On the Practicality of Data-Oblivious Sorting Kris Vestergaard Ebbesen, 20094539
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Secure Multi-Party Sorting and Applications
Secure Multi-Party Sorting and Applications Kristján Valur Jónsson1, Gunnar Kreitz2, and Misbah Uddin2 1 Reykjavik University 2 KTH—Royal Institute of Technology Abstract. Sorting is among the most fundamental and well-studied problems within computer science and a core step of many algorithms. In this article, we consider the problem of constructing a secure multi-party computing (MPC) protocol for sorting, building on previous results in the field of sorting networks. Apart from the immediate uses for sorting, our protocol can be used as a building-block in more complex algorithms. We present a weighted set intersection algorithm, where each party inputs a set of weighted ele- ments and the output consists of the input elements with their weights summed. As a practical example, we apply our protocols in a network security setting for aggregation of security incident reports from multi- ple reporters, specifically to detect stealthy port scans in a distributed but privacy preserving manner. Both sorting and weighted set inter- section use O`n log2 n´ comparisons in O`log2 n´ rounds with practical constants. Our protocols can be built upon any secret sharing scheme supporting multiplication and addition. We have implemented and evaluated the performance of sorting on the Sharemind secure multi-party computa- tion platform, demonstrating the real-world performance of our proposed protocols. Keywords. Secure multi-party computation; Sorting; Aggregation; Co- operative anomaly detection 1 Introduction Intrusion Detection Systems (IDS) [16] are commonly used to detect anoma- lous and possibly malicious network traffic. Incidence reports and alerts from such systems are generally kept private, although much could be gained by co- operative sharing [30]. -

Kapitel 1 Einleitung
Kapitel 1 Einleitung 1.1 Parallele Rechenmodelle Ein Parallelrechner besteht aus einer Menge P = {P0,...,Pn−1} von Prozessoren und einem Kommunikationsmechanismus. Wir unterscheiden drei Typen von Kommunikationsmechanismen: a) Kommunikation ¨uber einen gemeinsamen Speicher Jeder Prozessor hat Lese- und Schreibzugriff auf die Speicherzellen eines großen ge- meinsamen Speichers (shared memory). Einen solchen Rechner nennen wir sha- red memory machine, Parallele Registermaschine oder Parallel Random Ac- cess Machine (PRAM). Dieses Modell zeichnet sich dadurch aus, daß es sehr kom- fortabel programmiert werden kann, da man sich auf das Wesentliche“ beschr¨anken ” kann, wenn man Algorithmen entwirft. Auf der anderen Seite ist es jedoch nicht (auf direktem Wege) realisierbar, ohne einen erheblichen Effizienzverlust dabei in Kauf neh- men zu mussen.¨ b) Kommunikation ¨uber Links Hier sind die Prozessoren gem¨aß einem ungerichteten Kommunikationsgraphen G = (P, E) untereinander zu einem Prozessornetzwerk (kurz: Netzwerk) verbunden. Die Kommunikation wird dabei folgendermaßen durchgefuhrt:¨ Jeder Prozessor Pi hat ein Lesefenster, auf das er Schreibzugriff hat. Falls {Pi,Pj} ∈ E ist, darf Pj im Lese- fenster von Pi lesen. Pi hat zudem ein Schreibfenster, auf das er Lesezugriff hat. Falls {Pi,Pj} ∈ E ist, darf Pj in das Schreibfenster von Pi schreiben. Zugriffskonflikte (gleichzeitiges Lesen und Schreiben im gleichen Fenster) k¨onnen auf verschiedene Arten gel¨ost werden. Wie dies geregelt wird, werden wir, wenn n¨otig, jeweils spezifizieren. Ebenso werden wir manchmal von der oben beschriebenen Kommunikation abweichen, wenn dadurch die Rechnungen vereinfacht werden k¨onnen. Auch darauf werden wir jeweils hinweisen. Die Zahl aller m¨oglichen Leitungen, die es in einem Netzwerk mit n Prozessoren geben n 10 kann, ist 2 . -

