Webtables: Exploring the Power of Tables on the Web
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Google Docs Accessibility (Pdf)
Google Docs Accessibility (A11y) Building Accessible Google Docs • Heading Styles • Images • Table of Contents • Captioning • Columns and Lists • Tables A11y • Tab Stops • Color Contrast • Paragraph Spacing • Headers and Footers • Meaningful Link Text • Accessibility Checker What is Assistive Technology? Assistive Technology (AT) are “products, equipment, and systems that enhance learning, working, and daily living for persons with disabilities.” Magnification Speech Screen Readers Software Recognition Trackball Mouse Keyboard Zoom Text Braille Computer Keyboard Captions/Subtitles Captioned Telephone Video Relay Services Captioning Videos Per federal and state law, and CSU policy, instructional media (e.g., videos, captured lectures, recorded presentations) must have captions. This includes instructional media used in classrooms, posted on websites or shared in Canvas. • All students who are enrolled in a course must be able to access the content in the course. • Faculty: Funding is available to help faculty generate captions and transcripts for instructional media. Materials should be submitted at least six weeks in advance of their use in instruction. • Staff: For CSUN staff who do not provide classroom material, there is a cost through chargeback. For information on the chargeback, email [email protected]. csun.edu/captioning What are Screen Readers Screen readers are a form of assistive technology (AT) software that enables access to a computer, and all the things a computer does, by attempting to identify and interpret what is being displayed on the computer screen using text-to-speech. Screen readers can only access and process live text (fully editable or selectable text). • Provides access to someone who is visually impaired, mobility or has a learning disability to access text on the screen. -

Profiles Research Networking Software Installation Guide
Profiles Research Networking Software Installation Guide Documentation Version : July 25, 2014 Software Version : ProfilesRNS_2.1.0 Table of Contents Introduction ..................................................................................................................... 2 Hardware and Operating System Requirements ............................................................. 3 Download Options ........................................................................................................... 4 Installing the Database .................................................................................................... 5 Loading Person Data....................................................................................................... 8 Loading Person Data: Part 1 – Importing SSIS Packages into SQL Server msdb Database ..................................................................................................................... 8 Loading Person Data: Part 2 – Importing Demographic Data .................................... 10 Loading Person Data: Part 3 – Geocoding ................................................................ 15 Loading Person Data: Part 4 – Obtaining Publications .............................................. 16 Loading Person Data: Part 5 – Convert data to RDF ................................................. 19 Scheduling Database Jobs ............................................................................................ 21 Installing the Code........................................................................................................ -

A Comparison of Natural Language Understanding Platforms for Chatbots in Software Engineering
1 A Comparison of Natural Language Understanding Platforms for Chatbots in Software Engineering Ahmad Abdellatif, Khaled Badran, Diego Elias Costa, and Emad Shihab, Senior Member, IEEE Abstract—Chatbots are envisioned to dramatically change the future of Software Engineering, allowing practitioners to chat and inquire about their software projects and interact with different services using natural language. At the heart of every chatbot is a Natural Language Understanding (NLU) component that enables the chatbot to understand natural language input. Recently, many NLU platforms were provided to serve as an off-the-shelf NLU component for chatbots, however, selecting the best NLU for Software Engineering chatbots remains an open challenge. Therefore, in this paper, we evaluate four of the most commonly used NLUs, namely IBM Watson, Google Dialogflow, Rasa, and Microsoft LUIS to shed light on which NLU should be used in Software Engineering based chatbots. Specifically, we examine the NLUs’ performance in classifying intents, confidence scores stability, and extracting entities. To evaluate the NLUs, we use two datasets that reflect two common tasks performed by Software Engineering practitioners, 1) the task of chatting with the chatbot to ask questions about software repositories 2) the task of asking development questions on Q&A forums (e.g., Stack Overflow). According to our findings, IBM Watson is the best performing NLU when considering the three aspects (intents classification, confidence scores, and entity extraction). However, the results from each individual aspect show that, in intents classification, IBM Watson performs the best with an F1-measure>84%, but in confidence scores, Rasa comes on top with a median confidence score higher than 0.91. -

