The Geography of Beliefs∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
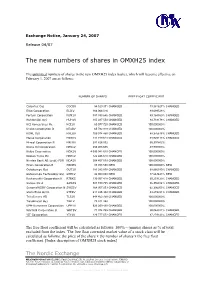
The New Numbers of Shares in OMXH25 Index
Exchange Notice, January 24, 2007 Release 04/07 The new numbers of shares in OMXH25 index The unlimited numbers of shares in the new OMXH25 index basket, which will become effective on February 1, 2007 are as follows: NUMBER OF SHARES FREE FLOAT COEFFICIENT Cargotec Oyj CGCBV 54 520 371 CHANGED 73,361627% CHANGED Elisa Corporation ELI1V 166 066 016 89,699528% Fortum Corporation FUM1V 887 393 646 CHANGED 49,184560% CHANGED Huhtamäki Oyj HUH1V 105 487 550 CHANGED 84,733178% CHANGED KCI Konecranes Plc KCI1V 60 077 720 CHANGED 100,000000% Kesko Corporation B KESBV 65 782 918 CHANGED 100,000000% KONE Oyj KNEBV 109 014 450 CHANGED 88,376618% CHANGED Metso Corporation MEO1V 141 719 614 CHANGED 88,925113% CHANGED M-real Corporation B MRLBV 291 826 062 65,397862% Neste Oil Corporation NES1V 256 403 686 49,900000% Nokia Corporation NOK1V 4 095 042 619 CHANGED 100,000000% Nokian Tyres Plc NRE1V 122 446 610 CHANGED 100,000000% Nordea Bank AB (publ) FDR NDA1V 304 457 879 CHANGED 100,000000% Orion Corporation B ORNBV 85 703 588 NEW 100,000000% NEW Outokumpu Oyj OUT1V 181 283 878 CHANGED 68,866180% CHANGED Outokumpu Technology Oyj OTE1V 42 000 000 NEW 77,663443% NEW Rautaruukki Corporation K RTRKS 139 957 418 CHANGED 60,233120% CHANGED Sampo Plc A SAMAS 581 100 785 CHANGED 86,356914% CHANGED SanomaWSOY Corporation B SWS1V 164 957 053 CHANGED 62,396055% CHANGED Stora Enso Oyj R STERV 611 435 382 CHANGED 93,215391% CHANGED TeliaSonera AB TLS1V 844 452 759 CHANGED 100,000000% TietoEnator Oyj TIE1V 75 841 462 100,000000% UPM-Kymmene Corporation UPM1V 523 259 430 CHANGED 100,000000% Wärtsilä Corporation B WRTBV 71 974 765 CHANGED 90,044011% CHANGED YIT Corporation YTY1V 126 777 072 CHANGED 87,279143% CHANGED The free float coefficient will be calculated as follows: 100% – (minus) shares as % of total excluded from the index. -

Introductions of Member Candidates to the Board of Directors of Orion Corporation
Introductions of member candidates to the Board of Directors of Orion Corporation Sirpa Jalkanen Professor, MD b. 1954 Member of the Board of Directors of Orion Corporation since 23 March 2009 Chairman of the R&D Committee Career 2010– Vice Dean, University of Turku 2008– Director of a Centre of Excellence of the Finnish Academy until 2013 2006– Research professor, National Institute for Health and Welfare, THL 2001– Professor of Immunology, University of Turku 2000–2005 Director of a Centre of Excellence of the Finnish Academy 1996–2006 Academy professor 1996– Director, Receptor Programme, University of Turku 1986–1996 Researcher, University of Turku, Academy of Finland, THL 1983–1986 Researcher, Stanford University, USA Current key positions of trust Member of the Board of Directors: Orion Corporation 2009–, Emil Aaltonen Foundation Member of the committee of medical experts of Sigrid Juselius Foundation 2001– Member of scientific committee of Cancer Institute 2002– Chairman of Finnish Academy of Science and Letters 2010– Sirpa Jalkanen has published about 200 scientific articles on mechanisms of inflammatory diseases and spreading of cancer. Several related patents granted and pending. Matti Kavetvuo M. Sc. (Eng.), M. Sc. (Economics) b. 1944 Vice Chairman of the Board of Directors of Orion Corporation since 24 March 2010, Chairman 1 July 2006 – 24 March 2010, member since 1 July 2006 Member of the R&D Committee and the Nomination Committee Career 2000–2001 President and CEO of Pohjola Insurance Group, retired 2001 1992–1999 President -

