Identification of Mammalian Orthologs Using Local Synteny
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Multiple Activities of Arl1 Gtpase in the Trans-Golgi Network Chia-Jung Yu1,2 and Fang-Jen S
© 2017. Published by The Company of Biologists Ltd | Journal of Cell Science (2017) 130, 1691-1699 doi:10.1242/jcs.201319 COMMENTARY Multiple activities of Arl1 GTPase in the trans-Golgi network Chia-Jung Yu1,2 and Fang-Jen S. Lee3,4,* ABSTRACT typical features of an Arf-family GTPase, including an amphipathic ADP-ribosylation factors (Arfs) and ADP-ribosylation factor-like N-terminal helix and a consensus site for N-myristoylation (Lu et al., proteins (Arls) are highly conserved small GTPases that function 2001; Price et al., 2005). In yeast, recruitment of Arl1 to the Golgi as main regulators of vesicular trafficking and cytoskeletal complex requires a second Arf-like GTPase, Arl3 (Behnia et al., reorganization. Arl1, the first identified member of the large Arl family, 2004; Setty et al., 2003). Yeast Arl3 lacks a myristoylation site and is an important regulator of Golgi complex structure and function in is, instead, N-terminally acetylated; this modification is required for organisms ranging from yeast to mammals. Together with its effectors, its recruitment to the Golgi complex by Sys1. In mammalian cells, Arl1 has been shown to be involved in several cellular processes, ADP-ribosylation-factor-related protein 1 (Arfrp1), a mammalian including endosomal trans-Golgi network and secretory trafficking, lipid ortholog of yeast Arl3, plays a pivotal role in the recruitment of Arl1 droplet and salivary granule formation, innate immunity and neuronal to the trans-Golgi network (TGN) (Behnia et al., 2004; Panic et al., development, stress tolerance, as well as the response of the unfolded 2003b; Setty et al., 2003; Zahn et al., 2006). -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Metastatic Adrenocortical Carcinoma Displays Higher Mutation Rate and Tumor Heterogeneity Than Primary Tumors
ARTICLE DOI: 10.1038/s41467-018-06366-z OPEN Metastatic adrenocortical carcinoma displays higher mutation rate and tumor heterogeneity than primary tumors Sudheer Kumar Gara1, Justin Lack2, Lisa Zhang1, Emerson Harris1, Margaret Cam2 & Electron Kebebew1,3 Adrenocortical cancer (ACC) is a rare cancer with poor prognosis and high mortality due to metastatic disease. All reported genetic alterations have been in primary ACC, and it is 1234567890():,; unknown if there is molecular heterogeneity in ACC. Here, we report the genetic changes associated with metastatic ACC compared to primary ACCs and tumor heterogeneity. We performed whole-exome sequencing of 33 metastatic tumors. The overall mutation rate (per megabase) in metastatic tumors was 2.8-fold higher than primary ACC tumor samples. We found tumor heterogeneity among different metastatic sites in ACC and discovered recurrent mutations in several novel genes. We observed 37–57% overlap in genes that are mutated among different metastatic sites within the same patient. We also identified new therapeutic targets in recurrent and metastatic ACC not previously described in primary ACCs. 1 Endocrine Oncology Branch, National Cancer Institute, National Institutes of Health, Bethesda, MD 20892, USA. 2 Center for Cancer Research, Collaborative Bioinformatics Resource, National Cancer Institute, National Institutes of Health, Bethesda, MD 20892, USA. 3 Department of Surgery and Stanford Cancer Institute, Stanford University, Stanford, CA 94305, USA. Correspondence and requests for materials should be addressed to E.K. (email: [email protected]) NATURE COMMUNICATIONS | (2018) 9:4172 | DOI: 10.1038/s41467-018-06366-z | www.nature.com/naturecommunications 1 ARTICLE NATURE COMMUNICATIONS | DOI: 10.1038/s41467-018-06366-z drenocortical carcinoma (ACC) is a rare malignancy with types including primary ACC from the TCGA to understand our A0.7–2 cases per million per year1,2. -

