UNIT 11 ADVANCED DATA STRUCTURES Structures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Curriculum for Second Year of Computer Engineering (2019 Course) (With Effect from 2020-21)
Faculty of Science and Technology Savitribai Phule Pune University Maharashtra, India Curriculum for Second Year of Computer Engineering (2019 Course) (With effect from 2020-21) www.unipune.ac.in Savitribai Phule Pune University Savitribai Phule Pune University Bachelor of Computer Engineering Program Outcomes (PO) Learners are expected to know and be able to– PO1 Engineering Apply the knowledge of mathematics, science, Engineering fundamentals, knowledge and an Engineering specialization to the solution of complex Engineering problems PO2 Problem analysis Identify, formulate, review research literature, and analyze complex Engineering problems reaching substantiated conclusions using first principles of mathematics natural sciences, and Engineering sciences PO3 Design / Development Design solutions for complex Engineering problems and design system of Solutions components or processes that meet the specified needs with appropriate consideration for the public health and safety, and the cultural, societal, and Environmental considerations PO4 Conduct Use research-based knowledge and research methods including design of Investigations of experiments, analysis and interpretation of data, and synthesis of the Complex Problems information to provide valid conclusions. PO5 Modern Tool Usage Create, select, and apply appropriate techniques, resources, and modern Engineering and IT tools including prediction and modeling to complex Engineering activities with an understanding of the limitations PO6 The Engineer and Apply reasoning informed by -

Simple Balanced Binary Search Trees
Simple Balanced Binary Search Trees Prabhakar Ragde Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] Efficient implementations of sets and maps (dictionaries) are important in computer science, and bal- anced binary search trees are the basis of the best practical implementations. Pedagogically, however, they are often quite complicated, especially with respect to deletion. I present complete code (with justification and analysis not previously available in the literature) for a purely-functional implemen- tation based on AA trees, which is the simplest treatment of the subject of which I am aware. 1 Introduction Trees are a fundamental data structure, introduced early in most computer science curricula. They are easily motivated by the need to store data that is naturally tree-structured (family trees, structured doc- uments, arithmetic expressions, and programs). We also expose students to the idea that we can impose tree structure on data that is not naturally so, in order to implement efficient manipulation algorithms. The typical first example is the binary search tree. However, they are problematic. Naive insertion and deletion are easy to present in a first course using a functional language (usually the topic is delayed to a second course if an imperative language is used), but in the worst case, this im- plementation degenerates to a list, with linear running time for all operations. The solution is to balance the tree during operations, so that a tree with n nodes has height O(logn). There are many different ways of doing this, but most are too complicated to present this early in the curriculum, so they are usually deferred to a later course on algorithms and data structures, leaving a frustrating gap. -

Wrapped Kd Trees Handed
CMSC 420: Spring 2021 Programming Assignment 2: Wrapped k-d Trees Handed out: Tue, Apr 6. Due: Wed, Apr 21, 11pm. (Submission via Gradescope.) Overview: In this assignment you will implement a variant of the kd-tree data structure, called a wrapped kd-tree (or WKDTree) to store a set of points in 2-dimensional space. This data structure will support insertion, deletion, and a number of geometric queries, some of which will be used later in Part 3 of the programming assignment. The data structure will be templated with the point type, which is any class that implements the Java interface LabeledPoint2D, as described in the file LabeledPoint2D.java from the provided skeleton code. A labeled point is a 2-dimensional point (Point2D from the skeleton code) that supports an additional function getLabel(). This returns a string associated with the point. In our case, the points will be the airports from our earlier projects, and the labels will be the 3-letter airport codes. The associated point (represented as a Point2D) can be extracted using the function getPoint2D(). The individual coordinates (which are floats) can be extracted directly using the functions getX() and getY(), or get(i), where i = 0 for x and i = 1 for y. Your wrapped kd-tree will be templated with one type, which we will call LPoint (for \labeled point"). For example, your file WKDTree will contain the following public class: public class WKDTree<LPoint extends LabeledPoint2D> { ... } Wrapped kd-Tree: Recall that a kd-tree is a data structure based on a hierarchical decomposition of space, using axis-orthogonal splits. -

