Visatm Étude Recensement D'outils De Fouille De Textes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Statistický Software
Statistický software 1 Software AcaStat GAUSS MRDCL RATS StatsDirect ADaMSoft GAUSS NCSS RKWard[4] Statistix Analyse-it GenStat OpenEpi SalStat SYSTAT The ASReml GoldenHelix Origin SAS Unscrambler Oxprogramming Auguri gretl language SOCR UNISTAT BioStat JMP OxMetrics Stata VisualStat BrightStat MacAnova Origin Statgraphics Winpepi Dataplot Mathematica Partek STATISTICA WinSPC EasyReg Matlab Primer StatIt XLStat EpiInfo MedCalc PSPP StatPlus XploRe EViews modelQED R SPlus Excel Minitab R Commander[4] SPSS 2 Data miningovýsoftware n Cca 20 až30 dodavatelů n Hlavníhráči na trhu: n Clementine, IBM SPSS Modeler n IBM’s Intelligent Miner, (PASW Modeler) n SGI’sMineSet, n SAS’s Enterprise Miner. n Řada vestavěných produktů: n fraud detection: n electronic commerce applications, n health care, n customer relationship management 3 Software-SAS n : www.sas.com 4 SAS n Společnost SAS Institute n Vznik 1976 v univerzitním prostředí n Dnes:největšísoukromásoftwarováspolečnost na světě (více než11.000 zaměstnanců) n přes 45.000 instalací n cca 9 milionů uživatelů ve 118 zemích n v USA okolo 1.000 akademických zákazníků (SAS používávětšina vyšších a vysokých škol a výzkumných pracovišť) 5 SAS 6 SAS 7 SAS q Statistickáanalýza: Ø Popisnástatistika Ø Analýza kontingenčních (frekvenčních) tabulek Ø Regresní, korelační, kovariančníanalýza Ø Logistickáregrese Ø Analýza rozptylu Ø Testováníhypotéz Ø Diskriminačníanalýza Ø Shlukováanalýza Ø Analýza přežití Ø … 8 SAS q Analýza časových řad: Ø Regresnímodely Ø Modely se sezónními faktory Ø Autoregresnímodely Ø -

The R Project for Statistical Computing a Free Software Environment For
The R Project for Statistical Computing A free software environment for statistical computing and graphics that runs on a wide variety of UNIX platforms, Windows and MacOS OpenStat OpenStat is a general-purpose statistics package that you can download and install for free. It was originally written as an aid in the teaching of statistics to students enrolled in a social science program. It has been expanded to provide procedures useful in a wide variety of disciplines. It has a similar interface to SPSS SOFA A basic, user-friendly, open-source statistics, analysis, and reporting package PSPP PSPP is a program for statistical analysis of sampled data. It is a free replacement for the proprietary program SPSS, and appears very similar to it with a few exceptions TANAGRA A free, open-source, easy to use data-mining package PAST PAST is a package created with the palaeontologist in mind but has been adopted by users in other disciplines. It’s easy to use and includes a large selection of common statistical, plotting and modelling functions AnSWR AnSWR is a software system for coordinating and conducting large-scale, team-based analysis projects that integrate qualitative and quantitative techniques MIX An Excel-based tool for meta-analysis Free Statistical Software This page links to free software packages that you can download and install on your computer from StatPages.org Free Statistical Software This page links to free software packages that you can download and install on your computer from freestatistics.info Free Software Information and links from the Resources for Methods in Evaluation and Social Research site You can sort the table below by clicking on the column names. -

Cumulation of Poverty Measures: the Theory Beyond It, Possible Applications and Software Developed
Cumulation of Poverty measures: the theory beyond it, possible applications and software developed (Francesca Gagliardi and Giulio Tarditi) Siena, October 6th , 2010 1 Context and scope Reliable indicators of poverty and social exclusion are an essential monitoring tool. In the EU-wide context, these indicators are most useful when they are comparable across countries and over time. Furthermore, policy research and application require statistics disaggregated to increasingly lower levels and smaller subpopulations. Direct, one-time estimates from surveys designed primarily to meet national needs tend to be insufficiently precise for meeting these new policy needs. This is particularly true in the domain of poverty and social exclusion, the monitoring of which requires complex distributional statistics – statistics necessarily based on intensive and relatively small- scale surveys of households and persons. This work addresses some statistical aspects relating to improving the sampling precision of such indicators in EU countries, in particular through the cumulation of data over rounds of regularly repeated national surveys. 2 EU-SILC The reference data for this purpose are EU Statistics on Income and Living Conditions, the major source of comparative statistics on income and living conditions in Europe. A standard integrated design has been adopted by nearly all EU countries. It involves a rotational panel, with a new sample of households and persons introduced each year to replace one-fourth of the existing sample. Persons enumerated in each new sample are followed-up in the survey for four years. The design yields each year a cross- sectional sample, as well as longitudinal samples of 2, 3 and 4 year duration. -

