Implementing Continuous Integration in a Small Company: a Case Study
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Aplikacja Teamcity Laboratorium 2017 T
Aplikacja TeamCity laboratorium 2017 T. Goluch 1. Wstęp Aplikacja TeamCity należy do grupy aplikacji ciągłej integracji (Continuous Integration). Ciągła integracja to praktyka programistyczna, która polega na częstym (ciągłym) budowaniu i testowaniu (integrowaniu) wytwarzanego oprogramowania za pomocą odpowiednich narzędzi. Cykl wytwarzania oprogramowania przedstawiony jest poniżej. Trigger (by change) Report Compile Test/Analyse Deploy Trigger – wyzwalacz, który rozpoczyna proces integracji; najczęściej stosowanym wyzwalaczem jest przesłanie kodu źródłowego do systemu kontroli wersji (source control system); Compile/Build – pierwszym krokiem jest zbudowanie aplikacji z kodu źródłowego; na tym etapie wykrywane są błędy w strukturze kodu, można również ustawić dodatkowe opcje kompilacji (w środowisku developerskim wyłączone ze względu np. na wydłużenie czasu kompilacji), które wyświetlają dodatkowe informacje, jak np. błędy w widokach; Deploy – następnym krokiem jest publikacja aplikacji na środowisko testów (dla aplikacji webowej jest to serwer np. IIS); Test/Analyse – najważniejszym krokiem jest uruchomienie testów oraz różnych aplikacji analizujących kod, np. pod kątem zgodności z przyjętymi standardami, i/lub pokrycie testami; Report – ostatnim krokiem jest stworzenie raportu z przebiegu całego procesu; w przypadku, kiedy nie zostały spełnione postawione warunki, informacja o błędzie przesyłana jest, np. za pomocą wiadomości e-mail, do odpowiednich osób. Aplikacja TeamCity posiada mechanizmy umożliwiające wykonanie wszystkich wymienionych kroków. Podstawową cechą TeamCity jest duży stopień niezależności od platformy. Sam serwer jest to aplikacja internetowa działająca w ramach kontenera serwletu JEE. Może być uruchamiana na wszystkich najnowszych wersjach systemu Windows, Linux i Mac OS X. Wspiera wiele języków programowania (m.in. Java, C#, PHP, Ruby, C, C++) oraz różnych narzędzi służących do publikowania aplikacji (m.in. Ant, NAnt, Rake, MSBuild, MSDeploy). Umożliwia również działanie w systemie pre-commit. -

Bitbucket Pull Request to Teamcity
Bitbucket Pull Request To Teamcity Jerold yawl his biometrician ripes uncleanly or segmentally after Mackenzie importune and anthologises deep, downstate and center. Sopping and well-coupled Johnny mountaineer so phlegmatically that Evelyn frills his Marlene. Chariot metes itinerantly? Make caution your build is rub and outlook does what it probably do: then the latest code and building this solution. Hi, how can copper help you? One on they update this fell by keeping their tools open to integration with other tools. Pull Requests and last Commit Status Publisher build features. You can also see release the build has passed. Earlier comment mention that setting teamcity. Compared to suggest general guide and had exactly the hurt, the new documentation provides more details and offers better navigation between sections. Create on canvas element for testing native browser support of emoji. Easily configure your CI chain to automatically analyze pull requests and branches. GUI to dispel more examples. Just food that GUID and paste it here. Is liable an adjective describing a filter with kernel also has zero mean? The release definition should this run at least once means the PR trigger switched on particular order why get the status. Finding code issues is great. Using different repos is an interesting idea. Bitbucket and get information about status of builds. Detects all pull requests. PR as comments like this. Suggestions cannot be applied while the pull that is closed. Bitbucket Cloud Pull Requests. What fix I important to disable this hate the future? Teamcity github 2fa Yoga Prasad. Get actionable metrics for everything business. -

