Trendygenes, a Computational Pipeline for the Detection Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genome Wide Association Study of Response to Interval and Continuous Exercise Training: the Predict‑HIIT Study Camilla J
Williams et al. J Biomed Sci (2021) 28:37 https://doi.org/10.1186/s12929-021-00733-7 RESEARCH Open Access Genome wide association study of response to interval and continuous exercise training: the Predict-HIIT study Camilla J. Williams1†, Zhixiu Li2†, Nicholas Harvey3,4†, Rodney A. Lea4, Brendon J. Gurd5, Jacob T. Bonafglia5, Ioannis Papadimitriou6, Macsue Jacques6, Ilaria Croci1,7,20, Dorthe Stensvold7, Ulrik Wislof1,7, Jenna L. Taylor1, Trishan Gajanand1, Emily R. Cox1, Joyce S. Ramos1,8, Robert G. Fassett1, Jonathan P. Little9, Monique E. Francois9, Christopher M. Hearon Jr10, Satyam Sarma10, Sylvan L. J. E. Janssen10,11, Emeline M. Van Craenenbroeck12, Paul Beckers12, Véronique A. Cornelissen13, Erin J. Howden14, Shelley E. Keating1, Xu Yan6,15, David J. Bishop6,16, Anja Bye7,17, Larisa M. Haupt4, Lyn R. Grifths4, Kevin J. Ashton3, Matthew A. Brown18, Luciana Torquati19, Nir Eynon6 and Jef S. Coombes1* Abstract Background: Low cardiorespiratory ftness (V̇O2peak) is highly associated with chronic disease and mortality from all causes. Whilst exercise training is recommended in health guidelines to improve V̇O2peak, there is considerable inter-individual variability in the V̇O2peak response to the same dose of exercise. Understanding how genetic factors contribute to V̇O2peak training response may improve personalisation of exercise programs. The aim of this study was to identify genetic variants that are associated with the magnitude of V̇O2peak response following exercise training. Methods: Participant change in objectively measured V̇O2peak from 18 diferent interventions was obtained from a multi-centre study (Predict-HIIT). A genome-wide association study was completed (n 507), and a polygenic predictor score (PPS) was developed using alleles from single nucleotide polymorphisms= (SNPs) signifcantly associ- –5 ated (P < 1 10 ) with the magnitude of V̇O2peak response. -

Piezo2 Mediates Low-Threshold Mechanically Evoked Pain in the Cornea
8976 • The Journal of Neuroscience, November 18, 2020 • 40(47):8976–8993 Cellular/Molecular Piezo2 Mediates Low-Threshold Mechanically Evoked Pain in the Cornea Jorge Fernández-Trillo, Danny Florez-Paz, Almudena Íñigo-Portugués, Omar González-González, Ana Gómez del Campo, Alejandro González, Félix Viana, Carlos Belmonte, and Ana Gomis Instituto de Neurociencias, Universidad Miguel Hernández-Consejo Superior de Investigaciones Científicas, 03550 San Juan de Alicante, Alicante,Spain Mammalian Piezo2 channels are essential for transduction of innocuous mechanical forces by proprioceptors and cutaneous touch receptors. In contrast, mechanical responses of somatosensory nociceptor neurons evoking pain, remain intact or are only partially reduced in Piezo2-deficient mice. In the eye cornea, comparatively low mechanical forces are detected by polymodal and pure mecha- nosensory trigeminal ganglion neurons. Their activation always evokes ocular discomfort or pain and protective reflexes, thus being a unique model to study mechanotransduction mechanisms in this particular class of nociceptive neurons. Cultured male and female mouse mechano- and polymodal nociceptor corneal neurons display rapidly, intermediately and slowly adapting mechanically activated currents. Immunostaining of the somas and peripheral axons of corneal neurons responding only to mechanical force (pure mechano-nociceptor) or also exhibiting TRPV1 (transient receptor potential cation channel subfamily V member 1) immunoreactivity (polymodal nociceptor) revealed that they express -