An Evolutionary Approach for Sorting Algorithms
ORIENTAL JOURNAL OF ISSN: 0974-6471 COMPUTER SCIENCE & TECHNOLOGY December 2014, An International Open Free Access, Peer Reviewed Research Journal Vol. 7, No. (3): Published By: Oriental Scientific Publishing Co., India. Pgs. 369-376 www.computerscijournal.org Root to Fruit (2): An Evolutionary Approach for Sorting Algorithms PRAMOD KADAM AND Sachin KADAM BVDU, IMED, Pune, India. (Received: November 10, 2014; Accepted: December 20, 2014) ABstract This paper continues the earlier thought of evolutionary study of sorting problem and sorting algorithms (Root to Fruit (1): An Evolutionary Study of Sorting Problem) [1]and concluded with the chronological list of early pioneers of sorting problem or algorithms. Latter in the study graphical method has been used to present an evolution of sorting problem and sorting algorithm on the time line. Key words: Evolutionary study of sorting, History of sorting Early Sorting algorithms, list of inventors for sorting. IntroDUCTION name and their contribution may skipped from the study. Therefore readers have all the rights to In spite of plentiful literature and research extent this study with the valid proofs. Ultimately in sorting algorithmic domain there is mess our objective behind this research is very much found in documentation as far as credential clear, that to provide strength to the evolutionary concern2. Perhaps this problem found due to lack study of sorting algorithms and shift towards a good of coordination and unavailability of common knowledge base to preserve work of our forebear platform or knowledge base in the same domain. for upcoming generation. Otherwise coming Evolutionary study of sorting algorithm or sorting generation could receive hardly information about problem is foundation of futuristic knowledge sorting problems and syllabi may restrict with some base for sorting problem domain1. -

Improving the Performance of Bubble Sort Using a Modified Diminishing Increment Sorting
Scientific Research and Essay Vol. 4 (8), pp. 740-744, August, 2009 Available online at http://www.academicjournals.org/SRE ISSN 1992-2248 © 2009 Academic Journals Full Length Research Paper Improving the performance of bubble sort using a modified diminishing increment sorting Oyelami Olufemi Moses Department of Computer and Information Sciences, Covenant University, P. M. B. 1023, Ota, Ogun State, Nigeria. E- mail: [email protected] or [email protected]. Tel.: +234-8055344658. Accepted 17 February, 2009 Sorting involves rearranging information into either ascending or descending order. There are many sorting algorithms, among which is Bubble Sort. Bubble Sort is not known to be a very good sorting algorithm because it is beset with redundant comparisons. However, efforts have been made to improve the performance of the algorithm. With Bidirectional Bubble Sort, the average number of comparisons is slightly reduced and Batcher’s Sort similar to Shellsort also performs significantly better than Bidirectional Bubble Sort by carrying out comparisons in a novel way so that no propagation of exchanges is necessary. Bitonic Sort was also presented by Batcher and the strong point of this sorting procedure is that it is very suitable for a hard-wired implementation using a sorting network. This paper presents a meta algorithm called Oyelami’s Sort that combines the technique of Bidirectional Bubble Sort with a modified diminishing increment sorting. The results from the implementation of the algorithm compared with Batcher’s Odd-Even Sort and Batcher’s Bitonic Sort showed that the algorithm performed better than the two in the worst case scenario. The implication is that the algorithm is faster. -

