Content-Based Music Information Retrieval
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chet Faker Thinking in Textures Mp3, Flac, Wma
Chet Faker Thinking In Textures mp3, flac, wma DOWNLOAD LINKS (Clickable) Genre: Electronic Album: Thinking In Textures Country: Australia Released: 2013 Style: Leftfield, Downtempo MP3 version RAR size: 1694 mb FLAC version RAR size: 1539 mb WMA version RAR size: 1291 mb Rating: 4.6 Votes: 716 Other Formats: ADX MP2 MP4 RA MMF AIFF VOX Tracklist Hide Credits 1 I'm Into You 4:23 2 Terms And Conditions 3:42 No Diggity 3 Written-By – Andre Young, Bill Withers, Chauncey Hannibal, Lynise Walters, Richard Vick, 3:41 Teddy Riley, William Stewart* 4 Love And Feeling 4:10 5 Cigarettes And Chocolate 5:16 6 Solo Sunrise 4:04 7 Everything I Wanted 3:30 Companies, etc. Record Company – Inertia Marketed By – Remote Control Mastered At – Deluxe Mastering Manufactured By – SM – 6141005306 Credits Art Direction, Design – Christopher Doyle Mastered By – Andrei Eremin Music By – Chet Faker Photography By – Jefton Sungkar Producer – Chet Faker Notes Digipak. Manufactured & distributed exclusively in Australia by Inertia Pty. Ltd. Marketing and promotion by remote control records Barcode and Other Identifiers Barcode: 9332727021732 Matrix / Runout: [SM logo] OP001 6141005306 Mastering SID Code: ifpi LR11 Mould SID Code: IFPI 7917 Other versions Category Artist Title (Format) Label Category Country Year Chet Thinking In Textures Opulent Records OP001 OP001 Australia 2012 Faker (CD, EP) , Remote Control Opulent Records Chet Thinking In Textures B0028022-01 , Downtown B0028022-01 US 2018 Faker (12", EP, Ltd, Cle) Records Thinking In Textures Chet DWT70340 (12", EP, Ltd, RP, Downtown DWT70340 US 2015 Faker Whi) Chet Thinking In Textures DWT70340 Downtown DWT70340 US 2012 Faker (12", EP) Chet Thinking In Textures none Chess Club none UK Unknown Faker (CDr, EP, Promo) Related Music albums to Thinking In Textures by Chet Faker 1. -

Oce Cx2100 BR-Script3, and Then Click Add
Please read this manual thoroughly before using this machine on your network. You can view this manual in PDF format from the CD-ROM at any time, please keep the CD-ROM in a convenient place for quick and easy reference at all times. You can also download the manual in PDF format and the latest drivers from the Océ USA web site (http://www.oceusa.com). Definitions of warnings, cautions, and notes We use the following icon throughout this User’s Guide: Notes tell you how you should respond to a situation that may arise or give tips about how the operation works with other features. Trademarks Océ and the Océ logo are trademarks of Océ N.V., Registered in the U.S. Patent and Trademark Office and/or other jurisdictions. BRAdmin Light and BRAdmin Professional are trademarks of Brother Industries, Ltd. UNIX is a registered trademark of The Open Group. Apple and Macintosh are registered trademarks and Safari is a trademark of Apple Inc. HP, Hewlett-Packard, Jetdirect and PCL are registered trademarks of Hewlett-Packard Company. PostScript is a registered trademark of Adobe Systems Incorporated. Microsoft, Windows and Windows Server are registered trademarks of Microsoft Corporation in the U.S. and other countries. Windows Vista is either a registered trademark or trademark of Microsoft Corporation in the United States and/or other countries. BROADCOM, SecureEasySetup and the SecureEasySetup logo are trademarks or registered trademarks of Broadcom Corporation. Wi-Fi is a registered trademark and WPA and WPA2 are registered trademarks of the Wi-Fi Alliance. Firefox is a registered trademark of the Mozilla Foundation. -

