Cirdox: an On/Off-Line Multisource Speech and Sound Analysis Software
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SCIS Boardman Labs User Manual Version5
SCIS Common Use Labs in Boardman Hall USER MANUAL Note: The instructions in this manual assume students walking into the labs are first-time users of the labs and are complete novices in using the machines. Table of Contents Page I. Access to Boardman Hall SCIS Labs for Computer Science and New Media Students A. Services Provided 2 B. Gaining Access to Lab Rooms and Computers 3 II. SCIS Common Use Lab (Room 138 Boardman) A. Services Provided 3 B. Use of iMacs on Tables 4 C. Use of Large Table Monitor for Sharing Among Table Group 4 D. Use of Overhead Projector 5 E. Use of Laser Printer (8 ½ by 11” Prints) 6 F. Use of Large Format Plotter 7 G. Software Available on Computers in Room 138 7 H. Equipment Available for Checkout from Room 138 Lab Monitors 8 III. Combined Focus Ring and Stillwater Labs (Rooms 127 and 129 Boardman) A. Services Provided 8 B. Use of iMacs on Tables 9 C. Use of Cybertron PC for AI and VR D. Use of … E. Software Available on Computers in Rooms 127 and 129 F. Equipment Checkout Procedure G. Equipment Available for Checkout from Rooms 127 and 129 Lab Monitors IV. SCIS Student Lounge and Project Work Room (Room 137 Boardman) A. Services Provided B. Use of Large Screen by Students APPENDICES Appendix A. Laptop Computer Recommendations for Computer Science Students Appendix B. Laptop Computer Recommendations for New Media Students Appendix C. Convenient Web Resources for Development of Computer Code Note: On SCIS web site all of the above topics will link to anchors at the same topics below. -

Tworzenie Dokumentów, Prawo Autorskie
Zajęcia 7 - tworzenie dokumentów JANUSZ WRÓBEL Typy plików Tekstowe txt – najprostszy plik tekstowy np. z Notatnika doc, docx - dokumenty z WORDA lub WORDPADA odt – dokumenty z programu OPENOFFICE rtf – format tekstowy zawierający podstawowe formatowanie tekstu kompatybilny z wieloma edytorami tekstu Graficzne jpg – najpopularniejszy format plików graficznych png – format głównie wykorzystywany przez Internet gif – format graficzny umożliwiający przechowanie wielu obrazów tworzących np. animację Tiff – format kompresji bezstratnej Dźwiękowe Mp3 – najpopularniejszy, stratny zapis dźwięku Midi - standard dla przechowywania zapisu dźwięku zbliżonego do nutowego Wav – popularny standard dla Windowsa i internetu Wma – gównie pliki w Windowsie Wideo MPEG4 – najpopularniejszy standard kodowania umożliwiający rejestrowanie i przesyłanie na bieżąco wizji i fonii. MOV- kodowanie firmy Apple wymaga specjalnego odtwarzacza QuickTime Player Avi – format zapisu filmów zwykle przeznaczonych do dalszej obróbki WMV – format kompresji filmów firmy Microsoft FLV – format filmów wykorzystywany na stronach www Uruchamialne EXE – popularny dla Windowsa plik programu mogący zawierać różne zasoby np. okna, ikony, dźwięki BAT – program wykonywany przez komputer bez wpływu użytkownika na jego przebieg (tryb wsadowy) COM – dawniej popularny typ programów wykonywalnych w systemie DOS Skompresowane ZIP – format kompresji bezstratnej i archiwizacji na PC (Personal Computer) RAR – format kompresji bezstratnej i archiwizacji JPG, MPEG, MP3 – to -
Audacity® Is Recording and Audio Editing Software That Is Free, Open Sourced, and Generally Easy to Use
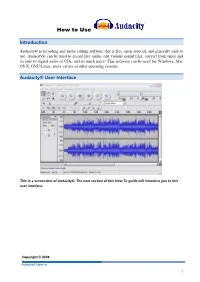
How to Use Introduction Audacity® is recording and audio editing software that is free, open sourced, and generally easy to use. Audacity® can be used to record live audio, edit various sound files, convert from tapes and records to digital audio or CDs, and so much more! This software can be used for Windows, Mac OS X, GNU/Linux, and a variety of other operating systems. Audacity® User Interface This is a screenshot of Audacity®. The next section of this How-To guide will introduce you to this user interface. Copyright © 2008 Audacity® How- to 1 Audacity® User Interface: Toolbars The Audacity® Control Toolbar Envelope Tool Skip to Start Stop Button Button Select D r a w Record Tool Tool Button Zoom Multi- Tool Tool Pause Skip to End Timeshift Play Button Button Tool Button The Audacity® Edit Toolbar Zoom Zoom To Copy Cut Paste Undo Redo Out Selection Zoom Zoom To Trim Silence In Entire Project The Audacity® Meter & Mixer Toolbars Input Output Level Level Meter Meter Output Input Volume Volume Input Control Control Source Selector Copyright © 2008 Audacity® How- to 2 Importing Audio with Audacity® 1. Create a New Project This is an important step. Give your project a name & saving location prior to working in Audacity®. Select and choose a file name and location to save your project. *Note when you initially begin Audacity® only the “Save As” function will be available. 2. Check Preferences Click File > Preferences (Ctrl + P) Check to be sure the correct Playback & Recording Devices have been selected. Copyright © 2008 Audacity® How- to 3 Set the sample rate of your choice. -

