Prediction Method of Underwater Acoustic Transmission Loss Based on Deep Belief Net Neural Network
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Analytical, Numerical and Experimental Calculation of Sound Transmission Loss Characteristics of Single Walled Muffler Shells
1 Analytical, Numerical and Experimental calculation of sound transmission loss characteristics of single walled muffler shells A thesis submitted to the Division of Graduate Studies and Research of the University of Cincinnati in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE In the Department of Mechanical Engineering of the College of Engineering May 2007 by John George B. E., Regional Engineering College, Surat, India, 1995 M. E., Regional Engineering College, Trichy, India, 1997 Committee Chair: Dr. Jay Kim 2 Abstract Accurate prediction of sound radiation characteristics from muffler shells is of significant importance in automotive exhaust system design. The most commonly used parameter to evaluate the sound radiation characteristic of a structure is transmission loss (TL). Many tools are available to simulate the transmission loss characteristic of structures and they vary in terms of complexity and inherent assumptions. MATLAB based analytical models are very valuable in the early part of the design cycle to estimate design alternatives quickly, as they are very simple to use and could be used by the design engineers themselves. However the analytical models are generally limited to simple shapes and cannot handle more complex contours as the geometry evolves during the design process. Numerical models based on Finite Element Method (FEM) and Boundary Element Method (BEM) requires expert knowledge and is more suited to handle complex muffler configurations in the latter part of the design phase. The subject of this study is to simulate TL characteristics from muffler shells utilizing commercially available FEM/BEM tools (NASTRAN and SYSNOISE, in this study) and MATLAB based analytical model. -

Sound Transmission Loss Test AS-TL1765
Acoustical Surfaces, Inc. Acoustical Surfaces, Inc. We identify and SOUNDPROOFING, ACOUSTICS, NOISE & VIBRATION CONTROL SPECIALISTS 123 Columbia Court North = Suite 201 = Chaska, MN 55318 (952) 448-5300 = Fax (952) 448-2613 = (800) 448-0121 Email: [email protected] Your Noise Problems Visit our Website: www.acousticalsurfaces.com Sound Transmission Obscuring Products Soundproofing, Acoustics, Noise & Vibration Control Specialists ™ We Identify and S.T.O.P. Your Noise Problems ACOUSTIC SYSTEMS ACOUSTICAL RESEARCH FACILITY OFFICIAL LABORATORY REPORT AS-TL1765 Subject: Sound Transmission Loss Test Date: December 26, 2000 Contents: Transmission Loss Data, One-third Octave Bands Transmission Loss Data, Octave Bands Sound Transmission Class Rating Outdoor /Indoor Transmission Class Rating on Asymmetrical Staggered Metal Stud Wall Assembly w/Two Layers 5/8” FIRECODE Gypsum (Source Side), One Layer 5/8” FIRECODE Gypsum on RC-1 Channels (Receive Side), and R-19 UltraTouch Blue Insulation for Rendered by Manufacturer and released to Acoustical Surfaces 123 Columbia Court North Chaska, MN 55318 ACOUSTIC SYSTEMS ACOUSTICAL RESEARCH FACILITY is NVLAP-Accredited for this and other test procedures National Institute of Standards National Voluntary and Technology Laboratory Accreditation Program Certified copies of the Report carry a Raised Seal on every page. Reports may be reproduced freely if in full and without alteration. Results apply only to the unit tested and do not extend to other same or similar items. The NVLAP logo does not denote -

