Burst-Dependent Synaptic Plasticity Can Coordinate Learning in Hierarchical Circuits
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Interactions Among Diameter, Myelination, and the Na/K Pump Affect Axonal Resilience to High-Frequency Spiking
Interactions among diameter, myelination, and the Na/K pump affect axonal resilience to high-frequency spiking Yunliang Zanga,b and Eve Mardera,b,1 aVolen National Center for Complex Systems, Brandeis University, Waltham, MA 02454; and bDepartment of Biology, Brandeis University, Waltham, MA 02454 Contributed by Eve Marder, June 22, 2021 (sent for review March 25, 2021; reviewed by Carmen C. Canavier and Steven A. Prescott) Axons reliably conduct action potentials between neurons and/or (16–21). It remains unknown how these directly correlated pro- other targets. Axons have widely variable diameters and can be cesses, fast spiking and slow Na+ removal, interact in the control myelinated or unmyelinated. Although the effect of these factors of reliable spike generation and propagation. Furthermore, it is on propagation speed is well studied, how they constrain axonal unclear whether reducing Na+-andK+-current overlap can con- resilience to high-frequency spiking is incompletely understood. sistently decrease the rate of Na+ influx and accordingly enhance Maximal firing frequencies range from ∼1Hzto>300 Hz across axonal reliability to propagate high-frequency spikes. Conse- neurons, but the process by which Na/K pumps counteract Na+ quently, by modeling the process of Na+ removal in unmyelinated influx is slow, and the extent to which slow Na+ removal is com- and myelinated axons, we systematically explored the effects of patible with high-frequency spiking is unclear. Modeling the pro- diameter, myelination, and Na/K pump density on spike propagation cess of Na+ removal shows that large-diameter axons are more reliability. resilient to high-frequency spikes than are small-diameter axons, because of their slow Na+ accumulation. -

Energy Expenditure Computation of a Single Bursting Neuron
Cognitive Neurodynamics (2019) 13:75–87 https://doi.org/10.1007/s11571-018-9503-3 (0123456789().,-volV)(0123456789().,-volV) ORIGINAL ARTICLE Energy expenditure computation of a single bursting neuron 2 1,2 2 2 Fengyun Zhu • Rubin Wang • Xiaochuan Pan • Zhenyu Zhu Received: 17 October 2017 / Revised: 22 August 2018 / Accepted: 28 August 2018 / Published online: 3 September 2018 Ó The Author(s) 2018 Abstract Brief bursts of high-frequency spikes are a common firing pattern of neurons. The cellular mechanisms of bursting and its biological significance remain a matter of debate. Focusing on the energy aspect, this paper proposes a neural energy calculation method based on the Chay model of bursting. The flow of ions across the membrane of the bursting neuron with or without current stimulation and its power which contributes to the change of the transmembrane electrical potential energy are analyzed here in detail. We find that during the depolarization of spikes in bursting this power becomes negative, which was also discovered in previous research with another energy model. We also find that the neuron’s energy consumption during bursting is minimal. Especially in the spontaneous state without stimulation, the total energy con- sumption (2.152 9 10-7 J) during 30 s of bursting is very similar to the biological energy consumption (2.468 9 10-7 J) during the generation of a single action potential, as shown in Wang et al. (Neural Plast 2017, 2017a). Our results suggest that this property of low energy consumption could simply be the consequence of the biophysics of generating bursts, which is consistent with the principle of energy minimization. -

