A Scalable Data Platform for a Large Number of Small Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A View-Based Approach to Relaxing Global Serializability in Multidatabase Systems
Purdue University Purdue e-Pubs Department of Computer Science Technical Reports Department of Computer Science 1993 A View-Based Approach to Relaxing Global Serializability in Multidatabase Systems Aidong Zhang Evaggelia Pitoura Bharat K. Bhargava Purdue University, [email protected] Report Number: 93-082 Zhang, Aidong; Pitoura, Evaggelia; and Bhargava, Bharat K., "A View-Based Approach to Relaxing Global Serializability in Multidatabase Systems" (1993). Department of Computer Science Technical Reports. Paper 1095. https://docs.lib.purdue.edu/cstech/1095 This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information. A VIEW-BASED APPROACH TO RELAXING GLOBAL SERIALIZABILITY IN MULTIDATABASE SYSTEMS Aldong Zhang Evaggelia PitOUI'3 Bharat Bh:Jrgava CSD TR-9J.082 December 1993 (Revised March 1994) A View-Based Approach to Relaxing Global Serializability in Multidatabase Systems Aidong Zhang, Evaggelia Pitoura, and Bharat K Bhargava Department of Computer Science Purdue University West Lafayette, IN 47907 USA Abstract In this paper, we propose a new approach to ensuring the correctness of non serializable executions. The approach is based on relating transaction views of the database to the integrity constraints of the system. Drawing upon this approach, we de velop a new correctness criterion for multidatabase concurrency control. This criterion, caUed view-based two-level serializability, relaxes global serializabitity in multidatabase systems while respecting the autonomy of local database systems. No additional re strictions other than serializallility are imposed on local database systems. 1 Introduction A Illultidataba.-<;e system (MDBS) is a higher-level confederation of a nWllber of pre-existing autonomolls and possibly heterogeneous database systems. -

Concurrency Control Basics
Outline l Introduction/problems, l definitions Introduction/ (transaction, history, conflict, equivalence, Problems serializability, ...), Definitions l locking. Chapter 2: Locking Concurrency Control Basics Klemens Böhm Distributed Data Management: Concurrency Control Basics – 1 Klemens Böhm Distributed Data Management: Concurrency Control Basics – 2 Atomicity, Isolation Synchronisation, Distributed (1) l Transactional guarantees – l Essential feature of databases: in particular, atomicity and isolation. Many users can access the same data concurrently – be it read, be it write. Introduction/ l Atomicity Introduction/ Problems Problems u Example, „bank scenario“: l Consistency must be guaranteed – Definitions Definitions task of synchronization component. Locking Number Person Balance Locking Klemens 5000 l Multi-user mode shall be hidden from users as far as possible: concurrent processing Gunter 200 of requests shall be transparent, u Money transfer – two elementary operations. ‚illusion‘ of being the only user. – debit(Klemens, 500), – credit(Gunter, 500). l Isolation – can be explained with this example, too. l Transactions. Klemens Böhm Distributed Data Management: Concurrency Control Basics – 3 Klemens Böhm Distributed Data Management: Concurrency Control Basics – 4 Synchronisation, Distributed (2) Synchronization in General l Serial execution of application programs Uncontrolled non-serial execution u achieves that illusion leads to other problems, notably inconsistency: l Introduction/ without any synchronization effort, Introduction/ -

Serializability, Not Serial: Concurrency Control and Availability in Multi-Datacenter Datastores
Serializability, not Serial: Concurrency Control and Availability in Multi-Datacenter Datastores Stacy Patterson1 Aaron J. Elmore2 Faisal Nawab2 Divyakant Agrawal2 Amr El Abbadi2 1Department of Electrical Engineering 2Department of Computer Science Technion - Israel Institute of Technology University of California, Santa Barbara Haifa, 32000, Israel Santa Barbara, CA 93106 [email protected] faelmore,nawab,agrawal,[email protected] ABSTRACT create applications within the eventual consistency model We present a framework for concurrency control and avail- [21]. Many cloud providers then introduced support for ability in multi-datacenter datastores. While we consider atomic access to individual data items, in essence, provid- Google's Megastore as our motivating example, we define ing strong consistency guarantees. This consistency level general abstractions for key components, making our solu- has become a standard feature that is offered in most cloud tion extensible to any system that satisfies the abstraction datastore implementations, including BigTable, SimpleDB, properties. We first develop and analyze a transaction man- and Apache HBase [17]. Strong consistency of single data agement and replication protocol based on a straightforward items is sufficient for many applications. However, if several implementation of the Paxos algorithm. Our investigation data items must be updated atomically, the burden to imple- reveals that this protocol acts as a concurrency prevention ment this atomic action in a scalable, fault tolerant manner mechanism rather than a concurrency control mechanism. lies with the software developer. Several recent works have We then propose an enhanced protocol called Paxos with addressed the problem of implementing ACID transactions Combination and Promotion (Paxos-CP) that provides true in cloud datastores [3, 11, 12], and, while full transaction transaction concurrency while requiring the same per in- support remains a scalability challenge, these works demon- stance message complexity as the basic Paxos protocol. -