Human Induced Pluripotent Stem Cell–Derived Podocytes Mature Into Vascularized Glomeruli Upon Experimental Transplantation
BASIC RESEARCH www.jasn.org Human Induced Pluripotent Stem Cell–Derived Podocytes Mature into Vascularized Glomeruli upon Experimental Transplantation † Sazia Sharmin,* Atsuhiro Taguchi,* Yusuke Kaku,* Yasuhiro Yoshimura,* Tomoko Ohmori,* ‡ † ‡ Tetsushi Sakuma, Masashi Mukoyama, Takashi Yamamoto, Hidetake Kurihara,§ and | Ryuichi Nishinakamura* *Department of Kidney Development, Institute of Molecular Embryology and Genetics, and †Department of Nephrology, Faculty of Life Sciences, Kumamoto University, Kumamoto, Japan; ‡Department of Mathematical and Life Sciences, Graduate School of Science, Hiroshima University, Hiroshima, Japan; §Division of Anatomy, Juntendo University School of Medicine, Tokyo, Japan; and |Japan Science and Technology Agency, CREST, Kumamoto, Japan ABSTRACT Glomerular podocytes express proteins, such as nephrin, that constitute the slit diaphragm, thereby contributing to the filtration process in the kidney. Glomerular development has been analyzed mainly in mice, whereas analysis of human kidney development has been minimal because of limited access to embryonic kidneys. We previously reported the induction of three-dimensional primordial glomeruli from human induced pluripotent stem (iPS) cells. Here, using transcription activator–like effector nuclease-mediated homologous recombination, we generated human iPS cell lines that express green fluorescent protein (GFP) in the NPHS1 locus, which encodes nephrin, and we show that GFP expression facilitated accurate visualization of nephrin-positive podocyte formation in -

Prediction of Human Disease Genes by Human-Mouse Conserved Coexpression Analysis
Prediction of Human Disease Genes by Human-Mouse Conserved Coexpression Analysis Ugo Ala1., Rosario Michael Piro1., Elena Grassi1, Christian Damasco1, Lorenzo Silengo1, Martin Oti2, Paolo Provero1*, Ferdinando Di Cunto1* 1 Molecular Biotechnology Center, Department of Genetics, Biology and Biochemistry, University of Turin, Turin, Italy, 2 Department of Human Genetics and Centre for Molecular and Biomolecular Informatics, University Medical Centre Nijmegen, Nijmegen, The Netherlands Abstract Background: Even in the post-genomic era, the identification of candidate genes within loci associated with human genetic diseases is a very demanding task, because the critical region may typically contain hundreds of positional candidates. Since genes implicated in similar phenotypes tend to share very similar expression profiles, high throughput gene expression data may represent a very important resource to identify the best candidates for sequencing. However, so far, gene coexpression has not been used very successfully to prioritize positional candidates. Methodology/Principal Findings: We show that it is possible to reliably identify disease-relevant relationships among genes from massive microarray datasets by concentrating only on genes sharing similar expression profiles in both human and mouse. Moreover, we show systematically that the integration of human-mouse conserved coexpression with a phenotype similarity map allows the efficient identification of disease genes in large genomic regions. Finally, using this approach on 850 OMIM loci characterized by an unknown molecular basis, we propose high-probability candidates for 81 genetic diseases. Conclusion: Our results demonstrate that conserved coexpression, even at the human-mouse phylogenetic distance, represents a very strong criterion to predict disease-relevant relationships among human genes. Citation: Ala U, Piro RM, Grassi E, Damasco C, Silengo L, et al. -

13192 Golgin-97 (D8P2K) Rabbit Mab