Neuromodulators and Long-Term Synaptic Plasticity in Learning and Memory: a Steered-Glutamatergic Perspective
brain sciences Review Neuromodulators and Long-Term Synaptic Plasticity in Learning and Memory: A Steered-Glutamatergic Perspective Amjad H. Bazzari * and H. Rheinallt Parri School of Life and Health Sciences, Aston University, Birmingham B4 7ET, UK; [email protected] * Correspondence: [email protected]; Tel.: +44-(0)1212044186 Received: 7 October 2019; Accepted: 29 October 2019; Published: 31 October 2019 Abstract: The molecular pathways underlying the induction and maintenance of long-term synaptic plasticity have been extensively investigated revealing various mechanisms by which neurons control their synaptic strength. The dynamic nature of neuronal connections combined with plasticity-mediated long-lasting structural and functional alterations provide valuable insights into neuronal encoding processes as molecular substrates of not only learning and memory but potentially other sensory, motor and behavioural functions that reflect previous experience. However, one key element receiving little attention in the study of synaptic plasticity is the role of neuromodulators, which are known to orchestrate neuronal activity on brain-wide, network and synaptic scales. We aim to review current evidence on the mechanisms by which certain modulators, namely dopamine, acetylcholine, noradrenaline and serotonin, control synaptic plasticity induction through corresponding metabotropic receptors in a pathway-specific manner. Lastly, we propose that neuromodulators control plasticity outcomes through steering glutamatergic transmission, thereby gating its induction and maintenance. Keywords: neuromodulators; synaptic plasticity; learning; memory; LTP; LTD; GPCR; astrocytes 1. Introduction A huge emphasis has been put into discovering the molecular pathways that govern synaptic plasticity induction since it was first discovered [1], which markedly improved our understanding of the functional aspects of plasticity while introducing a surprisingly tremendous complexity due to numerous mechanisms involved despite sharing common “glutamatergic” mediators [2]. -

Review Article Mechanisms of Cerebrovascular Autoregulation and Spreading Depolarization-Induced Autoregulatory Failure: a Literature Review
Int J Clin Exp Med 2016;9(8):15058-15065 www.ijcem.com /ISSN:1940-5901/IJCEM0026645 Review Article Mechanisms of cerebrovascular autoregulation and spreading depolarization-induced autoregulatory failure: a literature review Gang Yuan1*, Bingxue Qi2*, Qi Luo1 1Department of Neurosurgery, The First Hospital of Jilin University, Changchun, China; 2Department of Endocrinology, Jilin Province People’s Hospital, Changchun, China. *Equal contributors. Received February 25, 2016; Accepted June 4, 2016; Epub August 15, 2016; Published August 30, 2016 Abstract: Cerebrovascular autoregulation maintains brain hemostasis via regulating cerebral flow when blood pres- sure fluctuation occurs. Monitoring autoregulation can be achieved by transcranial Doppler ultrasonography, the pressure reactivity index (PRx) can serve as a secondary index of vascular deterioration, and outcome and prognosis are assessed by the low-frequency PRx. Although great changes in arterial blood pressure (ABP) occur, complex neu- rogenic, myogenic, endothelial, and metabolic mechanisms are involved to maintain the flow within its narrow limits. The steady association between ABP and cerebral blood flow (CBF) reflects static cerebral autoregulation (CA). Spreading depolarization (SD) is a sustained depolarization of neurons with concomitant pronounced breakdown of ion gradients, which originates in patients with brain ischemia, hemorrhage, trauma, and migraine. It is character- ized by the propagation of an extracellular negative potential, followed by an increase in O2 and glucose consump- tion. Immediately after SD, CA is transiently impaired but is restored after 35 min. This process initiates a cascade of pathophysiological mechanisms, leading to neuronal damage and loss if consecutive events are evoked. The clini- cal application of CA in regulating CBF is to dilate the cerebral arteries as a compensatory mechanism during low blood pressure, thus protecting the brain from ischemia. -

Characteristics of Hippocampal Primed Burst Potentiation in Vitro and in the Awake Rat
The Journal of Neuroscience, November 1988, 8(11): 4079-4088 Characteristics of Hippocampal Primed Burst Potentiation in vitro and in the Awake Rat D. M. Diamond, T. V. Dunwiddie, and G. M. Rose Medical Research Service, Veterans Administration Medical Center, and Department of Pharmacology, University of Colorado Health Sciences Center, Denver, Colorado 80220 A pattern of electrical stimulation based on 2 prominent (McNaughton, 1983; Lynch and Baudry, 1984; Farley and Al- physiological features of the hippocampus, complex spike kon, 1985; Byrne, 1987). Of these, a phenomenontermed long- discharge and theta rhythm, was used to induce lasting in- term potentiation (LTP) has received extensive attention be- creases in responses recorded in area CA1 of hippocampal causeit sharesa number of characteristicswith memory. For slices maintained in vitro and from the hippocampus of be- example, LTP has a rapid onset and long duration and is having rats. This effect, termed primed burst (PB) potentia- strengthenedby repetition (Barnes, 1979; Teyler and Discenna, tion, was elicited by as few as 3 stimuli delivered to the 1987). In addition, the decay of LTP is correlated with the time commissural/associational afferents to CAl. The patterns courseof behaviorally assessedforgetting (Barnes, 1979; Barnes of stimulus presentation consisted of a single priming pulse and McNaughton, 1985). The similarity of LTP and memory followed either 140 or 170 msec later by a high-frequency has fostered an extensive characterization of the conditions un- burst of 2-10 pulses; control stimulation composed of un- derlying the initiation of LTP, as well as its biochemical sub- primed high-frequency trains of up to 10 pulses had no en- strates (Lynch and Baudry, 1984; Wigstrijm and Gustafsson, during effect. -

