Universal Mobile Service Execution Framework for Device-To-Device Collaborations" (2018)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Security to Android Mobile Applications: Camera Based
ISSN 2319-8885 Vol.04,Issue.29, August-2015, Pages:5534-5539 www.ijsetr.com Security to Android Mobile Applications: Camera Based Security and Theft Alert Mobile Phones 1 2 3 SANA SULTANA , G.VEERANJANEYULU , SALEHA FARHA 1PG Scholar, Dept of CSE, Shadan Women’s College of Engineering and Technology, Hyderabad, TS, India, E-mail: [email protected]. 2Professor, Dept of CSE, Shadan Women’s College of Engineering and Technology, Hyderabad, TS, India, E-mail: [email protected]. 3HOD, Dept of CSE, Shadan Women’s College of Engineering and Technology, Hyderabad, TS, India, E-mail: [email protected]. Abstract: Now Smartphone’s are simply small computers with added services such as GSM, radio. Thus it is true to say that next generations of operating system will be on these Smartphone and the likes of windows, IOS and android are showing us the glimpse of this future. Android has already gained significant advantages on its counterparts in terms of market share. One of the reason behind this is the most important feature of Android is that it is open-source which makes it free and allows any one person could develop their own applications and publish them freely. This openness of android brings the developers and users a wide range of convenience but simultaneously it increases the security issues. The major threat of Android users is Malware infection via Android Application Market which is targeting some loopholes in the architecture mainly on the end-users part. Attackers can implement spy cameras in malicious apps such that the phone camera is launched automatically without the device owner’s notice, and the captured photos and videos are sent out to these remote attackers. -

Building Vision and Voice Based Robots Using Android
1st Annual International Interdisciplinary Conference, AIIC 2013, 24-26 April, Azores, Portugal - Proceedings- BUILDING VISION AND VOICE BASED ROBOTS USING ANDROID Pradeep N. , Assistant Professor Dr. Mohammed Sharief, Professor Dr. M. Siddappa, Professor Dept. of Computer Science and Engineering, SSIT, Tumkur, Karnataka, India Abstract: This project uses Android, along with cloud based APIs and the Arduino microcontroller, to create a software-hardware system that attempts to address several current problems in robotics, including, among other things, line-following, obstacle-avoidance, voice control, voice synthesis, remote surveillance, motion & obstacle detection, face detection, remote live image streaming and remote photography in panorama & time-lapse mode. The rover, built upon a portable five-layered architecture, will use several mature and a few experimental algorithms in AI, Computer Vision, Robot Kinetics and Dynamics behind-the-scene to provide its prospective user in defense, entertainment or industrial sector a positive user experience. A minimal amount of security is achieved via. a handshake using MD5, SHA1 and AES. It even has a Twitter account for autonomous social networking. Key Words: Voice Synthesis, Voice Control, Robot-User Interaction, Face Detection, Motion and Object Detection, Remote Surveillance, Panoramic and Time-lapse Photography, Line-following and Obstacle-Avoiding Robotics, AI, Computer Vision, Image Processing, Network Security Introduction Android, which is actually a software stack, running atop the Linux kernel, is one of the most successful operating systems available to mobile users today. This success can be attributed to the fact that Android makes development of application softwares ('apps') really easy by allowing developers to code in Java (among many other languages) and thus enabling them to take advantage of the innumerable packages and modules made available by the Java community. -