A Study of the Availability and Serializability in a Distributed Database System
A STUDY OF THE AVAILABILITY AND SERIALIZABILITY IN A DISTRIBUTED DATABASE SYSTEM David Wai-Lok Cheung B.Sc., Chinese University of Hong Kong, 1971 M.Sc., Simon Fraser University, 1985 A THESIS SUBMI'ITED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHLLOSOPHY , in the School of Computing Science 0 David Wai-Lok Cheung 1988 SIMON FRASER UNIVERSITY January 1988 All rights reserved. This thesis may not be reproduced in whole or in part, by photocopy or other means, without permission of the author. 1 APPROVAL Name: David Wai-Lok Cheung Degree: Doctor of Philosophy Title of Thesis: A Study of the Availability and Serializability in a Distributed Database System Examining Committee: Chairperson: Dr. Binay Bhattacharya Senior Supervisor: Dr. TikoJameda WJ ru p v Dr. Arthur Lee Liestman Dr. Wo-Shun Luk Dr. Jia-Wei Han External Examiner: Toshihide Ibaraki Department of Applied Mathematics and Physics Kyoto University, Japan Bate Approved: January 15, 1988 PARTIAL COPYRIGHT LICENSE I hereby grant to Simon Fraser University the right to lend my thesis, project or extended essay (the title of which is shown below) to users of the Simon Fraser University Library, and to make partial or single copies only for such users or in response to a request from the library of any other university, or other educational institution, on its own behalf or for one of its users. I further agree that permission for multiple copying of this work for scholarly purposes may be granted by me or the Dean of Graduate Studies. It is understood that copying or publication of this work for financial gain shall not be allowed without my written permission, T it l e of Thes i s/Project/Extended Essay Author: (signature) ( name (date) ABSTRACT Replication of data objects enhances the reliability and availability of a distributed database system. -

A Theory of Global Concurrency Control in Multidatabase Systems
VLDB Journal,2, 331-360 (1993), Michael Carey and Patrick Valduriez, Editors 331 t~)VLDB A Theory of Global Concurrency Control in Multidatabase Systems Aidong Zhang and Ahmed K. Elmagarmid Received December 1, 1992; revised version received February 1, 1992; accepted March 15, 1993. Abstract. This article presents a theoretical basis for global concurrency control to maintain global serializability in multidatabase systems. Three correctness criteria are formulated that utilize the intrinsic characteristics of global transactions to de- termine the serialization order of global subtransactions at each local site. In par- ticular, two new types of serializability, chain-conflicting serializability and shar- ing serializability, are proposed and hybrid serializability, which combines these two basic criteria, is discussed. These criteria offer the advantage of imposing no restrictions on local sites other than local serializability while retaining global se- rializability. The graph testing techniques of the three criteria are provided as guidance for global transaction scheduling. In addition, an optimal property of global transactions for determinating the serialization order of global subtransac- tions at local sites is formulated. This property defines the upper limit on global serializability in multidatabase systems. Key Words. Chain-conflicting serializability, sharing serializability, hybrid serial- izability, optimality. 1. Introduction Centralized databases were predominant during the 1970s, a period which saw the development of diverse database systems based on relational, hierarchical, and network models. The advent of applications involving increased cooperation between systems necessitated the development of methods for integrating these pre-existing database systems. The design of such global database systems must allow unified access to these diverse database systems without subjecting them to conversion or major modifications. -

Models of Transactions Structuring Applications Flat Transaction Flat
Structuring Applications • Many applications involve long transactions Models of Transactions that make many database accesses • To deal with such complex applications many transaction processing systems Chapter 19 provide mechanisms for imposing some structure on transactions 2 Flat Transaction Flat Transaction • Consists of: begin transaction – Computation on local variables • Abort causes the begin transaction • not seen by DBMS; hence will be ignored in most future discussion execution of a program ¡£ ¤¦©¨ – Access to DBMS using call or ¢¡£ ¥¤§¦©¨ that restores the statement level interface variables updated by the ¡£ ¤¦©¨ • This is transaction schedule; commit ….. applies to these operations ¢¡£ ¤§¦©¨ ….. transaction to the state • No internal structure they had when the if condition then abort • Accesses a single DBMS transaction first accessed commit commit • Adequate for simple applications them. 3 4 Some Limitations of Flat Transactions • Only total rollback (abort) is possible – Partial rollback not possible Providing Structure Within a • All work lost in case of crash Single Transaction • Limited to accessing a single DBMS • Entire transaction takes place at a single point in time 5 6 1 Savepoints begin transaction S1; Savepoints Call to DBMS sp1 := create_savepoint(); S2; sp2 := create_savepoint(); • Problem: Transaction detects condition that S3; requires rollback of recent database changes if (condition) {rollback (sp1); S5}; S4; that it has made commit • Solution 1: Transaction reverses changes • Rollback to spi causes -