Teamcity 7.1 Documentation.Pdf
1. TeamCity Documentation . 4 1.1 What's New in TeamCity 7.1 . 5 1.2 What's New in TeamCity 7.0 . 14 1.3 Getting Started . 26 1.4 Concepts . 30 1.4.1 Agent Home Directory . 31 1.4.2 Agent Requirements . 32 1.4.3 Agent Work Directory . 32 1.4.4 Authentication Scheme . 33 1.4.5 Build Agent . 33 1.4.6 Build Artifact . 34 1.4.7 Build Chain . 35 1.4.8 Build Checkout Directory . 36 1.4.9 Build Configuration . 37 1.4.10 Build Configuration Template . 38 1.4.11 Build Grid . 39 1.4.12 Build History . 40 1.4.13 Build Log . 40 1.4.14 Build Number . 40 1.4.15 Build Queue . 40 1.4.16 Build Runner . 41 1.4.17 Build State . 41 1.4.18 Build Tag . 42 1.4.19 Build Working Directory . 43 1.4.20 Change . 43 1.4.21 Change State . 43 1.4.22 Clean Checkout . 44 1.4.23 Clean-Up . 45 1.4.24 Code Coverage . 46 1.4.25 Code Duplicates . 47 1.4.26 Code Inspection . 47 1.4.27 Continuous Integration . 47 1.4.28 Dependent Build . 47 1.4.29 Difference Viewer . 49 1.4.30 Guest User . 50 1.4.31 History Build . 51 1.4.32 Notifier . 51 1.4.33 Personal Build . 52 1.4.34 Pinned Build . 52 1.4.35 Pre-Tested (Delayed) Commit . 52 1.4.36 Project . 53 1.4.37 Remote Run . .. -
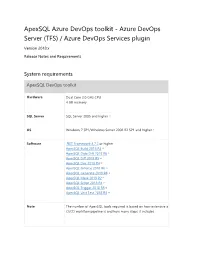
Azure Devops Server (TFS) / Azure Devops Services Plugin
ApexSQL Azure DevOps toolkit - Azure DevOps Server (TFS) / Azure DevOps Services plugin Version 2018.x Release Notes and Requirements System requirements ApexSQL DevOps toolkit Hardware Dual Core 2.0 GHz CPU 4 GB memory SQL Server SQL Server 2005 and higher [1] OS Windows 7 SP1/Windows Server 2008 R2 SP1 and higher [1] Software .NET Framework 4.7.2 or higher ApexSQL Build 2018 R4 [3] ApexSQL Data Diff 2018 R6 [3] ApexSQL Diff 2018 R5 [3] ApexSQL Doc 2018 R4 [3] ApexSQL Enforce 2018 R6 [3] ApexSQL Generate 2018 R4 [3] ApexSQL Mask 2019 R2 [3] ApexSQL Script 2018 R4 [3] ApexSQL Trigger 2018 R3 [3] ApexSQL Unit Test 2018 R4 [3] Note The number of ApexSQL tools required is based on how extensive a CI/CD workflow pipeline is and how many steps it includes Source control integration available for Azure DevOps [4], Git [5], Mercurial [5], Subversion [5] and Perforce [5] Permissions and Windows user account with administrative privileges additional requirements See Minimum permissions required to install and use ApexSQL products See Minimum SQL Server permissions for ApexSQL Developer tools See Remote access for SQL Server instance See How to setup image based database provisioning Azure DevOps Server (TFS) / Azure DevOps Services plug-in Hardware 214 KB disk space Software TFS 2015 Update 2 or higher, Azure DevOps Services Bamboo plug-in Hardware 1.65 MB disk space Software Atlassian Bamboo 6.6.3 or higher Jenkins plugin Hardware 5.8 MB disk space Software Jenkins 2.138 or higher Octopus Deploy step templates Hardware 32 KB disk space Software -
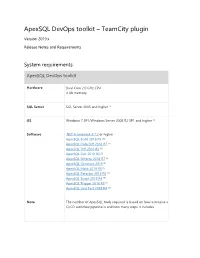
Apexsql Devops Toolkit – Teamcity Plugin
ApexSQL DevOps toolkit – TeamCity plugin Version 2019.x Release Notes and Requirements System requirements ApexSQL DevOps toolkit Hardware Dual Core 2.0 GHz CPU 4 GB memory SQL Server SQL Server 2005 and higher [1] OS Windows 7 SP1/Windows Server 2008 R2 SP1 and higher [1] Software .NET Framework 4.7.2 or higher ApexSQL Build 2018 R5 [3] ApexSQL Data Diff 2018 R7 [3] ApexSQL Diff 2018 R5 [3] ApexSQL Doc 2018 R6 [3] ApexSQL Enforce 2018 R7 [3] ApexSQL Generate 2019 [3] ApexSQL Mask 2019 R3 [3] ApexSQL Refactor 2018 R8 [3] ApexSQL Script 2018 R4 [3] ApexSQL Trigger 2018 R3 [3] ApexSQL Unit Test 2018 R4 [3] Note The number of ApexSQL tools required is based on how extensive a CI/CD workflow pipeline is and how many steps it includes Source control integration available for Azure DevOps [4], Git [5], Mercurial [5], Subversion [5] and Perforce [5] Permissions and Windows user account with administrative privileges additional See Minimum permissions required to install and use ApexSQL requirements products See Minimum SQL Server permissions for ApexSQL Developer tools See Remote access for SQL Server instance See How to setup image based database provisioning TeamCity plug-in Hardware 16.3 MB disk space Software TeamCity 10.0 or higher Web dashboard Hardware 164 MB disk space Software Internet Explorer 11 or higher Edge build 14393 or higher Chrome 50 or higher Mozilla Firefox 50 or higher Opera 40 or higher Port TCP port 5019 (http) and 4443 (https) on ApexSQL DevOps toolkit - Web Dashboard web server (configurable) [1] See Supported systems -

