedia to extract information about over 200 million references and find the most popular and reliable sources. We presented 10 models for the assessment of the popularity and reliability of the sources based on analysis of meta information about the references in Wikipedia articles, page views and authors of the articles. Using DBpedia and Wikidata we automatically identified the alignment of the sources to a specific domain. Additionally, we analyzed the changes of popularity and reliability in time and identified growth leaders in each of the considered months. The results can be used for quality improvements of the content in different languages versions of Wikipedia. -

Elephant Escapades Audience Activity Designed for 10 Years Old and Up
Elephant Escapades Audience Activity designed for 10 years old and up Goal Students will learn the differences between the African and Asian elephants, as well as, how their different adaptations help them survive in their habitats. Objective • To understand elephant adaptations • To identify the differences between African and Asian elephants Conservation Message Elephants play a major role in their habitats. They act as keystone species which means that other species depend on them and if elephants were removed from the ecosystem it would change drastically. It is important to understand these species and take efforts to encourage the preservation of African and Asian elephants and their habitats. Background Information Elephants are the largest living land animal; they can weigh between 6,000 and 12,000 pounds and stand up to 12 feet tall. There are only two species of elephants; the African Elephants and the Asian Elephant. The Asian elephant is native to parts of South and Southeast Asia. While the African elephant is native to the continent of Africa. While these two species are very different, they do share some common traits. For example, both elephant species have a trunk that can move in any direction and move heavy objects. An elephant’s trunk is a fusion, or combination, of the nose and upper lip and does not contain any bones. Their trunks have thousands of muscles and tendons that make movements precise and give the trunk amazing strength. Elephants use their trunks for snorkeling, smelling, eating, defending themselves, dusting and other activities that they perform daily. Another common feature that the two elephant species share are their feet. -
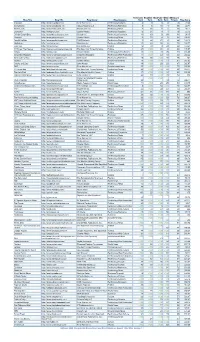
Blog Title Blog URL Blog Owner Blog Category Technorati Rank
Technorati Bloglines BlogPulse Wikio SEOmoz’s Blog Title Blog URL Blog Owner Blog Category Rank Rank Rank Rank Trifecta Blog Score Engadget http://www.engadget.com Time Warner Inc. Technology/Gadgets 4 3 6 2 78 19.23 Boing Boing http://www.boingboing.net Happy Mutants LLC Technology/Marketing 5 6 15 4 89 33.71 TechCrunch http://www.techcrunch.com TechCrunch Inc. Technology/News 2 27 2 1 76 42.11 Lifehacker http://lifehacker.com Gawker Media Technology/Gadgets 6 21 9 7 78 55.13 Official Google Blog http://googleblog.blogspot.com Google Inc. Technology/Corporate 14 10 3 38 94 69.15 Gizmodo http://www.gizmodo.com/ Gawker Media Technology/News 3 79 4 3 65 136.92 ReadWriteWeb http://www.readwriteweb.com RWW Network Technology/Marketing 9 56 21 5 64 142.19 Mashable http://mashable.com Mashable Inc. Technology/Marketing 10 65 36 6 73 160.27 Daily Kos http://dailykos.com/ Kos Media, LLC Politics 12 59 8 24 63 163.49 NYTimes: The Caucus http://thecaucus.blogs.nytimes.com The New York Times Company Politics 27 >100 31 8 93 179.57 Kotaku http://kotaku.com Gawker Media Technology/Video Games 19 >100 19 28 77 216.88 Smashing Magazine http://www.smashingmagazine.com Smashing Magazine Technology/Web Production 11 >100 40 18 60 283.33 Seth Godin's Blog http://sethgodin.typepad.com Seth Godin Technology/Marketing 15 68 >100 29 75 284 Gawker http://www.gawker.com/ Gawker Media Entertainment News 16 >100 >100 15 81 287.65 Crooks and Liars http://www.crooksandliars.com John Amato Politics 49 >100 33 22 67 305.97 TMZ http://www.tmz.com Time Warner Inc. -

Omnipedia: Bridging the Wikipedia Language
Omnipedia: Bridging the Wikipedia Language Gap Patti Bao*†, Brent Hecht†, Samuel Carton†, Mahmood Quaderi†, Michael Horn†§, Darren Gergle*† *Communication Studies, †Electrical Engineering & Computer Science, §Learning Sciences Northwestern University {patti,brent,sam.carton,quaderi}@u.northwestern.edu, {michael-horn,dgergle}@northwestern.edu ABSTRACT language edition contains its own cultural viewpoints on a We present Omnipedia, a system that allows Wikipedia large number of topics [7, 14, 15, 27]. On the other hand, readers to gain insight from up to 25 language editions of the language barrier serves to silo knowledge [2, 4, 33], Wikipedia simultaneously. Omnipedia highlights the slowing the transfer of less culturally imbued information similarities and differences that exist among Wikipedia between language editions and preventing Wikipedia’s 422 language editions, and makes salient information that is million monthly visitors [12] from accessing most of the unique to each language as well as that which is shared information on the site. more widely. We detail solutions to numerous front-end and algorithmic challenges inherent to providing users with In this paper, we present Omnipedia, a system that attempts a multilingual Wikipedia experience. These include to remedy this situation at a large scale. It reduces the silo visualizing content in a language-neutral way and aligning effect by providing users with structured access in their data in the face of diverse information organization native language to over 7.5 million concepts from up to 25 strategies. We present a study of Omnipedia that language editions of Wikipedia. At the same time, it characterizes how people interact with information using a highlights similarities and differences between each of the multilingual lens. -

