Uq5912f90 OA.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Identification of the Binding Partners for Hspb2 and Cryab Reveals
Brigham Young University BYU ScholarsArchive Theses and Dissertations 2013-12-12 Identification of the Binding arP tners for HspB2 and CryAB Reveals Myofibril and Mitochondrial Protein Interactions and Non- Redundant Roles for Small Heat Shock Proteins Kelsey Murphey Langston Brigham Young University - Provo Follow this and additional works at: https://scholarsarchive.byu.edu/etd Part of the Microbiology Commons BYU ScholarsArchive Citation Langston, Kelsey Murphey, "Identification of the Binding Partners for HspB2 and CryAB Reveals Myofibril and Mitochondrial Protein Interactions and Non-Redundant Roles for Small Heat Shock Proteins" (2013). Theses and Dissertations. 3822. https://scholarsarchive.byu.edu/etd/3822 This Thesis is brought to you for free and open access by BYU ScholarsArchive. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. Identification of the Binding Partners for HspB2 and CryAB Reveals Myofibril and Mitochondrial Protein Interactions and Non-Redundant Roles for Small Heat Shock Proteins Kelsey Langston A thesis submitted to the faculty of Brigham Young University in partial fulfillment of the requirements for the degree of Master of Science Julianne H. Grose, Chair William R. McCleary Brian Poole Department of Microbiology and Molecular Biology Brigham Young University December 2013 Copyright © 2013 Kelsey Langston All Rights Reserved ABSTRACT Identification of the Binding Partners for HspB2 and CryAB Reveals Myofibril and Mitochondrial Protein Interactors and Non-Redundant Roles for Small Heat Shock Proteins Kelsey Langston Department of Microbiology and Molecular Biology, BYU Master of Science Small Heat Shock Proteins (sHSP) are molecular chaperones that play protective roles in cell survival and have been shown to possess chaperone activity. -
Evolution of Multiple Cell Clones Over a 29-Year Period of a CLL Patient
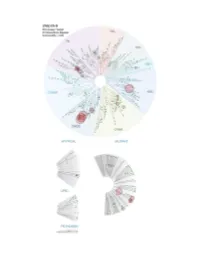
ARTICLE Received 11 May 2016 | Accepted 1 Nov 2016 | Published 16 Dec 2016 DOI: 10.1038/ncomms13765 OPEN Evolution of multiple cell clones over a 29-year period of a CLL patient Zhikun Zhao1,2,3,*, Lynn Goldin4,*, Shiping Liu1,5,*, Liang Wu1,*, Weiyin Zhou6,*, Hong Lou6,*, Qichao Yu1,7, Shirley X. Tsang8, Miaomiao Jiang1,3, Fuqiang Li1, MaryLou McMaster4, Yang Li1, Xinxin Lin1, Zhifeng Wang1, Liqin Xu1, Gerald Marti9, Guibo Li1,10,KuiWu1,10, Meredith Yeager6, Huanming Yang1,11, Xun Xu1,**, Stephen J. Chanock4,**, Bo Li1,**, Yong Hou1,10,**, Neil Caporaso4,** & Michael Dean1,4,** Chronic lymphocytic leukaemia (CLL) is a frequent B-cell malignancy, characterized by recurrent somatic chromosome alterations and a low level of point mutations. Here we present single-nucleotide polymorphism microarray analyses of a single CLL patient over 29 years of observation and treatment, and transcriptome and whole-genome sequencing at selected time points. We identify chromosome alterations 13q14 À ,6qÀ and 12q þ in early cell clones, elimination of clonal populations following therapy, and subsequent appearance of a clone containing trisomy 12 and chromosome 10 copy-neutral loss of heterogeneity that marks a major population dominant at death. Serial single-cell RNA sequencing reveals an expression pattern with high FOS, JUN and KLF4 at disease acceleration, which resolves following therapy, but reoccurs following relapse and death. Transcriptome evolution indicates complex changes in expression occur over time. In conclusion, CLL can evolve gradually during indolent phases, and undergo rapid changes following therapy. 1 BGI-Shenzhen, Shenzhen 518083, China. 2 State Key Laboratory of Bioelectronics, Southeast University, Nanjing 210096, China. -

