The ICER Progressive Wavelet Image Compressor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PDF/A for Scanned Documents
Webinar www.pdfa.org PDF/A for Scanned Documents Paper Becomes Digital Mark McKinney, LuraTech, Inc., President Armin Ortmann, LuraTech, CTO Mark McKinney President, LuraTech, Inc. © 2009 PDF/A Competence Center, www.pdfa.org Existing Solutions for Scanned Documents www.pdfa.org Black & White: TIFF G4 Color: Mostly JPEG, but sometimes PNG, BMP and other raster graphics formats Often special version formats like “JPEG in TIFF” Disadvantages: Several formats already for scanned documents Even more formats for born digital documents Loss of information, e.g. with TIFF G4 Bad image quality and huge file size, e.g. with JPEG No standardized metadata spread over all formats Not full text searchable (OCR) inside of files Black/White: Color: - TIFF FAX G4 - TIFF - TIFF LZW Mark McKinney - JPEG President, LuraTech, Inc. - PDF 2 Existing Solutions for Scanned Documents www.pdfa.org Bad image quality vs. file size TIFF/BMP JPEG TIFF G4 23.8 MB 180 kB 60 kB Mark McKinney President, LuraTech, Inc. 3 Alternative Solution: PDF www.pdfa.org PDF is already widely used to: Unify file formats Image à PDF “Office” Documents à PDF Other sources à PDF Create full-text searchable files Apply modern compression technology (e.g. the JPEG2000 file formats family) Harmonize metadata Conclusion: PDF avoids the disadvantages of the legacy formats “So if you are already using PDF as archival Mark McKinney format, why not use PDF/A with its many President, LuraTech, Inc. advantages?” 4 PDF/A www.pdfa.org What is PDF/A? • ISO 19005-1, Document Management • Electronic document file format for long-term preservation Goals of PDF/A: • Maintain static visual representation of documents • Consistent handing of Metadata • Option to maintain structure and semantic meaning of content • Transparency to guarantee access • Limit the number of restrictions Mark McKinney President, LuraTech, Inc. -

Chapter 9 Image Compression Standards
Fundamentals of Multimedia, Chapter 9 Chapter 9 Image Compression Standards 9.1 The JPEG Standard 9.2 The JPEG2000 Standard 9.3 The JPEG-LS Standard 9.4 Bi-level Image Compression Standards 9.5 Further Exploration 1 Li & Drew c Prentice Hall 2003 ! Fundamentals of Multimedia, Chapter 9 9.1 The JPEG Standard JPEG is an image compression standard that was developed • by the “Joint Photographic Experts Group”. JPEG was for- mally accepted as an international standard in 1992. JPEG is a lossy image compression method. It employs a • transform coding method using the DCT (Discrete Cosine Transform). An image is a function of i and j (or conventionally x and y) • in the spatial domain. The 2D DCT is used as one step in JPEG in order to yield a frequency response which is a function F (u, v) in the spatial frequency domain, indexed by two integers u and v. 2 Li & Drew c Prentice Hall 2003 ! Fundamentals of Multimedia, Chapter 9 Observations for JPEG Image Compression The effectiveness of the DCT transform coding method in • JPEG relies on 3 major observations: Observation 1: Useful image contents change relatively slowly across the image, i.e., it is unusual for intensity values to vary widely several times in a small area, for example, within an 8 8 × image block. much of the information in an image is repeated, hence “spa- • tial redundancy”. 3 Li & Drew c Prentice Hall 2003 ! Fundamentals of Multimedia, Chapter 9 Observations for JPEG Image Compression (cont’d) Observation 2: Psychophysical experiments suggest that hu- mans are much less likely to notice the loss of very high spatial frequency components than the loss of lower frequency compo- nents. -