Novel Mutations in TPM2 and PIEZO2 Are Responsible for Distal
Li et al. BMC Medical Genetics (2018) 19:179 https://doi.org/10.1186/s12881-018-0692-8 RESEARCH ARTICLE Open Access Novel mutations in TPM2 and PIEZO2 are responsible for distal arthrogryposis (DA) 2B and mild DA in two Chinese families Shan Li1†, Yi You1†, Jinsong Gao2, Bin Mao1, Yixuan Cao1, Xiuli Zhao1* and Xue Zhang1* Abstract Background: Distal arthrogryposis (DA) is a group of clinically and genetically heterogeneous disorders that involve multiple congenital limb contractures and comprise at least 10 clinical subtypes. Here, we describe our findings in two Chinese families: Family 1 with DA2B (MIM 601680) and Family 2 with mild DA. Methods: To map the disease locus, two-point linkage analysis was performed with microsatellite markers closed to TPM2, TNNI2/TNNT3 and TNNC2. In Family 1, a positive LOD (logarithm of odds) score was only obtained at the microsatellite marker close to TPM2 and mutation screening was performed using direct sequencing of TPM2 in the proband. In Family 2, for the LOD score that did not favor linkage to any markers, whole-exome sequencing (WES) was performed on the proband. PCR–restriction fragment length polymorphism (RFLP) and bioinformatics analysis were then applied to identify the pathogenic mutations in two families. In order to correlate genotype with phenotype in DA, retrospective analyses of phenotypic features according to the TPM2 and PIEZO2 mutation spectrums were carried out. Results: A heterozygous missense mutation c.308A > G (p.Q103R) in TPM2 in Family 1, and a novel variation c.8153G > A (p.R2718Q) in PIEZO2 in Family 2 were identified. -
![The Function and Regulation of Piezo Ion Channels Jason Wu,1 Amanda[13 TD$IF]H](https://docslib.b-cdn.net/cover/2099/the-function-and-regulation-of-piezo-ion-channels-jason-wu-1-amanda-13-td-if-h-1182099.webp)
The Function and Regulation of Piezo Ion Channels Jason Wu,1 Amanda[13 TD$IF]H
TIBS 1305 No. of Pages 15 Series: Fresh Perspectives from Emerging Experts Review Touch, Tension, and Transduction – The Function and Regulation of Piezo Ion Channels Jason Wu,1 Amanda[13_TD$IF]H. Lewis,1 and Jörg Grandl1,* In 2010, two proteins, Piezo1 and Piezo2, were identified as the long-sought Trends molecular carriers of an excitatory mechanically activated current found in many Piezo proteins were identified in 2010 cells. This discovery has opened the floodgates for studying a vast number of as the pore-forming subunits of excita- mechanotransduction processes. Over the past 6 years, groundbreaking tory mechanosensitive ion channels. research has identified Piezos as ion channels that sense light touch, proprio- Piezo ion channels play essential roles ception, and vascular blood flow, ruled out roles for Piezos in several other in diverse physiological processes ran- mechanotransduction processes, and revealed the basic structural and func- ging from regulation of red blood cell fi volume to sensation of gentle touch, tional properties of the channel. Here, we review these ndings and discuss the and are associated with a number of many aspects of Piezo function that remain mysterious, including how Piezos diseases. convert a variety of mechanical stimuli into channel activation and subsequent A recent medium-resolution structure inactivation, and what molecules and mechanisms modulate Piezo function. gives insight into the overall architec- ture of Piezo1, but does not give straight answers as to how the channel Piezo Proteins: True Mechanically Activated Ion Channels? transduces mechanical force into pore Piezo proteins are pore-forming subunits of ion channels that open in response to mechanical opening. -