Multi-Percussion in the Undergraduate Percussion Curriculum Benjamin A
University of Miami Scholarly Repository Open Access Dissertations Electronic Theses and Dissertations 2014-12 Multi-percussion in the Undergraduate Percussion Curriculum Benjamin A. Charles University of Miami, [email protected] Follow this and additional works at: http://scholarlyrepository.miami.edu/oa_dissertations Recommended Citation Charles, Benjamin A., "Multi-percussion in the Undergraduate Percussion Curriculum" (2014). Open Access Dissertations. Paper 1324. This Open access is brought to you for free and open access by the Electronic Theses and Dissertations at Scholarly Repository. It has been accepted for inclusion in Open Access Dissertations by an authorized administrator of Scholarly Repository. For more information, please contact [email protected]. ! ! UNIVERSITY OF MIAMI ! ! MULTI-PERCUSSION IN THE UNDERGRADUATE PERCUSSION CURRICULUM ! By Benjamin Andrew Charles ! A DOCTORAL ESSAY ! ! Submitted to the Faculty of the University of Miami in partial fulfillment of the requirements for the degree of Doctor of Musical Arts ! ! ! ! ! ! ! ! ! Coral Gables,! Florida ! December 2014 ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ©2014 Benjamin Andrew Charles ! All Rights Reserved UNIVERSITY! OF MIAMI ! ! A doctoral essay proposal submitted in partial fulfillment of the requirements for the degree of Doctor of Musical! Arts ! ! MULTI-PERCUSSION IN THE UNDERGRADUATE PERCUSSION CURRICULUM! ! Benjamin Andrew Charles ! ! !Approved: ! _________________________ __________________________ -

Mechanical Systems
UNIT Mechanical Systems How many mechanical systems have you used today? You may not realize it, but you use mechanical systems all the time to do simple tasks. When you ride a bicycle, open a can, or sharpen a pencil, you have used a mechanical system to help you complete a task. All mechanical systems have an energy source. The energy could come from electricity, gasoline, or solar energy, but often the energy comes from humans. (Remember that huge structures such as the pyramids were built solely using human power!) The energy needed to move this bicycle and this plane, for example, comes from a pedalling human. Can you see how machines help us perform tasks we might find difficult to do otherwise? Imagine opening a can without a can opener. Could you fly without a plane or other type of aircraft? In this unit, you will learn how some small, human-powered mechanical devices work. You will see that tools as simple as a pair of scissors function on the same principles as massive equipment powered by fluid pressure and heat engines. You will discover the main factors in the efficient operation of mechanical systems. You will also design and build your own mechanical devices — including some powered by hydraulics and pneumatics — and investigate their efficiency. Finally, this unit examines how machines have changed as science and technology have changed. 266 Unit Contents TOPIC 1 Levers and Inclined Planes 270 TOPIC 2 The Wheel and Axle,Gears, and Pulleys 285 TOPIC 3 Energy, Friction, and Efficiency 296 TOPIC 4 Force, Pressure, and Area 304 TOPIC 5 Hydraulics and Pneumatics 313 TOPIC 6 Combining Systems 326 TOPIC 7 Machines Throughout History 332 TOPIC 8 People and Machines 342 UNIT 4 • How do we use How many machines have you used today? machines to do work and How do we use mechanical devices such as to transfer energy? levers and pulleys to help us perform tasks? In Topics 1–3, you will learn about lots of How can we design and • mechanical devices. -