Non-Coding Rnas As Cancer Hallmarks in Chronic Lymphocytic Leukemia
International Journal of Molecular Sciences Review Non-Coding RNAs as Cancer Hallmarks in Chronic Lymphocytic Leukemia Linda Fabris 1, Jaroslav Juracek 2 and George Calin 1,* 1 Department of Translational Molecular Pathology, The University of Texas MD Anderson Cancer Center, Houston, TX 77030, USA; [email protected] 2 Department of Experimental Therapeutics, The University of Texas MD Anderson Cancer Center, Houston, TX 77030, USA; [email protected] * Correspondence: [email protected] Received: 24 July 2020; Accepted: 10 September 2020; Published: 14 September 2020 Abstract: The discovery of non-coding RNAs (ncRNAs) and their role in tumor onset and progression has revolutionized the way scientists and clinicians study cancers. This discovery opened new layers of complexity in understanding the fine-tuned regulation of cellular processes leading to cancer. NcRNAs represent a heterogeneous group of transcripts, ranging from a few base pairs to several kilobases, that are able to regulate gene networks and intracellular pathways by interacting with DNA, transcripts or proteins. Deregulation of ncRNAs impinge on several cellular responses and can play a major role in each single hallmark of cancer. This review will focus on the most important short and long non-coding RNAs in chronic lymphocytic leukemia (CLL), highlighting their implications as potential biomarkers and therapeutic targets as they relate to the well-established hallmarks of cancer. The key molecular events in the onset of CLL will be contextualized, taking into account the role of the “dark matter” of the genome. Keywords: chronic lymphocytic leukemia; lncRNA; miRNA; hallmarks 1. Introduction: Current Status of Chronic Lymphocytic Leukemia Research Chronic lymphocytic leukemia (CLL) is the most common leukemia in adults in the Western world, representing more than 30% of all leukemia cases [1]. -

Seq2pathway Vignette
seq2pathway Vignette Bin Wang, Xinan Holly Yang, Arjun Kinstlick May 19, 2021 Contents 1 Abstract 1 2 Package Installation 2 3 runseq2pathway 2 4 Two main functions 3 4.1 seq2gene . .3 4.1.1 seq2gene flowchart . .3 4.1.2 runseq2gene inputs/parameters . .5 4.1.3 runseq2gene outputs . .8 4.2 gene2pathway . 10 4.2.1 gene2pathway flowchart . 11 4.2.2 gene2pathway test inputs/parameters . 11 4.2.3 gene2pathway test outputs . 12 5 Examples 13 5.1 ChIP-seq data analysis . 13 5.1.1 Map ChIP-seq enriched peaks to genes using runseq2gene .................... 13 5.1.2 Discover enriched GO terms using gene2pathway_test with gene scores . 15 5.1.3 Discover enriched GO terms using Fisher's Exact test without gene scores . 17 5.1.4 Add description for genes . 20 5.2 RNA-seq data analysis . 20 6 R environment session 23 1 Abstract Seq2pathway is a novel computational tool to analyze functional gene-sets (including signaling pathways) using variable next-generation sequencing data[1]. Integral to this tool are the \seq2gene" and \gene2pathway" components in series that infer a quantitative pathway-level profile for each sample. The seq2gene function assigns phenotype-associated significance of genomic regions to gene-level scores, where the significance could be p-values of SNPs or point mutations, protein-binding affinity, or transcriptional expression level. The seq2gene function has the feasibility to assign non-exon regions to a range of neighboring genes besides the nearest one, thus facilitating the study of functional non-coding elements[2]. Then the gene2pathway summarizes gene-level measurements to pathway-level scores, comparing the quantity of significance for gene members within a pathway with those outside a pathway. -

Supplementary Information Integrative Analyses of Splicing in the Aging Brain: Role in Susceptibility to Alzheimer’S Disease