Slides-Data-Structures.Pdf
Data structures ● Organize your data to support various queries using little time an space Example: Inventory Want to support SEARCH INSERT DELETE ● Given n elements A[1..n] ● Support SEARCH(A,x) := is x in A? ● Trivial solution: scan A. Takes time Θ(n) ● Best possible given A, x. ● What if we are first given A, are allowed to preprocess it, can we then answer SEARCH queries faster? ● How would you preprocess A? ● Given n elements A[1..n] ● Support SEARCH(A,x) := is x in A? ● Preprocess step: Sort A. Takes time O(n log n), Space O(n) ● SEARCH(A[1..n],x) := /* Binary search */ If n = 1 then return YES if A[1] = x, and NO otherwise else if A[n/2] ≤ x then return SEARCH(A[n/2..n]) else return SEARCH(A[1..n/2]) ● Time T(n) = ? ● Given n elements A[1..n] ● Support SEARCH(A,x) := is x in A? ● Preprocess step: Sort A. Takes time O(n log n), Space O(n) ● SEARCH(A[1..n],x) := /* Binary search */ If n = 1 then return YES if A[1] = x, and NO otherwise else if A[n/2] ≤ x then return SEARCH(A[n/2..n]) else return SEARCH(A[1..n/2]) ● Time T(n) = O(log n). ● Given n elements A[1..n] each ≤ k, can you do faster? ● Support SEARCH(A,x) := is x in A? ● DIRECTADDRESS: Initialize S[1..k] to 0 ● Preprocess step: For (i = 1 to n) S[A[i]] = 1 ● T(n) = O(n), Space O(k) ● SEARCH(A,x) = ? ● Given n elements A[1..n] each ≤ k, can you do faster? ● Support SEARCH(A,x) := is x in A? ● DIRECTADDRESS: Initialize S[1..k] to 0 ● Preprocess step: For (i = 1 to n) S[A[i]] = 1 ● T(n) = O(n), Space O(k) ● SEARCH(A,x) = return S[x] ● T(n) = O(1) ● Dynamic problems: ● Want to support SEARCH, INSERT, DELETE ● Support SEARCH(A,x) := is x in A? ● If numbers are small, ≤ k Preprocess: Initialize S to 0. -

CMSC 420: Lecture 6 2-3, Red-Black, and AA Trees
CMSC 420 Dave Mount CMSC 420: Lecture 6 2-3, Red-black, and AA trees \A rose by any other name": In today's lecture, we consider three closely related search trees. All three have the property that they support find, insert, and delete in time O(log n) for a tree with n nodes. Although the definitions appear at first glance to be different, they are essentially equivalent or very slight variants of each other. These are 2-3 trees, red-black trees, and AA trees. Together, they show that the same idea can be viewed from many different perspectives. 2-3 Trees: An \ideal" binary search tree has n nodes and height roughly lg n. (More precisely, the ideal would be blg nc, where we recall our convention that \lg" means logarithm base 2.) However, it is not possible to efficiently maintain a tree subject to such rigid requirements. AVL trees relax the height restriction by allowing the two subtrees associated with each node to be of similar heights. Another way to relax the requirements is to say that a node may have either two or three children (see Fig.1(a) and (b)). When a node has three children, it stores two keys. Given the two key values b and d, the three subtrees A, C, and E must satisfy the requirement that for all a 2 A, c 2 C, and e 2 E, we have a < b < c < d < e; (The concept of an inorder traversal of such a tree can be generalized, but it involves visiting each 3-node twice, once to visit the first key and again to visit the second key.) These are called 2-nodes and 3-nodes, respectively. -

