Multivariate Calculus∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SOME CONSEQUENCES of the MEAN-VALUE THEOREM Below
SOME CONSEQUENCES OF THE MEAN-VALUE THEOREM PO-LAM YUNG Below we establish some important theoretical consequences of the mean-value theorem. First recall the mean value theorem: Theorem 1 (Mean value theorem). Suppose f :[a; b] ! R is a function defined on a closed interval [a; b] where a; b 2 R. If f is continuous on the closed interval [a; b], and f is differentiable on the open interval (a; b), then there exists c 2 (a; b) such that f(b) − f(a) = f 0(c)(b − a): This has some important corollaries. 1. Monotone functions We introduce the following definitions: Definition 1. Suppose f : I ! R is defined on some interval I. (i) f is said to be constant on I, if and only if f(x) = f(y) for any x; y 2 I. (ii) f is said to be increasing on I, if and only if for any x; y 2 I with x < y, we have f(x) ≤ f(y). (iii) f is said to be strictly increasing on I, if and only if for any x; y 2 I with x < y, we have f(x) < f(y). (iv) f is said to be decreasing on I, if and only if for any x; y 2 I with x < y, we have f(x) ≥ f(y). (v) f is said to be strictly decreasing on I, if and only if for any x; y 2 I with x < y, we have f(x) > f(y). (Can you draw some examples of such functions?) Corollary 2. -

Advanced Calculus: MATH 410 Functions and Regularity Professor David Levermore 6 August 2020
Advanced Calculus: MATH 410 Functions and Regularity Professor David Levermore 6 August 2020 5. Functions, Continuity, and Limits 5.1. Functions. We now turn our attention to the study of real-valued functions that are defined over arbitrary nonempty subsets of R. The subset of R over which such a function f is defined is called the domain of f, and is denoted Dom(f). We will write f : Dom(f) ! R to indicate that f maps elements of Dom(f) into R. For every x 2 Dom(f) the function f associates the value f(x) 2 R. The range of f is the subset of R defined by (5.1) Rng(f) = f(x): x 2 Dom(f) : Sequences correspond to the special case where Dom(f) = N. When a function f is given by an expression then, unless it is specified otherwise, Dom(f) will be understood to be all x 2 R forp which the expression makes sense. For example, if functions f and g are given by f(x) = 1 − x2 and g(x) = 1=(x2 − 1), and no domains are specified explicitly, then it will be understood that Dom(f) = [−1; 1] ; Dom(g) = x 2 R : x 6= ±1 : These are natural domains for these functions. Of course, if these functions arise in the context of a problem for which x has other natural restrictions then these domains might be smaller. For example, if x represents the population of a species or the amountp of a product being manufactured then we must further restrict x to [0; 1). -

Matrix Convex Functions with Applications to Weighted Centers for Semidefinite Programming
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Research Papers in Economics Matrix Convex Functions With Applications to Weighted Centers for Semidefinite Programming Jan Brinkhuis∗ Zhi-Quan Luo† Shuzhong Zhang‡ August 2005 Econometric Institute Report EI-2005-38 Abstract In this paper, we develop various calculus rules for general smooth matrix-valued functions and for the class of matrix convex (or concave) functions first introduced by L¨ownerand Kraus in 1930s. Then we use these calculus rules and the matrix convex function − log X to study a new notion of weighted centers for semidefinite programming (SDP) and show that, with this definition, some known properties of weighted centers for linear programming can be extended to SDP. We also show how the calculus rules for matrix convex functions can be used in the implementation of barrier methods for optimization problems involving nonlinear matrix functions. ∗Econometric Institute, Erasmus University. †Department of Electrical and Computer Engineering, University of Minnesota. Research supported by National Science Foundation, grant No. DMS-0312416. ‡Department of Systems Engineering and Engineering Management, The Chinese University of Hong Kong, Shatin, Hong Kong. Research supported by Hong Kong RGC Earmarked Grant CUHK4174/03E. 1 Keywords: matrix monotonicity, matrix convexity, semidefinite programming. AMS subject classification: 15A42, 90C22. 2 1 Introduction For any real-valued function f, one can define a corresponding matrix-valued function f(X) on the space of real symmetric matrices by applying f to the eigenvalues in the spectral decomposition of X. Matrix functions have played an important role in scientific computing and engineering. -