Read Readings Monthly, April 2014 Here
FREE APRIL 2014 BOOKS MUSIC FILM EVENTS N David Brooks on John A. Scott’s masterful new novel page 4 FRANK SINATRA HAS A COLD Adam Curley on the essays of Gay Talese page 6 LITTLE ITALY Mark Rubbo on Lygon Street – Si Parla Italiano page 17 NEW IN APRIL KARL OVE RAINBOW MARK LYGON EMMYLOU KNAUSGAARD ROWELL ISAACS STREET HARRIS $32.99 $16.99 $29.95 $39.95 $39.95 $24.99 $13.99 $24.95 $29.95 page 17 page 7 page 10 page 11 page 18 2 READINGS MONTHLY APRIL 2014 News OPERA AND BALLET DVD SALE Boy, Lost, Kristina Olsson; The Swan Book, To celebrate the opera and ballet season, Alexis Wright; and The Forgotten Rebels of Readings is offering up to 40% off a wide Eureka, Clare Wright. range of opera and ballet DVDs. Titles include operas from Wagner and Mozart, Buy any two of the 2014 Stella Prize ballets from Tchaikovsky and a host more. shortlisted titles at any Readings shop, in This offer is available at Readings Carlton, store or online and receive a special Stella Hawthorn and Malvern shops, and online Prize light canvas portrait tote. Those until 30 April 2014. Only while stocks last. ordering online need to place ‘The Stella Prize’ in the notes field to receive their bag. Only while stocks last. 20% OFF VINYL SALE Officially on Saturday 19 April, Readings is celebrating Record Store Day all month UPCOMING EVENTS AT LINDEN long with 20% off all vinyl! Hand-picked Readings are proud to partner with Linden by our passionate music team, our Centre for Contemporary Arts on two vinyl collection includes old favourites upcoming programs, Toddler Tales at alongside terrific new releases. -
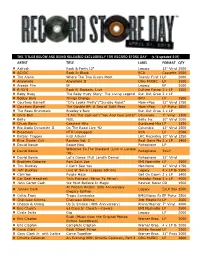
The Titles Below Are Being Released Exclusively For
THE TITLES BELOW ARE BEING RELEASED EXCLUSIVELY FOR RECORD STORE DAY (v.14 updated 5-01) ARTIST TITLE LABEL FORMAT QTY ¢ Aaliyah Back & Forth 12" Legacy 12" Vinyl 2500 ¢ AC/DC Back In Black RCA Cassette 2500 ¢ The Alarm Where The Two Rivers Meet Twenty First CenturyLP Recording2000 ¢ Anywhere Anywhere II ORG MUSIC LP 1500 ¢ Arcade Fire EP Legacy EP 3000 ¢ B-52'S Rock N' Rockets, Live Culture Factory2 USx LP 1200 ¢ Baby Huey The Baby Huey Story: The Living Legend Run Out Groove2 x LP ¢ Bobby Bare Things Change BFD LP 1500 ¢ Courtney Barnett "City Looks Pretty"/"Sunday Roast" Mom+Pop 12" Vinyl 1750 ¢ Courtney Barnett The Double EP: A Sea of Split Peas Mom+Pop LP Picture1800 Disc ¢ The Beau Brummels Bradley's Barn Run Out Groove2 x LP ¢ Chris Bell "I Am The Cosmos"/"You And Your Sister" Omnivore 7" Vinyl 1300 ¢ Belly FEEL Belly Inc 10" Vinyl 2000 ¢ Chuck Berry Greatest Hits Sundazed MusicLP 1350 ¢ Big Audio Dynamite II On The Road Live '92 Columbia 12" Vinyl 2500 ¢ Bleachers MTV Unplugged RCA LP 2500 ¢ Blitzen Trapper Kids Album! LKC Recordings10" Vinyl 1250 ¢ Blue Öyster Cult Rarities Vol. 2 Real Gone Music2 x LP 1400 ¢ David Bowie Bowie Now Parlophone LP Welcome To The Blackout (Live in London ¢ David Bowie Parlophone 3XLP '78) ¢ David Bowie Let's Dance (Full Length Demo) Parlophone 12" Vinyl ¢ Brothers Osborne Port Saint Joe EMI Nashville LP 1500 ¢ Tim Buckley I Can't See You Manifesto 12" Vinyl 1750 ¢ Jeff Buckley Live at Sin-e (Legacy Edition) Legacy 4 x LP Box2500 Set ¢ Cam'ron Purple Haze Get On Down 2 x LP 1400 ¢ Car Seat Headrest -

The Private and External Costs of Germany's Nuclear Phase-Out
Energy Institute WP 304 The Private and External Costs of Germany’s Nuclear Phase-Out Stephen Jarvis, Olivier Deschenes, and Akshaya Jha January 2020 Energy Institute at Haas working papers are circulated for discussion and comment purposes. They have not been peer-reviewed or been subject to review by any editorial board. The Energy Institute acknowledges the generous support it has received from the organizations and individuals listed at http://ei.haas.berkeley.edu/support/. © 2020 by Stephen Jarvis, Olivier Deschenes, and Akshaya Jha. All rights reserved. Short sections of text, not to exceed two paragraphs, may be quoted without explicit permission provided that full credit is given to the source. The Private and External Costs of Germany's Nuclear Phase-Out Stephen Jarvis, Olivier Deschenes, and Akshaya Jha∗ Abstract Many countries have phased out nuclear electricity production in response to con- cerns about nuclear waste and the risk of nuclear accidents. This paper examines the impact of the shutdown of roughly half of the nuclear production capacity in Germany after the Fukushima accident in 2011. We use hourly data on power plant operations and a novel machine learning framework to estimate how plants would have operated differently if the phase-out had not occurred. We find that the lost nuclear electricity production due to the phase-out was replaced primarily by coal-fired production and net electricity imports. The social cost of this shift from nuclear to coal is approximately 12 billion dollars per year. Over 70% of this cost comes from the increased mortality risk associated with exposure to the local air pollution emitted when burning fossil fuels. -