Development and Validation of Survey Questionnaire Experimental Data – a Systematical Review-Based Statistical Approach
Munich Personal RePEc Archive Development and Validation of Survey Questionnaire Experimental Data – A Systematical Review-based Statistical Approach Aithal, Architha and Aithal, Sreeramana Srinivas College of Pharmacy, Mangalore, India, College of Management Commerce, Srinivas University, Mangalore, India 30 October 2020 Online at https://mpra.ub.uni-muenchen.de/103996/ MPRA Paper No. 103996, posted 12 Nov 2020 06:35 UTC Development and Validation of Survey Questionnaire & Experimental Data – A Systematical Review-based Statistical Approach Architha Aithal* & P. S. Aithal** *Intern, PharmD, Srinivas College of Pharmacy, Mangalore, India OrchID: 0000-0003-2361-5166; E-mail: [email protected] **Professor, College of Management & Commerce, Srinivas University, Mangalore, India OrcidID: 0000-0002-4691-8736; E-mail: [email protected] November 2020 ABSTRACT In quantitative research methodology, the empirical research method is finding importance due to its effectiveness in carrying out research in social sciences, business management, and health sciences. The empirical research method contains the procedure of developing a model to find the relationship between different variables identified in a problem. Based on developing hypotheses and testing hypotheses, one can examine and improve the model to explain real- world phenomena. The empirical research method consists of using a survey-based questionnaire to collect the data to identify and interrelate variables present in the problem. It is a comparatively difficult task to design -

Coal Wholesale Lines World Report
Coal Wholesale Lines World Report established in 1974, and a brand since 1981. www.datagroup.org Coal Wholesale Lines World Report Database Ref: 4235201_L This database is updated monthly. Coal Wholesale Lines World Report COAL WHOLESALE LINES WORLD REPORT The Coal merchant wholesalers Lines Report has the following information. The base report has 59 chapters, plus the Excel spreadsheets & Access databases specified. This research provides World Data on Coal merchant wholesalers Product Lines. The report is available in several Editions and Parts and the contents and cost of each part is shown below. The Client can choose the Edition required; and subsequently any Parts that are required from the After- Sales Service. Contents Description ....................................................................................................................................... 5 REPORT EDITIONS ........................................................................................................................... 6 World Report ....................................................................................................................................... 6 Regional Report ................................................................................................................................... 6 Country Report .................................................................................................................................... 6 Town & Country Report ...................................................................................................................... -

A Comparative Analysis of Web Scraping Technologies
Using Internet as a Data Source for Official Statistics: a Comparative Analysis of Web Scraping Technologies Giulio Barcaroli1 ([email protected]), Monica Scannapieco1 ([email protected]), Donato Summa1 ([email protected]), Marco Scarnò2 (m.scarnò@cineca.it) Keywords: Big data, Web Scraping, Web data 1. INTRODUCTION The Internet can be considered as a data source (belonging to the vast category of Big Data), that may be harnessed in substitution, or in combination with, data collected by means of the traditional instruments of a statistical survey. The survey on “ICT in enterprises”, carried out by all EU Statistical Institutes, is a natural candidate to experiment this approach, as the questionnaire contains a number of questions, related to the characteristics of the websites owned or used by the enterprises, whose answers can be deduced directly by the content of these websites (for instance the presence of web sales functionalities). An experiment is being conducted whose aim is twofold: (i) from a technological point of view, to verify the capability to access the websites indicated by enterprises participating to the sampling survey, and collect all the relevant information, (ii) from a methodological point of view, to use the information collected from the Internet in order to predict the characteristics of the websites not only for surveyed enterprises, but for the whole population of reference, in order to produce estimates with a higher level of accuracy. The first phase of the experiment has been based on the use of the survey data, that is a sample of 19,000 respondent enterprises, that indicated a total of 8,600 websites. -