Echo Time Spreading and the Definition of Transmission Loss for Broadband Active Sonar
Paper Number 97, Proceedings of ACOUSTICS 2011 2-4 November 2011, Gold Coast, Australia Echo time spreading and the definition of transmission loss for broadband active sonar Z. Y. Zhang Defence Science and Technology Organisation P.O. Box 1500, Edinburgh, SA 5111, Australia ABSTRACT In active sonar, the echo from a target is the convolution of the source waveform with the impulse responses of the target and the propagation channel. The transmitted source waveform is generally known and replica-correlation is used to increase the signal gain. This process is also called pulse compression because for broadband pulses the re- sulting correlation functions are impulse-like. The echo after replica-correlation may be regarded as equivalent to that received by transmitting the impulsive auto-correlation function of the source waveform. The echo energy is spread out in time due to different time-delays of the multipath propagation and from the scattering process from the target. Time spreading leads to a reduction in the peak power of the echo in comparison with that which would be obtained had all multipaths overlapped in time-delay. Therefore, in contrast to passive sonar where all energies from all sig- nificant multipaths are included, the concept of transmission losses in the active sonar equation needs to be handled with care when performing sonar performance modelling. We show modelled examples of echo time spreading for a baseline case from an international benchmarking workshop. INTRODUCTION ECHO MODELLING ISSUES The performance of an active sonar system is often illustrated In a sound channel, the transmitted pulse generally splits into by the power (or energy) budget afforded by a separable form multipath arrivals with different propagation angles and of the sonar equation, such as the following, travel times that ensonify the target, which scatters and re- radiates each arrival to more multipath arrivals at the re- SE = EL – [(NL – AGN) ⊕ RL] + MG – DT (1) ceiver. -

2015 Standard for Sound Rating and Sound Transmission Loss of Packaged Terminal Equipment
ANSI/AHRI Standard 300 2015 Standard for Sound Rating and Sound Transmission Loss of Packaged Terminal Equipment Approved by ANSI on July 8, 2016 IMPORTANT SAFETY DISCLAIMER AHRI does not set safety standards and does not certify or guarantee the safety of any products, components or systems designed, tested, rated, installed or operated in accordance with this standard/guideline. It is strongly recommended that products be designed, constructed, assembled, installed and operated in accordance with nationally recognized safety standards and code requirements appropriate for products covered by this standard/guideline. AHRI uses its best efforts to develop standards/guidelines employing state-of-the-art and accepted industry practices. AHRI does not certify or guarantee that any tests conducted under its standards/guidelines will be non-hazardous or free from risk. Note: This standard supersedes AHRI Standard 300-2008. Note: This version of the standard differs from the 2008 version of the standard in the following: This standard references the sound intensity test method defined in ANSI/AHRI Standard 230, as an alternate method of test to the reverberation room test method defined in ANSI/AHRI Standard 220 for determination of sound power ratings. Price $10.00 (M) $20.00 (NM) ©Copyright 2015, by Air-Conditioning, Heating, and Refrigeration Institute Printed in U.S.A. Registered United States Patent and Trademark Office TABLE OF CONTENTS SECTION PAGE Section 1. Purpose .......................................................................................................................................... -

Linear Acoustic Modelling and Testing of Exhaust Mufflers
Linear Acoustic Modelling And Testing of Exhaust Mufflers Sathish Kumar Master of Science Thesis Stockholm, Sweden 2007 Linear Acoustic Modelling And Testing of Exhaust Mufflers By Sathish Kumar The Marcus Wallenberg Laboratory MWL for Sound and Vibration Research 2 Abstract Intake and Exhaust system noise makes a huge contribution to the interior and exterior noise of automobiles. There are a number of linear acoustic tools developed by institutions and industries to predict the acoustic properties of intake and exhaust systems. The present project discusses and validates, through measurements, the proper modelling of these systems using BOOST- SID and discusses the ideas to properly convert a geometrical model of an exhaust muffler to an acoustic model. The various elements and their properties are also discussed. When it comes to Acoustic properties there are several parameters that describe the performance of a muffler, the Transmission Loss (TL) can be useful to check the validity of a mathematical model but when we want to predict the actual acoustic behavior of a component after it is installed in a system and subjected to operating conditions then we have to determine other properties like Attenuation, Insertion loss etc,. Zero flow and Mean flow (M=0.12) measurements of these properties were carried out for mufflers ranging from simple expansion chambers to complex geometry using two approaches 1) Two Load technique 2) Two Source location technique. For both these cases, the measured transmission losses were compared to those obtained from BOOST-SID models. The measured acoustic properties compared well with the simulated model for almost all the cases. -