CS848 - Cloud Data Management
Cloud Transactions Failures Partitioning Replication CAP Views CS848 - Cloud Data Management Introduction and Background Ken Salem David R. Cheriton School of Computer Science University of Waterloo Winter 2010 • Adjectives associated with clouds • scalable • highly-available • pay-as-you-go • on demand • Not much point in trying to pin down what is cloud and what is not. Cloud Transactions Failures Partitioning Replication CAP Views What is cloud computing? • It seems that everybody who is offering an internet service or using a cluster wants to label themselves “cloud” • Not much point in trying to pin down what is cloud and what is not. Cloud Transactions Failures Partitioning Replication CAP Views What is cloud computing? • It seems that everybody who is offering an internet service or using a cluster wants to label themselves “cloud” • Adjectives associated with clouds • scalable • highly-available • pay-as-you-go • on demand Cloud Transactions Failures Partitioning Replication CAP Views What is cloud computing? • It seems that everybody who is offering an internet service or using a cluster wants to label themselves “cloud” • Adjectives associated with clouds • scalable • highly-available • pay-as-you-go • on demand • Not much point in trying to pin down what is cloud and what is not. Cloud Transactions Failures Partitioning Replication CAP Views Services Spectrum less flexible more flexible more constrained less constrained less effort more effort Cloud Transactions Failures Partitioning Replication CAP Views Services Spectrum less -

Life Beyond Distributed Transactions: an Apostate's Opinion
Life beyond Distributed Transactions: an Apostate’s Opinion Position Paper Pat Helland Amazon.Com 705 Fifth Ave South Seattle, WA 98104 USA [email protected] The positions expressed in this paper are Instead, applications are built using different personal opinions and do not in any way reflect techniques which do not provide the same the positions of my employer Amazon.com. transactional guarantees but still meet the needs of their businesses. ABSTRACT This paper explores and names some of the practical approaches used in the implementations Many decades of work have been invested in the of large-scale mission-critical applications in a area of distributed transactions including world which rejects distributed transactions. We protocols such as 2PC, Paxos, and various discuss the management of fine-grained pieces of approaches to quorum. These protocols provide application data which may be repartitioned over the application programmer a façade of global time as the application grows. We also discuss serializability. Personally, I have invested a non- the design patterns used in sending messages trivial portion of my career as a strong advocate between these repartitionable pieces of data. for the implementation and use of platforms The reason for starting this discussion is to raise providing guarantees of global serializability. awareness of new patterns for two reasons. First, My experience over the last decade has led me to it is my belief that this awareness can ease the 1 liken these platforms to the Maginot Line . In challenges of people hand-crafting very large general, application developers simply do not scalable applications. Second, by observing the implement large scalable applications assuming patterns, hopefully the industry can work distributed transactions. -

A Theory of Global Concurrency Control in Multidatabase Systems
Purdue University Purdue e-Pubs Department of Computer Science Technical Reports Department of Computer Science 1992 A Theory of Global Concurrency Control in Multidatabase Systems Aidong Zhang Ahmed K. Elmagarmid Purdue University, [email protected] Report Number: 92-098 Zhang, Aidong and Elmagarmid, Ahmed K., "A Theory of Global Concurrency Control in Multidatabase Systems" (1992). Department of Computer Science Technical Reports. Paper 1017. https://docs.lib.purdue.edu/cstech/1017 This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information. A THEORY OF GLOBAL CONCURRENCY CONTROL IN MULTIDATABASE SYSTEMS Aidong Zhang Ahmed K. Elmagarmid CSD·TR-92-098 December 1992 A Theory of Global Concurrency Control in Multidatabase Systems • Aidong Zhang and Ahmed K. Elmagarmid Department of Computer Science Purdue University West Lafayette, IN 47907 USA {azhang,ake}@cs.purdue.edu Abstract This paper presents a theoretical basis for global concurrency control to maintain global serializability in multidatabase systems. Three correctness criteria are formulated to utilize the intrinsic characteristics of global transactions at the global level to determine the serialization order of global subtransactions at each local site. In particular, two new types of serializabiIity, chain-conflicting serializability and sharing serializability, are proposed, and an optimal criterion (termed hybrid serializability) combining these two basic criteria is discussed. These criteria offer the advantage of imposing no restrictions on local sites other than local serializability while retaining global serializability. The graph testing techniques of the three criteria are provided as guidance for global transaction scheduling. In addition, the optimal aspect of hybrid serializability defines the upper limit on global serializability in multidatabase systems. -