Algoritmi Za Sortiranje U Programskom Jeziku C++ Završni Rad
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Repository of the University of Rijeka SVEUČILIŠTE U RIJECI FILOZOFSKI FAKULTET U RIJECI ODSJEK ZA POLITEHNIKU Algoritmi za sortiranje u programskom jeziku C++ Završni rad Mentor završnog rada: doc. dr. sc. Marko Maliković Student: Alen Jakus Rijeka, 2016. SVEUČILIŠTE U RIJECI Filozofski fakultet Odsjek za politehniku Rijeka, Sveučilišna avenija 4 Povjerenstvo za završne i diplomske ispite U Rijeci, 07. travnja, 2016. ZADATAK ZAVRŠNOG RADA (na sveučilišnom preddiplomskom studiju politehnike) Pristupnik: Alen Jakus Zadatak: Algoritmi za sortiranje u programskom jeziku C++ Rješenjem zadatka potrebno je obuhvatiti sljedeće: 1. Napraviti pregled algoritama za sortiranje. 2. Opisati odabrane algoritme za sortiranje. 3. Dijagramima prikazati rad odabranih algoritama za sortiranje. 4. Opis osnovnih svojstava programskog jezika C++. 5. Detaljan opis tipova podataka, izvedenih oblika podataka, naredbi i drugih elemenata iz programskog jezika C++ koji se koriste u rješenjima odabranih problema. 6. Opis rješenja koja su dobivena iz napisanih programa. 7. Cjelokupan kôd u programskom jeziku C++. U završnom se radu obvezno treba pridržavati Pravilnika o diplomskom radu i Uputa za izradu završnog rada sveučilišnog dodiplomskog studija. Zadatak uručen pristupniku: 07. travnja 2016. godine Rok predaje završnog rada: ____________________ Datum predaje završnog rada: ____________________ Zadatak zadao: Doc. dr. sc. Marko Maliković 2 FILOZOFSKI FAKULTET U RIJECI Odsjek za politehniku U Rijeci, 07. travnja 2016. godine ZADATAK ZA ZAVRŠNI RAD (na sveučilišnom preddiplomskom studiju politehnike) Pristupnik: Alen Jakus Naslov završnog rada: Algoritmi za sortiranje u programskom jeziku C++ Kratak opis zadatka: Napravite pregled algoritama za sortiranje. Opišite odabrane algoritme za sortiranje. -

Parallel Sorting Algorithms + Topic Overview
+ Design of Parallel Algorithms Parallel Sorting Algorithms + Topic Overview n Issues in Sorting on Parallel Computers n Sorting Networks n Bubble Sort and its Variants n Quicksort n Bucket and Sample Sort n Other Sorting Algorithms + Sorting: Overview n One of the most commonly used and well-studied kernels. n Sorting can be comparison-based or noncomparison-based. n The fundamental operation of comparison-based sorting is compare-exchange. n The lower bound on any comparison-based sort of n numbers is Θ(nlog n) . n We focus here on comparison-based sorting algorithms. + Sorting: Basics What is a parallel sorted sequence? Where are the input and output lists stored? n We assume that the input and output lists are distributed. n The sorted list is partitioned with the property that each partitioned list is sorted and each element in processor Pi's list is less than that in Pj's list if i < j. + Sorting: Parallel Compare Exchange Operation A parallel compare-exchange operation. Processes Pi and Pj send their elements to each other. Process Pi keeps min{ai,aj}, and Pj keeps max{ai, aj}. + Sorting: Basics What is the parallel counterpart to a sequential comparator? n If each processor has one element, the compare exchange operation stores the smaller element at the processor with smaller id. This can be done in ts + tw time. n If we have more than one element per processor, we call this operation a compare split. Assume each of two processors have n/p elements. n After the compare-split operation, the smaller n/p elements are at processor Pi and the larger n/p elements at Pj, where i < j. -
Sorting Networks
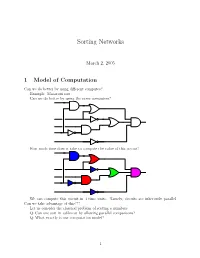
Sorting Networks March 2, 2005 1 Model of Computation Can we do better by using different computes? Example: Macaroni sort. Can we do better by using the same computers? How much time does it take to compute the value of this circuit? We can compute this circuit in 4 time units. Namely, circuits are inherently parallel. Can we take advantage of this??? Let us consider the classical problem of sorting n numbers. Q: Can one sort in sublinear by allowing parallel comparisons? Q: What exactly is our computation model? 1 1.1 Computing with a circuit We are going to design a circuit, where the inputs are the numbers, and we compare two numbers using a comparator gate: ¢¤¦© ¡ ¡ Comparator ¡£¢¥¤§¦©¨ ¡ For our drawings, we will draw such a gate as follows: ¢¡¤£¦¥¨§ © ¡£¦ So, circuits would just be horizontal lines, with vertical segments (i.e., gates) between them. A complete sorting network, looks like: The inputs come on the wires on the left, and are output on the wires on the right. The largest number is output on the bottom line. The surprising thing, is that one can generate circuits from a sorting algorithm. In fact, consider the following circuit: Q: What does this circuit does? A: This is the inner loop of insertion sort. Repeating this inner loop, we get the following sorting network: 2 Alternative way of drawing it: Q: How much time does it take for this circuit to sort the n numbers? Running time = how many time clocks we have to wait till the result stabilizes. In this case: 5 1 2 3 4 6 7 8 9 In general, we get: Lemma 1.1 Insertion sort requires 2n − 1 time units to sort n numbers. -