Electronics Engineering
INTERNATIONAL JOURNAL OF ELECTRONICS ENGINEERING ISSN : 0973-7383 Volume 11 • Number 1 • 2019 Study of Different Image File formats for Raster images Prof. S. S. Thakare1, Prof. Dr. S. N. Kale2 1Assistant professor, GCOEA, Amravati, India, [email protected] 2Assistant professor, SGBAU,Amaravti,India, [email protected] Abstract: In the current digital world, the usage of images are very high. The development of multimedia and digital imaging requires very large disk space for storage and very long bandwidth of network for transmission. As these two are relatively expensive, Image compression is required to represent a digital image yielding compact representation of image without affecting its essential information with reducing transmission time. This paper attempts compression in some of the image representation formats and the experimental results for some image file format are also shown. Keywords: ImageFileFormats, JPEG, PNG, TIFF, BITMAP, GIF,CompressionTechniques,Compressed image processing. 1. INTRODUCTION Digital images generally occupy a large amount of storage space and therefore take longer time to transmit and download (Sayood 2012;Salomonetal 2010;Miano 1999). To reduce this time image compression is necessary. Image compression is a technique used to identify internal data redundancy and then develop a compact representation that takes up less storage space than the original image size and the reverse process is called decompression (Javed 2016; Kia 1997). There are two types of image compression (Gonzalez and Woods 2009). 1. Lossy image compression 2. Lossless image compression In case of lossy compression techniques, it removes some part of data, so it is used when a perfect consistency with the original data is not necessary after decompression. -

Design and Implementation of Image Processing and Compression Algorithms for a Miniature Embedded Eye Tracking System Pavel Morozkin
Design and implementation of image processing and compression algorithms for a miniature embedded eye tracking system Pavel Morozkin To cite this version: Pavel Morozkin. Design and implementation of image processing and compression algorithms for a miniature embedded eye tracking system. Signal and Image processing. Sorbonne Université, 2018. English. NNT : 2018SORUS435. tel-02953072 HAL Id: tel-02953072 https://tel.archives-ouvertes.fr/tel-02953072 Submitted on 29 Sep 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Sorbonne Université Institut supérieur d’électronique de Paris (ISEP) École doctorale : « Informatique, télécommunications & électronique de Paris » Design and Implementation of Image Processing and Compression Algorithms for a Miniature Embedded Eye Tracking System Par Pavel MOROZKIN Thèse de doctorat de Traitement du signal et de l’image Présentée et soutenue publiquement le 29 juin 2018 Devant le jury composé de : M. Ales PROCHAZKA Rapporteur M. François-Xavier COUDOUX Rapporteur M. Basarab MATEI Examinateur M. Habib MEHREZ Examinateur Mme Maria TROCAN Directrice de thèse M. Marc Winoc SWYNGHEDAUW Encadrant Abstract Human-Machine Interaction (HMI) progressively becomes a part of coming future. Being an example of HMI, embedded eye tracking systems allow user to interact with objects placed in a known environment by using natural eye movements. -

JPEG and JPEG 2000
JPEG and JPEG 2000 Past, present, and future Richard Clark Elysium Ltd, Crowborough, UK [email protected] Planned presentation Brief introduction JPEG – 25 years of standards… Shortfalls and issues Why JPEG 2000? JPEG 2000 – imaging architecture JPEG 2000 – what it is (should be!) Current activities New and continuing work… +44 1892 667411 - [email protected] Introductions Richard Clark – Working in technical standardisation since early 70’s – Fax, email, character coding (8859-1 is basis of HTML), image coding, multimedia – Elysium, set up in ’91 as SME innovator on the Web – Currently looks after JPEG web site, historical archive, some PR, some standards as editor (extensions to JPEG, JPEG-LS, MIME type RFC and software reference for JPEG 2000), HD Photo in JPEG, and the UK MPEG and JPEG committees – Plus some work that is actually funded……. +44 1892 667411 - [email protected] Elysium in Europe ACTS project – SPEAR – advanced JPEG tools ESPRIT project – Eurostill – consensus building on JPEG 2000 IST – Migrator 2000 – tool migration and feature exploitation of JPEG 2000 – 2KAN – JPEG 2000 advanced networking Plus some other involvement through CEN in cultural heritage and medical imaging, Interreg and others +44 1892 667411 - [email protected] 25 years of standards JPEG – Joint Photographic Experts Group, joint venture between ISO and CCITT (now ITU-T) Evolved from photo-videotex, character coding First meeting March 83 – JPEG proper started in July 86. 42nd meeting in Lausanne, next week… Attendance through national -