Revision 1 C 0 2 - t Golgin-97 (D8P2K) Rabbit mAb a e r o t S Orders: 877-616-CELL (2355) [email protected] 2 Support: 877-678-TECH (8324) 9 1 Web: [email protected] 3 www.cellsignal.com 1 # 3 Trask Lane Danvers Massachusetts 01923 USA For Research Use Only. Not For Use In Diagnostic Procedures. Applications: Reactivity: Sensitivity: MW (kDa): Source/Isotype: UniProt ID: Entrez-Gene Id: WB, IP, IF-IC H M Endogenous 97 Rabbit IgG Q92805 2800 Product Usage Information 4. Lu, L. and Hong, W. (2003) Mol Biol Cell 14, 3767-81. 5. Yoshino, A. et al. (2003) J Cell Sci 116, 4441-54. Application Dilution 6. Lu, L. et al. (2004) Mol Biol Cell 15, 4426-43. 7. Lock, J.G. et al. (2005) Traffic 6, 1142-56. Western Blotting 1:1000 8. Alzhanova, D. and Hruby, D.E. (2006) J Virol 80, 11520-7. Immunoprecipitation 1:100 9. Alzhanova, D. and Hruby, D.E. (2007) Virology 362, 421-7. Immunofluorescence (Immunocytochemistry) 1:100 Storage Supplied in 10 mM sodium HEPES (pH 7.5), 150 mM NaCl, 100 µg/ml BSA, 50% glycerol and less than 0.02% sodium azide. Store at –20°C. Do not aliquot the antibody. Specificity / Sensitivity Golgin-97 (D8P2K) Rabbit mAb recognizes endogenous levels of total golgin-97 protein. Species Reactivity: Human, Mouse Source / Purification Monoclonal antibody is produced by immunizing animals with a synthetic peptide corresponding to residues surrounding Leu663 of human golgin-97 protein. Background The Golgi-associated protein golgin A1 (GOLGA1, golgin-97) was first isolated as a Golgi complex autoantigen associated with the autoimmune disorder Sjogren's syndrome (1). -

Mouse Arpc5l Conditional Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Arpc5l Conditional Knockout Project (CRISPR/Cas9) Objective: To create a Arpc5l conditional knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Arpc5l gene (NCBI Reference Sequence: NM_028809 ; Ensembl: ENSMUSG00000026755 ) is located on Mouse chromosome 2. 4 exons are identified, with the ATG start codon in exon 1 and the TAA stop codon in exon 4 (Transcript: ENSMUST00000112862). Exon 2~3 will be selected as conditional knockout region (cKO region). Deletion of this region should result in the loss of function of the Mouse Arpc5l gene. To engineer the targeting vector, homologous arms and cKO region will be generated by PCR using BAC clone RP24-82N14 as template. Cas9, gRNA and targeting vector will be co-injected into fertilized eggs for cKO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Exon 2 starts from about 32.68% of the coding region. The knockout of Exon 2~3 will result in frameshift of the gene. The size of intron 1 for 5'-loxP site insertion: 4770 bp, and the size of intron 3 for 3'-loxP site insertion: 1158 bp. The size of effective cKO region: ~1285 bp. The cKO region does not have any other known gene. Page 1 of 8 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele 5' gRNA region gRNA region 3' 1 2 3 4 Targeting vector Targeted allele Constitutive KO allele (After Cre recombination) Legends Exon of mouse Arpc5l Homology arm cKO region loxP site Page 2 of 8 https://www.alphaknockout.com Overview of the Dot Plot Window size: 10 bp Forward Reverse Complement Sequence 12 Note: The sequence of homologous arms and cKO region is aligned with itself to determine if there are tandem repeats. -
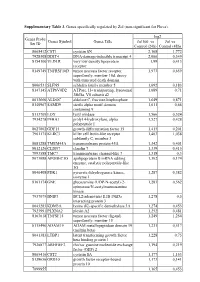
Supplementary Table 3. Genes Specifically Regulated by Zol (Non-Significant for Fluva)
