Developing Remote Clients for Oracle Coherence
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

User-Level Online Offloading Framework
ULOOF: USER-LEVEL ONLINE OFFLOADING FRAMEWORK JOSÉ LEAL DOMINGUES NETO ULOOF: USER-LEVEL ONLINE OFFLOADING FRAMEWORK Dissertação apresentada ao Programa de Pós- -Graduação em Ciência da Computação do Instituto de Ciências Exatas da Universidade Federal de Minas Gerais como requisito par- cial para a obtenção do grau de Mestre em Ciência da Computação. ORIENTADOR:JOSÉ MARCOS S. NOGUEIRA COORIENTADOR:DANIEL F. MACEDO Belo Horizonte Março de 2016 JOSÉ LEAL DOMINGUES NETO ULOOF: USER-LEVEL ONLINE OFFLOADING FRAMEWORK Dissertation presented to the Graduate Pro- gram in Computer Science of the Federal Uni- versity of Minas Gerais in partial fulfillment of the requirements for the degree of Master in Computer Science. ADVISOR:JOSÉ MARCOS S. NOGUEIRA CO-ADVISOR:DANIEL F. MACEDO Belo Horizonte March 2016 © 2016, José Leal Domingues Neto. Todos os direitos reservados Ficha catalográfica elaborada pela Biblioteca do ICEx UFMG Domingues Neto, José Leal. D671u Uloof: userlevel online offloading framework. / José Leal Domingues Neto. Belo Horizonte, 2016. xxiii, 96 f.: il.; 29 cm. Dissertação (mestrado) Universidade Federal de Minas Gerais – Departamento de Ciência da Computação. Orientador: José Marcos Silva Nogueira. Coorientador: Daniel Fernandes Macedo. 1. Computação – Teses. 2. Redes de computadores – Teses. 3. Computação em nuvem – Teses. I. Orientador. II. Coorientador. III. Título. CDU 519.6*22(043) Acknowledgments This work could not be completed without the support and love from many people across the world. I would like to firstly thank my mother and father. Mother, you are a true inspiration to me. Without your guidance, love and care I would not be able to glance back and cherish this joyful moment. -

AN3928, Web Server Using the MCF51CN Family and Freertos
Freescale Semiconductor Document Number: AN3928 Application Note Rev. 0, 08/2009 Web Server Using the MCF51CN Family and FreeRTOS by: Paolo Alcantara Applications Engineering RTAC Americas 1 Introduction Contents 1 Introduction . 1 This document describes a web server using the 2 Introduction to Web Server . 2 2.1 Hardware Implementation . 2 MCF51CN128, the open source RTOS FreeRTOS ® 2.2 Principle of Operation . 3 V5.3.0, and the TCP/IP stack lwIP V1.3.0. 3 Introduction to the Web Server Software. 5 3.1 Server Side Include (SSI) Support . 5 This document discusses the following implementations 3.2 Asynchronous JavaScript and XML (AJAX) . 7 on the MCF51CN128: 3.3 Common Gateway Interface (CGI) . 9 3.4 Tasks Status . 10 3.5 SD Card Support . 10 Web server with: 3.6 Limitations . 11 • Dynamic content 3.7 Principle of Operation . 11 4 Web Server Software . 11 •AJAX 4.1 Software Architecture . 11 4.2 Software Hierarchy . 12 • DHCP 4.2.1 Hardware Abstraction Layer (HAL) . 13 • File system (FAT16) 4.2.2 Fast Ethernet Controller (FEC) Handling . 13 4.2.3 Hardware Independent Layer (HIL) . 14 4.3 Socket Interface . 14 This document is intended to be used by all software 5 Web Server API. 15 development engineers, test engineers, and anyone else 6 Customization . 16 who needs to use an embedded web server. 7 Conclusion. 17 8 Considerations and References . 18 © Freescale Semiconductor, Inc., 2009. All rights reserved. Introduction to Web Server 2 Introduction to Web Server This web server software allows you to post information to the world wide web (WWW) that is easily viewable by a standard web browser. -