Institute for Clinical and Economic Review
INSTITUTE FOR CLINICAL AND ECONOMIC REVIEW FINAL APPRAISAL DOCUMENT CORONARY COMPUTED TOMOGRAPHIC ANGIOGRAPHY FOR DETECTION OF CORONARY ARTERY DISEASE January 9, 2009 Senior Staff Daniel A. Ollendorf, MPH, ARM Chief Review Officer Alexander Göhler, MD, PhD, MSc, MPH Lead Decision Scientist Steven D. Pearson, MD, MSc President, ICER Associate Staff Michelle Kuba, MPH Sr. Technology Analyst Marie Jaeger, B.S. Asst. Decision Scientist © 2009, Institute for Clinical and Economic Review 1 CONTENTS About ICER .................................................................................................................................. 3 Acknowledgments ...................................................................................................................... 4 Executive Summary .................................................................................................................... 5 Evidence Review Group Deliberation.................................................................................. 17 ICER Integrated Evidence Rating.......................................................................................... 25 Evidence Review Group Members........................................................................................ 27 Appraisal Overview.................................................................................................................. 30 Background ................................................................................................................................ 33 -
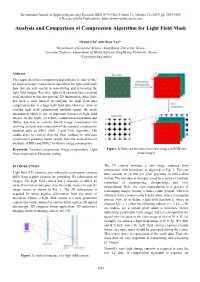
Analysis and Comparison of Compression Algorithm for Light Field Mask
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 12, Number 12 (2017) pp. 3553-3556 © Research India Publications. http://www.ripublication.com Analysis and Comparison of Compression Algorithm for Light Field Mask Hyunji Cho1 and Hoon Yoo2* 1Department of Computer Science, SangMyung University, Korea. 2Associate Professor, Department of Media Software SangMyung University, Korea. *Corresponding author Abstract This paper describes comparison and analysis of state-of-the- art lossless image compression algorithms for light field mask data that are very useful in transmitting and refocusing the light field images. Recently, light field cameras have received wide attention in that they provide 3D information. Also, there has been a wide interest in studying the light field data compression due to a huge light field data. However, most of existing light field compression methods ignore the mask information which is one of important features of light field images. In this paper, we reports compression algorithms and further use this to achieve binary image compression by realizing analysis and comparison of the standard compression methods such as JBIG, JBIG 2 and PNG algorithm. The results seem to confirm that the PNG method for text data compression provides better results than the state-of-the-art methods of JBIG and JBIG2 for binary image compression. Keywords: Lossless compression, Image compression, Light Figure. 2. Basic architecture from raw images to RGB and filed compression, Plenoptic coding mask images INTRODUCTION The LF camera provides a raw image captured from photosensor with microlens, as depicted in Fig. 1. The raw Light field (LF) cameras, also referred to as plenoptic cameras, data consists of 10 bits per pixel precision in little-endian differ from regular cameras by providing 3D information of format. -