User-Level Online Offloading Framework
ULOOF: USER-LEVEL ONLINE OFFLOADING FRAMEWORK JOSÉ LEAL DOMINGUES NETO ULOOF: USER-LEVEL ONLINE OFFLOADING FRAMEWORK Dissertação apresentada ao Programa de Pós- -Graduação em Ciência da Computação do Instituto de Ciências Exatas da Universidade Federal de Minas Gerais como requisito par- cial para a obtenção do grau de Mestre em Ciência da Computação. ORIENTADOR:JOSÉ MARCOS S. NOGUEIRA COORIENTADOR:DANIEL F. MACEDO Belo Horizonte Março de 2016 JOSÉ LEAL DOMINGUES NETO ULOOF: USER-LEVEL ONLINE OFFLOADING FRAMEWORK Dissertation presented to the Graduate Pro- gram in Computer Science of the Federal Uni- versity of Minas Gerais in partial fulfillment of the requirements for the degree of Master in Computer Science. ADVISOR:JOSÉ MARCOS S. NOGUEIRA CO-ADVISOR:DANIEL F. MACEDO Belo Horizonte March 2016 © 2016, José Leal Domingues Neto. Todos os direitos reservados Ficha catalográfica elaborada pela Biblioteca do ICEx UFMG Domingues Neto, José Leal. D671u Uloof: userlevel online offloading framework. / José Leal Domingues Neto. Belo Horizonte, 2016. xxiii, 96 f.: il.; 29 cm. Dissertação (mestrado) Universidade Federal de Minas Gerais – Departamento de Ciência da Computação. Orientador: José Marcos Silva Nogueira. Coorientador: Daniel Fernandes Macedo. 1. Computação – Teses. 2. Redes de computadores – Teses. 3. Computação em nuvem – Teses. I. Orientador. II. Coorientador. III. Título. CDU 519.6*22(043) Acknowledgments This work could not be completed without the support and love from many people across the world. I would like to firstly thank my mother and father. Mother, you are a true inspiration to me. Without your guidance, love and care I would not be able to glance back and cherish this joyful moment. -

AN3928, Web Server Using the MCF51CN Family and Freertos
Freescale Semiconductor Document Number: AN3928 Application Note Rev. 0, 08/2009 Web Server Using the MCF51CN Family and FreeRTOS by: Paolo Alcantara Applications Engineering RTAC Americas 1 Introduction Contents 1 Introduction . 1 This document describes a web server using the 2 Introduction to Web Server . 2 2.1 Hardware Implementation . 2 MCF51CN128, the open source RTOS FreeRTOS ® 2.2 Principle of Operation . 3 V5.3.0, and the TCP/IP stack lwIP V1.3.0. 3 Introduction to the Web Server Software. 5 3.1 Server Side Include (SSI) Support . 5 This document discusses the following implementations 3.2 Asynchronous JavaScript and XML (AJAX) . 7 on the MCF51CN128: 3.3 Common Gateway Interface (CGI) . 9 3.4 Tasks Status . 10 3.5 SD Card Support . 10 Web server with: 3.6 Limitations . 11 • Dynamic content 3.7 Principle of Operation . 11 4 Web Server Software . 11 •AJAX 4.1 Software Architecture . 11 4.2 Software Hierarchy . 12 • DHCP 4.2.1 Hardware Abstraction Layer (HAL) . 13 • File system (FAT16) 4.2.2 Fast Ethernet Controller (FEC) Handling . 13 4.2.3 Hardware Independent Layer (HIL) . 14 4.3 Socket Interface . 14 This document is intended to be used by all software 5 Web Server API. 15 development engineers, test engineers, and anyone else 6 Customization . 16 who needs to use an embedded web server. 7 Conclusion. 17 8 Considerations and References . 18 © Freescale Semiconductor, Inc., 2009. All rights reserved. Introduction to Web Server 2 Introduction to Web Server This web server software allows you to post information to the world wide web (WWW) that is easily viewable by a standard web browser. -

When Program Analysis Meets Bytecode Search: Targeted and Efficient Inter-Procedural Analysis of Modern Android Apps in Backdroid
When Program Analysis Meets Bytecode Search: Targeted and Efficient Inter-procedural Analysis of Modern Android Apps in BackDroid Daoyuan Wu1, Debin Gao2, Robert H. Deng2, and Rocky K. C. Chang3 1The Chinese University of Hong Kong 2Singapore Management University 3The Hong Kong Polytechnic University Contact: [email protected] Abstract—Widely-used Android static program analysis tools, be successfully analyzed by its underlying FlowDroid tool. e.g., Amandroid and FlowDroid, perform the whole-app inter- Although HSOMiner [53] increased the size of the analyzed procedural analysis that is comprehensive but fundamentally apps, the average app size is still only 8.4MB. Even for difficult to handle modern (large) apps. The average app size has these small apps, AppContext timed out for 16.1% of the increased three to four times over five years. In this paper, we 1,002 apps tested and HSOMiner similarly failed in 8.4% explore a new paradigm of targeted inter-procedural analysis that can skip irrelevant code and focus only on the flows of security- of 3,000 apps, causing a relatively high failure rate. Hence, sensitive sink APIs. To this end, we propose a technique called this is not only a performance issue, but also the detection on-the-fly bytecode search, which searches the disassembled app burden. Additionally, third-party libraries were often ignored. bytecode text just in time when a caller needs to be located. In this For example, Amandroid by default skipped the analysis of way, it guides targeted (and backward) inter-procedural analysis 139 popular libraries, such as AdMob, Flurry, and Facebook. -