Command-Line Sound Editing Wednesday, December 7, 2016
21m.380 Music and Technology Recording Techniques & Audio Production Workshop: Command-line sound editing Wednesday, December 7, 2016 1 Student presentation (pa1) • 2 Subject evaluation 3 Group picture 4 Why edit sound on the command line? Figure 1. Graphical representation of sound • We are used to editing sound graphically. • But for many operations, we do not actually need to see the waveform! 4.1 Potential applications • • • • • • • • • • • • • • • • 1 of 11 21m.380 · Workshop: Command-line sound editing · Wed, 12/7/2016 4.2 Advantages • No visual belief system (what you hear is what you hear) • Faster (no need to load guis or waveforms) • Efficient batch-processing (applying editing sequence to multiple files) • Self-documenting (simply save an editing sequence to a script) • Imaginative (might give you different ideas of what’s possible) • Way cooler (let’s face it) © 4.3 Software packages On Debian-based gnu/Linux systems (e.g., Ubuntu), install any of the below packages via apt, e.g., sudo apt-get install mplayer. Program .deb package Function mplayer mplayer Play any media file Table 1. Command-line programs for sndfile-info sndfile-programs playing, converting, and editing me- Metadata retrieval dia files sndfile-convert sndfile-programs Bit depth conversion sndfile-resample samplerate-programs Resampling lame lame Mp3 encoder flac flac Flac encoder oggenc vorbis-tools Ogg Vorbis encoder ffmpeg ffmpeg Media conversion tool mencoder mencoder Media conversion tool sox sox Sound editor ecasound ecasound Sound editor 4.4 Real-world -

Sound-HOWTO.Pdf
The Linux Sound HOWTO Jeff Tranter [email protected] v1.22, 16 July 2001 Revision History Revision 1.22 2001−07−16 Revised by: jjt Relicensed under the GFDL. Revision 1.21 2001−05−11 Revised by: jjt This document describes sound support for Linux. It lists the supported sound hardware, describes how to configure the kernel drivers, and answers frequently asked questions. The intent is to bring new users up to speed more quickly and reduce the amount of traffic in the Usenet news groups and mailing lists. The Linux Sound HOWTO Table of Contents 1. Introduction.....................................................................................................................................................1 1.1. Acknowledgments.............................................................................................................................1 1.2. New versions of this document.........................................................................................................1 1.3. Feedback...........................................................................................................................................2 1.4. Distribution Policy............................................................................................................................2 2. Sound Card Technology.................................................................................................................................3 3. Supported Hardware......................................................................................................................................4 -

EMEP/MSC-W Model Unofficial User's Guide
EMEP/MSC-W Model Unofficial User’s Guide Release rv4_36 https://github.com/metno/emep-ctm Sep 09, 2021 Contents: 1 Welcome to EMEP 1 1.1 Licenses and Caveats...........................................1 1.2 Computer Information..........................................2 1.3 Getting Started..............................................2 1.4 Model code................................................3 2 Input files 5 2.1 NetCDF files...............................................7 2.2 ASCII files................................................ 12 3 Output files 17 3.1 Output parameters NetCDF files..................................... 18 3.2 Emission outputs............................................. 20 3.3 Add your own fields........................................... 20 3.4 ASCII outputs: sites and sondes..................................... 21 4 Setting the input parameters 23 4.1 config_emep.nml .......................................... 23 4.2 Base run................................................. 24 4.3 Source Receptor (SR) Runs....................................... 25 4.4 Separate hourly outputs......................................... 26 4.5 Using and combining gridded emissions................................. 26 4.6 Nesting.................................................. 27 4.7 config: Europe or Global?........................................ 31 4.8 New emission format........................................... 32 4.9 Masks................................................... 34 4.10 Other less used options......................................... -