The Logic Behind Neural Control of Breathing Pattern Alona Ben-Tal 1, Yunjiao Wang2 & Maria C
www.nature.com/scientificreports OPEN The logic behind neural control of breathing pattern Alona Ben-Tal 1, Yunjiao Wang2 & Maria C. A. Leite3 The respiratory rhythm generator is spectacular in its ability to support a wide range of activities and Received: 10 January 2019 adapt to changing environmental conditions, yet its operating mechanisms remain elusive. We show Accepted: 29 May 2019 how selective control of inspiration and expiration times can be achieved in a new representation of Published: xx xx xxxx the neural system (called a Boolean network). The new framework enables us to predict the behavior of neural networks based on properties of neurons, not their values. Hence, it reveals the logic behind the neural mechanisms that control the breathing pattern. Our network mimics many features seen in the respiratory network such as the transition from a 3-phase to 2-phase to 1-phase rhythm, providing novel insights and new testable predictions. Te mechanism for generating and controlling the breathing pattern by the respiratory neural circuit has been debated for some time1–6. In 1991, an area of the brainstem, the pre Bötzinger Complex (preBötC), was found essential for breathing7. An isolated single PreBötC neuron could generate tonic spiking (a non-interrupted sequence of action potentials), bursting (a repeating pattern that consists of a sequence of action potentials fol- lowed by a time interval with no action potentials) or silence (no action potentials)8. Tese signals are transmit- ted, through other populations of neurons, to spinal motor neurons that activate the respiratory muscle4,6. Te respiratory muscle contracts when it receives a sequence of action potentials from the motor neurons and relaxes when no action potentials arrive9. -

Long-Term Potentiation and Long-Term Depression of Primary Afferent Neurotransmission in the Rat Spinal Cord
The Journal of Neuroscience, December 1993. 13(12): 52286241 Long-term Potentiation and Long-term Depression of Primary Afferent Neurotransmission in the Rat Spinal Cord M. RandiC, M. C. Jiang, and R. Cerne Department of Veterinary Physiology and Pharmacology, Iowa State University, Ames, Iowa 50011 Synaptic transmission between dorsal root afferents and ably mediated by L-glutamate, or a related amino acid (Jahr and neurons in the superficial laminae of the spinal dorsal horn Jessell, 1985; Gerber and RandiC, 1989; Kangrga and Randic, (laminae I-III) was examined by intracellular recording in a 1990, 1991; Yoshimura and Jessell, 1990; Ceme et al., 1991). transverse slice preparation of rat spinal cord. Brief high- Neuronal excitatory amino acids (EAAs), including gluta- frequency electrical stimulation (300 pulses at 100 Hz) of mate, produce their effects through two broad categoriesof re- primary afferent fibers produced a long-term potentiation ceptors called ionotropic and metabotropic (Honor6 et al., 1988; (LTP) or a long-term depression (LTD) of fast (monosynaptic Schoepp et al., 1991; Watkins et al., 1990). The ionotropic and polysynaptic) EPSPs in a high proportion of dorsal horn NMDA, a-amino-3-hydroxy-5-methyl-4-isoxazolepropionic neurons. Both the AMPA and the NMDA receptor-mediated acid (AMPA)/quisqualate (QA), and kainate receptors directly components of synaptic transmission at the primary afferent regulate the opening of ion channelsto Na, K+, and, in the case synapses with neurons in the dorsal horn can exhibit LTP of NMDA receptors, CaZ+as well (Mayer and Westbrook, 1987; and LTD of the synaptic responses. In normal and neonatally Ascher and Nowak, 1987). -