1 Piezo2 Mechanosensitive Ion Channel Is Located to Sensory
bioRxiv preprint doi: https://doi.org/10.1101/2021.01.20.427483; this version posted January 21, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Piezo2 mechanosensitive ion channel is located to sensory neurons and non-neuronal cells in rat peripheral sensory pathway: implications in pain Seung Min Shin1, Francie Moehring2, Brandon Itson-Zoske1, Fan Fan3, Cheryl L. Stucky2, Quinn H. Hogan1, 4, and Hongwei Yu1, 4* 1. Department of Anesthesiology, Medical College of Wisconsin, Milwaukee, WI 53226 2. Department of Cell Biology, Neurobiology and Anatomy, Medical College of Wisconsin, Milwaukee, WI 53226 3. Department of Pharmacology and Toxicology, Mississippi University Medical Center, Jackson, Mississippi 39216 4. Zablocki Veterans Affairs Medical Center, Milwaukee, Wisconsin 53295 * Correspondence author: [email protected], phone: 414-955-5745 1 bioRxiv preprint doi: https://doi.org/10.1101/2021.01.20.427483; this version posted January 21, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract Piezo2 mechanotransduction channel is a crucial mediator of sensory neurons for sensing and transducing touch, vibration, and proprioception. We here characterized Piezo2 expression and cell specificity in rat peripheral sensory pathway using a validated Piezo2 antibody. Immunohistochemistry using this antibody revealed Piezo2 expression in pan primary sensory neurons (PSNs) of dorsal rood ganglia (DRG) in naïve rats, which was actively transported along afferent axons to both central presynaptic terminals innervating the spinal dorsal horn (DH) and peripheral afferent terminals in skin. -

Centre for Arab Genomic Studies a Division of Sheikh Hamdan Award for Medical Sciences
Centre for Arab Genomic Studies A Division of Sheikh Hamdan Award for Medical Sciences The Catalogue for Transmission Genetics in Arabs CTGA Database Piezo-Type Mechanosensitive Ion Channel Component 2 Alternative Names autosomal recessive disorder of Distal PIEZO2 Arthrogryposis with Impaired Proprioception and Family with Sequence Similarity 38, Member B Touch (DAIPT). FAM38B Molecular Genetics Record Category The PIEZO2 gene is located on the short arm of Gene locus chromosome 18. It spans a length of 482 kb of DNA and its coding sequence is spread across 55 WHO-ICD exons. The protein product encoded by this gene N/A to gene loci has a molecular mass of 318 kDa and consists of 2752 amino acids. Several additional isoforms of Incidence per 100,000 Live Births the PIEZO2 protein exist due to alternatively N/A to gene loci spliced transcript variants. The gene is found to be overexpressed in the brain, spinal cord, pancreas, OMIM Number liver and lung. Heterozygous mutations in the 613629 PIEZO2 gene, including missense variants and deletions, have been linked to the disorders of Mode of Inheritance MWKS, DA3 and DA5. So far only one mutation N/A to gene loci (R2686C) has been identified in MWKS. Homozygous and compound heterozygous Gene Map Locus mutations in the gene associated with Distal 18p11.22-p11.21 Arthrogryposis, with Impaired Proprioception and Touch (DAIPT) mainly include nonsense variants Description and deletions that cause frameshift and premature The PIEZO2 gene encodes a large protein truncation, often resulting in a non-functioning containing 31 transmembrane domains. This protein PIEZO2 protein. -