Supplementary Table 3. Genes specifically regulated by Zol (non-significant for Fluva). log2 Genes Probe Genes Symbol Genes Title Zol100 vs Zol vs Set ID Control (24h) Control (48h) 8065412 CST1 cystatin SN 2,168 1,772 7928308 DDIT4 DNA-damage-inducible transcript 4 2,066 0,349 8154100 VLDLR very low density lipoprotein 1,99 0,413 receptor 8149749 TNFRSF10D tumor necrosis factor receptor 1,973 0,659 superfamily, member 10d, decoy with truncated death domain 8006531 SLFN5 schlafen family member 5 1,692 0,183 8147145 ATP6V0D2 ATPase, H+ transporting, lysosomal 1,689 0,71 38kDa, V0 subunit d2 8013660 ALDOC aldolase C, fructose-bisphosphate 1,649 0,871 8140967 SAMD9 sterile alpha motif domain 1,611 0,66 containing 9 8113709 LOX lysyl oxidase 1,566 0,524 7934278 P4HA1 prolyl 4-hydroxylase, alpha 1,527 0,428 polypeptide I 8027002 GDF15 growth differentiation factor 15 1,415 0,201 7961175 KLRC3 killer cell lectin-like receptor 1,403 1,038 subfamily C, member 3 8081288 TMEM45A transmembrane protein 45A 1,342 0,401 8012126 CLDN7 claudin 7 1,339 0,415 7993588 TMC7 transmembrane channel-like 7 1,318 0,3 8073088 APOBEC3G apolipoprotein B mRNA editing 1,302 0,174 enzyme, catalytic polypeptide-like 3G 8046408 PDK1 pyruvate dehydrogenase kinase, 1,287 0,382 isozyme 1 8161174 GNE glucosamine (UDP-N-acetyl)-2- 1,283 0,562 epimerase/N-acetylmannosamine kinase 7937079 BNIP3 BCL2/adenovirus E1B 19kDa 1,278 0,5 interacting protein 3 8043283 KDM3A lysine (K)-specific demethylase 3A 1,274 0,453 7923991 PLXNA2 plexin A2 1,252 0,481 8163618 TNFSF15 tumor necrosis -

Supplementary Material For
Supplementary material for: New families of human regulatory RNA structures identified by comparative analysis of vertebrate genomes Brian J. Parker*, Ida Moltke, Adam Roth, Stefan Washietl, Jiayu Wen, Manolis Kellis, Ronald Breaker, and Jakob Skou Pedersen*. *Corresponding authors Supplementary figures: ..........................................................................................3 Figure S1: 29 mammals and two vertebrate out‐group species used for family detection. ....................................................................................................................................................................................3 Figure S2: 41‐way alignment. .......................................................................................................................4 Figure S3: Family mean length distribution. ..........................................................................................5 Figure S4: Genomic distribution of initial EvoFold prediction set (excluding protein‐ coding regions)....................................................................................................................................................6 Figure S5: Genomic distribution of family members..........................................................................7 Figure S6: MALAT1 family. .............................................................................................................................8 Figure S7: Thermodynamic analysis of structure families using RNAz......................................9 -

Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations Fall 2010 Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress Renuka Nayak University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Computational Biology Commons, and the Genomics Commons Recommended Citation Nayak, Renuka, "Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress" (2010). Publicly Accessible Penn Dissertations. 1559. https://repository.upenn.edu/edissertations/1559 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/1559 For more information, please contact [email protected]. Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress Abstract Genes interact in networks to orchestrate cellular processes. Here, we used coexpression networks based on natural variation in gene expression to study the functions and interactions of human genes. We asked how these networks change in response to stress. First, we studied human coexpression networks at baseline. We constructed networks by identifying correlations in expression levels of 8.9 million gene pairs in immortalized B cells from 295 individuals comprising three independent samples. The resulting networks allowed us to infer interactions between biological processes. We used the network to predict the functions of poorly-characterized human genes, and provided some experimental support. Examining genes implicated in disease, we found that IFIH1, a diabetes susceptibility gene, interacts with YES1, which affects glucose transport. Genes predisposing to the same diseases are clustered non-randomly in the network, suggesting that the network may be used to identify candidate genes that influence disease susceptibility. -