PDF Image JBIG2 Compression and Decompression with JBIG2 Encoding and Decoding SDK Library | 1
PDF image JBIG2 compression and decompression with JBIG2 encoding and decoding SDK library | 1 JBIG2 is an image compression standard for bi-level images developed by the Joint bi-level Image Expert Group. It is suitable for lossless compression and lossy compression. According to the group’s press release, in its lossless mode, JBIG2 usually generates files that are one- third to one-fifth the size of the fax group 4 and twice the size of JBIG, which was previously released by the group. The double-layer compression standard. JBIG2 was released as an international standard ITU in 2000. JBIG2 compression JBIG2 is an international standard for bi-level image compression. By segmenting the image into overlapping and/or non-overlapping areas of text, halftones and general content, compression techniques optimized for each content type are used: *Text area: The text area is composed of characters that are well suited for symbol-based encoding methods. Usually, each symbol will correspond to a character bitmap, and a sub-image represents a character or text. For each uppercase and lowercase character used on the front face, there is usually only one character bitmap (or sub-image) in the symbol dictionary. For example, the dictionary will have an “a” bitmap, an “A” bitmap, a “b” bitmap, and so on. VeryUtils.com PDF image JBIG2 compression and decompression with JBIG2 encoding and decoding SDK library | 1 PDF image JBIG2 compression and decompression with JBIG2 encoding and decoding SDK library | 2 *Halftone area: Halftone areas are similar to text areas because they consist of patterns arranged in a regular grid. -
Lossless Image Compression
Lossless Image Compression C.M. Liu Perceptual Signal Processing Lab College of Computer Science National Chiao-Tung University http://www.csie.nctu.edu.tw/~cmliu/Courses/Compression/ Office: EC538 (03)5731877 [email protected] Lossless JPEG (1992) 2 ITU Recommendation T.81 (09/92) Compression based on 8 predictive modes ( “selection values): 0 P(x) = x (no prediction) 1 P(x) = W 2 P(x) = N 3 P(x) = NW NW N 4 P(x) = W + N - NW 5 P(x) = W + ⎣(N-NW)/2⎦ W x 6 P(x) = N + ⎣(W-NW)/2⎦ 7 P(x) = ⎣(W + N)/2⎦ Sequence is then entropy-coded (Huffman/AC) Lossless JPEG (2) 3 Value 0 used for differential coding only in hierarchical mode Values 1, 2, 3 One-dimensional predictors Values 4, 5, 6, 7 Two-dimensional Value 1 (W) Used in the first line of samples At the beginning of each restart Selected predictor used for the other lines Value 2 (N) Used at the start of each line, except first P-1 Default predictor value: 2 At the start of first line Beginning of each restart Lossless JPEG Performance 4 JPEG prediction mode comparisons JPEG vs. GIF vs. PNG Context-Adaptive Lossless Image Compression [Wu 95/96] 5 Two modes: gray-scale & bi-level We are skipping the lossy scheme for now Basic ideas find the best context from the info available to encoder/decoder estimate the presence/lack of horizontal/vertical features CALIC: Initial Prediction 6 if dh−dv > 80 // sharp horizontal edge X* = N else if dv−dh > 80 // sharp vertical edge X* = W else { // assume smoothness first X* = (N+W)/2 +(NE−NW)/4 if dh−dv > 32 // horizontal edge X* = (X*+N)/2 -

Acronyms Abbreviations &Terms
Acronyms Abbreviations &Terms A Capability Assurance Job Aid FEMA P-524 / July 2009 FEMA Acronyms Abbreviations and Terms Produced by the National Preparedness Directorate, National Integration Center, Incident Management Systems Integration Division Please direct requests for additional copies to: FEMA Publications (800) 480-2520 Or download the document from the Web: www.fema.gov/plan/prepare/faat.shtm U.S. Department of Homeland Security Federal Emergency Management Agency The FEMA Acronyms, Abbreviations & Terms (FAAT) List is not designed to be an authoritative source, merely a handy reference and a living document subject to periodic updating. Inclusion recognizes terminology existence, not legitimacy. Entries known to be obsolete (see new “Obsolete or Replaced” section near end of this document) are included because they may still appear in extant publications and correspondence. Your comments and recommendations are welcome. Please electronically forward your input or direct your questions to: [email protected] Please direct requests for additional copies to: FEMA Publications (800) 480-2520 Or download the document from the Web: www.fema.gov/plan/prepare/faat.shtm 2SR Second Stage Review ABEL Agent Based Economic Laboratory 4Wd Four Wheel Drive ABF Automatic Broadcast Feed A 1) Activity of Isotope ABHS Alcohol Based Hand Sanitizer 2) Ampere ABI Automated Broker Interface 3) Atomic Mass ABIH American Board of Industrial Hygiene A&E Architectural and Engineering ABIS see IDENT A&FM Aviation and Fire Management ABM Anti-Ballistic Missile -