Supplementary Information Integrative analyses of splicing in the aging brain: role in susceptibility to Alzheimer’s Disease Contents 1. Supplementary Notes 1.1. Religious Orders Study and Memory and Aging Project 1.2. Mount Sinai Brain Bank Alzheimer’s Disease 1.3. CommonMind Consortium 1.4. Data Availability 2. Supplementary Tables 3. Supplementary Figures Note: Supplementary Tables are provided as separate Excel files. 1. Supplementary Notes 1.1. Religious Orders Study and Memory and Aging Project Gene expression data1. Gene expression data were generated using RNA- sequencing from Dorsolateral Prefrontal Cortex (DLPFC) of 540 individuals, at an average sequence depth of 90M reads. Detailed description of data generation and processing was previously described2 (Mostafavi, Gaiteri et al., under review). Samples were submitted to the Broad Institute’s Genomics Platform for transcriptome analysis following the dUTP protocol with Poly(A) selection developed by Levin and colleagues3. All samples were chosen to pass two initial quality filters: RNA integrity (RIN) score >5 and quantity threshold of 5 ug (and were selected from a larger set of 724 samples). Sequencing was performed on the Illumina HiSeq with 101bp paired-end reads and achieved coverage of 150M reads of the first 12 samples. These 12 samples will serve as a deep coverage reference and included 2 males and 2 females of nonimpaired, mild cognitive impaired, and Alzheimer's cases. The remaining samples were sequenced with target coverage of 50M reads; the mean coverage for the samples passing QC is 95 million reads (median 90 million reads). The libraries were constructed and pooled according to the RIN scores such that similar RIN scores would be pooled together. -

Environmental Influences on Endothelial Gene Expression
ENDOTHELIAL CELL GENE EXPRESSION John Matthew Jeff Herbert Supervisors: Prof. Roy Bicknell and Dr. Victoria Heath PhD thesis University of Birmingham August 2012 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ABSTRACT Tumour angiogenesis is a vital process in the pathology of tumour development and metastasis. Targeting markers of tumour endothelium provide a means of targeted destruction of a tumours oxygen and nutrient supply via destruction of tumour vasculature, which in turn ultimately leads to beneficial consequences to patients. Although current anti -angiogenic and vascular targeting strategies help patients, more potently in combination with chemo therapy, there is still a need for more tumour endothelial marker discoveries as current treatments have cardiovascular and other side effects. For the first time, the analyses of in-vivo biotinylation of an embryonic system is performed to obtain putative vascular targets. Also for the first time, deep sequencing is applied to freshly isolated tumour and normal endothelial cells from lung, colon and bladder tissues for the identification of pan-vascular-targets. Integration of the proteomic, deep sequencing, public cDNA libraries and microarrays, delivers 5,892 putative vascular targets to the science community. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
Profiling Data
Compound Name DiscoveRx Gene Symbol Entrez Gene Percent Compound Symbol Control Concentration (nM) JNK-IN-8 AAK1 AAK1 69 1000 JNK-IN-8 ABL1(E255K)-phosphorylated ABL1 100 1000 JNK-IN-8 ABL1(F317I)-nonphosphorylated ABL1 87 1000 JNK-IN-8 ABL1(F317I)-phosphorylated ABL1 100 1000 JNK-IN-8 ABL1(F317L)-nonphosphorylated ABL1 65 1000 JNK-IN-8 ABL1(F317L)-phosphorylated ABL1 61 1000 JNK-IN-8 ABL1(H396P)-nonphosphorylated ABL1 42 1000 JNK-IN-8 ABL1(H396P)-phosphorylated ABL1 60 1000 JNK-IN-8 ABL1(M351T)-phosphorylated ABL1 81 1000 JNK-IN-8 ABL1(Q252H)-nonphosphorylated ABL1 100 1000 JNK-IN-8 ABL1(Q252H)-phosphorylated ABL1 56 1000 JNK-IN-8 