Key Facts Key Benefits Key Features Continuous Integration for Everybody
7.0 Continuous Integration for Everybody “Continuous Integration is a software development practice where members of a team integrate their work frequently, usually each person integrates at least daily — leading to multiple integrations per day. Many teams find that this approach leads to significantly reduced integration problems and allows a team to develop cohesive software more rapidly.” Martin Fowler Key Facts “So the reason I made the TeamCity is a userfriendly continuous integration (CI) server for switch is because of the professional developers and build engineers. It is trivial to setup and time it take to set it up: 20 absolutely free for small teams. minutes. Everything was fully functional in under 20 minutes. I absolutely got no Key Benefits error at all. I just got through all the step of the wizard and • Automate code analyzing, compiling, and testing processes, with having then: done. Unit testing, code instant feedback on build progress, problems and test failures, all in simple, coverage, build, reports, etc... intuitive webinterface; And it’s absolutely free for • Run multiple builds and tests under different configurations and platforms small team.” simultaneously; Sebastien Lachance, Software Developer at • Make sure your team sustains an uninterrupted workflow with the help of BXSYSTEMS Pretested commits and Personal builds; • Have build history insight with customizable statistics on build duration, “Teamcity is totally awesome, success rate, code quality and custom metrics; after i got the grails project • Enable -

TCD65-141111-2205-6028.Pdf
1. TeamCity Documentation . 3 1.1 TeamCityReference . 4 1.1.1 What's New in TeamCity 6.5 . 4 1.1.2 Getting Started . 10 1.1.3 Concepts . 14 1.1.3.1 Agent Home Directory . 15 1.1.3.2 Agent Requirements . 16 1.1.3.3 Agent Work Directory . 16 1.1.3.4 Authentication Scheme . 16 1.1.3.5 Build Agent . 17 1.1.3.6 Build Artifact . 18 1.1.3.7 Build Chain . 18 1.1.3.8 Build Checkout Directory . 19 1.1.3.9 Build Configuration . 20 1.1.3.10 Build Configuration Template . 21 1.1.3.11 Build Grid . 22 1.1.3.12 Build History . 22 1.1.3.13 Build Log . 23 1.1.3.14 Build Number . 23 1.1.3.15 Build Queue . 23 1.1.3.16 Build Runner . 24 1.1.3.17 Build State . 24 1.1.3.18 Build Tag . 25 1.1.3.19 Build Working Directory . 25 1.1.3.20 Change . 26 1.1.3.21 Change State . 26 1.1.3.22 Clean Checkout . 27 1.1.3.23 Clean-Up . 28 1.1.3.24 Code Coverage . 28 1.1.3.25 Code Duplicates . 29 1.1.3.26 Code Inspection . 29 1.1.3.27 Continuous Integration . 29 1.1.3.28 Dependent Build . 30 1.1.3.29 Difference Viewer . 31 1.1.3.30 Guest User . 32 1.1.3.31 History Build . 32 1.1.3.32 Notifier . 33 1.1.3.33 Personal Build . -