Foundations of Differentially Oblivious Algorithms
Foundations of Differentially Oblivious Algorithms T-H. Hubert Chan Kai-Min Chung Bruce Maggs Elaine Shi August 5, 2020 Abstract It is well-known that a program's memory access pattern can leak information about its input. To thwart such leakage, most existing works adopt the technique of oblivious RAM (ORAM) simulation. Such an obliviousness notion has stimulated much debate. Although ORAM techniques have significantly improved over the past few years, the concrete overheads are arguably still undesirable for real-world systems | part of this overhead is in fact inherent due to a well-known logarithmic ORAM lower bound by Goldreich and Ostrovsky. To make matters worse, when the program's runtime or output length depend on secret inputs, it may be necessary to perform worst-case padding to achieve full obliviousness and thus incur possibly super-linear overheads. Inspired by the elegant notion of differential privacy, we initiate the study of a new notion of access pattern privacy, which we call \(, δ)-differential obliviousness". We separate the notion of (, δ)-differential obliviousness from classical obliviousness by considering several fundamental algorithmic abstractions including sorting small-length keys, merging two sorted lists, and range query data structures (akin to binary search trees). We show that by adopting differential obliv- iousness with reasonable choices of and δ, not only can one circumvent several impossibilities pertaining to full obliviousness, one can also, in several cases, obtain meaningful privacy with little overhead relative to the non-private baselines (i.e., having privacy \almost for free"). On the other hand, we show that for very demanding choices of and δ, the same lower bounds for oblivious algorithms would be preserved for (, δ)-differential obliviousness. -

Selected Sorting Algorithms
Selected Sorting Algorithms CS 165: Project in Algorithms and Data Structures Michael T. Goodrich Some slides are from J. Miller, CSE 373, U. Washington Why Sorting? • Practical application – People by last name – Countries by population – Search engine results by relevance • Fundamental to other algorithms • Different algorithms have different asymptotic and constant-factor trade-offs – No single ‘best’ sort for all scenarios – Knowing one way to sort just isn’t enough • Many to approaches to sorting which can be used for other problems 2 Problem statement There are n comparable elements in an array and we want to rearrange them to be in increasing order Pre: – An array A of data records – A value in each data record – A comparison function • <, =, >, compareTo Post: – For each distinct position i and j of A, if i < j then A[i] ≤ A[j] – A has all the same data it started with 3 Insertion sort • insertion sort: orders a list of values by repetitively inserting a particular value into a sorted subset of the list • more specifically: – consider the first item to be a sorted sublist of length 1 – insert the second item into the sorted sublist, shifting the first item if needed – insert the third item into the sorted sublist, shifting the other items as needed – repeat until all values have been inserted into their proper positions 4 Insertion sort • Simple sorting algorithm. – n-1 passes over the array – At the end of pass i, the elements that occupied A[0]…A[i] originally are still in those spots and in sorted order. -