ABL1(T315I)-nonphosphorylated ABL1 100 1000 JNK-IN-8 ABL1(T315I)-phosphorylated ABL1 92 1000 JNK-IN-8 ABL1(Y253F)-phosphorylated ABL1 71 1000 JNK-IN-8 ABL1-nonphosphorylated ABL1 97 1000 JNK-IN-8 ABL1-phosphorylated ABL1 100 1000 JNK-IN-8 ABL2 ABL2 97 1000 JNK-IN-8 ACVR1 ACVR1 100 1000 JNK-IN-8 ACVR1B ACVR1B 88 1000 JNK-IN-8 ACVR2A ACVR2A 100 1000 JNK-IN-8 ACVR2B ACVR2B 100 1000 JNK-IN-8 ACVRL1 ACVRL1 96 1000 JNK-IN-8 ADCK3 CABC1 100 1000 JNK-IN-8 ADCK4 ADCK4 93 1000 JNK-IN-8 AKT1 AKT1 100 1000 JNK-IN-8 AKT2 AKT2 100 1000 JNK-IN-8 AKT3 AKT3 100 1000 JNK-IN-8 ALK ALK 85 1000 JNK-IN-8 AMPK-alpha1 PRKAA1 100 1000 JNK-IN-8 AMPK-alpha2 PRKAA2 84 1000 JNK-IN-8 ANKK1 ANKK1 75 1000 JNK-IN-8 ARK5 NUAK1 100 1000 JNK-IN-8 ASK1 MAP3K5 100 1000 JNK-IN-8 ASK2 MAP3K6 93 1000 JNK-IN-8 AURKA AURKA 100 1000 JNK-IN-8 AURKA AURKA 84 1000 JNK-IN-8 AURKB AURKB 83 1000 JNK-IN-8 AURKB AURKB 96 1000 JNK-IN-8 AURKC AURKC 95 1000 JNK-IN-8 -

Co-Expression Module Analysis Reveals Biological Processes
Shi et al. BMC Systems Biology 2010, 4:74 http://www.biomedcentral.com/1752-0509/4/74 RESEARCH ARTICLE Open Access Co-expressionResearch article module analysis reveals biological processes, genomic gain, and regulatory mechanisms associated with breast cancer progression Zhiao Shi1,2, Catherine K Derow3 and Bing Zhang*3 Abstract Background: Gene expression signatures are typically identified by correlating gene expression patterns to a disease phenotype of interest. However, individual gene-based signatures usually suffer from low reproducibility and interpretability. Results: We have developed a novel algorithm Iterative Clique Enumeration (ICE) for identifying relatively independent maximal cliques as co-expression modules and a module-based approach to the analysis of gene expression data. Applying this approach on a public breast cancer dataset identified 19 modules whose expression levels were significantly correlated with tumor grade. The correlations were reproducible for 17 modules in an independent breast cancer dataset, and the reproducibility was considerably higher than that based on individual genes or modules identified by other algorithms. Sixteen out of the 17 modules showed significant enrichment in certain Gene Ontology (GO) categories. Specifically, modules related to cell proliferation and immune response were up-regulated in high- grade tumors while those related to cell adhesion was down-regulated. Further analyses showed that transcription factors NYFB, E2F1/E2F3, NRF1, and ELK1 were responsible for the up-regulation of the cell proliferation modules. IRF family and ETS family proteins were responsible for the up-regulation of the immune response modules. Moreover, inhibition of the PPARA signaling pathway may also play an important role in tumor progression. -

Redefining the Specificity of Phosphoinositide-Binding by Human
bioRxiv preprint doi: https://doi.org/10.1101/2020.06.20.163253; this version posted June 21, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. Redefining the specificity of phosphoinositide-binding by human PH domain-containing proteins Nilmani Singh1†, Adriana Reyes-Ordoñez1†, Michael A. Compagnone1, Jesus F. Moreno Castillo1, Benjamin J. Leslie2, Taekjip Ha2,3,4,5, Jie Chen1* 1Department of Cell & Developmental Biology, University of Illinois at Urbana-Champaign, Urbana, IL 61801; 2Department of Biophysics and Biophysical Chemistry, Johns Hopkins University School of Medicine, Baltimore, MD 21205; 3Department of Biophysics, Johns Hopkins University, Baltimore, MD 21218; 4Department of Biomedical Engineering, Johns Hopkins University, Baltimore, MD 21205; 5Howard Hughes Medical Institute, Baltimore, MD 21205, USA †These authors contributed equally to this work. *Correspondence: [email protected]. bioRxiv preprint doi: https://doi.org/10.1101/2020.06.20.163253; this version posted June 21, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. ABSTRACT Pleckstrin homology (PH) domains are presumed to bind phosphoinositides (PIPs), but specific interaction with and regulation by PIPs for most PH domain-containing proteins are unclear. Here we employed a single-molecule pulldown assay to study interactions of lipid vesicles with full-length proteins in mammalian whole cell lysates. -