Downloaded from the Mouse Lysosome Gene Database, Mlgdb
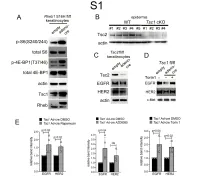
1 Supplemental Figure Legends 2 3 Supplemental Figure S1: Epidermal-specific mTORC1 gain-of-function models show 4 increased mTORC1 activation and down-regulate EGFR and HER2 protein expression in a 5 mTORC1-sensitive manner. (A) Immunoblotting of Rheb1 S16H flox/flox keratinocyte cultures 6 infected with empty or adenoviral cre recombinase for markers of mTORC1 (p-S6, p-4E-BP1) 7 activity. (B) Tsc1 cKO epidermal lysates also show decreased expression of TSC2 by 8 immunoblotting of the same experiment as in Figure 2A. (C) Immunoblotting of Tsc2 flox/flox 9 keratinocyte cultures infected with empty or adenoviral cre recombinase showing decreased EGFR 10 and HER2 protein expression. (D) Expression of EGFR and HER2 was decreased in Tsc1 cre 11 keratinocytes compared to empty controls, and up-regulated in response to Torin1 (1µM, 24 hrs), 12 by immunoblot analyses. Immunoblots are contemporaneous and parallel from the same biological 13 replicate and represent the same experiment as depicted in Figure 7B. (E) Densitometry 14 quantification of representative immunoblot experiments shown in Figures 2E and S1D (r≥3; error 15 bars represent STDEV; p-values by Student’s T-test). 16 17 18 19 20 21 22 23 Supplemental Figure S2: EGFR and HER2 transcription are unchanged with epidermal/ 24 keratinocyte Tsc1 or Rptor loss. Egfr and Her2 mRNA levels in (A) Tsc1 cKO epidermal lysates, 25 (B) Tsc1 cKO keratinocyte lysates and(C) Tsc1 cre keratinocyte lysates are minimally altered 26 compared to their respective controls. (r≥3; error bars represent STDEV; p-values by Student’s T- 27 test). -
97537 Golgin-97 (CDF4) Mouse Mab
Revision 1 C 0 2 - t Golgin-97 (CDF4) Mouse mAb a e r o t S Orders: 877-616-CELL (2355) [email protected] 7 Support: 877-678-TECH (8324) 3 5 Web: [email protected] 7 www.cellsignal.com 9 # 3 Trask Lane Danvers Massachusetts 01923 USA For Research Use Only. Not For Use In Diagnostic Procedures. Applications: Reactivity: Sensitivity: MW (kDa): Source/Isotype: UniProt ID: Entrez-Gene Id: WB, IF-IC H Endogenous 97 Mouse IgG1 Q92805 2800 Product Usage Information 5. Yoshino, A. et al. (2003) J Cell Sci 116, 4441-54. 6. Lu, L. et al. (2004) Mol Biol Cell 15, 4426-43. Application Dilution 7. Lock, J.G. et al. (2005) Traffic 6, 1142-56. 8. Alzhanova, D. and Hruby, D.E. (2006) J Virol 80, 11520-7. Western Blotting 1:1000 9. Alzhanova, D. and Hruby, D.E. (2007) Virology 362, 421-7. Immunofluorescence (Immunocytochemistry) 1:200 Storage Supplied in 10 mM sodium HEPES (pH 7.5), 150 mM NaCl, 100 µg/ml BSA, 50% glycerol and less than 0.02% sodium azide. Store at –20°C. Do not aliquot the antibody. Specificity / Sensitivity Golgin-97 (CDF4) Mouse mAb recognizes endogenous levels of total golgin-97 protein. Species Reactivity: Human Source / Purification Monoclonal antibody is produced by immunizing animals with recombinant human Golgin- 97 protein. Background The Golgi-associated protein golgin A1 (GOLGA1, golgin-97) was first isolated as a Golgi complex autoantigen associated with the autoimmune disorder Sjogren's syndrome (1). The golgin-97 protein contains a carboxy-terminal GRIP domain and is a commonly used trans-Golgi network (TGN) marker.