1 1 2 Department of Commerce 3 Internet Policy Task
1 1 2 3 DEPARTMENT OF COMMERCE 4 INTERNET POLICY TASK FORCE 5 6 7 8 Developing the Digital Marketplace 9 for Copyrighted Works 10 Second Public Meeting 11 12 13 14 15 United States Patent and Trademark Office 16 Madison Auditorium 17 January 25, 2018, 9:00 a.m. 18 19 20 21 22 23 24 Digitally recorded by: Linda D. Metcalf, CER 25 Transcribed by: Susanne Bergling, RMR-CRR-CLR 2 1 C O N T E N T S 2 SESSION PAGE 3 4 WELCOME - KAREN FERRITER 3 5 6 KEYNOTE SPEAKER - BILL ROSENBLATT 5 7 8 MORNING PANEL 1 25 9 10 PRESENTATION – PEX 66 11 12 MORNING PANEL 2 73 13 14 PRESENTATION - LOBSTER 119 15 16 PRESENTATION - COPYRIGHT HUB 123 17 18 AFTERNOON PANEL 1 130 19 20 AFTERNOON PANEL 2 176 21 22 AFTERNOON PLENARY DISCUSSION 221 23 24 CLOSING REMARKS 242 25 26 3 1 P R O C E E D I N G S 2 - - - - - 3 WELCOME REMARKS 4 - - - - - 5 MS. FERRITER: Good morning and welcome to the 6 U.S. Patent and Trademark Office. I'm very glad to 7 see so many with us here today in person. I'd like to 8 also welcome those watching us via webcast and those 9 joining us through the watch parties being held at the 10 USPTO's regional offices in Detroit, Denver, and San 11 Jose. 12 Today's meeting is hosted by the Department of 13 Commerce's Internet Policy Task Force. The Task Force 14 was formed in 2010 to review the policy and 15 operational issues that affect the private sector's 16 ability to spur economic growth and job creation 17 through the internet. -
![Songs of the IBM.]](https://docslib.b-cdn.net/cover/0128/songs-of-the-ibm-3980128.webp)
Songs of the IBM.]
1 [The following is a partial reproduction of the 1935 edition of Songs Of The IBM.] Fellowship Songs of International Business Machines Corporation Divisions: The Tabulating Machine Division International Time Recording Division International Scale Division Electromatic Typewriters Division Home Office: 270 Broadway New York, N. Y. For thirty-five years, the gatherings and conventions of our IBM workers have expressed in happy songs the fine spirit of loyal cooperation and good fellowship which has promoted the signal success of our great IBM Corporation in its truly International Service for the betterment of business and benefit to mankind. In appreciation of the able and inspiring leadership of our beloved President, Mr. Thos. J. Watson, and our unmatchable staff of IBM executives, and in recognition of the noble aims and purposes of our International Service and Products, this 1935 edition of IBM songs solicits your vocal approval by hearty cooperation in our songfests at our conventions and fellowship gatherings. Yours in International Service, Harry S. Evans 1. AMERICA My country, ‘tis of thee, Sweet land of liberty Of thee I sing. Land where my fathers died, Land of the pilgrim’s pride, From every mountain side, Let freedom ring. 3405SB1 2 2. STAR-SPANGLED BANNER Oh, say, can you see, by the dawn’s early light, What so proudly we hailed at the twilight’s last gleaming, Whose broad stripes and bright stars, thro’ the perilous fight, O’er the ramparts we watched, were so gallantly streaming? And the rockets’ red glare, the bombs bursting in air, Gave proof thro’ the night that our flag was still there. -

Commencement to Return to Stadium Law Professor Receives Fulbright
THE INDEPENDENT TO UNCOVER NEWSPAPER SERVING THE TRUTH NOTRE DAME AND AND REPORT SAINT MAry’S IT ACCURATELY VLEO UM 48, ISSUE 90 | TUESDAY, FEBRUARY 17, 2015 | NDSMCOBSERVER.COM Commencement to return to Stadium Jenkins announces change in ceremony location, addresses core curriculum concerns during town hall By EMILY McCONVILLE School of International Affairs, News Writer the core curriculum review and Campus Crossroads progress. U niversity President Fr. John Jenkins announced Tuesday that Commencement 2015 the Class of 2015’s commence- Jenkins said the ment ceremony will take place Commencement ceremony’s in Notre Dame Stadium in- location change comes due to a stead of the Joyce Center, as the relatively mild winter, which led University originally planned. to better-than-expected prog- Jenkins made the announce- ress on the Campus Crossroads ment at an undergraduate project. town hall meeting in DeBartolo “Campus Crossroads won’t be Hall, during which Jenkins, finished; there will be a little in- University Provost Tom Burish convenience, but I’m sure it will and Executive Vice President be minimal, and it will be a great John Affleck-Graves also updat- Commencement,” Jenkins said. EMILY McCONVILLE | The Observer ed the student body on staff di- University President Fr. John Jenkins announces the change in location of the 2015 Commencement versity and inclusion, the Keough see TOWN HALL PAGE 5 ceremony from the Joyce Athletic and Convocation Center to Notre Dame Stadium. Law professor receives Alumni create Fulbright research grant endowment for By SELENA PONIO on human rights and represent- Cassel said. News Writer ed victims of human rights vio- Cassel said a new doctrine women’s basketball lations in Colombia, Guatemala, implemented in Mexico not Notre Dame law professor Peru and Venezuela. -