Lecture 1: Basic Terms and Rules in Mathematics
Lecture 7: differentiation – further topics Content: - additional topic to previous lecture - derivatives utilization - Taylor series - derivatives utilization - L'Hospital's rule - functions graph course analysis Derivatives – basic rules repetition from last lecture Derivatives – basic rules repetition from last lecture http://www.analyzemath.com/calculus/Differentiation/first_derivative.html Lecture 7: differentiation – further topics Content: - additional topic to previous lecture - derivatives utilization - Taylor series - derivatives utilization - L'Hospital's rule - functions graph course analysis Derivatives utilization – Taylor series Definition: The Taylor series of a real or complex-valued function ƒ(x) that is infinitely differentiable at a real or complex number a is the power series: In other words: a function ƒ(x) can be approximated in the close vicinity of the point a by means of a power series, where the coefficients are evaluated by means of higher derivatives evaluation (divided by corresponding factorials). Taylor series can be also written in the more compact sigma notation (summation sign) as: Comment: factorial 0! = 1. Derivatives utilization – Taylor series When a = 0, the Taylor series is called a Maclaurin series (Taylor series are often given in this form): a = 0 ... and in the more compact sigma notation (summation sign): a = 0 graphical demonstration – approximation with polynomials (sinx) nice examples: https://en.wikipedia.org/wiki/Taylor_series http://mathdemos.org/mathdemos/TaylorPolynomials/ Derivatives utilization – Taylor (Maclaurin) series Examples (Maclaurin series): Derivatives utilization – Taylor (Maclaurin) series Taylor (Maclaurin) series are utilized in various areas: 1. Approximation of functions – mostly in so called local approx. (in the close vicinity of point a or 0). Precision of this approximation can be estimated by so called remainder or residual term Rn, describing the contribution of ignored higher order terms: 2. -

MA 105 : Calculus Division 1, Lecture 06
MA 105 : Calculus Division 1, Lecture 06 Prof. Sudhir R. Ghorpade IIT Bombay Prof. Sudhir R. Ghorpade, IIT Bombay MA 105 Calculus: Division 1, Lecture 6 Recap of the previous lecture Rolle's theorem and its proof (using Extreme Value Property) (Lagrange's) Mean Value Theorem and its proof Consequences of MVT Monotonicity. Relation with derivatives Convexity and Concavity. Prof. Sudhir R. Ghorpade, IIT Bombay MA 105 Calculus: Division 1, Lecture 6 Convexity and Concavity Let I be an interval. A function f : I R is called convex on I if the line segment joining any two points! on the graph of f lies on or above the graph of f . If x1; x2 I , then the equation 2 of the line passing through (x1; f (x1)) and (x2; f (x2)) is given by f (x2) f (x1) y = f (x1) + − (x x1). Thus f is convex on I if x2 x1 − − f (x2) f (x1) x1; x2; x I ; x1 < x < x2 = f (x) f (x1)+ − (x x1): 2 ) ≤ x2 x1 − − Similarly, a function f : I R is called concave on I if ! f (x2) f (x1) x1; x2; x I ; x1 < x < x2 = f (x) f (x1)+ − (x x1): 2 ) ≥ x2 x1 − − Remark: It is easy to see that f f ((1 λ)x1 + λx2) (1 λ)f (x1)+λf (x2) λ [0; 1] and x1; x2 I : − ≤ − 8 2 2 Likewise for concacity (with changed to ). ≤ ≥ Prof. Sudhir R. Ghorpade, IIT Bombay MA 105 Calculus: Division 1, Lecture 6 A function f : I R is called strictly convex on I if the inequality in the! definition of a convex function can be replaced by≤ the strict inequality <. -

2Nd Order Derivatives, Concavity
Mathematics for Economics Anthony Tay 10. The Second-Order Derivative, Concavity and Convexity The second-order derivative (or simply ‘second derivative’) is the derivative of the derivative fa′′(+− h ) fa () fa′′( )= lim . h→0 h The objective of this section is to provide examples of their application in general, and in economics in particular. We can also compute ‘third-order derivatives’, ‘fourth-order derivatives’, etc. These are useful, although we will be using them less frequently. Example 10.1 If fx()= x3 , then fx′()= 3 x2 , fx′′()= 6 x, fx′′′()= 6. Notation If y = f (x) , then d 2 dy2 Second Derivative f ′′(x), f (2)(x), y′′ , fx(), dx2 dx2 d n dyn n-th ordered derivative f (n)(x), y(n) , fx() , dxn dxn If y is a function of time, then the second derivative is often written y , following the convention that the first-derivative in such applications is written y . The most straightforward interpretation of the second-derivative is that it is the rate of change of the rate of change of fx() as x increases. Geometrically, the second derivative can also help to describe the shape of a function. When used in specific disciplines, the first and second derivations can often be given an interpretation appropriate to the context of that discipline. You are probably familiar with the concepts of velocity and acceleration in physics. Example 10.2 If xt() gives you the position of an object relative to some reference point x(0) , and t is time, then x is the velocity of the object, and x is its acceleration. -