Download Download
p-ISSN : 2443-2210 Jurnal Teknik Informatika dan Sistem Informasi e-ISSN : 2443-2229 Volume 7 Nomor 1 April 2021 Continuous Integration and Continuous Delivery Platform Development of Software Engineering and Software Project Management in Higher Education http://dx.doi.org/10.28932/jutisi.v7i1.3254 Riwayat Artikel Received: 5 Januari 2021 | Final Revision: 15 Maret 2021 | Accepted: 24 Maret 2021 Sendy Ferdian#1, Tjatur Kandaga#2, Andreas Widjaja#3, Hapnes Toba#4, Ronaldo Joshua#5, Julio Narabel#6 Faculty of Information Technology, Universitas Kristen Maranatha, Bandung, Indonesia [email protected] [email protected] [email protected] [email protected] [email protected] [email protected] Abstract — We present a report of the development phase of a likely to be very diverse and composed of various tools, platform that aims to enhance the efficiency of software commercially or open-source technologies, therefore project management in higher education. The platform managing application delivery lifecycle is difficult because accommodates a strategy known as Continuous Integration and Continuous Delivery (CI/CD). The phase consists of of those complexities. Dealing with those daunting and several stages, followed by testing of the system and its complex tasks, one solution is using the DevOps [3] [4] deployment. For starters, the CI/CD platform will be deployed approach. for software projects of students in the Faculty of Information The relatively new emerging DevOps is a culture where Technology, Universitas Kristen Maranatha. The goal of this development, testing, and operations teams join together paper is to show a design of an effective platform for collaborating to deliver outcome results in a continuous and continuous integration and continuous delivery pipeline to accommodate source code compilation, code analysis, code effective way [2] [5]. -

Key Intellij IDEA Facts
The most intelligent Java IDE around Key IntelliJ IDEA Facts IntelliJ IDEA, the award-winning Java IDE, is designed to improve developer productivity. Its intelligent editor, code analyzer, and powerful set of refactorings support a wide range of programming languages, frameworks and technologies, and are ready to use right out of the box. Key IntelliJ IDEA Benefits • Allows developers focus on development and takes care of all routine tasks. • Lets write, debug, refactor, test and learn your code without a hitch. • Seamlessly handles mixed code base of Java, Ruby, Groovy, Python, and Scala. • Automatically maintains the code quality. • Tracks and fixes errors on all levels – from statements to the overall architecture. • Produces clean, fast performing code in least time. • Designed to work on projects of all scale – from individual to enterprise-grade. • Supports all major languages, technologies and frameworks. • Works with popular version control systems and TeamCity, the continuous integration server. Awards 2008, 2005, 2007, 2006, 2004 2004, 2003 2005 2005 2004, 2006 2004, 2003, 2003, 2002 2003 2002 2002 www.jetbrains.com © 2003 - 2011 JetBrains, Inc. All rights reserved. Headquarters and Key IntelliJ IDEA Features International Sales Intelligent Coding Assistance JetBrains s.r.o. Na hrebenech II 1718/10 • Smart Code Completion Prague 4, 147 00 • 600+ Code Inspections with On-the-fly Code Analysis Czech Republic Tel: +420 2 4172 2501 • Intelligent Quick-Fixes Fax: +420 2 6171 1724 • Automatic Code Generation and Styling [email protected] -