Parallel Heterogeneous Computing a Case Study on Accelerating JPEG2000 Coder
Parallel Heterogeneous Computing A Case Study On Accelerating JPEG2000 Coder by Ro-To Le M.Sc., Brown University; Providence, RI, USA, 2009 B.Sc., Hanoi University of Technology; Hanoi, Vietnam, 2007 A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The School of Engineering at Brown University PROVIDENCE, RHODE ISLAND May 2013 c Copyright 2013 by Ro-To Le This dissertation by Ro-To Le is accepted in its present form by The School of Engineering as satisfying the dissertation requirement for the degree of Doctor of Philosophy. Date R. Iris Bahar, Ph.D., Advisor Date Joseph L. Mundy, Ph.D., Advisor Recommended to the Graduate Council Date Vishal Jain, Ph.D., Reader Approved by the Graduate Council Date Peter M. Weber, Dean of the Graduate School iii Vitae Roto Le was born in Duc-Tho, Ha-Tinh, a countryside area in the Midland of Vietnam. He received his B.Sc., with Excellent Classification, in Electronics and Telecommunications from Hanoi University of Technology in 2007. Soon after re- ceiving his B.Sc., Roto came to Brown University to start a Ph.D. program in Com- puter Engineering in Fall 2007. His Ph.D. program was sponsored by a fellowship from the Vietnam Education Foundation, which was selectively nominated by the National Academies’ scientists. During his Ph.D. program, he earned a M.Sc. degree in Computer Engineering in 2009. Roto has been studying several aspects of modern computing systems, from hardware architecture and VLSI system design to high-performance software design. He has published several articles in designing a parallel JPEG2000 coder based on heterogeneous CPU-GPGPU systems and designing novel Three-Dimensional (3D) FPGA architectures. -

Kompresja Statycznego Obrazu 138
Damian Karwowski Zrozumieć Kompresję Obrazu Podstawy Technik Kodowania Stratnego oraz Bezstratnego Obrazów Wydanie Pierwsze, wersja 1.2 Poznań 2019r. ISBN 978-83-953420-0-4 9 788395 342004 © Damian Karwowski – „Zrozumieć Kompresję Obrazu” © Copyright by DAMIAN KARWOWSKI. All rights reserved. Książka jest chroniona prawem autorskim i prawami pokrewnymi. Egzemplarz książki został zdeponowany w Kancelarii Notarialnej. Książka jest dostępna pod adresem: www.zrozumieckompresje.pl ISBN 978-83-953420-0-4 Projekt okładki książki oraz strona internetowa zostały wykonane przez Marka Piskulskiego. Serdecznie dziękuję za profesjonalną pracę Obraz „Miś Panda”, który jest częścią okładki, namalowała na płótnie Natalka Karwowska. Natalko, dziękuję Ci za Twój wysiłek Autor książki dołożył ogromnych starań, żeby zamieszczone w niej informacje były prawdziwe i rzetelnie przedstawione. Korzystając z książki Czytelnik robi to jednak wyłącznie na własną odpowiedzialność. Tym samym autor nie odpowiada za jakiekolwiek szkody, będące następstwem wykorzystania zawartej w książce wiedzy. Autor książki Dr inż. Damian Karwowski. Absolwent Politechniki Poznańskiej. Uzyskał tytuł zawodowy magistra inżyniera oraz stopień doktora nauk technicznych na Politechnice Poznańskiej, odpowiednio w latach 2003 i 2008. Obecnie pracownik naukowo-dydaktyczny na wyżej wymienionej uczelni. Od roku 2003 zawodowo zajmuje się kompresją obrazu. Autor ponad 50 publikacji naukowych o tematyce kompresji i przetwarzania obrazów. Brał udział w licznych projektach naukowych dotyczących wydajnej reprezentacji multimedialnych danych. Dodatkowo członek wielu zespołów badawczych, które w tematyce kompresji obrazu i dźwięku realizowały prace badawczo-wdrożeniowe dla przemysłu. Jego zainteresowania obejmują kompresję danych, techniki kodowania entropijnego danych oraz realizację kodeków obrazu i dźwięku na procesorach x86 oraz DSP. 4 | S t r o n a © Damian Karwowski – „Zrozumieć Kompresję Obrazu” Spis treści Spis treści 5 “Słowo” wstępu 11 Rozdział 1 15 Obraz i jego reprezentacja przestrzenna 15 1.1.