Behavior of Transmission Loss in Muffler with the Variation in Absorption Layer Thickness
International Journal of scientific research and management (IJSRM) \ ||Volume||3||Issue||4 ||Pages|| 2656-2661||2015|| Website: www.ijsrm.in ISSN (e): 2321-3418 Behavior of transmission loss in muffler with the variation in absorption layer thickness Ujjal Kalita1, Abhijeet Pratap2, Sushil Kumar3 1Master’s Student, School of Mechanical Engineering, Lovely Professional University, Delhi-Jalandhar Highway, Phagwara, Punjab-144411, India [email protected] 2Master’s Student, School of Mechanical Engineering, Lovely Professional University, Delhi-Jalandhar Highway, Phagwara, Punjab-144411, India [email protected] 3Assistant Professor, School of Mechanical Engineering, Lovely Professional University, Delhi-Jalandhar Highway, Phagwara, Punjab-144411, India [email protected] Abstract: This paper reveals the acoustic performance of packed dissipative muffler with the variation in thickness of absorption material. It researches the sound absorbing capacity of different mufflers on application of this absorption material and also predicts one of the suitable designs of muffler for application in automobile industry. Delany-Bazley equations are used for the application of properties to the absorption materials. This study is performed to reduce the noise coming out of the exhaust system of vehicles as noise pollution and excessive exhaust smoke affect the environment. Transmission Loss (TL) which is the main acoustic performance parameter is evaluated as it determines the reduction in exhaust noise. This is performed in the 3D linear pressure acoustic module of Comsol Multiphysics. Polyester, Ceramic Acoustic Absorber and Rockwool are the materials taken for study. Keywords: Absorption material, Packed dissipative muffler, Transmission Loss, Thickness, Ceramic acoustic absorber with silicon carbide fibers 1. INTRODUCTION surface and 50- 450 µm near the front surface of the body. -

An Introduction to the Sonar Equations with Applications (Revised)
Calhoun: The NPS Institutional Archive Reports and Technical Reports All Technical Reports Collection 1979-02-01 An introduction to the sonar equations with applications (revised) Coppens, Alan B. Monterey, California. Naval Postgraduate School http://hdl.handle.net/10945/15240 DSTGRADUATE SCHOOL Monterey, Galifornia --- --- X? IYTRODUCTION TO THE SONAX EQVAT'COXS XITIi iUDPLLCATIONS (REVISED) b Y X.S. Coppens, H.X. 3ahl, and J.V. Sanders NPS Publication Approved for public release; distribution unlimited Prepared for: :\Tavl Postgraduate Schoc.1 Monterey, California 93940 v [d 7,$ $- B *;* i NAVAL POSTGRADUATE SCHOOL Monterey, California Rear Admiral Tyler F. Dedman Jack R. Borsting Superintendent Provost The materials presented herein were produced with the support of the Department of Physics and Chemistry and the Office of Continuing Education, Naval Postgraduate School. Reproduction of all or part of this report is authorized. This report was prepared by: h4.4~ Harvey A. V~ahl ~ssistantProfessor of Physics 4WZ > - ,,'"/ James V. Sanders / Associate Professor of Physics i / Reviewed by: <---- - --7 d& d& 2~ /& K.E. Woehler, Chairman William M. Tolles Department of Physics Dean of Research and Chemistry Unclassified CURITY CLASSIFICATION OF THIS PAGE (When Date Entered) READ INSTRUCTIONS REPORTDOCUMENTATIONPAGE BEFORE COMPLETING FORM REPORT NUMBER 12. GOVT ACCESSION NO. 3. RECIPIENT'S CATALOG NUMBER I I TITLE (and Subtitle) 5. TYPE OF REPORT & PERIOD COVERED AN INTRODUCTION TO THE SONAR EQUATIONS WITH APPLICATIONS (REVISED) NPS Publication 6. PERFORMING ORG. REPORT NUMBER AU THOR(8) 8. CONTRACT OR GRANT NUMBER(*) Alan B. Coppens, Harvey A. Dahl, and James V. Sanders PERFORMING ORGANIZATION NAME AND ADDRESS 10. PROGRAM ELEMENT, PROJECT, TASK Naval Postgraduate School AREA 6 WORK UNIT NUMBERS Code 61Sd/Cz/Dh Monterey, California 93940 I. -
Construction Required to Obtain the Desired Sound Transmission Loss... OR ~How to Find out How Much Isolation You Need~
Construction required to obtain the desired sound transmission loss... OR ~How to find out how much Isolation you need~ Introduction Noise attenuation measures are required in a noise sensitive area to achieve the following criteria: • World Health Organisation (WHO) sleep disturbance criteria: 30 dB(A) Leq and 45 dB(A) Lmax inside bedrooms • Interior Sound Level Criteria: Type of Occupancy / Activity Maximum Recommended Design Sound Pressure Level Houses and Apartments near Major Roads: Living Areas 45 Sleeping Areas 40 Work Areas 45 Houses and Apartments near Minor Roads: Living Areas 40 Sleeping Areas 35 Work Areas 40 • Music noise criteria (most nations have similar noise codes): The noise level in any bedroom is to be no more than 8 dB above the level of background noise in any octave band of the sound spectrum when exposed to music noise from any existing entertainment premises. Additionally, the music noise must be less than 5 dB(A) above the background noise for the overall (sum of all octave bands) A‐weighted levels. For example; see the chart below which represents the octave band for various musical instruments: Redrawn by John Schneider. See John R. Pierce, e Science of Musical Sound (New York, 1992), pp. 18‐19; Donald E. Hall, Mucical Acoustics: An Introduction (Pacific Grove, California, 1991), inside back cover; and Edward R. Tufte, Visual Explanations (Cheshire, Connecticut, 2001), p. 87. The table below shows a summary of the peak levels of various musical instruments. It can be seen that some instruments are quite capable of generating very high sound levels. Instrument Peak Level (dB SPL) French Horn 107 Bassoon 102 Trombone 108 Tuba 110 Trumpet 111 Violin 109 Clarinet 108 Cello 100 Amplified Guitar >115 Drums >120 So, depending on the use of the music room or studio, your isolation requirements can vary greatly. -