RFP Response to Region 10 ESC
An NEC Solution for Region 10 ESC Building and School Security Products and Services RFP #EQ-111519-04 January 17, 2020 Submitted By: Submitted To: Lainey Gordon Ms. Sue Hayes Vertical Practice – State and Local Chief Financial Officer Government Region 10 ESC Enterprise Technology Services (ETS) 400 East Spring Valley Rd. NEC Corporation of America Richardson, TX 75081 Cell: 469-315-3258 Office: 214-262-3711 Email: [email protected] www.necam.com 1 DISCLAIMER NEC Corporation of America (“NEC”) appreciates the opportunity to provide our response to Education Service Center, Region 10 (“Region 10 ESC”) for Building and School Security Products and Services. While NEC realizes that, under certain circumstances, the information contained within our response may be subject to disclosure, NEC respectfully requests that all customer contact information and sales numbers provided herein be considered proprietary and confidential, and as such, not be released for public review. Please notify Lainey Gordon at 214-262-3711 promptly upon your organization’s intent to do otherwise. NEC requests the opportunity to negotiate the final terms and conditions of sale should NEC be selected as a vendor for this engagement. NEC Corporation of America 3929 W John Carpenter Freeway Irving, TX 75063 http://www.necam.com Copyright 2020 NEC is a registered trademark of NEC Corporation of America, Inc. 2 Table of Contents EXECUTIVE SUMMARY ................................................................................................................................... -

Sox Examples
Signal Analysis Young Won Lim 2/17/18 Copyright (c) 2016 – 2018 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License". Please send corrections (or suggestions) to [email protected]. This document was produced by using LibreOffice. Young Won Lim 2/17/18 Based on Signal Processing with Free Software : Practical Experiments F. Auger Audio Signal Young Won Lim Analysis (1A) 3 2/17/18 Sox Examples Audio Signal Young Won Lim Analysis (1A) 4 2/17/18 soxi soxi s1.mp3 soxi s1.mp3 > s1_info.txt Input File Channels Sample Rate Precision Duration File Siz Bit Rate Sample Encoding Audio Signal Young Won Lim Analysis (1A) 5 2/17/18 Generating signals using sox sox -n s1.mp3 synth 3.5 sine 440 sox -n s2.wav synth 90000s sine 660:1000 sox -n s3.mp3 synth 1:20 triangle 440 sox -n s4.mp3 synth 1:20 trapezium 440 sox -V4 -n s5.mp3 synth 6 square 440 0 0 40 sox -n s6.mp3 synth 5 noise Audio Signal Young Won Lim Analysis (1A) 6 2/17/18 stat Sox s1.mp3 -n stat Sox s1.mp3 -n stat > s1_info_stat.txt Samples read Length (seconds) Scaled by Maximum amplitude Minimum amplitude Midline amplitude Mean norm Mean amplitude RMS amplitude Maximum delta Minimum delta Mean delta RMS delta Rough frequency Volume adjustment Audio Signal Young Won -

Name Synopsis Description Options
SoXI(1) Sound eXchange SoXI(1) NAME SoXI − Sound eXchange Information, display sound file metadata SYNOPSIS soxi [−V[level]] [−T][−t|−r|−c|−s|−d|−D|−b|−B|−p|−e|−a] infile1 ... DESCRIPTION Displays information from the header of a givenaudio file or files. Supported audio file types are listed and described in soxformat(7). Note however, that soxi is intended for use only with audio files with a self- describing header. By default, as much information as is available is shown. An option may be giventoselect just a single piece of information (perhaps for use in a script or batch-file). OPTIONS −V Set verbosity.See sox(1) for details. −T Used with multiple files; changes the behaviour of −s, −d and −D to display the total across all givenfiles. Note that when used with −s with files with different sampling rates, this is of ques- tionable value. −t Showdetected file-type. −r Showsample-rate. −c Shownumber of channels. −s Shownumber of samples (0 if unavailable). −d Showduration in hours, minutes and seconds (0 if unavailable). Equivalent to number of samples divided by the sample-rate. −D Showduration in seconds (0 if unavailable). −b Shownumber of bits per sample (0 if not applicable). −B Showthe bitrate averaged overthe whole file (0 if unavailable). −p Showestimated sample precision in bits. −e Showthe name of the audio encoding. −a Showfile comments (annotations) if available. BUGS Please report anybugs found in this version of SoX to the mailing list ([email protected]). SEE ALSO sox(1), soxformat(7), libsox(3) The SoX web site at http://sox.sourceforge.net LICENSE Copyright 2008−2013 by Chris Bagwell and SoX Contributors. -