Connected Cl As Sroom
Data in the Cloud he ability to move from one representation monthly temperatures for cities in the United of data to another is one of the key char- States, South America, and Russia. Tacteristics of expert mathematicians and A quick inspection of the graph makes it evi- scientists. Cloud computing will offer more dent that on average it is always colder in Verk- opportunities to create and display multiple hoyansk than in Washington (and much colder representations of data, making this skill in the winter) and that the seasons in the south- even more important in the future. ern hemisphere are reversed. These patterns would have been much more difficult to discern Multiple Representations in a table of numbers alone. We can represent data in a variety of forms— Even young students can explore multiple rep- graphs, charts, tables of numbers, equations. resentations of the same data with software such Mathematicians, scientists, and engineers often as The Graph Club (Tom Snyder Productions). look for patterns in data. Different representations This application allows students to view two of the same data sometimes make it easier to see linked representations of data simultaneously. As a pattern. For example, the pattern in the table children drag icons to form a picture graph or of numbers below is not immediately evident. enter numbers in a simple table, a corresponding bar graph or pie chart takes shape (see Figure 2). Changing the size of a sector in the circle graph or the height of a bar in a bar chart Table 1. changes the pictogram or vice versa. -

Voice.AI Gateway One-Click Dialogflow Integration Guide
Integration Guide AudioCodes Intuitive Human Communications for Chatbot Services Voice.AI Gateway Google One-Click DialogFlow Integration Integration Guide Contents Table of Contents 1 Introduction ......................................................................................................... 7 1.1 Purpose .................................................................................................................. 7 2 Messages Sent by Voice.AI Gateway ................................................................ 9 2.1 Welcome Message ................................................................................................. 9 3 Messages Sent by Agent .................................................................................. 11 3.1 Basic Activity Syntax ............................................................................................ 11 3.2 hangup activity ..................................................................................................... 11 3.3 Bot Framework Specific Details ............................................................................ 12 3.3.1 Google Dialogflow ....................................................................................................12 Voice Bot Solutions 3 Voice.AI Gateway One-Click Dialogflow List of Tables Table 2-1: Description of Initial Message Sent by Voice.AI Gateway ...................................................... 9 Table 3-1: Properties of JSON Object Activities.....................................................................................11 -

The Ultimate Guide to Google Sheets Everything You Need to Build Powerful Spreadsheet Workflows in Google Sheets
The Ultimate Guide to Google Sheets Everything you need to build powerful spreadsheet workflows in Google Sheets. Zapier © 2016 Zapier Inc. Tweet This Book! Please help Zapier by spreading the word about this book on Twitter! The suggested tweet for this book is: Learn everything you need to become a spreadsheet expert with @zapier’s Ultimate Guide to Google Sheets: http://zpr.io/uBw4 It’s easy enough to list your expenses in a spreadsheet, use =sum(A1:A20) to see how much you spent, and add a graph to compare your expenses. It’s also easy to use a spreadsheet to deeply analyze your numbers, assist in research, and automate your work—but it seems a lot more tricky. Google Sheets, the free spreadsheet companion app to Google Docs, is a great tool to start out with spreadsheets. It’s free, easy to use, comes packed with hundreds of functions and the core tools you need, and lets you share spreadsheets and collaborate on them with others. But where do you start if you’ve never used a spreadsheet—or if you’re a spreadsheet professional, where do you dig in to create advanced workflows and build macros to automate your work? Here’s the guide for you. We’ll take you from beginner to expert, show you how to get started with spreadsheets, create advanced spreadsheet-powered dashboard, use spreadsheets for more than numbers, build powerful macros to automate your work, and more. You’ll also find tutorials on Google Sheets’ unique features that are only possible in an online spreadsheet, like built-in forms and survey tools and add-ons that can pull in research from the web or send emails right from your spreadsheet. -

Recovering Semantics of Tables on the Web
Recovering Semantics of Tables on the Web Petros Venetis Alon Halevy Jayant Madhavan Marius Pas¸ca Stanford University Google Inc. Google Inc. Google Inc. [email protected] [email protected] [email protected] [email protected] Warren Shen Fei Wu Gengxin Miao Chung Wu Google Inc. Google Inc. UC Santa Barbara Google Inc. [email protected] [email protected] [email protected] [email protected] ABSTRACT away. Furthermore, unlike text documents, where small changes The Web offers a corpus of over 100 million tables [6], but the in the document structure or wording do not correspond to vastly meaning of each table is rarely explicit from the table itself. Header different content, variations in table layout or terminology change rows exist in few cases and even when they do, the attribute names the semantics significantly. In addition to table search, knowing are typically useless. We describe a system that attempts to recover the semantics of tables is also necessary for higher-level operations the semantics of tables by enriching the table with additional anno- such as combining tables via join or union. tations. Our annotations facilitate operations such as searching for In principle, we would like to associate semantics with each table tables and finding related tables. in the corpus, and use the semantics to guide retrieval, ranking and To recover semantics of tables, we leverage a database of class table combination. However, given the scale, breadth and hetero- labels and relationships automatically extracted from the Web. The geneity of the tables on the Web, we cannot rely on hand-coded database of classes and relationships has very wide coverage, but domain knowledge. -