Advanced Data Structures and Implementation
www.getmyuni.com Advanced Data Structures and Implementation • Top-Down Splay Trees • Red-Black Trees • Top-Down Red Black Trees • Top-Down Deletion • Deterministic Skip Lists • AA-Trees • Treaps • k-d Trees • Pairing Heaps www.getmyuni.com Top-Down Splay Tree • Direct strategy requires traversal from the root down the tree, and then bottom-up traversal to implement the splaying tree. • Can implement by storing parent links, or by storing the access path on a stack. • Both methods require large amount of overhead and must handle many special cases. • Initial rotations on the initial access path uses only O(1) extra space, but retains the O(log N) amortized time bound. www.getmyuni.com www.getmyuni.com Case 1: Zig X L R L R Y X Y XR YL Yr XR YL Yr If Y should become root, then X and its right sub tree are made left children of the smallest value in R, and Y is made root of “center” tree. Y does not have to be a leaf for the Zig case to apply. www.getmyuni.com www.getmyuni.com Case 2: Zig-Zig L X R L R Z Y XR Y X Z ZL Zr YR YR XR ZL Zr The value to be splayed is in the tree rooted at Z. Rotate Y about X and attach as left child of smallest value in R www.getmyuni.com www.getmyuni.com Case 3: Zig-Zag (Simplified) L X R L R Y Y XR X YL YL Z Z XR ZL Zr ZL Zr The value to be splayed is in the tree rooted at Z. -

Implementation of the Tree Structure in the XML and Relational Database
Proceedings of Informing Science & IT Education Conference (InSITE) 2012 Implementation of the Tree Structure in the XML and Relational Database Aleksandar Bulajic Nenad Filipovic Faculty of Information Faculty of Engineering Technology, Science, Metropolitan University, University of Kragujevac, Belgrade, Serbia Kragujevac, Serbia [email protected] [email protected] Abstract A tree structure is a powerful tool for storing and manipulating all kind of data, without differ- ences is it used for natural language analysis, compiling computer languages or storing and ana- lyzing scientific or business data. Algorithms for searching and browsing tree structures are well known, and for free are available numbers of tools for manipulating tree structures implemented in different computer languages. Even is impossible to avoid these algorithms and tools, primary focus in this paper is XML and XML tools. Storing and retrieving, as well as validation of XML tree structures in relational database can be a challenge. This document describes these challenges and currently available solutions. Keywords: Tree structure, XQuey, XML, XML Parser, XSLT, XML Schema, DOM, SAX, Da- tabase, SQL. Introduction Tree structure in computer science is a data structure used for representing hierarchical data struc- tures. Oxford Dictionary (Oxford Advanced Learner’s Dictionary 2011) describes hierarchy as “a system, especially in a society or an organization, in which people are organized into different levels of importance from highest to lowest” and Wikipedia describes hierarchy as “Greek: hier- archia (ἱεραρχία), from hierarches, "leader of sacred rites") is an arrangement of items (objects, names, values, categories, etc.) in which the items are represented as being "above," "below," or "at the same level as" one another.” These definitions are not sufficient because a Tree structure requires also that each node has only one parent and can have zero or more children, and is an acyclic connected graph. -

CMSC 420 Data Structures1
CMSC 420 Data Structures1 David M. Mount Department of Computer Science University of Maryland Fall 2019 1 Copyright, David M. Mount, 2019, Dept. of Computer Science, University of Maryland, College Park, MD, 20742. These lecture notes were prepared by David Mount for the course CMSC 420, Data Structures, at the University of Maryland. Permission to use, copy, modify, and distribute these notes for educational purposes and without fee is hereby granted, provided that this copyright notice appear in all copies. Lecture Notes 1 CMSC 420 Lecture 1: Course Introduction and Background Algorithms and Data Structures: The study of data structures and the algorithms that ma- nipulate them is among the most fundamental topics in computer science. Most of what computer systems spend their time doing is storing, accessing, and manipulating data in one form or another. Some examples from computer science include: Information Retrieval: List the 10 most informative Web pages on the subject of \how to treat high blood pressure?" Identify possible suspects of a crime based on fingerprints or DNA evidence. Find movies that a Netflix subscriber may like based on the movies that this person has already viewed. Find images on the Internet containing both kangaroos and horses. Geographic Information Systems: How many people in the USA live within 25 miles of the Mississippi River? List the 10 movie theaters that are closest to my current location. If sea levels rise 10 meters, what fraction of Florida will be under water? Compilers: You need to store a set of variable names along with their associated types. Given an assignment between two variables we need to look them up in a symbol table, determine their types, and determine whether it is possible to cast from one type to the other). -