Composition of the Suggested Kemira Oyj Board of Directors
1 ANNUAL GENERAL MEETING OF KEMIRA OYJ 2021 COMPOSITION OF THE SUGGESTED KEMIRA OYJ BOARD OF DIRECTORS Wolfgang Büchele, b. 1959, Dr. rer. nat. Exyte GmbH (formerly part of M+W Group GmbH), CEO and Chairman of the Board since 2018 Member of the Kemira Oyj Board of Directors in 2009–2012 and since 2014 Wolfgang Büchele is independent of the Company and its significant shareholders Positions of trust • KMW + Nexter Defense Systems N.V., Member of the Supervisory Board since 2020 • Wegmann Unternehmens–Holding GmbH & Co. KG, Member of the Board of Partners in 2019, Chairman of the Board of Partners since 2020 • GELITA AG, Deputy Chairman of the Supervisory Board 2018–2019, Chairman of the Supervisory Board since 2019 • Merck KGaA, Member of the Supervisory Board 2009–2014 and Chairman of the Supervisory Board since 2014 • E. Merck KG, Member of the Board of Partners since 2009 Past positions of trust • Committee on Eastern European Economic Relations, Chairman, 2016–2019 • Chemical Industry Federation of Germany, Member of the Board, 2014–2016 • European Chemicals Association (Cefic), Member of the Board, 2012–2016 Career history • M+W Group GmbH, CEO, 2017–2018 • Linde AG, Chief Executive Officer, 2014–2016 • Kemira Oyj, President and CEO, 2012–2014 • BorsodChem Zrt., Member of the Board and Chief Executive Officer, 2009–2011 • Permira Beteiligungsberatung GmbH., Senior Advisor, 2008–2011 • Blackstone Group LLP, Project Advisor, 2008 • BASF AG, various positions, 1987–2007: President Fine Chemicals Division, 2005–2007 President Performance Chemicals Division, 2003–2005 President Eastern Europe, Africa, West Asia Regional Division, 2001–2003 Group Vice President Business Management Fine Chemicals Europe, 1999–2001 Director Global Marketing Cosmetic Raw Materials, 1997–1999 Director Regional Marketing Catalysts Asia, 1993–1997 Head of Research Group Industrial Catalysts, 1990–1993 Research Chemist, 1987–1993 February 11, 2021 2 Shirley Cunningham, b. -

Cvs of the Member Candidates the Bod of Orion Corporation
1 (3) CVs of the member candidates the BoD of Orion Corporation Sirpa Jalkanen Matti Kavetvuo b. 1954 b. 1944 Professor, MD M.Sc. (Eng.), B.Sc. (Econ.) x Proposed as a new member to the Board of Directors x Member and Chairman of the Board of Directors of Orion Corporation since 1 July 2006 Career x Member and Chairman of the Board of Directors of the 2008– Director of a Centre of Excellence of the Finnish Academy demerged Orion 2004 – 30 June 2006 until 2013 x Chairman of the Compensation Committee, member of the 2006– Research professor, National Institute for Health and R&D Committee, member of the Nomination Committee Welfare, THL 2001– Professor of Immunology, University of Turku Career 2000–2005 Director of a Centre of Excellence of the Finnish 2000–2001 President and CEO of Pohjola Insurance Group, Academy retired 2001 1996–2006 Academy professor 1992–1999 President and CEO of Valio Ltd 1996– Director, Receptor Programme, University of Turku 1985–1991 President and CEO of Orion Corporation 1986–1996 Researcher, University of Turku, Academy of 1979–1984 President of Instrumentarium Corporation Finland, THL 1983–1986 Researcher, Stanford University, USA Other current and former positions of trust x Chairman of the Board of Directors: Metso Corporation Current key positions of trust: 2003–, Marimekko Corporation 2007–2008 (Member of the x Emil Aaltonen Foundation, member of the Board Board of Directors 1997–2008), Suominen Corporation x Sigrid Juselius Foundation, member of the committee of 2002–2006, Member of the Board of Directors 2001–2006) medical experts x Vice Chairman of the Board of Directors: Alma Media x Cancer Institute, member of scientific committee Corporation 2005– (Member of the Board of Directors 2000–), x Finnish Academy of Sciences and Letters, Vice chairman Kesko Corporation 2003–2006 x Member of the Board of Directors: Konecranes Plc 2001–, About 200 scientific publications on mechanisms of inflammatory Lassila & Tikanoja Plc 2008–, 1998–2001, 1984–1988, diseases and spreading of cancer. -