A Simple Generic Attack on Text Captchas
A Simple Generic Attack on Text Captchas Haichang Gao1*, Jeff Yan2*, Fang Cao1, Zhengya Zhang1, Lei Lei1, Mengyun Tang1, Ping Zhang1, Xin Zhou1, Xuqin Wang1 and Jiawei Li1 1. Institute of Software Engineering, Xidian University, Xi’an, Shaanxi, 710071, P.R. China 2. Security Lancaster & School of Computing and Communications, Lancaster University, UK ∗Corresponding authors: [email protected], [email protected] Abstract—Text-based Captchas have been widely deployed attacked many early Captchas deployed on the Internet [19]. across the Internet to defend against undesirable or malicious Yan and El Ahmad broke most visual schemes provided at bot programs. Many attacks have been proposed; these fine prior Captchaservice.org in 2006 [24], published a segmentation art advanced the scientific understanding of Captcha robustness, attack on Captchas deployed by Microsoft and Yahoo! [25] but most of them have a limited applicability. In this paper, in 2008, and broke the Megaupload scheme with a method we report a simple, low-cost but powerful attack that effectively of identifying and merging character components in 2010 [1]. breaks a wide range of text Captchas with distinct design features, including those deployed by Google, Microsoft, Yahoo!, Amazon In 2011, Bursztein et al. showed that 13 Captchas on pop- and other Internet giants. For all the schemes, our attack achieved ular websites were vulnerable to automated attacks, but they a success rate ranging from 5% to 77%, and achieved an achieved zero success on harder schemes such as reCAPTCHA average speed of solving a puzzle in less than 15 seconds on and Google’s own scheme [5]. -

Webkit and Blink: Open Development Powering the HTML5 Revolution
WebKit and Blink: Open Development Powering the HTML5 Revolution Juan J. Sánchez LinuxCon 2013, New Orleans Myself, Igalia and WebKit Co-founder, member of the WebKit/Blink/Browsers team Igalia is an open source consultancy founded in 2001 Igalia is Top 5 contributor to upstream WebKit/Blink Working with many industry actors: tablets, phones, smart tv, set-top boxes, IVI and home automation. WebKit and Blink Juan J. Sánchez Outline The WebKit technology: goals, features, architecture, code structure, ports, webkit2, ongoing work The WebKit community: contributors, committers, reviewers, tools, events How to contribute to WebKit: bugfixing, features, new ports Blink: history, motivations for the fork, differences, status and impact in the WebKit community WebKit and Blink Juan J. Sánchez WebKit: The technology WebKit and Blink Juan J. Sánchez The WebKit project Web rendering engine (HTML, JavaScript, CSS...) The engine is the product Started as a fork of KHTML and KJS in 2001 Open Source since 2005 Among other things, it’s useful for: Web browsers Using web technologies for UI development WebKit and Blink Juan J. Sánchez Goals of the project Web Content Engine: HTML, CSS, JavaScript, DOM Open Source: BSD-style and LGPL licenses Compatibility: regression testing Standards Compliance Stability Performance Security Portability: desktop, mobile, embedded... Usability Hackability WebKit and Blink Juan J. Sánchez Goals of the project NON-goals: “It’s an engine, not a browser” “It’s an engineering project not a science project” “It’s not a bundle of maximally general and reusable code” “It’s not the solution to every problem” http://www.webkit.org/projects/goals.html WebKit and Blink Juan J. -