Xerox® Versant® 80/180/280 Security Guide
Security Guide Xerox® Versant® 80/180/280 Press © 2020 Xerox Corporation. All rights reserved. Xerox is a trademark of Xerox Corporation in the United States and/or other countries. BR26398 Other company trademarks are also acknowledged. Document Version: 1.2 (October 2020). Copyright protection claimed includes all forms and matters of copyrightable material and information now allowed by statutory or judicial law or hereinafter granted including without limitation, material generated from the software programs which are displayed on the screen, such as icons, screen displays, looks, etc. Changes are periodically made to this document. Changes, technical inaccuracies, and typographic errors will be corrected in subsequent editions. Contents 1. Introduction ....................................................................................................................... 1-5 Purpose ........................................................................................................................................... 1-5 Target Audience .............................................................................................................................. 1-5 Disclaimer ....................................................................................................................................... 1-5 2. Product Description .......................................................................................................... 2-6 Physical Components .................................................................................................................... -

Modicon M340 for Ethernet Modicon M340 Hardware and Communication Requirements 31007131 04/2015
Modicon M340 for Ethernet 31007131 04/2015 Modicon M340 for Ethernet Communications Modules and Processors User Manual 04/2015 31007131.12 www.schneider-electric.com The information provided in this documentation contains general descriptions and/or technical characteristics of the performance of the products contained herein. This documentation is not intended as a substitute for and is not to be used for determining suitability or reliability of these products for specific user applications. It is the duty of any such user or integrator to perform the appropriate and complete risk analysis, evaluation and testing of the products with respect to the relevant specific application or use thereof. Neither Schneider Electric nor any of its affiliates or subsidiaries shall be responsible or liable for misuse of the information contained herein. If you have any suggestions for improvements or amendments or have found errors in this publication, please notify us. No part of this document may be reproduced in any form or by any means, electronic or mechanical, including photocopying, without express written permission of Schneider Electric. All pertinent state, regional, and local safety regulations must be observed when installing and using this product. For reasons of safety and to help ensure compliance with documented system data, only the manufacturer should perform repairs to components. When devices are used for applications with technical safety requirements, the relevant instructions must be followed. Failure to use Schneider Electric software or approved software with our hardware products may result in injury, harm, or improper operating results. Failure to observe this information can result in injury or equipment damage. -
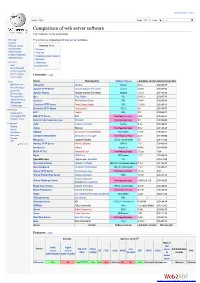
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

Infor LN UI 11.3 Sizing Guide
Infor LN UI 11.3 Sizing Guide Copyright © 2016 Infor Important Notices The material contained in this publication (including any supplementary information) constitutes and contains confidential and proprietary information of Infor. By gaining access to the attached, you acknowledge and agree that the material (including any modification, translation or adaptation of the material) and all copyright, trade secrets and all other right, title and interest therein, are the sole property of Infor and that you shall not gain right, title or interest in the material (including any modification, translation or adaptation of the material) by virtue of your review thereof other than the non-exclusive right to use the material solely in connection with and the furtherance of your license and use of software made available to your company from Infor pursuant to a separate agreement, the terms of which separate agreement shall govern your use of this material and all supplemental related materials ("Purpose"). In addition, by accessing the enclosed material, you acknowledge and agree that you are required to maintain such material in strict confidence and that your use of such material is limited to the Purpose described above. Although Infor has taken due care to ensure that the material included in this publication is accurate and complete, Infor cannot warrant that the information contained in this publication is complete, does not contain typographical or other errors, or will meet your specific requirements. As such, Infor does not assume and hereby disclaims all liability, consequential or otherwise, for any loss or damage to any person or entity which is caused by or relates to errors or omissions in this publication (including any supplementary information), whether such errors or omissions result from negligence, accident or any other cause. -

Developing Remote Clients for Oracle Coherence
Oracle® Fusion Middleware Developing Remote Clients for Oracle Coherence 14c (14.1.1.0.0) F23524-03 November 2020 Oracle Fusion Middleware Developing Remote Clients for Oracle Coherence, 14c (14.1.1.0.0) F23524-03 Copyright © 2008, 2020, Oracle and/or its affiliates. Primary Author: Oracle Corporation This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial -

TIBCO Gridserver?? Installation Guide
TIBCO GridServer® Installation Guide Software Release 6.2 November 2014 Two-Second Advantage® Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE. USE OF SUCH EMBEDDED OR BUNDLED TIBCO SOFTWARE IS SOLELY TO ENABLE THE FUNCTIONALITY (OR PROVIDE LIMITED ADD-ON FUNCTIONALITY) OF THE LICENSED TIBCO SOFTWARE. THE EMBEDDED OR BUNDLED SOFTWARE IS NOT LICENSED TO BE USED OR ACCESSED BY ANY OTHER TIBCO SOFTWARE OR FOR ANY OTHER PURPOSE. USE OF TIBCO SOFTWARE AND THIS DOCUMENT IS SUBJECT TO THE TERMS AND CONDITIONS OF A LICENSE AGREEMENT FOUND IN EITHER A SEPARATELY EXECUTED SOFTWARE LICENSE AGREEMENT, OR, IF THERE IS NO SUCH SEPARATE AGREEMENT, THE CLICKWRAP END USER LICENSE AGREEMENT WHICH IS DISPLAYED DURING DOWNLOAD OR INSTALLATION OF THE SOFTWARE (AND WHICH IS DUPLICATED IN THE LICENSE FILE) OR IF THERE IS NO SUCH SOFTWARE LICENSE AGREEMENT OR CLICKWRAP END USER LICENSE AGREEMENT, THE LICENSE(S) LOCATED IN THE “LICENSE” FILE(S) OF THE SOFTWARE. USE OF THIS DOCUMENT IS SUBJECT TO THOSE TERMS AND CONDITIONS, AND YOUR USE HEREOF SHALL CONSTITUTE ACCEPTANCE OF AND AN AGREEMENT TO BE BOUND BY THE SAME. This document contains confidential information that is subject to U.S. and international copyright laws and treaties. No part of this document may be reproduced in any form without the written authorization of TIBCO Software Inc. TIBCO, Two-Second Advantage, GridServer, FabricServer, GridClient, GridBroker, FabricBroker, LiveCluster, VersaUtility, VersaVision, SpeedLink, Federator, and RTI Design are either registered trademarks or trademarks of TIBCO Software Inc. in the United States and/or other countries. EJB, Java EE, J2EE, and all Java-based trademarks and logos are trademarks or registered trademarks of Sun Microsystems, Inc. -

RZ/A1LU Group Stream It! Web Server Demonstration
Application Note RZ/A1LU Group Stream it! - RZ Web Server Demonstration Introduction This application note describes how to configure the Stream it! - RZ V2 kit (hardware) and install the tools to run the Oryx Web Server demo supplied as part of the Stream it! - RZ kit The application, which is running on the Stream it! - RZ V2 board, hosts a web server implementation using the TCP/IP stack from Oryx. By default, the contents of the website which is hosted on the Stream it! - RZ hardware provides the following pages: • Page 1 Ajax Demo 1 This demonstration application reads the position of the potentiometer and acquires raw acceleration data from the multi-axis MEMS. This web page uses Ajax (Asynchronous JavaScript and XML) to update itself periodically. • Page 2 Ajax Demo 2 The cube follows the inclination of the board. Just tilt the board up with your hand! The joystick and the potentiometer can also be used, respectively for translation and spinning. • Page 3 CGI Demo The web server supports SSI (Server-Sides Includes) and CGI scripting for dynamic contents. The following properties are dynamically generated each time the page is refreshed (press F5). If your system supports IPv6, try to access the server using its IPv6 link-local address or global address and discover your own IPv6 host address! • Page 4 SMTP Demo If your LAN is connected to the Internet, this form allows you to send an e-mail. Fill in the required fields and press the ‘Send’ button. It may take a few seconds to complete the operation if your SMTP server requires secure SSL/TLS connection. -
Controlling and Monitoring of Servo Motor Through Embedded Http Server on Arm Board
CONTROLLING AND MONITORING OF SERVO MOTOR THROUGH EMBEDDED HTTP SERVER ON ARM BOARD By MOHD HARIZ BIN MOHD RIFAN Submitted to the Department of Electrical & Electronic Engineering in Partial Fulfillment of the Requirements for the Degree Bachelor of Engineering (Hons) (Electrical and Electronics Engineering) UniversitiTeknologi PETRONAS Bandar Seri Iskandar 31750 Tronoh Perak Darul Ridzuan Copyright 2013 by Mohd Hariz bin Mohd Rifan, 2013 ii CERTIFICATION OF APPROVAL Controlling and Monitoring of Servo Motor through Embedded HTTP Server on ARM Board by Mohd Hariz bin Mohd Rifan A project dissertation submitted to the Electrical & Electronics Engineering Programme Universiti Teknologi PETRONAS in partial fulfillment of the requirement for the Bachelor of Engineering (Hons) (Electrical and Electronics Engineering) Approved by, _______________________ (Dr. Mohd Zuki bin Yusoff) Project Supervisor UNIVERSITI TEKNOLOGI PETRONAS TRONOH, PERAK May 2013 iii CERTIFICATION OF ORIGINALITY This is to certify that I am responsible for the work submitted in this project, that the original work is my own except as specified in the references and acknowledgements, and that the original work contained herein have not been undertaken or done by unspecified sources or persons. _____________________________ (MOHD HARIZ BIN MOHD RIFAN) iv ABSTRACT The positioning of servo motor is controlled by sourcing the servo with PWM signal of varying pulse width. The pulse width of the PWM signal can be manipulated through a web interface hosted on ARM board programmed as an embedded HTTP server where control application by an embedded system can be monitored and managed remotely. Embedded HTTP server network stack is based on modified TCP/IP protocol suite where only important features are used. -