Payroll Service Lines World Report
Payroll Service Lines World Report established in 1974, and a brand since 1981. www.datagroup.org Payroll Service Lines World Report Database Ref: 541214_L This database is updated monthly. Payroll Service Lines World Report PAYROLL SERVICE LINES WORLD REPORT The Payroll services Lines Report has the following information. The base report has 59 chapters, plus the Excel spreadsheets & Access databases specified. This research provides World Data on Payroll services Product Lines. The report is available in several Editions and Parts and the contents and cost of each part is shown below. The Client can choose the Edition required; and subsequently any Parts that are required from the After-Sales Service. Contents Description ....................................................................................................................................... 5 REPORT EDITIONS ........................................................................................................................... 6 World Report ....................................................................................................................................... 6 Regional Report ................................................................................................................................... 6 Country Report .................................................................................................................................... 6 Town & Country Report ...................................................................................................................... -

Industrial Boilers & Pressure Vessels World Report
Industrial Boilers & Pressure Vessels World Report established in 1974, and a brand since 1981. www.datagroup.org Industrial Boilers & Pressure Vessels World Report Database Ref: M05014_M This database is updated monthly. Industrial Boilers & Pressure Vessels World Report INDUSTRIAL BOILERS WORLD REPORT The Industrial Boilers and Pressure Vessels Report has the following information. The base report has 59 chapters, plus the Excel spreadsheets & Access databases specified. This research provides World Data on Industrial Boilers and Pressure Vessels. The report is available in several Editions and Parts and the contents and cost of each part is shown below. The Client can choose the Edition required; and subsequently any Parts that are required from the After-Sales Service. Contents Description ....................................................................................................................................... 5 REPORT EDITIONS ........................................................................................................................... 6 World Report ....................................................................................................................................... 6 Regional Report ................................................................................................................................... 6 Country Report .................................................................................................................................... 6 Town & Country Report ...................................................................................................................... -
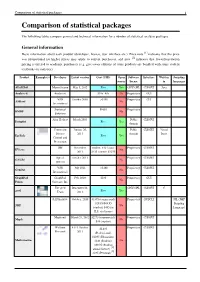
Comparison of Statistical Packages 1 Comparison of Statistical Packages
Comparison of statistical packages 1 Comparison of statistical packages The following tables compare general and technical information for a number of statistical analysis packages. General information Basic information about each product (developer, license, user interface etc.). Price note [1] indicates that the price was promotional (so higher prices may apply to current purchases), and note [2] indicates that lower/penetration pricing is offered to academic purchasers (e.g. give-away editions of some products are bundled with some student textbooks on statistics). Product Example(s) Developer Latest version Cost (USD) Open Software Interface Written Scripting source license in languages ADaMSoft Marco Scarno May 5, 2012 Free Yes GNU GPL CLI/GUI Java Analyse-it Analyse-it $185–495 No Proprietary GUI VSN October 2009 >$150 Proprietary CLI ASReml No International Statistical $1095 Proprietary BMDP No Solutions Alan Heckert March 2005 Public CLI/GUI Dataplot Free Yes domain Centers for January 26, Public CLI/GUI Visual Disease 2011 domain Basic Epi Info Free Yes Control and Prevention IHS November student: $40 / acad: Proprietary CLI/GUI EViews No 2011 $425 / comm: $1075 Aptech October 2011 Proprietary CLI/GUI GAUSS No systems VSN July 2011 >$190 Proprietary CLI/GUI GenStat No International GraphPad GraphPad Feb. 2009 $595 Proprietary GUI No Prism Software, Inc. The gretl December 22, GNU GPL CLI/GUI C gretl Team 2011 Free Yes SAS Institute October, 2010 $1895 (commercial) Proprietary GUI/CLI JSL (JMP $29.95/$49.95 Scripting JMP No (student) $495 for Language) H.S. site licence Maplesoft March 28, 2012 $2275 (commercial), Proprietary CLI/GUI Maple No $99 (student) Wolfram 8.0.4, October $2,495 Proprietary CLI/GUI Research 2011 (Professional), $1095 (Education), Mathematica $140 (Student), No $69.95 (Student [3] annual license) [4] $295 (Personal) Comparison of statistical packages 2 The New releases Depends on many Proprietary CLI/GUI Java MATLAB No MathWorks twice per year things. -