Bitonic Sorting Algorithm: a Review
International Journal of Computer Applications (0975 – 8887) Volume 113 – No. 13, March 2015 Bitonic Sorting Algorithm: A Review Megha Jain Sanjay Kumar V.K Patle S.O.S In CS & IT, S.O.S In CS & IT, S.O.S In CS & IT, PT. Ravi Shankar Shukla PT. Ravi Shankar Shukla PT. Ravi Shankar Shukla University, Raipur (C.G), India University, Raipur (C.G), India University, Raipur (C.G), India ABSTRACT 2.1 Bitonic Sequence The Batcher`s bitonic sorting algorithm is a parallel sorting A bitonic sequence of n elements ranges from x0,……,xn-1 algorithm, which is used for sorting the numbers in modern with characteristics (a) Existence of the index i, where 0 ≤ i ≤ parallel machines. There are various parallel sorting n-1, such that there exist monotonically increasing sequence algorithms such as radix sort, bitonic sort, etc. It is one of the from x0 to xi, and monotonically decreasing sequence from xi efficient parallel sorting algorithm because of load balancing to xn-1.(b) Existence of the cyclic shift of indices by which property. It is widely used in various scientific and characterics satisfy [10]. After applying the above engineering applications. However, Various researches have characteristics bitonic sequence occur. The bitonic split worked on a bitonic sorting algorithm in order to improve up operation is applied for producing two bitonic sequences on the performance of original batcher`s bitonic sorting which merge and sort operation is applied as shown in Fig 1. algorithm. In this paper, tried to review the contribution made by these researchers. 3. -

Advanced Topics in Sorting
Advanced Topics in Sorting complexity system sorts duplicate keys comparators 1 complexity system sorts duplicate keys comparators 2 Complexity of sorting Computational complexity. Framework to study efficiency of algorithms for solving a particular problem X. Machine model. Focus on fundamental operations. Upper bound. Cost guarantee provided by some algorithm for X. Lower bound. Proven limit on cost guarantee of any algorithm for X. Optimal algorithm. Algorithm with best cost guarantee for X. lower bound ~ upper bound Example: sorting. • Machine model = # comparisons access information only through compares • Upper bound = N lg N from mergesort. • Lower bound ? 3 Decision Tree a < b yes no code between comparisons (e.g., sequence of exchanges) b < c a < c yes no yes no a b c b a c a < c b < c yes no yes no a c b c a b b c a c b a 4 Comparison-based lower bound for sorting Theorem. Any comparison based sorting algorithm must use more than N lg N - 1.44 N comparisons in the worst-case. Pf. Assume input consists of N distinct values a through a . • 1 N • Worst case dictated by tree height h. N ! different orderings. • • (At least) one leaf corresponds to each ordering. Binary tree with N ! leaves cannot have height less than lg (N!) • h lg N! lg (N / e) N Stirling's formula = N lg N - N lg e N lg N - 1.44 N 5 Complexity of sorting Upper bound. Cost guarantee provided by some algorithm for X. Lower bound. Proven limit on cost guarantee of any algorithm for X. -

Sorting Algorithm 1 Sorting Algorithm
Sorting algorithm 1 Sorting algorithm In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order. Efficient sorting is important for optimizing the use of other algorithms (such as search and merge algorithms) that require sorted lists to work correctly; it is also often useful for canonicalizing data and for producing human-readable output. More formally, the output must satisfy two conditions: 1. The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order); 2. The output is a permutation, or reordering, of the input. Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement. For example, bubble sort was analyzed as early as 1956.[1] Although many consider it a solved problem, useful new sorting algorithms are still being invented (for example, library sort was first published in 2004). Sorting algorithms are prevalent in introductory computer science classes, where the abundance of algorithms for the problem provides a gentle introduction to a variety of core algorithm concepts, such as big O notation, divide and conquer algorithms, data structures, randomized algorithms, best, worst and average case analysis, time-space tradeoffs, and lower bounds. Classification Sorting algorithms used in computer science are often classified by: • Computational complexity (worst, average and best behaviour) of element comparisons in terms of the size of the list . For typical sorting algorithms good behavior is and bad behavior is .