The Culture of Wikipedia
Good Faith Collaboration: The Culture of Wikipedia Good Faith Collaboration The Culture of Wikipedia Joseph Michael Reagle Jr. Foreword by Lawrence Lessig The MIT Press, Cambridge, MA. Web edition, Copyright © 2011 by Joseph Michael Reagle Jr. CC-NC-SA 3.0 Purchase at Amazon.com | Barnes and Noble | IndieBound | MIT Press Wikipedia's style of collaborative production has been lauded, lambasted, and satirized. Despite unease over its implications for the character (and quality) of knowledge, Wikipedia has brought us closer than ever to a realization of the centuries-old Author Bio & Research Blog pursuit of a universal encyclopedia. Good Faith Collaboration: The Culture of Wikipedia is a rich ethnographic portrayal of Wikipedia's historical roots, collaborative culture, and much debated legacy. Foreword Preface to the Web Edition Praise for Good Faith Collaboration Preface Extended Table of Contents "Reagle offers a compelling case that Wikipedia's most fascinating and unprecedented aspect isn't the encyclopedia itself — rather, it's the collaborative culture that underpins it: brawling, self-reflexive, funny, serious, and full-tilt committed to the 1. Nazis and Norms project, even if it means setting aside personal differences. Reagle's position as a scholar and a member of the community 2. The Pursuit of the Universal makes him uniquely situated to describe this culture." —Cory Doctorow , Boing Boing Encyclopedia "Reagle provides ample data regarding the everyday practices and cultural norms of the community which collaborates to 3. Good Faith Collaboration produce Wikipedia. His rich research and nuanced appreciation of the complexities of cultural digital media research are 4. The Puzzle of Openness well presented. -

Classifying Wikipedia Article Quality with Revision History Networks
Classifying Wikipedia Article Quality With Revision History Networks Narun Raman∗ Nathaniel Sauerberg∗ Carleton College Carleton College [email protected] [email protected] Jonah Fisher Sneha Narayan Carleton College Carleton College [email protected] [email protected] ABSTRACT long been interested in maintaining and investigating the quality We present a novel model for classifying the quality of Wikipedia of its content [4][6][12]. articles based on structural properties of a network representation Editors and WikiProjects typically rely on assessments of article of the article’s revision history. We create revision history networks quality to focus volunteer attention on improving lower quality (an adaptation of Keegan et. al’s article trajectory networks [7]), articles. This has led to multiple efforts to create classifiers that can where nodes correspond to individual editors of an article, and edges predict the quality of a given article [3][4][18]. These classifiers can join the authors of consecutive revisions. Using descriptive statistics assist in providing assessments of article quality at scale, and help generated from these networks, along with general properties like further our understanding of the features that distinguish high and the number of edits and article size, we predict which of six quality low quality Wikipedia articles. classes (Start, Stub, C-Class, B-Class, Good, Featured) articles belong While many Wikipedia article quality classifiers have focused to, attaining a classification accuracy of 49.35% on a stratified sample on assessing quality based on the content of the latest version of of articles. These results suggest that structures of collaboration an article [1, 4, 18], prior work has suggested that high quality arti- underlying the creation of articles, and not just the content of the cles are associated with more intense collaboration among editors article, should be considered for accurate quality classification. -

QUARTERLY CHECK-IN Technology (Services) TECH GOAL QUADRANT
QUARTERLY CHECK-IN Technology (Services) TECH GOAL QUADRANT C Features that we build to improve our technology A Foundation level goals offering B Features we build for others D Modernization, renewal and tech debt goals The goals in each team pack are annotated using this scheme illustrate the broad trends in our priorities Agenda ● CTO Team ● Research and Data ● Design Research ● Performance ● Release Engineering ● Security ● Technical Operations Photos (left to right) Technology (Services) CTO July 2017 quarterly check-in All content is © Wikimedia Foundation & available under CC BY-SA 4.0, unless noted otherwise. CTO Team ● Victoria Coleman - Chief Technology Officer ● Joel Aufrecht - Program Manager (Technology) ● Lani Goto - Project Assistant ● Megan Neisler - Senior Project Coordinator ● Sarah Rodlund - Senior Project Coordinator ● Kevin Smith - Program Manager (Engineering) Photos (left to right) CHECK IN TEAM/DEPT PROGRAM WIKIMEDIA FOUNDATION July 2017 CTO 4.5 [LINK] ANNUAL PLAN GOAL: expand and strengthen our technical communities What is your objective / Who are you working with? What impact / deliverables are you expecting? workflow? Program 4: Technical LAST QUARTER community building (none) Outcome 5: Organize Wikimedia Developer Summit NEXT QUARTER Objective 1: Developer Technical Collaboration Decide on event location, dates, theme, deadlines, etc. Summit web page and publicize the information published four months before the event (B) STATUS: OBJECTIVE IN PROGRESS Technology (Services) Research and Data July, 2017 quarterly