Självständigt Arbete På Grundnivå Independent Degree Project - First Cycle
Självständigt arbete på grundnivå Independent degree project - first cycle Computer Engineering A framework for communicating with Android apps from the browser Karl Lindström A framework for communicating with Android apps from the browser Karl Lindström 2014-05-29 MID SWEDEN UNIVERSITY Avdelningen för Informations- och kommunikationssystem (IKS) Examiner: Ulf Jennehag, [email protected] Supervisor: Magnus Eriksson, [email protected] Author: Karl Lindström, [email protected] Degree programme: International Bachelor's Programme in Computer Engi- neering, 180 credits Main field of study: Computer Engineering Semester, year: 1, 2014 ii A framework for communicating with Android apps from the browser Karl Lindström 2014-05-29 Abstract With the recent growth of the mobile market, companies want to target mobile devices while at the same time keeping product development costs low. One way to do this is to develop web applications, which are accessed from a mobile de- vice’s web browser, instead of native applications. The same web application can then be used on different platforms such as Android and iOS. However, devices such as smart phones and tablets often include cameras and sensors that a web ap- plication may want to access, but which are only accessible from native applica- tions. A framework was developed that enables web applications to communicate with native Android applications. Native applications are launched by clicking a link in the browser, and the result produced is made available to the web applica- tion through a HTTP POST request or a local web server running on the device. Key characteristics of the framework include ease of extension and the ability to enable secure (SSL) communication if desired. -

Xerox® Versant® 80/180/280 Security Guide
Security Guide Xerox® Versant® 80/180/280 Press © 2020 Xerox Corporation. All rights reserved. Xerox is a trademark of Xerox Corporation in the United States and/or other countries. BR26398 Other company trademarks are also acknowledged. Document Version: 1.2 (October 2020). Copyright protection claimed includes all forms and matters of copyrightable material and information now allowed by statutory or judicial law or hereinafter granted including without limitation, material generated from the software programs which are displayed on the screen, such as icons, screen displays, looks, etc. Changes are periodically made to this document. Changes, technical inaccuracies, and typographic errors will be corrected in subsequent editions. Contents 1. Introduction ....................................................................................................................... 1-5 Purpose ........................................................................................................................................... 1-5 Target Audience .............................................................................................................................. 1-5 Disclaimer ....................................................................................................................................... 1-5 2. Product Description .......................................................................................................... 2-6 Physical Components .................................................................................................................... -

Modicon M340 for Ethernet Modicon M340 Hardware and Communication Requirements 31007131 04/2015
Modicon M340 for Ethernet 31007131 04/2015 Modicon M340 for Ethernet Communications Modules and Processors User Manual 04/2015 31007131.12 www.schneider-electric.com The information provided in this documentation contains general descriptions and/or technical characteristics of the performance of the products contained herein. This documentation is not intended as a substitute for and is not to be used for determining suitability or reliability of these products for specific user applications. It is the duty of any such user or integrator to perform the appropriate and complete risk analysis, evaluation and testing of the products with respect to the relevant specific application or use thereof. Neither Schneider Electric nor any of its affiliates or subsidiaries shall be responsible or liable for misuse of the information contained herein. If you have any suggestions for improvements or amendments or have found errors in this publication, please notify us. No part of this document may be reproduced in any form or by any means, electronic or mechanical, including photocopying, without express written permission of Schneider Electric. All pertinent state, regional, and local safety regulations must be observed when installing and using this product. For reasons of safety and to help ensure compliance with documented system data, only the manufacturer should perform repairs to components. When devices are used for applications with technical safety requirements, the relevant instructions must be followed. Failure to use Schneider Electric software or approved software with our hardware products may result in injury, harm, or improper operating results. Failure to observe this information can result in injury or equipment damage. -
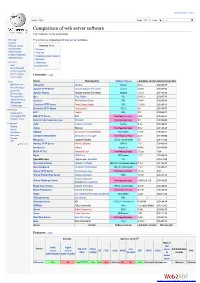
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