Using Data Analytics to Extract Knowledge from Middle-Of-Life Product Data
International Journal of Advanced Research and Publications ISSN: 2456-9992 Using Data Analytics To Extract Knowledge From Middle-Of-Life Product Data Fatima-Zahra Abou Eddahab, Imre Horváth Delft University of Technology, Industrial Design Engineering, Landbergstraat 15, 2628 CE Delft, Netherlands, [email protected] Delft University of Technology, Industrial Design Engineering, Landbergstraat 15, 2628 CE Delft, Netherlands, [email protected] Abstract: Data analytics needs dedicated tools, which are getting complex. In this paper we summarize the results of our literature research done with special attention to existing and potential future tools. The attention is paid mainly to processing big data, rather than to effective semantic processing of middle-of-life data (MoLD). The issue of handling of big MoLD of specific characteristics efficiently has not yet been addressed by the commercialized tools and methods. Another major limitation of the current tools is that they are typically not capable to adapt themselves to designers‟ needs and to support knowledge/experience reusability in multiple design tasks. MoLD require quasi-real life handling due to their nature and direct feedback relationships to the operation process and the environment of products. Nowadays products are equipped with smart capabilities. This offers new opportunities for exploiting MoLD. The knowledge aggregated in this study will be used in the development of a toolbox, which (i) integrates various tools under a unified interface, (ii) implements various smart and semantics orientated functions, and (iii) facilitates data transformations in contexts by the practicing designers themselves. Keywords: Data analytics, middle-of-life data, analytics tools, application practices, smart analytics toolbox. -

TAPPS Release 1: Plugin-Extensible Platform for Technical Analysis and Applied Statistics
ACSIJ Advances in Computer Science: an International Journal, Vol. 5, Issue 1, No.19 , January 2016 ISSN : 2322-5157 www.ACSIJ.org TAPPS Release 1: Plugin-Extensible Platform for Technical Analysis and Applied Statistics Justin Sam Chew Colossus Technologies LLP, Republic of Singapore [email protected] Maurice HT Ling Colossus Technologies LLP, Republic of Singapore School of BioSciences, The University of Melbourne Parkville, Victoria 3010, Australia [email protected] specific command language; of which, a popular example Abstract is SQL; is a shallower learning curve compared to a full We present the first release of TAPPS (Technical Analysis and programming language. Applied Statistics System); a Python implementation of a thin software platform aimed towards technical analyses and applied Here, we present TAPPS release 1 (abbreviation for statistics. The core of TAPPS is a container for 2-dimensional “Technical Analysis and Applied Statistics System”; data frame objects and a TAPPS command language. TAPPS hereafter, known as “TAPPS”) as a platform aimed language is not meant to be a programming language for script and plugin development but for the operational purposes. In this towards technical analyses and applied statistics. TAPPS aspect, TAPPS language takes on the flavor of SQL rather than is licensed under GNU General Public License version 3 R, resulting in a shallower learning curve. All analytical for academic and non-profit use. The main features of functions are implemented as plugins. This results in a defined TAPPS are (1) a thin platform with (2) a CLI-based, plugin system, which enables rapid development and domain-specific command language where (3) all incorporation of analysis functions. -

Wood Outdoor Furniture, Unpainted Wood Furniture & Ready-To
Wood Outdoor Furniture, Unpainted Wood Furniture & Ready-to-assemble Wood Furniture (B2B Procurement) Purchasing World Report Since 1979 www.datagroup.org Wood Outdoor Furniture, Unpainted Wood Furniture & Ready-to-assemble Wood Furniture (B2B Procurement) Wood Outdoor Furniture, Unpainted Wood Furniture & Ready-to-assemble Wood Furniture (B2B Procurement) 2 B B Purchasing World Report Wood Outdoor Furniture, Unpainted Wood Furniture & Ready-to-assemble Wood Furniture (B2B Procurement) The Purchasing World Report is an extract of the main database and provides a number of limited datasets for each of the countries covered. For users needing more information, detailed data on Wood Outdoor Furniture, Unpainted Wood Furniture & Ready-to-assemble Wood Furniture (B2B Procurement) is available in several Editions and Database versions. Users can order (at a discount) any other Editions, or the Database versions, as required from the After-Sales Service or from any Dealer. This research provides data the Buying of Materials, Products and Services used for Wood outdoor furniture, unpainted wood furniture & ready-to-assemble wood furniture. Contents B2B Purchasing World Report ................................................................................................................................... 2 B2B Purchasing World Report Specifications ............................................................................................................ 4 Materials, Products and Services Purchased : US$ ..........................................................................................