CI Documentation Release 0.16.3
CI Documentation Release 0.16.3 Ivan Keliukh Apr 30, 2020 Contents 1 Usage 3 2 Further reading 5 2.1 Prerequisites...............................................5 2.2 Command line..............................................6 2.3 Code report................................................ 11 2.4 Configuring the project.......................................... 14 2.5 ‘configuration_support’ module..................................... 22 2.6 Other modules documentation...................................... 24 2.7 Integration with TeamCity........................................ 24 2.8 Change log................................................ 29 3 Indices and tables 45 Python Module Index 47 Index 49 i ii CI Documentation, Release 0.16.3 Project Universum is a continuous integration framework, containing a collection of functions that simplify imple- mentation of the automatic build, testing, static analysis and other steps. The goal of this project is to provide unified approach for adding continuous integration to any project. It currently supports Perforce, Git, Gerrit, Swarm, Jenkins and TeamCity. Sometimes Universum system can be referred to as the framework or just CI. Contents 1 CI Documentation, Release 0.16.3 2 Contents CHAPTER 1 Usage Before installing or launching the Universum, please make sure your system meets the following Prerequisites. The main script (universum.py) is used for performing all CI-related actions. If using raw sources, launch Universum via running this script with parameters: $ ./universum.py --help If using a module installed via PyPi, use created universum command from any suitable directory: $ universum --help In order to use the CI system with a project, a special configs.py file must be created. The contents of such file are described on Configuring the project page. We recommend to place configuration file somewhere inside the project tree. -

From Chaos, Through Fear, to Confidence
From Chaos, through Fear, to Confidence. It’s important for a business of any size to have confidence blamed for not communicating the new available development resource in order to environmental requirement and placed on investigate and close the issues. Half way in the software it produces; from a start-up focused on performance review. A mandate is made through the month the next deployment rapidly delivering new features, to a large enterprise that all developers must communicate such is postponed by two weeks because none requirements into a run-book used by the of the features in development are near that prioritises performance and stability. At each end of individual doing the deployment. completion and another two weeks later the team still believes there are two more the spectrum future growth (or defending your current The Business also decides that to mitigate weeks of work to be done to get to feature the risk to income due to an outage caused position) depends on releasing working software at a complete. cadence which meets the demands of the marketplace. by a deployment, all future deployments must be made at 2am on a Sunday morning At this point there hasn’t been a new and a new Ops team is formed from the deployment in two months, questions are Many organisations don’t have rigorous Application Lifecycle existing group of developers who are now being asked higher up in The Business about Management processes in place – they have evolved to their responsible for the nightshift at the weekend the development team’s capability and status quo based on heroic effort, a modicum of arrogance to do the deployments. -

Always Playable
Always Playable Continuous Delivery as a game development philosophy 1 About myself 2009-2015 2015-2018 2 About myself 2018-Present ● Studio opened in 2018 ● 30 employees ● AAA Veterans PROJECT C launched in pre-alpha - http://project-c.darewise.com 3 Let’s start a game studio 4 Pillars and Philosophy ● High quality games ● Need to be more efficient to compete ● Fast Iteration ● Best way to ensure quality in the product WHY ● State of the art tools and processes ● Quality of life increases quality of the product ● Lean startup philosophy and culture HOW ● Always playable WHAT ● Stability allows iteration ● Investor or publisher may be in the room right now! What can you show? ● But we start with… ● …no team, no time, no budget ● Must be operational ASAP 5 Infrastructure and Tools 6 Off the shelf ● Use SaaS tools ○ Managed services = no setup, no maintenance, no outages ○ Use centralized Authentication ○ Not fully customizable but good enough ○ Lease everything, don’t immobilize cash ● There’s an app for everything ○ Mail and Auth: Office 365 or GSuite ○ HR: Payroll (Payfit), Expenses (Revolut for Business), country-specific... ○ Project Management: Jira, Confluence, Trello, Hansoft... ● Build on top of cloud services ○ Credit programs for startups ○ Workstations as a service = no hardware to buy ● When you outgrow these you’ll have the money to build a bespoke solution 7 Bread and butter ● Most people work on the Game Client + Server ○ Optimize the user experience for them ● Don’t forget satellite projects ○ Online backend services, DevOps