Audacity Manual.Pdf
A Free, Open Source, Cross-Platform Audio Editor Version 1.2.4 This is the online help for Audacity. It is meant to be a quick reference, not a complete manual. There is also a complete user's manual available online: http://audacity.sourceforge.net/help/documentation Table of Contents Table of Contents............................................................................................................................ 1 Toolbars .......................................................................................................................................... 3 Control Toolbar........................................................................................................................... 3 Editing Tools........................................................................................................................... 3 Audio Control Buttons............................................................................................................ 3 Mixer Toolbar ............................................................................................................................. 4 Edit Toolbar ................................................................................................................................4 Meter Toolbar ............................................................................................................................. 5 Menu Bar ....................................................................................................................................... -

Audacity: Record, Import & Export on Windows & Macintosh Platforms
IMC Innovate Make Create https://library.albany.edu/imc/ 518 442-3607 Audacity: record, import & export on Windows & Macintosh platforms Audacity is an open-source application to edit sound files and convert them to various formats. It is freely available to the public for download. The copyright law of the United States (Title 17, United States Code) governs the reproduction of copyrighted material. The person using this equipment and software is liable for any infringement. To install Audacity, download from https://www.audacityteam.org/. To work with many audio file types (i.e. OGG, ac3, and audio from video) download the FFmpeg plug-in [NOTE: versions previous to 2.3.2 also require the MP3 lame encoder to work with MP3 files]. After installing Audacity, open the application. From the top line menu select Edit > Preferences on Windows and Audacity > Preferences on Mac. Select Libraries from the menu on the left. Select Download for FFmpeg. Follow the instructions for adding this export/import Library. NOTES when working in Audacity If you are using multiple tracks, they should all be the same format. Use the [keyboard] space bar to play and stop the audio track If Pause or Play is selected you cannot execute commands. IMPORTING A SOUND FILE NOTES: Audio files from a CD must first be “ripped” or extracted using CD extraction software and then imported into Audacity. Audio may be extracted from video. From the top line menu select File > Import > Audio... Page 1 of 4 Make a copy of the file before editing to ensure that the original audio is untouched and that the file imported into Audacity will always be associated with the project. -

Le Capitole Du Libre
Capitole du Libre 2016 Communiqué de Presse 8 novembre 2016 Benh Lieu Song – CC-BY-SA 3.0 Association Toulibre http://toulibre.org http://capitoledulibre.org [email protected] Le Capitole du Libre Le Capitole du Libre est un évènement tout public de promotion des logiciels libres, organisé par l’association Toulibre. Il se déroule à Toulouse, chaque année depuis 2009, sur un weekend du mois de novembre. Grâce à une programmation variée et de qualité, le Capitole du Libre est aujourd’hui une référence parmi les manifestations consacrées aux logiciels libres. Le public et les orateurs y viennent plus nombreux — et de plusieurs pays voisins — chaque année. Tout au long du weekend, des conférences et des ateliers pratiques sur des sujets variés, aussi bien techniques que grand public, se déroulent en parallèle. Le Capitole du Libre est également l’occasion de réunir des communautés du libre pour des conférences, lightning talks, coding sprints… Le Capitole du Libre a accueilli plusieurs évènements depuis 2011 tels que : • DrupalCamp en 2011 ; • DjangoCon en 2012 ; • FranceJS en 2013 ; • LuaWorkshop en 2013 ; • OpenStack en 2013 ; • Hackfest LibreOffice en 2014 ; • Akademy-FR depuis la première édition ! Un village associatif permet également de présenter les projets des associations du libre : Liberté0, Wikimédia France, OpenStreetMap France, Framasoft ou encore Tetaneutral.net. Amphithéâtre comble pour Stéphane Bortzmayer de l’AFNIC L’évènement est basé uniquement sur le bénévolat. Durant les mois de préparation et pendant tout le weekend, Capitole du Libre 2016 https://2016.capitoledulibre.org Dossier de Presse 2/7 100 bénévoles des associations et des clubs techniques de l’INP-ENSEEIHT se sont mobilisés pour l’élabo- ration du programme, l’accueil du public, la captation des conférences ou encore l’aide à l’installation des logiciels libres.