Report Artist Release Tracktitle Streaming 2016 2 Unlimited Unlimited Hits & Remixes No Limit Streaming 2016 666 Paradoxx (P
Report Artist Release Tracktitle Streaming 2016 2 Unlimited Unlimited Hits & Remixes No Limit Streaming 2016 666 Paradoxx (Platinum Edition) AmokK (Radio Edit) Streaming 2016 8Ball Din Søster (Radio Edit) - Single Din Søster (Radio Edit) Streaming 2016 A2M I Got Bitches I Got Bitches Streaming 2016 Adam Tony Montana - Single Tony Montana (feat. Murro) Streaming 2016 Adam Vi Rykker Vi Rykker (feat. Carmon) Streaming 2016 Adam 5 Drab - EP Kolde Tider Streaming 2016 Adam 5 Drab - EP Ting På Hjertet Streaming 2016 ADAM Gulddreng Diss - Single Gulddreng Diss Streaming 2016 Adam Friedman Green - EP Lemonade (feat. Mike Posner) Streaming 2016 Ahrix Desynthesized Nova Streaming 2016 Aquilo Aquilo - EP You There Streaming 2016 Ashley DuBose Be You Intoxicated Streaming 2016 ATL All Night All Night (feat. Wally Sparks) Streaming 2016 Austin Basham Linton / Oslo EP All Is Well Streaming 2016 B3nte Like - Single Like Streaming 2016 Baby E Finessin Finessin Streaming 2016 Beachbraaten Trump Trump Streaming 2016 Beta Radio Colony of Bees On the Frame Streaming 2016 Black Coast Trndsttr (feat. M.Maggie) [Lucian Remix] - Single Trndsttr (feat. M.Maggie) [Lucian Remix] Streaming 2016 Black Elk Sparks Intro Streaming 2016 Bobby Puma Making Me Dizzy - Single Making Me Dizzy Streaming 2016 Bombs Away Damn Daniel - Single Damn Daniel Streaming 2016 Boyce Avenue Road Less Traveled Be Somebody Streaming 2016 Breathe Carolina Soldier - Single Soldier Streaming 2016 Brett Bixby City Lights Fireside The Most Beautiful Moment in Life: Young Streaming 2016 BTS Forever Save Me Streaming 2016 Busta Rhymes Worldwide Choppers - Single Worldwide Choppers Streaming 2016 Cameron Bedell Earned It (Acoustic Cover) - Single Earned It (Acoustic Cover) Streaming 2016 Cameron Dallas She Bad (feat. -

University of Southampton Research Repository Eprints Soton
University of Southampton Research Repository ePrints Soton Copyright © and Moral Rights for this thesis are retained by the author and/or other copyright owners. A copy can be downloaded for personal non-commercial research or study, without prior permission or charge. This thesis cannot be reproduced or quoted extensively from without first obtaining permission in writing from the copyright holder/s. The content must not be changed in any way or sold commercially in any format or medium without the formal permission of the copyright holders. When referring to this work, full bibliographic details including the author, title, awarding institution and date of the thesis must be given e.g. AUTHOR (year of submission) "Full thesis title", University of Southampton, name of the University School or Department, PhD Thesis, pagination http://eprints.soton.ac.uk UNIVERSITY OF SOUTHAMPTON Telling Your Story: Autobiographical Metadata and the Semantic Web by Mischa Moussavian Tuffield A thesis submitted in partial fulfillment for the degree of Doctor of Philosophy in the Faculty of Engineering, Science and Mathematics School of Electronics and Computer Science Intelligence, Agents, Multimedia Group July 2010 UNIVERSITY OF SOUTHAMPTON ABSTRACT FACULTY OF ENGINEERING, SCIENCE AND MATHEMATICS SCHOOL OF ELECTRONICS AND COMPUTER SCIENCE INTELLIGENCE, AGENTS, MULTIMEDIA GROUP Doctor of Philosophy by Mischa Moussavian Tuffield Given the current explosion of user-generated content driven by the ever-decreasing price of sensing and storage hardware the dream of capturing and archiving the entirety of a human life is slowly being realised. The Semantic Web, a discipline of Computer Science, aims to support the sharing and interoperation of knowledge using the Web’s infrastructure.