AVL Tree, Red-Black Tree, 2-3 Tree, AA Tree, Scapegoat Tree, Splay Tree, Treap,
CSC263 Week 4 Problem Set 2 is due this Tuesday! Due Tuesday (Oct 13) Other Announcements Ass1 marks available on MarkUS ➔ Re-marking requests accepted until October 14 **YOUR MARK MAY GO UP OR DOWN AS THE RESULT OF A REMARK REQUEST Recap ADT: Dictionary ➔ Search, Insert, Delete Binary Search Tree ➔ TreeSearch, TreeInsert, TreeDelete, … ➔ Worst case running time: O(h) ➔ Worst case height h: O(n) Balanced BST: h is O(log n) Balanced BSTs AVL tree, Red-Black tree, 2-3 tree, AA tree, Scapegoat tree, Splay tree, Treap, ... AVL tree Invented by Georgy Adelson-Velsky and E. M. Landis in 1962. First self-balancing BST to be invented. We use BFs to check the balance of a tree. An extra attribute to each node in a BST -- balance factor hR(x): height of x’s right subtree hL(x): height of x’s left subtree BF(x) = hR(x) - hL(x) x BF(x) = 0: x is balanced BF(x) = 1: x is right-heavy BF(x) = -1: x is left-heavy above 3 cases are considered as “good” hL hR L R BF(x) > 1 or < -1: x is imbalanced (not good) heights of some special trees NIL h = 0 h = -1 h = 1 Note: height is measured by the number of edges. AVL tree: definition An AVL tree is a BST in which every node is balanced, right-heavy or left-heavy. i.e., the BF of every node must be 0, 1 or -1. 0 - -- ++ + - - + 0 + 0 0 0 0 It can be proven that the height of an AVL tree with n nodes satisfies i.e., h is in O(log n) WHY? Operations on AVL trees AVL-Search(root, k) AVL-Insert(root, x) AVL-Delete(root, x) Things to worry about ➔ Before the operation, the BST is a valid AVL tree (precondition) ➔ After the operation, the BST must still be a valid AVL tree (so re-balancing may be needed) ➔ The balance factor attributes of some nodes need to be updated. -

Randomized Search Trees
Randomized Search Trees Raimund Seidel Fachb erich Informatik Computer Science Division Universitat des Saarlandes University of California Berkeley D Saarbruc ken GERMANY Berkeley CA y Cecilia R Aragon Computer Science Division University of California Berkeley Berkeley CA Abstract We present a randomized strategy for maintaining balance in dynamically changing search trees that has optimal expected b ehavior In particular in the exp ected case a search or an up date takes logarithmic time with the up date requiring fewer than two rotations Moreover the up date time remains logarithmic even if the cost of a rotation is taken to b e prop ortional to the size of the rotated subtree Finger searches and splits and joins can be p erformed in optimal exp ected time also We show that these results continue to hold even if very little true randomness is available ie if only a logarithmic numb er of truely random bits are available Our approach generalizes naturally to weighted trees where the exp ected time b ounds for accesses and up dates again match the worst case time b ounds of the b est deterministic metho ds We also discuss ways of implementing our randomized strategy so that no explicit balance information is maintained Our balancing strategy and our algorithms are exceedingly simple and should b e fast in practice This pap er is dedicated to the memory of Gene Law ler Intro duction Storing sets of items so as to allow for fast access to an item given its key is a ubiquitous problem in computer science When the keys are drawn from -