Transaction Properties(ACID Properties)
UNIT-5 Transaction properties(ACID properties) In computer science, ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably. In the context ofdatabases, a single logical operation on the data is called a transaction. For example, a transfer of funds from one bank account to another, even involving multiple changes such as debiting one account and crediting another, is a single transaction. Jim Gray defined these properties of a reliable transaction system in the late 1970s and developed technologies to achieve them automatically. In 1983, Andreas Reuter and Theo Härder coined the acronym ACID to describe them. The characteristics of these four properties as defined by Reuter and Härder: Atomicity Atomicity requires that each transaction be "all or nothing": if one part of the transaction fails, the entire transaction fails, and the database state is left unchanged. An atomic system must guarantee atomicity in each and every situation, including power failures, errors, and crashes. To the outside world, a committed transaction appears (by its effects on the database) to be indivisible ("atomic"), and an aborted transaction does not happen. Consistency The consistency property ensures that any transaction will bring the database from one valid state to another. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof. This does not guarantee correctness of the transaction in all ways the application programmer might have wanted (that is the responsibility of application-level code) but merely that any programming errors cannot result in the violation of any defined rules. -
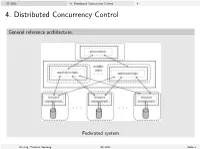
4. Distributed Concurrency Control 4
SS 2013 4. Distributed Concurrency Control 4. 4. Distributed Concurrency Control General reference architecture. Federated system Dr.-Ing. Thomas Hornung SS 2013 Seite 1 SS 2013 4. Distributed Concurrency Control 4.1. Preliminaries 4.1: Preliminaries Sites and subtransactions I Let be given a fixed number of sites across which the data is distributed. The server at site i, 1 ≤ i ≤ n is responsible for a (finite) set Di of data items. The n corresponding global database is given as D = [i=1Di . I Data items are not replicated; thus Di \ Dj = ;, i 6= j. I Let T = fT1;:::; Tmg be a set of transactions, where Ti = (OPi ; <i ), 1 ≤ i ≤ m. I Transaction Ti is called global, if its actions are running at more than one server; otherwise it is called local. I The part of a transaction Ti being executed at a certain site j is called subtransaction and is denoted by Tij . Dr.-Ing. Thomas Hornung SS 2013 Seite 2 SS 2013 4. Distributed Concurrency Control 4.1. Preliminaries Local and global schedules We are interested in deciding whether or not the execution of a set of transactions is serializable, or not. I At the local sites we can observe an evolving sequence of the respective transactions' actions. I We would like to decide whether or not all these locally observable sequences imply a (globally) serializable schedule. I However, on the global level we cannot observe an evolving sequence, as there does not exist a notion of global physical time. Dr.-Ing. Thomas Hornung SS 2013 Seite 3 SS 2013 4. -

Chapter 24: Advanced Transaction Processing
ChapterChapter 24:24: AdvancedAdvanced TransactionTransaction ProcessingProcessing ! Transaction-Processing Monitors ! Transactional Workflows ! High-Performance Transaction Systems ! Main memory databases ! Real-Time Transaction Systems ! Long-Duration Transactions ! Transaction management in multidatabase systems 1 Database System Concepts 24.1 ©Silberschatz, Korth and Sudarshan TransactionTransaction ProcessingProcessing MonitorsMonitors ! TP monitors initially developed as multithreaded servers to support large numbers of terminals from a single process. ! Provide infrastructure for building and administering complex transaction processing systems with a large number of clients and multiple servers. ! Provide services such as: ! Presentation facilities to simplify creating user interfaces ! Persistent queuing of client requests and server responses ! Routing of client messages to servers ! Coordination of two-phase commit when transactions access multiple servers. ! Some commercial TP monitors: CICS from IBM, Pathway from Tandem, Top End from NCR, and Encina from Transarc 2 Database System Concepts 24.2 ©Silberschatz, Korth and Sudarshan TPTP MonitorMonitor ArchitecturesArchitectures 3 Database System Concepts 24.3 ©Silberschatz, Korth and Sudarshan TPTP MonitorMonitor ArchitecturesArchitectures (Cont.)(Cont.) ! Process per client model - instead of individual login session per terminal, server process communicates with the terminal, handles authentication, and executes actions. ! Memory requirements are high ! Multitasking- high