Webkit and Blink: Bridging the Gap Between the Kernel and the HTML5 Revolution
WebKit and Blink: Bridging the Gap Between the Kernel and the HTML5 Revolution Juan J. Sánchez LinuxCon Japan 2014, Tokyo Myself, Igalia and WebKit Co-founder, member of the WebKit/Blink/Browsers team Igalia is an open source consultancy founded in 2001 Igalia is Top 5 contributor to upstream WebKit/Blink Working with many industry actors: tablets, phones, smart tv, set-top boxes, IVI and home automation. WebKit and Blink Juan J. Sánchez Outline 1 Why this all matters 2 2004-2013: WebKit, a historical perspective 2.1. The technology: goals, features, architecture, ports, webkit2, code, licenses 2.2. The community: kinds of contributors and contributions, tools, events 3 April 2013. The creation of Blink: history, motivations for the fork, differences and impact in the WebKit community 4 2013-2014: Current status of both projects, future perspectives and conclusions WebKit and Blink Juan J. Sánchez PART 1: Why this all matters WebKit and Blink Juan J. Sánchez Why this all matters Long time trying to use Web technologies to replace native totally or partially Challenge enabled by new HTML5 features and improved performance Open Source is key for innovation in the field Mozilla focusing on the browser WebKit and now Blink are key projects for those building platforms and/or browsers WebKit and Blink Juan J. Sánchez PART 2: 2004-2013 WebKit, a historical perspective WebKit and Blink Juan J. Sánchez PART 2.1 WebKit: the technology WebKit and Blink Juan J. Sánchez The WebKit project Web rendering engine (HTML, JavaScript, CSS...) The engine is the product Started as a fork of KHTML and KJS in 2001 Open Source since 2005 Among other things, it’s useful for: Web browsers Using web technologies for UI development WebKit and Blink Juan J. -
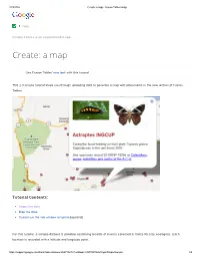
Ate: a Map - Fusion Tables Help
2/19/2014 Create: a map - Fusion Tables Help Help Community Fusion Tables is an experimental app. Create: a map Use Fusion Tables' new look with this tutorial This 2-3 minute tutorial steps you through uploading data to generate a map with placemarks in the new version of Fusion Tables. Tutorial Contents: Import the data Map the data Customize the info window template [optional] For this tutorial, a sample dataset is provided containing records of insects collected in Costa Rica by ecologists. Each location is recorded with a latitude and longitude point. https://support.google.com/fusiontables/answer/2527132?hl=en&topic=2573107&ctx=topic#importsample 1/5 2/19/2014 Create: a map - Fusion Tables Help Import the sample dataset 1. Download this sample insect dataset. 2. Go to Google Docs. Sign in to your Google Account or create a Google Account if you don't already have one. (Note that you can't use a Google Apps for your Domain account for Fusion Tables.) 3. Click the Create button. 4. Choose Create > More > Fusion Table from the dropdown menu. 5. In the Import new table dialog box, click Choose File. 6. Select the "Astraptes fulgerator complex sample data.csv" file you downloaded, and press Next. 7. Check that the data is formatted correctly and click Next. 8. Give your table a name and click Finish. Your uploaded data now appears in a new Fusion Table with thumbnail images in the two columns of URL links: Map the data Fusion Tables auto-detects location data in a table and displays a tab called "Map of <location column name>." In this case, the Map tab is titled "Map of latitude." 1. -

Large Scale Captcha Survey
LARGE SCALE CAPTCHA SURVEY by Mecheal Greene A thesis submitted to the Faculty of the University of Delaware in partial fulfillment of the requirements for the degree of Master of Science in Electrical and Computer Engineering Summer 2018 c 2018 Mecheal Greene All Rights Reserved LARGE SCALE CAPTCHA SURVEY by Mecheal Greene Approved: Haining Wang, Ph.D. Professor in charge of thesis on behalf of the Advisory Committee Approved: Kenneth E. Barner, Ph.D. Chair of the Department of Electrical and Computer Engineering Approved: Babatunde A. Ogunnaike, Ph.D. Dean of the College of Engineering Approved: Douglas J. Doren, Ph.D. Interim Vice Provost for Graduate and Professional Education ACKNOWLEDGMENTS First, I would like to thank the Bridge to Doctorate program for funding me and allowing me the opportunity to pursue my Masters degree at the University of Delaware, immediately following my graduation from Cheyney University. I especially want to thank Dean Doctor Michael Vaughan for being the on campus advisor of the program and assisting me whenever a problem arose. My advisor, Doctor Haining Wang, for guiding me on the completion of my Masters thesis and degree. You allowed me to grow and learn throughout my graduate career. Most, importantly you took a chance on a young black man that you didnt even know but still you embraced me with open arms and worked with me towards accomplishing this goal. My partner on this project Alparslan Sari, you helped me and guided me every step of the way whether it was through meetings, conversations or emails. You knew this was my first time doing anything thesis related but you made it all easier on me and didnt mind helping me above and beyond what I even imagined.