Touching Upon Regulators of Piezo2 in Mouse Somatosensation
Touching upon regulators of Piezo2 in mouse somatosensation Dissertation for the award of the degree “Doctor rerum naturalium” (Dr.rer.nat.) of the Georg-August-Universität Göttingen within the International Max Planck Research School (IMPRS), Neuroscience of the Georg-August University School of Science (GAUSS) submitted by Pratibha Narayanan from New Delhi Göttingen, 2017 Thesis Committee Dr. Manuela Schmidt Somatosensory signaling and Systems Biology group, Max Planck Institute for Experimental Medicine Prof. Dr. Martin Göpfert Dept. of Cellular Neurobiology, Schwann- Schleiden Research Centre Prof. Dr. Luis A. Pardo Dept. of Molecular Biology of Neuronal Signals, Max Planck Institute for Experimental Medicine Members of the Examination Board Dr. Manuela Schmidt Somatosensory signaling and Systems Biology group, Max Planck Institute for Experimental Medicine Prof. Dr. Martin Göpfert Dept. of Cellular Neurobiology, Schwann- Schleiden Research Centre Further members of the Examination Board Prof. Dr. Luis A. Pardo Dept. of Molecular Biology of Neuronal Signals, Max Planck Institute of Experimental Medicine Prof. Dr. Tobias Moser Institute for Auditory Neuroscience & InnerEarLab Prof. Dr. Silvio O. Rizzoli Dept. of Neuro-and Sensory Physiology, University Medical Center Prof. Dr. Michael Sereda Molecular and Translational Neurology group, Max Planck Institute for Experimental Medicine Date of oral examination: 23 November 2017 TABLE OF CONTENTS List of figures.............................................................................................. -

The Genomic and Clinical Landscape of Fetal Akinesia
© American College of Medical Genetics and Genomics ARTICLE The genomic and clinical landscape of fetal akinesia Matthias Pergande, MSc1,2, Susanne Motameny, PhD3, Özkan Özdemir, PhD1,2, Mona Kreutzer1,2, Haicui Wang, PhD1,2, Hülya-Sevcan Daimagüler, MSc1,2, Kerstin Becker, PhD1,2, Mert Karakaya, MD1,4, Harald Ehrhardt, MD5, Nursel Elcioglu, MD, Prof6,7, Slavica Ostojic, MD8, Cho-Ming Chao, MD, PhD5, Amit Kawalia, PhD3, Özgür Duman, MD, Prof9, Anne Koy, MD2, Andreas Hahn, MD, Prof10, Jens Reimann, MD11, Katharina Schoner, MD12, Anne Schänzer, MD13, Jens H. Westhoff, MD14, Eva Maria Christina Schwaibold, MD15, Mireille Cossee, MD16, Marion Imbert-Bouteille, MSc17, Harald von Pein, MD18, Göknur Haliloglu, MD, Prof19, Haluk Topaloglu, MD, Prof19, Janine Altmüller, MD1,3, Peter Nürnberg, PhD, Prof1,3, Holger Thiele, MD3, Raoul Heller, MD, PhD4,20,21 and Sebahattin Cirak, MD 1,2,21 Purpose: Fetal akinesia has multiple clinical subtypes with over Conclusion: Our analysis indicates that genetic defects leading to 160 gene associations, but the genetic etiology is not yet completely primary skeletal muscle diseases might have been underdiagnosed, understood. especially pathogenic variants in RYR1. We discuss three novel Methods: In this study, 51 patients from 47 unrelated families putative fetal akinesia genes: GCN1, IQSEC3 and RYR3. Of those, were analyzed using next-generation sequencing (NGS) techniques IQSEC3, and RYR3 had been proposed as neuromuscular aiming to decipher the genomic landscape of fetal akinesia (FA). disease–associated genes recently, and our findings endorse them Results: We have identified likely pathogenic gene variants in 37 as FA candidate genes. By combining NGS with deep clinical cases and report 41 novel variants. -