Review by the President &
Review by the President & CEO Timo Lappalainen Annual General Meeting of Orion Corporation 20 March 2018 Disclaimer This presentation contains forward-looking statements which involve risks and uncertainty factors. These statements are not based on historical facts but relate to the Company’s future activities and performance. They include statements about future strategies and anticipated benefits of these strategies. These statements are subject to risks and uncertainties. Actual results may differ substantially from those stated in any forward-looking statement. This is due to a number of factors, including the possibility that Orion may decide not to implement these strategies and the possibility that the anticipated benefits of implemented strategies are not achieved. Orion assumes no obligation to update or revise any information included in this presentation. Annual General Meeting of Orion Corporation 2018 ©Orion Corporation 20 March 2018 2 2017 in review Orion had a good centenary year ● Net sales were at previous year’s level. 2016 2017 ● The operating profit in comparative period included EUR 22 million of capital gains. 1 074 1 085 ● Dexdor and Easyhaler product family continued to grow. ● Growth in sales of biosimilar Remsima generated a significant portion of Specialty Products growth. ● Narrowing of price band in Finland had EUR 15 million negative effect. 315 293 ● Targeted efficacy objectives were not met in Alzheimer’s disease Phase IIa clinical trial (ORM-12741). ● Development of new Easyhaler formulation (tiotropium) -

Kemira Group
1 COMPOSITION OF THE SUGGESTED KEMIRA OYJ BOARD OF DIRECTORS Wolfgang Büchele, b. 1959, Dr. rer.nat. Linde AG, Chief Executive Officer since 2014 Member of the Kemira Oyj Board of Directors in 2009-2012 and since 2014 Positions of trust: Committee on Eastern European Economic Relations, Chairman since 2016 Chemical Industry Federation of Germany, Member of the Board since 2014 Merck KGaA, Member of the Supervisory Board 2009–2014 and Chairman of the Supervisory Board since 2014 Cefic, Member of the Board since 2012 E. Merck KG, Member of the Board of Partners since 2009 Career history: Kemira Oyj, President and CEO, 2012–2014 BorsodChem Zrt., Member of the Board and Chief Executive Officer, 2009–2011 Permira Beteiligungsberatung GmbH., Senior Advisor, 2008–2011 Blackstone Group LLP, Project Advisor, 2008 BASF AG, various positions, 1987–2007: President Fine Chemicals Division, 2005–2007 President Performance Chemicals Division, 2003–2005 President Eastern Europe, Africa, West Asia Regional Division, 2001–2003 Group Vice President Business Management Fine Chemicals Europe, 1999–2001 Director Global Marketing Cosmetic Raw Materials, 1997–1999 Director Regional Marketing Catalysts Asia, 1993–1997 Head of Research Group Industrial Catalysts, 1990–1993 Research Chemist, 1987–1993 Winnie Fok, b. 1956, BCom Wallenberg Foundations AB (former name Foundation Administration Management Sweden AB), Senior Advisor since 2013 Member of the Kemira Oyj Board of Directors since 2011 Positions of trust: HOPU Fund II Management Co. Ltd., Member -

Introductions of Member Candidates to the Board of Directors 2020 of Orion Corporation
Introductions of member candidates to the Board of Directors 2020 of Orion Corporation Kari Jussi Aho M.Sc. (Econ.) b. 1960 Candidate for a new member of the Board of Directors Independent of the company and its significant shareholders Career 2020- Business owner and entrepreneur 2004-2019 Full-time Chairman of the Board, Rukakeskus Group 1987-2004 Managing Director, Pyhätunturi Ltd 1982-2002 Marketing Manager, Rukakeskus Ltd Current key positions of trust Vice Chairman of the Board: Confederation of Finnish Industries EK 2017-, Finnish Air Force support foundation (Non-profit foundation) 2010- Member of the Board: Aho Group Ltd 2006-, Aava Health Services Ltd 2016-, Economy and Youth TAT 2017- Other: Confederation of Finnish Industries EK, Delegation for Entrepreneurs, Chairman 2017-, Confederation of Finnish Industries EK, Suomalaisen omistajuuden työryhmä (working group for Finnish ownership), Chairman 2017- Former key positions of trust Chairman of the Board: Aho Group Ltd 2006-2012 Vice Chairman of the Board: United Laboratories Ltd 2004-2009 Member of the Board: Cor Group Ltd 2007-2011, Haaga-Helia Ltd 2009-2014, Management Institute of Finland MIF Ltd 2012- 2014 Member of the Supervisory Board: Orion Corporation 2001-2002 Member of the Nomination Committee: Orion Corporation 2006-2019 Pia Kalsta M.Sc. (Econ.) b. 1970 Member of the Board of Directors of Orion Corporation since 26 March 2019 Member of the Audit Committee and the R&D Committee Independent of the company and its significant shareholders Career 2015- Chief Executive -