Maxima and Minima
Maxima and Minima 9 This unit is designed to introduce the learners to the basic concepts associated with Optimization. The readers will learn about different types of functions that are closely related to optimization problems. This unit discusses maxima and minima of simple polynomial functions and develops the concept of critical points along with the first derivative test and next the concavity test. This unit also discusses the procedure of determining the optimum (maximum or minimum) point with single variable function, multivariate function and constrained equations. Some relevant business and economic applications of maxima and minima are also provided in this unit for clear understanding to the learners. School of Business Blank Page Unit-9 Page-200 Bangladesh Open University Lesson-1: Optimization of Single Variable Function After studying this lesson, you should be able to: Describe the concept of different types of functions; Explain the maximum, minimum and point of inflection of a function; Describe the methodology for determining optimization conditions for mathematical functions with single variable; Determine the maximum and minimum of a function with single variable; Determine the inflection point of a function with single variable. Introduction Optimization is a predominant theme in management and economic analysis. For this reason, the classical calculus methods of finding free and constrained extrema and the more recent techniques of mathematical programming occupy an important place in management and economics. The most common The most common criterion of choice among alternatives in economics is criterion of choice the goal of maximizing something (i.e. profit maximizing, utility among alternatives in maximizing, growth rate maximizing etc.) or of minimizing something economics is the goal of maximizing (i.e. -

Log-Concave Polynomials II: High-Dimensional Walks and an FPRAS for Counting Bases of a Matroid
Log-Concave Polynomials II: High-Dimensional Walks and an FPRAS for Counting Bases of a Matroid Nima Anari1, Kuikui Liu2, Shayan Oveis Gharan2, and Cynthia Vinzant3 1Stanford University, [email protected] 2University of Washington, [email protected], [email protected] 3North Carolina State University, [email protected] February 11, 2019 Abstract We design an FPRAS to count the number of bases of any matroid given by an independent set oracle, and to estimate the partition function of the random cluster model of any matroid in the regime where 0 < q < 1. Consequently, we can sample random spanning forests in a graph and (approximately) compute the reliability polynomial of any matroid. We also prove the thirty year old conjecture of Mihail and Vazirani that the bases exchange graph of any matroid has expansion at least 1. Our algorithm and the proof build on the recent results of Dinur, Kaufman, Mass and Oppenheim [KM17; DK17; KO18] who show that high dimensional walks on simplicial complexes mix rapidly if the corresponding localized random walks on 1-skeleton of links of all complexes are strong spectral expanders. One of our key observations is a close connection between pure simplicial complexes and multiaffine homogeneous polynomials. Specifically, if X is a pure simplicial complex with positive weights on its maximal faces, we can associate with X a multiaffine homogeneous polynomial pX such that the eigenvalues of the localized random walks on X correspond to the eigenvalues of the Hessian of derivatives of pX. 1 Introduction [n] Let m : 2 ! R>0 be a probability distribution on the subsets of the set [n] = f1, 2, .. -

On Hopital-Style Rules for Monotonicity and Oscillation
On Hˆopital-style rules for monotonicity and oscillation MAN KAM KWONG∗ Department of Applied Mathematics The Hong Kong Polytechnic University, Hunghom, Hong Kong [email protected] Abstract We point out the connection of the so-called Hˆopital-style rules for monotonicity and oscillation to some well-known properties of concave/convex functions. From this standpoint, we are able to generalize the rules under no differentiability requirements and greatly extend their usability. The improved rules can handle situations in which the functions involved have non-zero initial values and when the derived functions are not necessarily monotone. This perspective is not new; it can be dated back to Hardy, Littlewood and P´olya. 2010 Mathematics Subject Classification. 26.70, 26A48, 26A51 Keywords. Monotonicity, Hˆopital’s rule, oscillation, inequalities. arXiv:1502.07805v1 [math.CA] 27 Feb 2015 ∗The research of this author is supported by the Hong Kong Government GRF Grant PolyU 5003/12P and the Hong Kong Polytechnic University Grants G-UC22 and G-YBCQ. 1 1 Introduction and historical remarks Since the 1990’s, many authors have successfully applied the so-called monotone L’Hˆopital’s† rules to establish many new and useful inequalities. In this article we make use of the connection of these rules to some well-known properties of concave/convex functions (via a change of variable) to extend the usability of the rules. We show how the rules can be formulated under no differentiability requirements, and how to characterize all possible situations, which are normally not covered by the conventional form of the rules. These include situations in which the functions involved have non-zero initial values and when the derived functions are not necessarily monotone. -