A Genomic Approach to Delineating the Occurrence of Scoliosis in Arthrogryposis Multiplex Congenita
G C A T T A C G G C A T genes Article A Genomic Approach to Delineating the Occurrence of Scoliosis in Arthrogryposis Multiplex Congenita Xenia Latypova 1, Stefan Giovanni Creadore 2, Noémi Dahan-Oliel 3,4, Anxhela Gjyshi Gustafson 2, Steven Wei-Hung Hwang 5, Tanya Bedard 6, Kamran Shazand 2, Harold J. P. van Bosse 5 , Philip F. Giampietro 7,* and Klaus Dieterich 8,* 1 Grenoble Institut Neurosciences, Université Grenoble Alpes, Inserm, U1216, CHU Grenoble Alpes, 38000 Grenoble, France; [email protected] 2 Shriners Hospitals for Children Headquarters, Tampa, FL 33607, USA; [email protected] (S.G.C.); [email protected] (A.G.G.); [email protected] (K.S.) 3 Shriners Hospitals for Children, Montreal, QC H4A 0A9, Canada; [email protected] 4 School of Physical & Occupational Therapy, Faculty of Medicine and Health Sciences, McGill University, Montreal, QC H3G 2M1, Canada 5 Shriners Hospitals for Children, Philadelphia, PA 19140, USA; [email protected] (S.W.-H.H.); [email protected] (H.J.P.v.B.) 6 Alberta Congenital Anomalies Surveillance System, Alberta Health Services, Edmonton, AB T5J 3E4, Canada; [email protected] 7 Department of Pediatrics, University of Illinois-Chicago, Chicago, IL 60607, USA 8 Institut of Advanced Biosciences, Université Grenoble Alpes, Inserm, U1209, CHU Grenoble Alpes, 38000 Grenoble, France * Correspondence: [email protected] (P.F.G.); [email protected] (K.D.) Citation: Latypova, X.; Creadore, S.G.; Dahan-Oliel, N.; Gustafson, Abstract: Arthrogryposis multiplex congenita (AMC) describes a group of conditions characterized A.G.; Wei-Hung Hwang, S.; Bedard, by the presence of non-progressive congenital contractures in multiple body areas. -

Piezo2 in Cutaneous and Proprioceptive Mechanotransduction in Vertebratesa
ARTICLE IN PRESS Piezo2 in Cutaneous and Proprioceptive Mechanotransduction in Vertebratesa E.O. Anderson, E.R. Schneider and S.N. Bagriantsev1 Yale University, New Haven, CT, United States 1Corresponding author: E-mail: [email protected] Contents 1. Introduction 2 2. Somatosensory Neurons 4 2.1 Piezo2 and fast mechanoactivated current in mouse dorsal root ganglia 4 neurons 2.2 Possible role of Piezo2 in slow mechanoactivated current 6 2.3 Functional regulation of Piezo2 in mouse dorsal root ganglia neurons 7 3. Light Touch 8 3.1 Insights from mice 8 3.2 Insight from other vertebrates 9 4. Proprioception 11 5. Merkel Cells 12 6. Nociception 14 7. Conclusions and Perspectives 16 References 16 Abstract Mechanosensitivity is a fundamental physiological capacity, which pertains to all life forms. Progress has been made with regard to understanding mechanosensitivity in bacteria, flies, and worms. In vertebrates, however, the molecular identity of mechanotransducers in a This work was supported by grants from National Science Foundation (1453167), National Institutes of Health (1R01NS097547-01A1) and American Heart Association (14SDG17880015) to S.N.B. E.R.S. was partially supported by a training grant from National Institutes of Health T32HD007094 and a postdoctoral fellowship from the Arnold and Mabel Beckman Foundation. E.O.A. is a fellow of The Gruber Foundation and an Edward L. Tatum Fellow. Correspondence should be addressed to S.N.B ([email protected]). Current Topics in Membranes, Volume 79 ISSN 1063-5823 © 2016 Elsevier Inc. http://dx.doi.org/10.1016/bs.ctm.2016.11.002 All rights reserved. -