Bioturku: “Newly” Innovative?
BIOTURKU: “NEWLY” INNOVATIVE? THE RISE OF BIO-PHARMACEUTICALS AND THE BIOTECH CONCENTRATION IN SOUTHWEST FINLAND Smita Srinivas Kimmo Viljamaa MIT-IPC-LIS-03-001 The views expressed herein are the authors’ responsibility and do not necessarily reflect those of the MIT Industrial Performance Center or the Massachusetts Institute of Technology. INDUSTRIAL PERFORMANCE CENTER Massachusetts Institute of Technology Cambridge, MA 02139 BioTurku: “Newly” innovative? The rise of bio-pharmaceuticals and the biotech concentration in southwest Finland Smita Srinivas Kimmo Viljamaa Local Innovation Systems research group Researcher and Ph.D. student MIT Industrial Performance Centre and Research Unit for Urban and Regional Ph.D. candidate (Economic Development), MIT1 Development [email protected] Studies , University of Tampere Tampere, Finland [email protected] MIT IPC-LIS Working Paper 03-001 This paper is based on research carried out under the auspices of the Local Innovation Systems (LIS) Project, conducted in cooperation with the Industrial Performance Center at MIT, the University of Cambridge Center for Business Research, the University of Tokyo, University of Tampere/Sente, and the Helsinki University of Technology. Financial support was provided by Sloan foundation and the Finnish Technology Agency (Tekes.) 1 Now Research Fellow, STG Project, Belfer Centre for Science and International Affairs, John F. Kennedy School of Government, Harvard University. 1 Contents 1 BACKGROUND TO CASE TURKU 3 1.1 Introduction 3 1.2 Definition of the region -

Corporate Governance Statement 2020 a Sanoma Sustainability Review 2020 Contents
Year 2020 Board of Directors’ Report Financial Statements Corporate Governance Statement 2020 A Sanoma Sustainability Review 2020 Contents Corporate Governance Statement 2 Corporate governance structure 2 Board of Directors 3 President and CEO 10 Executive Management Team 10 Risk management and internal control 13 Risk management 13 Internal controls 14 Monitoring of financial reporting process 14 Other information 14 Internal audit 14 Related party transactions 14 Insider Administration 14 Audit 15 1 Sanoma Corporate Governance Statement 2020 Corporate Governance Statement Sanoma Corporation complies with the Finnish Corporate Governance Code issued by the Securities Market Associa- The General Meeting is Sanoma’s highest decision-making body, convening at least once a year. tion in 2019 and in force as of 1 January 2020. This Corporate General Meeting Audit Governance Statement has been prepared in accordance with of Shareholders the Code, which is available at www.cgfinland.fi. The statement has been reviewed by Sanoma’s Audit Committee. The statutory auditors of Sanoma have checked The Chairman, Vice Chairman and members of the Board that the statement has been issued and that its description Board of are elected by the General Meeting. The Board is respon- sible for the management of the company and its business of the main features of internal control and risk management Directors operations. systems related to the financial reporting process complies with the financial statements of the Company. This statement is presented as a separate report from the Board of Directors’ Report. The Board may appoint committees, executive committees and other permanent or fixed-term bodies to focus on certain duties assigned by the Board. -