Cerebral Pressure Autoregulation in Traumatic Brain Injury
Neurosurg Focus 25 (4):E7, 2008 Cerebral pressure autoregulation in traumatic brain injury LEONARDO RANGE L -CASTIL L A , M.D.,1 JAI M E GAS C O , M.D. 1 HARING J. W. NAUTA , M.D., PH.D.,1 DAVID O. OKONK W O , M.D., PH.D.,2 AND CLUDIAA S. ROBERTSON , M.D.3 1Division of Neurosurgery, University of Texas Medical Branch, Galveston; 3Department of Neurosurgery, Baylor College of Medicine, Houston, Texas; and 2Department of Neurosurgery, University of Pittsburgh Medical Center, Pittsburgh, Pennsylvania An understanding of normal cerebral autoregulation and its response to pathological derangements is helpful in the diagnosis, monitoring, management, and prognosis of severe traumatic brain injury (TBI). Pressure autoregula- tion is the most common approach in testing the effects of mean arterial blood pressure on cerebral blood flow. A gold standard for measuring cerebral pressure autoregulation is not available, and the literature shows considerable disparity in methods. This fact is not surprising given that cerebral autoregulation is more a concept than a physically measurable entity. Alterations in cerebral autoregulation can vary from patient to patient and over time and are critical during the first 4–5 days after injury. An assessment of cerebral autoregulation as part of bedside neuromonitoring in the neurointensive care unit can allow the individualized treatment of secondary injury in a patient with severe TBI. The assessment of cerebral autoregulation is best achieved with dynamic autoregulation methods. Hyperven- tilation, hyperoxia, nitric oxide and its derivates, and erythropoietin are some of the therapies that can be helpful in managing cerebral autoregulation. In this review the authors summarize the most important points related to cerebral pressure autoregulation in TBI as applied in clinical practice, based on the literature as well as their own experience. -
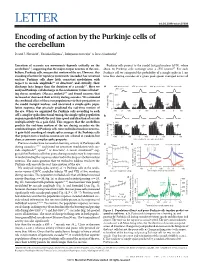
(2015) Encoding of Action by the Purkinje Cells of the Cerebellum
LETTER doi:10.1038/nature15693 Encoding of action by the Purkinje cells of the cerebellum David J. Herzfeld1, Yoshiko Kojima2, Robijanto Soetedjo2 & Reza Shadmehr1 Execution of accurate eye movements depends critically on the Purkinje cells project to the caudal fastigial nucleus (cFN), where cerebellum1–3, suggesting that the major output neurons of the cere- about 50 Purkinje cells converge onto a cFN neuron17. For each bellum, Purkinje cells, may predict motion of the eye. However, this Purkinje cell we computed the probability of a simple spike in 1-ms encoding of action for rapid eye movements (saccades) has remained time bins during saccades of a given peak speed, averaged across all unclear: Purkinje cells show little consistent modulation with respect to saccade amplitude4,5 or direction4, and critically, their discharge lasts longer than the duration of a saccade6,7.Herewe a 400° per s saccade 650° per s saccade 400° per s saccade 650° per s saccade analysed Purkinje-cell discharge in the oculomotor vermis of behav- 500° per s 8,9 200 ing rhesus monkeys (Macaca mulatta) and found neurons that N12 increased or decreased their activity during saccades. We estimated the combined effect of these two populations via their projections to 100 the caudal fastigial nucleus, and uncovered a simple-spike popu- lation response that precisely predicted the real-time motion of 0 the eye. When we organized the Purkinje cells according to each –1000 100 0 100 0 100 0 100 cell’s complex-spike directional tuning, the simple-spike population b 500° per s response predicted both the real-time speed and direction of saccade multiplicatively via a gain field. -

All-Trans Retinoic Acid Induces Synaptic Plasticity in Human Cortical Neurons
bioRxiv preprint doi: https://doi.org/10.1101/2020.09.04.267104; this version posted September 4, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. All-Trans Retinoic Acid induces synaptic plasticity in human cortical neurons Maximilian Lenz1, Pia Kruse1, Amelie Eichler1, Julia Muellerleile2, Jakob Straehle3, Peter Jedlicka2,4, Jürgen Beck3,5, Thomas Deller2, Andreas Vlachos1,5,*. 1Department of Neuroanatomy, Institute of Anatomy and Cell Biology, Faculty of Medicine, University of Freiburg, Germany. 2Institute of Clinical Neuroanatomy, Neuroscience Center, Goethe-University Frankfurt, Germany. 3Department of Neurosurgery, Medical Center and Faculty of Medicine, University of Freiburg, Germany. 4ICAR3R - Interdisciplinary Centre for 3Rs in Animal Research, Faculty of Medicine, Justus-Liebig- University, Giessen, Germany. 5Center for Basics in Neuromodulation (NeuroModulBasics), Faculty of Medicine, University of Freiburg, Germany. Abbreviated title: Synaptic plasticity in human cortex *Correspondence to: Andreas Vlachos, M.D. Albertstr. 17 79104 Freiburg, Germany Phone: +49 (0)761 203 5056 Fax: +49 (0)761 203 5054 Email: [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.09.04.267104; this version posted September 4, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. ABSTRACT A defining feature of the brain is its ability to adapt structural and functional properties of synaptic contacts in an experience-dependent manner. In the human cortex direct experimental evidence for synaptic plasticity is currently missing. -

