Using Prerequisites to Extract Concept Maps from Textbooks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
TMS Xdata Documentation
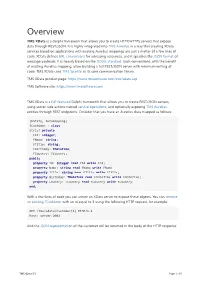
Overview TMS XData is a Delphi framework that allows you to create HTTP/HTTPS servers that expose data through REST/JSON. It is highly integrated into TMS Aurelius in a way that creating XData services based on applications with existing Aurelius mappings are just a matter of a few lines of code. XData defines URL conventions for adressing resources, and it specifies the JSON format of message payloads. It is heavily based on the OData standard. Such conventions, with the benefit of existing Aurelius mapping, allow building a full REST/JSON server with minimum writing of code. TMS XData uses TMS Sparkle as its core communication library. TMS XData product page: https://www.tmssoftware.com/site/xdata.asp TMS Software site: https://www.tmssoftware.com TMS XData is a full-featured Delphi framework that allows you to create REST/JSON servers, using server-side actions named service operations, and optionally exposing TMS Aurelius entities through REST endpoints. Consider that you have an Aurelius class mapped as follows: [Entity, Automapping] TCustomer = class strict private FId: integer; FName: string; FTitle: string; FBirthday: TDateTime; FCountry: TCountry; public property Id: Integer read FId write FId; property Name: string read FName write FName; property Title: string read FTitle write FTitle; property Birthday: TDateTime read FDateTime write FDateTime; property Country: TCountry read FCountry write FCountry; end; With a few lines of code you can create an XData server to expose these objects. You can retrieve an existing TCustomer -

TR-069 CPE WAN Management Protocol V1.1
TECHNICAL REPORT TR-069 CPE WAN Management Protocol v1.1 Version: Issue 1 Amendment 2 Version Date: December 2007 © 2007 The Broadband Forum. All rights reserved. CPE WAN Management Protocol v1.1 TR-069 Issue 1 Amendment 2 Notice The Broadband Forum is a non-profit corporation organized to create guidelines for broadband network system development and deployment. This Technical Report has been approved by members of the Forum. This document is not binding on the Broadband Forum, any of its members, or any developer or service provider. This document is subject to change, but only with approval of members of the Forum. This document is provided "as is," with all faults. Any person holding a copyright in this document, or any portion thereof, disclaims to the fullest extent permitted by law any representation or warranty, express or implied, including, but not limited to, (a) any warranty of merchantability, fitness for a particular purpose, non-infringement, or title; (b) any warranty that the contents of the document are suitable for any purpose, even if that purpose is known to the copyright holder; (c) any warranty that the implementation of the contents of the documentation will not infringe any third party patents, copyrights, trademarks or other rights. This publication may incorporate intellectual property. The Broadband Forum encourages but does not require declaration of such intellectual property. For a list of declarations made by Broadband Forum member companies, please see www.broadband-forum.org. December 2007 © The Broadband -

Version Indication & Negotiation
SIF Infrastructure Specification 3.3: Version Indication & Negotiation www.A4L.org Version 3.3, May 2019 SIF Infrastructure Specification 3.3: Version Indication & Negotiation Version 3.3, May 2019 Preface ...................................................................................................................................... 4 Disclaimer ................................................................................................................................. 4 Permission and Copyright ....................................................................................................... 5 Document Conventions ........................................................................................................... 5 Terms and Abbreviations .......................................................................................................... 5 Notations ..................................................................................................................................... 6 1. Context ............................................................................................................................... 7 2. Problem Statement ........................................................................................................... 8 3. Method ................................................................................................................................ 9 3.1 Schema Identification ....................................................................................................... -

HTTP Working Group M. Nottingham Internet-Draft Akamai Intended Status: Standards Track P
HTTP Working Group M. Nottingham Internet-Draft Akamai Intended status: Standards Track P. McManus Expires: September 9, 2016 Mozilla J. Reschke greenbytes March 8, 2016 HTTP Alternative Services draft-ietf-httpbis-alt-svc-14 Abstract This document specifies "Alternative Services" for HTTP, which allow an origin’s resources to be authoritatively available at a separate network location, possibly accessed with a different protocol configuration. Editorial Note (To be removed by RFC Editor) Discussion of this draft takes place on the HTTPBIS working group mailing list ([email protected]), which is archived at <https://lists.w3.org/Archives/Public/ietf-http-wg/>. Working Group information can be found at <http://httpwg.github.io/>; source code and issues list for this draft can be found at <https://github.com/httpwg/http-extensions>. The changes in this draft are summarized in Appendix A. Status of This Memo This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79. Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/. Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress." This Internet-Draft will expire on September 9, 2016. Nottingham, et al. Expires September 9, 2016 [Page 1] Internet-Draft HTTP Alternative Services March 2016 Copyright Notice Copyright (c) 2016 IETF Trust and the persons identified as the document authors. -