Orion Investor Presentation Disclaimer
Orion Investor Presentation Disclaimer This presentation contains forward-looking statements which involve risks and uncertainty factors. These statements are not based on historical facts but relate to the Company’s future activities and performance. They include statements about future strategies and anticipated benefits of these strategies. These statements are subject to risks and uncertainties. Actual results may differ substantially from those stated in any forward-looking statement. This is due to a number of factors, including the possibility that Orion may decide not to implement these strategies and the possibility that the anticipated benefits of implemented strategies are not achieved. Orion assumes no obligation to update or revise any information included in this presentation. On 21 April 2018, Orion signed an agreement on the sale of all shares in Orion Diagnostica Oy (i.e. the Orion Diagnostica business division). Following the transaction, that was completed on 30 April 2018, Orion Diagnostica business is reported as discontinued operation. All figures in this presentation are for continuing operations, if not otherwise stated. Investor Presentation © Orion Corporation 2 Content 1) Orion in brief 2) Highlights of 1−12/2019 3) R&D 4) Sustainability 5) Appendices 6) Financial calendar Investor Presentation © Orion Corporation 3 Orion in brief Key messages Orion develops, Growth targeted Strong position in 1manufactures and through new the Nordic 1 markets human 3 in-house developed 5 generics market. and animal drugs. pharmaceuticals, and APIs. Products marketed in >100 countries. Balanced business Core therapy areas Strong model: Both in R&D: oncology, profitability, 2 4 CNS,respiratory4 6 2proprietary drugs stable dividends. -

Introductions of Member Candidates to the Board of Directors 2016 of Orion Corporation
Introductions of member candidates to the Board of Directors 2016 of Orion Corporation Sirpa Jalkanen Academian, Professor, MD b. 1954 Member of the Board of Directors of Orion Corporation since 23 March 2009 Chairman of the R&D Committee Career 2014– Academy professor 2010–2013 Vice Dean, University of Turku 2008–2013 Director of a Centre of Excellence of the Finnish Academy 2006– Research professor, National Institute for Health and Welfare, THL 2001– Professor of Immunology, University of Turku 2000–2005 Director of a Centre of Excellence of the Finnish Academy 1996–2006 Academy professor 1996– Director, Receptor Programme, University of Turku 1986–1996 Researcher, University of Turku, Academy of Finland, THL 1983–1986 Researcher, Stanford University, USA Current key positions of trust Member of the Board of Directors: Orion Corporation 2009–, Emil Aaltonen Foundation 2000–, Tampere University of Technology 2010– Member of the committee of medical experts of Sigrid Juselius Foundation 2001– Member of scientific committee of Cancer Institute 2002– Former key positions of trust Chairman of Finnish Academy of Science and Letters 2010–2012 Sirpa Jalkanen has published about 250 scientific articles on mechanisms of inflammatory diseases and spreading of cancer. Several related patents granted and pending. Timo Maasilta M. Sc. (Eng.) b. 1954 Member of the Board of Directors of Orion Corporation since 20 March 2012 Member of the Audit Committee, Remuneration Committee and the R&D Committee Career 1993– Managing Director, Maa- ja vesitekniikan -

Orion Annual Report 2002
Annual ReportAnnual 2002 Annual Report Orion Corporation Corporate Administration Orionintie 1 A, 02200 Espoo P.O.Box 65, FIN-02101 Espoo, Finland Tel. +358 10 4291 Business Identity Code FI 01122835 www.orion.fi Design Evia Helsinki Oy Photographs Mikael Lindén and Compad Oy Printing Sävypaino Paper Cover Curious Metallics Ice Cold 250 g/m2 Inside pages Galerie Art Silk 150 g/m2 Orion Group Annual Report 2002 Orion Group Annual Report 2002 1 2 Orion Group Annual Report 2002 Contents 4 Information to shareholders 6 Orion Group 10 Our Values 12 Orion Group highlights in 2002 14 Review by the President and CEO Review of the Business Divisions 16 Orion Pharma 27 Wholesale and Distribution 28 Oriola 32 KD 36 Orion Diagnostica 38 Noiro 40 Personnel 44 Environment 48 Orion Group by annual quarters 2001–2002 Financial Statements 49 Report by the Board of Directors 57 Income Statement 58 Balance Sheet 60 Cash Flow Statement 61 Notes to the Financial Statements 74 Shares and shareholders 78 Adjusted data per share 79 Orion Group fi nancial development 1998–2002 81 Proposal for distribution of profi ts 82 Auditors’ report 83 Corporate governance 86 Board of Directors of Orion Corporation 88 Orion Group management 90 Division Management Teams 91 Addresses An electronic version of this Annual Report is available on the Web, homepage www.orion.fi Orion Group Annual Report 2002 3 Information to shareholders Annual General Meeting of the Shareholders on Thursday, 27 March 2003 The Annual General Meeting of the Shareholders of Orion Corporation will be held on Thursday, 27 March 2003 at 6 p.m.