Noelia Díaz Blanco
Effects of environmental factors on the gonadal transcriptome of European sea bass (Dicentrarchus labrax), juvenile growth and sex ratios Noelia Díaz Blanco Ph.D. thesis 2014 Submitted in partial fulfillment of the requirements for the Ph.D. degree from the Universitat Pompeu Fabra (UPF). This work has been carried out at the Group of Biology of Reproduction (GBR), at the Department of Renewable Marine Resources of the Institute of Marine Sciences (ICM-CSIC). Thesis supervisor: Dr. Francesc Piferrer Professor d’Investigació Institut de Ciències del Mar (ICM-CSIC) i ii A mis padres A Xavi iii iv Acknowledgements This thesis has been made possible by the support of many people who in one way or another, many times unknowingly, gave me the strength to overcome this "long and winding road". First of all, I would like to thank my supervisor, Dr. Francesc Piferrer, for his patience, guidance and wise advice throughout all this Ph.D. experience. But above all, for the trust he placed on me almost seven years ago when he offered me the opportunity to be part of his team. Thanks also for teaching me how to question always everything, for sharing with me your enthusiasm for science and for giving me the opportunity of learning from you by participating in many projects, collaborations and scientific meetings. I am also thankful to my colleagues (former and present Group of Biology of Reproduction members) for your support and encouragement throughout this journey. To the “exGBRs”, thanks for helping me with my first steps into this world. Working as an undergrad with you Dr. -

Large Meta-Analysis of Genome-Wide Association Studies
medRxiv preprint doi: https://doi.org/10.1101/2020.10.01.20200659; this version posted October 4, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. It is made available under a CC-BY-NC-ND 4.0 International license . Large meta-analysis of genome-wide association studies expands knowledge of the genetic etiology of Alzheimer’s disease and highlights potential translational opportunities Céline Bellenguez1,*,#, Fahri Küçükali2,3,4*, Iris Jansen5,6*, Victor Andrade7,8*, Sonia Morenau- Grau9,10,*, Najaf Amin11,12, Benjamin Grenier-Boley1, Anne Boland13, Luca Kleineidam7,8, Peter Holmans14, Pablo Garcia9,10, Rafael Campos Martin7, Adam Naj15,16, Yang Qiong17, Joshua C. Bis18, Vincent Damotte1, Sven Van der Lee5,6,19, Marcos Costa1, Julien Chapuis1, Vilmentas Giedraitis20, María Jesús Bullido10,21, Adolfo López de Munáin10,22, Jordi Pérez- Tur10,23, Pascual Sánchez-Juan10,24, Raquel Sánchez-Valle25, Victoria Álvarez26, Pau Pastor27, Miguel Medina10,28, Jasper Van Dongen2,3,4, Christine Van Broeckhoven2,3,4, Rik Vandenberghe29,30, Sebastiaan Engelborghs31,32, Gael Nicolas33, Florence Pasquier34, Olivier Hanon35, Carole Dufouil36, Claudine Berr37, Stéphanie Debette36, Jean-François Dartigues36, Gianfranco Spalletta38, Benedetta Nacmias39,40, Vincenzo Solfrezzi41, Barbara Borroni42, Lucio Tremolizzo43, Davide Seripa44, Paolo Caffarra45, Antonio Daniele46,47, Daniela Galimberti48,49, Innocenzo Rainero50, Luisa Benussi51, Alesio Squassina52, Patrizia Mecoci53, Lucilla Parnetti54, Carlo Masullo55, Beatrice Arosio56, John Hardy57, Simon Mead58, Kevin Morgan59, Clive Holmes60, Patrick Kehoe61, Bob Woods62, EADB, Charge, ADGC, Jin Sha15,16, Yi Zhao15,63, Chien-Yueh Lee15,63, Pavel P.