Analysis of Complex Bursting in Cortical Pyramidal Neuron Modelsଝ
Neurocomputing 32}33 (2000) 181}187 Analysis of complex bursting in cortical pyramidal neuron modelsଝ Adam Kepecs*, Xiao-Jing Wang Volen Center for Complex Systems, Brandeis University, Waltham, MA 02254, USA Accepted 13 January 2000 Abstract Burst "ring is a prominent feature of cortical pyramidal cells and is thought to have signi"cant functional roles in reliable signaling and synaptic plasticity. Modeling studies have successfully elucidated possible biophysical mechanisms underlying complex bursting in pyr- amidal cells. Based on these results (Pinsky, Rinzel, J. Comput. Neurosci. 1 (1994) 39}60), we have built a simpli"ed two-compartment burst model. Using the fast- and slow-variable analysis method, we show that complex bursting is an instance of square-wave bursting, where the dendritic slow potassium conductance is the single slow variable. The coupling parameters between the two compartments change the topological class of bursting thereby altering the "ring patterns of the neuron. These results explain the diverse set of "ring patterns seen with di!erent dendritic morphologies (Mainen, Sejnowski, Nature 382 (1996) 363}366). ( 2000 Elsevier Science B.V. All rights reserved. Keywords: Phase-plane analysis; Complex burst; Bifurcation diagram 1. Introduction Pyramidal cells in many cortical areas "re stereotyped bursts of action potentials termed complex spikes or complex bursts. These bursts consist of 2}7 action poten- tials occurring in a &30 ms window. First observed in hippocampal single-unit extracellular recordings, these were termed &complex spikes' and were later identi"ed by intracellular techniques. Burst "ring is thought to play an important role in reliable signaling [5,15] and synaptic plasticity [2]. -

SHORT-TERM SYNAPTIC PLASTICITY Robert S. Zucker Wade G. Regehr
23 Jan 2002 14:1 AR AR148-13.tex AR148-13.SGM LaTeX2e(2001/05/10) P1: GJC 10.1146/annurev.physiol.64.092501.114547 Annu. Rev. Physiol. 2002. 64:355–405 DOI: 10.1146/annurev.physiol.64.092501.114547 Copyright c 2002 by Annual Reviews. All rights reserved SHORT-TERM SYNAPTIC PLASTICITY Robert S. Zucker Department of Molecular and Cell Biology, University of California, Berkeley, California 94720; e-mail: [email protected] Wade G. Regehr Department of Neurobiology, Harvard Medical School, Boston, Massachusetts 02115; e-mail: [email protected] Key Words synapse, facilitation, post-tetanic potentiation, depression, augmentation, calcium ■ Abstract Synaptic transmission is a dynamic process. Postsynaptic responses wax and wane as presynaptic activity evolves. This prominent characteristic of chemi- cal synaptic transmission is a crucial determinant of the response properties of synapses and, in turn, of the stimulus properties selected by neural networks and of the patterns of activity generated by those networks. This review focuses on synaptic changes that re- sult from prior activity in the synapse under study, and is restricted to short-term effects that last for at most a few minutes. Forms of synaptic enhancement, such as facilitation, augmentation, and post-tetanic potentiation, are usually attributed to effects of a resid- 2 ual elevation in presynaptic [Ca +]i, acting on one or more molecular targets that appear to be distinct from the secretory trigger responsible for fast exocytosis and phasic release of transmitter to single action potentials. We discuss the evidence for this hypothesis, and the origins of the different kinetic phases of synaptic enhancement, as well as the interpretation of statistical changes in transmitter release and roles played by other 2 2 factors such as alterations in presynaptic Ca + influx or postsynaptic levels of [Ca +]i.