3 Protocol Mappings
Standards Track Work Product Specification for Transfer of OpenC2 Messages via HTTPS Version 1.0 Committee Specification 01 11 July 2019 This version: https://docs.oasis-open.org/openc2/open-impl-https/v1.0/cs01/open-impl-https-v1.0-cs01.md (Authoritative) https://docs.oasis-open.org/openc2/open-impl-https/v1.0/cs01/open-impl-https-v1.0-cs01.html https://docs.oasis-open.org/openc2/open-impl-https/v1.0/cs01/open-impl-https-v1.0-cs01.pdf Previous version: https://docs.oasis-open.org/openc2/open-impl-https/v1.0/csprd02/open-impl-https-v1.0- csprd02.md (Authoritative) https://docs.oasis-open.org/openc2/open-impl-https/v1.0/csprd02/open-impl-https-v1.0- csprd02.html https://docs.oasis-open.org/openc2/open-impl-https/v1.0/csprd02/open-impl-https-v1.0- csprd02.pdf Latest version: https://docs.oasis-open.org/openc2/open-impl-https/v1.0/open-impl-https-v1.0.md (Authoritative) https://docs.oasis-open.org/openc2/open-impl-https/v1.0/open-impl-https-v1.0.html https://docs.oasis-open.org/openc2/open-impl-https/v1.0/open-impl-https-v1.0.pdf Technical Committee: OASIS Open Command and Control (OpenC2) TC Chairs: Joe Brule ([email protected]), National Security Agency Duncan Sparrell ([email protected]), sFractal Consulting LLC Editor: open-impl-https-v1.0-cs01 Copyright © OASIS Open 2019. All Rights Reserved. 11 July 2019 - Page 1 of 29 Standards Track Work Product David Lemire ([email protected]), G2, Inc. Related work: This specification is related to: Open Command and Control (OpenC2) Language Specification Version 1.0. -

The OWASP Foundation Tweaking to Get Away from Slowdos
Tweaking to get away from SlowDOS Tweaking to get away from SlowDOS Sergey Shekyan, Senior Software Engineer June 2nd, 2012 OWASP Kansas City June 21st, 2012 Copyright 2012 © The OWASP Foundation Permission is granted to copy, distribute and/or modify this document under the terms of the OWASP License. The OWASP Foundation http://www.owasp.org Sunday, June 24, 12 1 Denial of Service Attacks OWASP 2 Sunday, June 24, 12 2 Types of attack There is a variety of forms aiming at a variety of services: Traffic consuming attacks (DNS, firewall, router, load balancer, OS, etc.) Application Layer attacks (web server, media server, mail server) OWASP 3 Sunday, June 24, 12 3 What is low-bandwidth attack? Slowloris GET Flood 400 300 Mbps/sec 200 100 0 0 10 20 30 40 Seconds OWASP 4 Sunday, June 24, 12 4 Network Layer attacks OWASP 5 Sunday, June 24, 12 5 Application Layer attacks OWASP 6 Sunday, June 24, 12 6 DDoS economics DDoS attacks are affordable (from $5/hour) DDoS attack is a great way to promote your start-up (attacks on Russian travel agencies are 5 times as frequent in high season) Longest attack detected by Kaspersky DDos Prevention System in the second half of 2011 targeted a travel agency website and lasted 80 days 19 hours 13 minutes 05 seconds Akamai reports DDoS attack incidents soar 2,000 percent in the past three years OWASP 7 Sunday, June 24, 12 7 Screenshot of a “company” offering DDoS services OWASP 8 Sunday, June 24, 12 8 Marketing HTTP Flood, UDP flood, SYN flood On-demand modules (for example, e-mail flooder) Multiple targets Pay from any ATM Money back guarantee OWASP 9 Sunday, June 24, 12 9 Application Layer DoS attacks Slow HTTP headers attack (a.k.a. -