Infor LN UI 11.3 Sizing Guide
Infor LN UI 11.3 Sizing Guide Copyright © 2016 Infor Important Notices The material contained in this publication (including any supplementary information) constitutes and contains confidential and proprietary information of Infor. By gaining access to the attached, you acknowledge and agree that the material (including any modification, translation or adaptation of the material) and all copyright, trade secrets and all other right, title and interest therein, are the sole property of Infor and that you shall not gain right, title or interest in the material (including any modification, translation or adaptation of the material) by virtue of your review thereof other than the non-exclusive right to use the material solely in connection with and the furtherance of your license and use of software made available to your company from Infor pursuant to a separate agreement, the terms of which separate agreement shall govern your use of this material and all supplemental related materials ("Purpose"). In addition, by accessing the enclosed material, you acknowledge and agree that you are required to maintain such material in strict confidence and that your use of such material is limited to the Purpose described above. Although Infor has taken due care to ensure that the material included in this publication is accurate and complete, Infor cannot warrant that the information contained in this publication is complete, does not contain typographical or other errors, or will meet your specific requirements. As such, Infor does not assume and hereby disclaims all liability, consequential or otherwise, for any loss or damage to any person or entity which is caused by or relates to errors or omissions in this publication (including any supplementary information), whether such errors or omissions result from negligence, accident or any other cause. -

Computing Homomorphic Program Invariants Benjamin Robert Holland Iowa State University
Iowa State University Capstones, Theses and Graduate Theses and Dissertations Dissertations 2018 Computing homomorphic program invariants Benjamin Robert Holland Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/etd Part of the Computer Sciences Commons Recommended Citation Holland, Benjamin Robert, "Computing homomorphic program invariants" (2018). Graduate Theses and Dissertations. 16818. https://lib.dr.iastate.edu/etd/16818 This Dissertation is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Graduate Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. Computing homomorphic program invariants by Benjamin Robert Holland A dissertation submitted to the graduate faculty in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY Major: Computer Engineering (Secure and Reliable Computing) Program of Study Committee: Suraj Kothari, Co-major Professor Yong Guan, Co-major Professor Srikanta Tirthapura Hridesh Rajan Wei Le The student author, whose presentation of the scholarship herein was approved by the program of study committee, is solely responsible for the content of this dissertation. The Graduate College will ensure this dissertation is globally accessible and will not permit alterations after a degree is conferred. Iowa State University Ames, Iowa 2018 Copyright © Benjamin Robert Holland, 2018. All rights reserved. ii DEDICATION I would like to dedicate this work to my family, friends, colleagues, mentors, coworkers, and Amber. Without any of you this would not have been possible. -

Implementation of a Homematic Simulator Using Android
Fakultät für Informatik der Technische Universität München Bachelor’s Thesis in Informatics Implementation of a HomeMatic simulator using Android Johannes Neutze Fakultät für Informatik der Technische Universität München Bachelor’s Thesis in Informatics Implementation of a HomeMatic simulator using Android Implementierung eines HomeMatic Simulators unter Android Author: Johannes Neutze Supervisor: Prof. Dr. Uwe Baumgarten Advisor: Nils T. Kannengießer, M. Sc. Date: April 15, 2013 I assure the single handed composition of this bachelor thesis only supported by declared resources. Munich, 15th of April, 2013 Johannes Neutze Abstract This bachelor thesis is about the development of an Android application, simulating the HomeMatic system and the XMLAPI v1.2, designed to control the HomeMatic system, e.g. through the HomeDroid client. Configuration of the system, handshake with HomeDroid and persistent storage of the entire system status is implemented by using standard components, like a HTTP server, a relational database and an Android graphical user interface. As a result, the user can connect to the application via HomeDroid and interact with it, like with the real hardware. First, the foundation of emulated system and the environment used to develop the application, are explained. Then the system requirements are outlined and the architecture is illustrated. Finally, the implementation of each component, the graphical user interface and its testing are described. Table of contents Abstract.....................................................................................................................................