Finish AVL Trees, Start Priority Queues and Heaps
CSE 373: Data Structures and Algorithms Lecture 11: Finish AVL Trees; Priority Queues; Binary Heaps Instructor: Lilian de Greef Quarter: Summer 2017 Today • Announcements • Finish AVL Trees • Priority Queues • Binary Heaps Announcements • Changes to OFfice Hours: from now on… • No more Wednesday morning & shorter Wednesday aFternoon ofFice hours • New Thursday oFFice hours! • Kyle’s Wednesday hour is now 1:30-2:30pm • Ben’s oFFice hours is now Thursday 1:00-3:00pm • AVL Tree Height • In section, computed that minimum # nodes in AVL tree oF a certain height is S(h) = 1 + S(h-1) + S(h-2) where h = height oF tree • Posted a prooF neXt to these lecture slides online For your perusal Announcements • Midterm • NeXt Friday! (at usual class time & location) • Everything we cover in class until eXam date is Fair game (minus clearly-marked “bonus material”). That includes neXt week’s material! • Today’s hw3 due date designed to give you time to study. • Course Feedback • Heads up: oFficial UW-mediated course feedback session for part of Wednesday • Also want to better understand an anonymous concern on course pacing → Poll The AVL Tree Data Structure An AVL tree is a self-balancing binary search tree. Structural properties 1. Binary tree property (same as BST) 2. Order property (same as For BST) 3. Balance condition: balance of every node is between -1 and 1 where balance(node) = height(node.leFt) – height(node.right) Result: Worst-case depth is O(log n) Single Rotations (Figures by Melissa O’Neill, reprinted with her permission to Lilian) Case #3: Right-Left Case (Figures by Melissa O’Neill, reprinted with her permission to Lilian) Case #3: Right-Left Case (after one rotation) right rotate (Figures by Melissa O’Neill, reprinted with her permission to Lilian) Case #3: Right-Left Case (after two rotations) leFt rotate right rotate A way to remember it: Move d to grandparent’s position. -
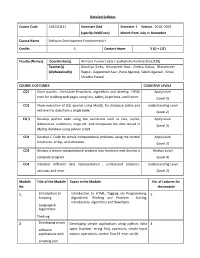
Detailed Syllabus Course Code 15B11CI111 Semester
Detailed Syllabus Course Code 15B11CI111 Semester Odd Semester I. Session 2018 -2019 (specify Odd/Even) Month from July to December Course Name Software Development Fundamentals-I Credits 4 Contact Hours 3 (L) + 1(T) Faculty (Names) Coordinator(s) Archana Purwar ( J62) + Sudhanshu Kulshrestha (J128) Teacher(s) Adwitiya Sinha, Amanpreet Kaur, Chetna Dabas, Dharamveer (Alphabetically) Rajput, Gaganmeet Kaur, Parul Agarwal, Sakshi Agarwal , Sonal, Shradha Porwal COURSE OUTCOMES COGNITIVE LEVELS CO1 Solve puzzles , formulate flowcharts, algorithms and develop HTML Apply Level code for building web pages using lists, tables, hyperlinks, and frames (Level 3) CO2 Show execution of SQL queries using MySQL for database tables and Understanding Level retrieve the data from a single table. (Level 2) CO 3 Develop python code using the constructs such as lists, tuples, Apply Level dictionaries, conditions, loops etc. and manipulate the data stored in (Level 3) MySQL database using python script. CO4 Develop C Code for simple computational problems using the control Apply Level structures, arrays, and structure. (Level 3) CO5 Analyze a simple computational problem into functions and develop a Analyze Level complete program. (Level 4) CO6 Interpret different data representation , understand precision, Understanding Level accuracy and error (Level 2) Module Title of the Module Topics in the Module No. of Lectures for No. the module 1. Introduction to Introduction to HTML, Tagging v/s Programming, 5 Scripting Algorithmic Thinking and Problem Solving, Introductory algorithms and flowcharts Language & Algorithmic Thinking 2. Developing simple Developing simple applications using python; data 4 software types (number, string, list), operators, simple input applications with output, operations, control flow (if -else, while) scripting and visual languages 3.