Cherrypy Documentation
CherryPy Documentation CherryPy Team Jul 03, 2021 CONTENTS 1 Foreword 1 1.1 Why CherryPy?.............................................1 1.2 Success Stories..............................................2 2 Installation 5 2.1 Requirements...............................................5 2.2 Supported python version........................................6 2.3 Installing.................................................6 2.4 Run it...................................................6 3 Tutorials 9 3.1 Tutorial 1: A basic web application................................... 10 3.2 Tutorial 2: Different URLs lead to different functions.......................... 11 3.3 Tutorial 3: My URLs have parameters.................................. 11 3.4 Tutorial 4: Submit this form....................................... 12 3.5 Tutorial 5: Track my end-user’s activity................................. 13 3.6 Tutorial 6: What about my javascripts, CSS and images?........................ 14 3.7 Tutorial 7: Give us a REST....................................... 16 3.8 Tutorial 8: Make it smoother with Ajax................................. 18 3.9 Tutorial 9: Data is all my life....................................... 21 3.10 Tutorial 10: Make it a modern single-page application with React.js.................. 23 3.11 Tutorial 11: Organize my code...................................... 27 3.12 Tutorial 12: Using pytest and code coverage............................... 28 4 Basics 31 4.1 The one-minute application example................................... 32 4.2 Hosting -

Spring Data Gemfire Reference Guide
Spring Data GemFire Reference Guide Costin Leau , David Turanski , John Blum , Oliver Gierke Version 2.0.5.RELEASE, 2018-02-28 Table of Contents Preface. 2 1. Introduction . 3 2. Requirements . 4 3. New Features . 5 3.1. New in the 1.2 Release. 5 3.2. New in the 1.3 Release. 5 3.3. New in the 1.4 Release. 6 3.4. New in the 1.5 Release. 7 3.5. New in the 1.6 Release. 7 3.6. New in the 1.7 Release. 7 3.7. New in the 1.8 Release. 8 3.8. New in the 1.9 Release. 9 3.9. New in the 2.0 Release. 9 Reference Guide . 10 4. Document Structure . 11 5. Bootstrapping Pivotal GemFire with the Spring container . 12 5.1. Advantages of using Spring over Pivotal GemFire cache.xml . 12 5.2. Using the Core Namespace. 12 5.3. Using the Data Access Namespace . 14 5.3.1. An Easy Way to Connect to GemFire . 14 5.4. Configuring a Cache . 15 5.4.1. Advanced Cache Configuration. 17 5.4.2. Configuring a GemFire CacheServer . 20 5.4.3. Configuring a GemFire ClientCache. 21 5.5. Configuring a Region. 24 5.5.1. Using an externally configured Region. 24 5.5.2. Auto Region Lookup. 25 5.5.3. Configuring Regions. 26 5.5.4. Compression . 30 5.5.5. Subregions . 30 5.5.6. Region Templates . 31 5.5.7. Data Eviction (with Overflow). 36 5.5.8. Data Expiration . 36 5.5.9.