Meter Reading Web Services Data Exchange Specification
Meter Reading Web Services Data Exchange Specification Version 2.0 2017 ISO New England Inc. ISO-NE PUBLIC Change Summary Revision Date Comments Version 1.0 June 2016 Initial release Version 2.0 November 2017 Changes for PFP/PRD Version 3.0 July 2020 Changes for FRM/Upgrade ISO-NE PUBLIC About this document The Meter Reading Web Services Data Exchange Specification document describes the REST messages and the Authentication and Authorization process used to exchange meter reading data between a Meter Reader and the Meter Reading application through web services. It also describes the upload and download files used to exchange meter reading data through a Meter Reader’s web browser and the “Submit Meter Reading” user interface provided by the SMD Site for ISO Applications. The user interface upload/download files and the web service REST messages share the same data format. This document explains how to access the Meter Reading web services, lays out the format and construction of REST messages used to exchange data, and briefly describes the Authentication and Authorization methods used to ensure security. This guide is designed to assist Meter Readers develop personal interfaces that interact and exchange meter reading data with the Meter Reading web services. It will help Meter Readers comprehend and construct the meter reading data messages essential for data exchange with the Meter Reading application. It can also help Meter Readers develop software that generates upload files for use with the Meter Reading user interface, or software that parses download files obtained from the Meter Reading user interface. Scope and prerequisite knowledge This document is offered to ISO New England Meter Readers as an aid in developing new interfaces as well as assisting in the upgrade/re-design of existing interfaces. -

Biotechniques Author Guidelines
Version: 04/03/2020 BioTechniques Author Guidelines This document outlines how to prepare articles for submission. We recommend you read these guidelines in full before submitting your article or making an article proposal. Table of Contents Journal aims & scope .............................................................................................................................. 3 Audience ................................................................................................................................................. 3 At-a-glance article formatting checklist .................................................................................................. 4 Search engine optimization .................................................................................................................... 5 Article types ............................................................................................................................................ 6 Benchmarks, Reports and Letters to the Editor .................................................................................. 6 Reviews & Practical Guides ................................................................................................................. 8 Interviews............................................................................................................................................ 9 Expert Opinions ................................................................................................................................ -

IHE IT Infrastructure Technical Framework Supplement Mobile
Integrating the Healthcare Enterprise 5 IHE IT Infrastructure Technical Framework Supplement 10 Mobile access to Health Documents (MHD) ® 15 FHIR DSTU2 Trial Implementation 20 Date: June 2, 2016 Author: IHE ITI Technical Committee Email: [email protected] 25 Please verify you have the most recent version of this document. See here for Trial Implementation and Final Text versions and here for Public Comment versions. Copyright © 2016: IHE International, Inc. IHE IT Infrastructure Technical Framework Supplement – Mobile access to Health Documents (MHD) ______________________________________________________________________________ Foreword This is a supplement to the IHE IT Infrastructure Technical Framework V12.0. Each supplement 30 undergoes a process of public comment and trial implementation before being incorporated into the volumes of the Technical Frameworks. This supplement is published on June 2, 2016 for trial implementation and may be available for testing at subsequent IHE Connectathons. The supplement may be amended based on the results of testing. Following successful testing it will be incorporated into the IT Infrastructure 35 Technical Framework. Comments are invited and may be submitted at http://www.ihe.net/ITI_Public_Comments. This supplement describes changes to the existing technical framework documents. “Boxed” instructions like the sample below indicate to the Volume Editor how to integrate the relevant section(s) into the relevant Technical Framework volume. 40 Amend Section X.X by the following: Where the amendment adds text, make the added text bold underline. Where the amendment removes text, make the removed text bold strikethrough. When entire new sections are added, introduce with editor’s instructions to “add new text” or similar, which for readability are not bolded or underlined. -