Convexity Conditions and Intersections with Smooth
TRANSACTIONS OF THE AMERICAN MATHEMATICAL SOCIETY Volume 289. Number 2, June 1985 CONVEXITYCONDITIONS AND INTERSECTIONS WITH SMOOTH FUNCTIONS BY S. AGRONSKY, A. M. BRUCKNER1, M. LACZKOVICH AND D. PREISS Abstract. A continuous function that agrees with each member of a family J^of smooth functions in a small set must itself possess certain desirable properties. We study situations that arise when ^consists of the family of polynomials of degree at most n, as well as certain larger families and when the small sets of agreement are finite. The conclusions of our theorems involve convexity conditions. For example, if a continuous function / agrees with each polynomial of degree at most n in only a finite set, then/is (n + l)-convex or (n + l)-concave on some interval. We consider also certain variants of this theorem, provide examples to show that certain improve- ments are not possible and present some applications of our results. 1. Introduction. We shall examine the extent to which certain theorems related to monotonicity extend to convexity and, more generally, n-convexity (monotonicity itself can be viewed as 1-convexity). By a theorem of E. Cech [2], if a continuous function / defined in an interval takes every value in finitely many points, then / is monotonie in some subinterval. Our main result is the following generalization of Cech's theorem: If the graph of / intersects the graph of every polynomial of degree at most n in finitely many points, then /is (n + l)-convex or (n + l)-concave in some subinterval (Theorem 13). Cech's result is the case of n = 0. -

Multi-Variable Calculus and Optimization
Multi-variable Calculus and Optimization Dudley Cooke Trinity College Dublin Dudley Cooke (Trinity College Dublin) Multi-variable Calculus and Optimization 1 / 51 EC2040 Topic 3 - Multi-variable Calculus Reading 1 Chapter 7.4-7.6, 8 and 11 (section 6 has lots of economic examples) of CW 2 Chapters 14, 15 and 16 of PR Plan 1 Partial differentiation and the Jacobian matrix 2 The Hessian matrix and concavity and convexity of a function 3 Optimization (profit maximization) 4 Implicit functions (indifference curves and comparative statics) Dudley Cooke (Trinity College Dublin) Multi-variable Calculus and Optimization 2 / 51 Multi-variable Calculus Functions where the input consists of many variables are common in economics. For example, a consumer's utility is a function of all the goods she consumes. So if there are n goods, then her well-being or utility is a function of the quantities (c1, ... , cn) she consumes of the n goods. We represent this by writing U = u(c1, ... , cn) Another example is when a firm’s production is a function of the quantities of all the inputs it uses. So, if (x1, ... , xn) are the quantities of the inputs used by the firm and y is the level of output produced, then we have y = f (x1, ... , xn). We want to extend the calculus tools studied earlier to such functions. Dudley Cooke (Trinity College Dublin) Multi-variable Calculus and Optimization 3 / 51 Partial Derivatives Consider a function y = f (x1, ... , xn). The partial derivative of f with respect to xi is the derivative of f with respect to xi treating all other variables as constants and is denoted, ¶f or fxi ¶xi Consider the following function: y = f (u, v) = (u + 4)(6u + v). -
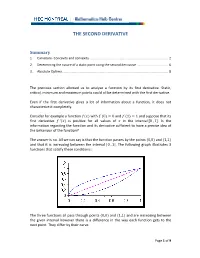
The Second Derivative
THE SECOND DERIVATIVE Summary 1. Curvature‐ Concavity and convexity ........................................................................................ 2 2. Determining the nature of a static point using the second derivative ................................... 6 3. Absolute Optima ...................................................................................................................... 8 The previous section allowed us to analyse a function by its first derivative. Static, critical, minimum and maximum points could all be determined with the first derivative. Even if the first derivative gives a lot of information about a function, it does not characterize it completely. Consider for example a function with 0 0 and 1 1 and suppose that its first derivative ’ is positive for all values of in the interval 0 , 1. Is the information regarding the function and its derivative sufficient to have a precise idea of the behaviour of the function? The answer is no. All we can say is that the function passes by the points 0,0 and 1,1 and that it is increasing between the interval 0 , 1. The following graph illustrates 3 functions that satisfy these conditions : The three functions all pass through points 0,0 and 1,1 and are increasing between the given interval however there is a difference in the way each function gets to the next point. They differ by their curve. Page 1 of 9 1. Curvature‐ concavity and convexity An intuitive definition: a function is said to be convex at an interval if, for all pairs of points on the graph, the line segment that connects these two points passes above the curve. A function is said to be concave at an interval if, for all pairs of points on the graph, the line segment that connects these two points passes below the curve.