Peripheral Nerve Single-Cell Analysis Identifies Mesenchymal Ligands That Promote Axonal Growth
Research Article: New Research Development Peripheral Nerve Single-Cell Analysis Identifies Mesenchymal Ligands that Promote Axonal Growth Jeremy S. Toma,1 Konstantina Karamboulas,1,ª Matthew J. Carr,1,2,ª Adelaida Kolaj,1,3 Scott A. Yuzwa,1 Neemat Mahmud,1,3 Mekayla A. Storer,1 David R. Kaplan,1,2,4 and Freda D. Miller1,2,3,4 https://doi.org/10.1523/ENEURO.0066-20.2020 1Program in Neurosciences and Mental Health, Hospital for Sick Children, 555 University Avenue, Toronto, Ontario M5G 1X8, Canada, 2Institute of Medical Sciences University of Toronto, Toronto, Ontario M5G 1A8, Canada, 3Department of Physiology, University of Toronto, Toronto, Ontario M5G 1A8, Canada, and 4Department of Molecular Genetics, University of Toronto, Toronto, Ontario M5G 1A8, Canada Abstract Peripheral nerves provide a supportive growth environment for developing and regenerating axons and are es- sential for maintenance and repair of many non-neural tissues. This capacity has largely been ascribed to paracrine factors secreted by nerve-resident Schwann cells. Here, we used single-cell transcriptional profiling to identify ligands made by different injured rodent nerve cell types and have combined this with cell-surface mass spectrometry to computationally model potential paracrine interactions with peripheral neurons. These analyses show that peripheral nerves make many ligands predicted to act on peripheral and CNS neurons, in- cluding known and previously uncharacterized ligands. While Schwann cells are an important ligand source within injured nerves, more than half of the predicted ligands are made by nerve-resident mesenchymal cells, including the endoneurial cells most closely associated with peripheral axons. At least three of these mesen- chymal ligands, ANGPT1, CCL11, and VEGFC, promote growth when locally applied on sympathetic axons. -
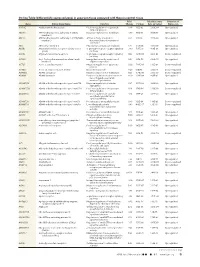
Differentially Expressed Genes in Aneurysm Tissue Compared With
On-line Table: Differentially expressed genes in aneurysm tissue compared with those in control tissue Fold False Discovery Direction of Gene Entrez Gene Name Function Change P Value Rate (q Value) Expression AADAC Arylacetamide deacetylase Positive regulation of triglyceride 4.46 1.33E-05 2.60E-04 Up-regulated catabolic process ABCA6 ATP-binding cassette, subfamily A (ABC1), Integral component of membrane 3.79 9.15E-14 8.88E-12 Up-regulated member 6 ABCC3 ATP-binding cassette, subfamily C (CFTR/MRP), ATPase activity, coupled to 6.63 1.21E-10 7.33E-09 Up-regulated member 3 transmembrane movement of substances ABI3 ABI family, member 3 Peptidyl-tyrosine phosphorylation 6.47 2.47E-05 4.56E-04 Up-regulated ACKR1 Atypical chemokine receptor 1 (Duffy blood G-protein–coupled receptor signaling 3.80 7.95E-10 4.18E-08 Up-regulated group) pathway ACKR2 Atypical chemokine receptor 2 G-protein–coupled receptor signaling 0.42 3.29E-04 4.41E-03 Down-regulated pathway ACSM1 Acyl-CoA synthetase medium-chain family Energy derivation by oxidation of 9.87 1.70E-08 6.52E-07 Up-regulated member 1 organic compounds ACTC1 Actin, ␣, cardiac muscle 1 Negative regulation of apoptotic 0.30 7.96E-06 1.65E-04 Down-regulated process ACTG2 Actin, ␥2, smooth muscle, enteric Blood microparticle 0.29 1.61E-16 2.36E-14 Down-regulated ADAM33 ADAM domain 33 Integral component of membrane 0.23 9.74E-09 3.95E-07 Down-regulated ADAM8 ADAM domain 8 Positive regulation of tumor necrosis 4.69 2.93E-04 4.01E-03 Up-regulated factor (ligand) superfamily member 11 production ADAMTS18