Web Services Description Language (WSDL) Version 2.0 Part 0: Primer W3C Candidate Recommendation 6 January 2006
Table of Contents Web Services Description Language (WSDL) Version 2.0 Part 0: Primer W3C Candidate Recommendation 6 January 2006 This version: http://www.w3.org/TR/2006/CR-wsdl20-primer-20060106 Latest version: http://www.w3.org/TR/wsdl20-primer Previous versions: http://www.w3.org/TR/2005/WD-wsdl20-primer-20050803 Editors: David Booth, W3C Fellow / Hewlett-Packard Canyang Kevin Liu, SAP Labs This document is also available in these non-normative formats: PDF, PostScript, XML, and plain text. Copyright © 2006 World Wide Web ConsortiumW3C ® (Massachusetts Institute of TechnologyMIT, European Research Consortium for Informatics and MathematicsERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. Abstract This document is a companion to the WSDL 2.0 specification (Web Services Description Language (WSDL) Version 2.0 Part 1: Core Language [WSDL 2.0 Core [p.83] ], Web Services Description Language (WSDL) Version 2.0 Part 2: Adjuncts [WSDL 2.0 Adjuncts [p.83] ]). It is intended for readers who wish to have an easier, less technical introduction to the main features of the language. This primer is only intended to be a starting point toward use of WSDL 2.0, and hence does not describe every feature of the language. Users are expected to consult the WSDL 2.0 specification if they wish to make use of more sophisticated features or techniques. Finally, this primer is non-normative. Any specific questions of what WSDL 2.0 requires or forbids should be referred to the WSDL 2.0 specification. 1 Status of this Document Status of this Document This section describes the status of this document at the time of its publication. -

HTTP Protocol Binding
ONEM2M TECHNICAL SPECIFICATION Document Number TS-0009-V2.6.1 Document Name: HTTP Protocol Binding Date: 2016-August-30 Abstract: HTTP Protocol Binding TS This Specification is provided for future development work within oneM2M only. The Partners accept no liability for any use of this Specification. The present document has not been subject to any approval process by the oneM2M Partners Type 1. Published oneM2M specifications and reports for implementation should be obtained via the oneM2M Partners' Publications Offices. © oneM2M Partners Type 1 (ARIB, ATIS, CCSA, ETSI, TIA, TSDSI, TTA, TTC) Page 1 of 20 This is a draft oneM2M document and should not be relied upon; the final version, if any, will be made available by oneM2M Partners Type 1. About oneM2M The purpose and goal of oneM2M is to develop technical specifications which address the need for a common M2M Service Layer that can be readily embedded within various hardware and software, and relied upon to connect the myriad of devices in the field with M2M application servers worldwide. More information about oneM2M may be found at: http//www.oneM2M.org Copyright Notification No part of this document may be reproduced, in an electronic retrieval system or otherwise, except as authorized by written permission. The copyright and the foregoing restriction extend to reproduction in all media. © 2016, oneM2M Partners Type 1 (ARIB, ATIS, CCSA, ETSI, TIA, TSDSI, TTA, TTC). All rights reserved. Notice of Disclaimer & Limitation of Liability The information provided in this document is directed solely to professionals who have the appropriate degree of experience to understand and interpret its contents in accordance with generally accepted engineering or other professional standards and applicable regulations. -

An Open Source Javascript Library for Health Data Visualization Andres Ledesma* , Mohammed Al-Musawi and Hannu Nieminen
Ledesma et al. BMC Medical Informatics and Decision Making (2016) 16:38 DOI 10.1186/s12911-016-0275-6 SOFTWARE Open Access Health figures: an open source JavaScript library for health data visualization Andres Ledesma* , Mohammed Al-Musawi and Hannu Nieminen Abstract Background: The way we look at data has a great impact on how we can understand it, particularly when the data is related to health and wellness. Due to the increased use of self-tracking devices and the ongoing shift towards preventive medicine, better understanding of our health data is an important part of improving the general welfare of the citizens. Electronic Health Records, self-tracking devices and mobile applications provide a rich variety of data but it often becomes difficult to understand. We implemented the hFigures library inspired on the hGraph visualization with additional improvements. The purpose of the library is to provide a visual representation of the evolution of health measurements in a complete and useful manner. Results: We researched the usefulness and usability of the library by building an application for health data visualization in a health coaching program. We performed a user evaluation with Heuristic Evaluation, Controlled User Testing and Usability Questionnaires. In the Heuristics Evaluation the average response was 6.3 out of 7 points and the Cognitive Walkthrough done by usability experts indicated no design or mismatch errors. In the CSUQ usability test the system obtained an average score of 6.13 out of 7, and in the ASQ usability test the overall satisfaction score was 6.64 out of 7. Conclusions: We developed hFigures, an open source library for visualizing a complete, accurate and normalized graphical representation of health data.