Sound Transmission Class - Wikipedia, the Free Encyclopedia
Sound transmission class - Wikipedia, the free encyclopedia https://en.wikipedia.org/wiki/Sound_transmission_class From Wikipedia, the free encyclopedia Sound Transmission Class (or STC) is an integer rating of how well a building partition attenuates airborne sound. In the USA, it is widely used to rate interior partitions, ceilings/floors, doors, windows and exterior wall configurations (see ASTM International Classification E413 and E90). Outside the USA, the Sound Reduction Index (SRI) ISO index or its related indices are used. These are currently (2012) defined in the ISO - 140 series of standards (under revision). The STC rating figure very roughly reflects the decibel reduction in noise that a partition can provide. 1 Rating methodology 2 Sound damping techniques 3 Legal and practical requirements 4 See also 5 External links 6 References The ASTM test methods have changed every few years. Thus, STC results posted before 1999 may not produce the same results today, and the differences become wider as one goes further back in time –the differences in the applicable test methods between the 1970s and today being quite significant. [citation needed] The STC number is derived from sound attenuation values tested at sixteen standard frequencies from 125 Hz to 4000 Hz. These transmission-loss values are then plotted on a sound pressure level graph and the resulting curve is compared to a standard reference contour. Acoustical engineers fit these values to the appropriate TL Curve (or Transmission Loss) to determine an STC rating. The measurement is accurate for speech sounds, but much less so for amplified music, mechanical equipment noise, transportation noise, or any sound with substantial low-frequency energy below 125 Hz. -

An Experimental and Numerical Study on the Effect of Spacing Between Two Helmholtz Resonators
acoustics Article An Experimental and Numerical Study on the Effect of Spacing between Two Helmholtz Resonators Abhishek Gautam , Alper Celik * and Mahdi Azarpeyvand Faculty of Engineering, University of Bristol, Bristol BS8 1TR, UK; [email protected] (A.G.); [email protected] (M.A.) * Correspondence: [email protected] Abstract: This study investigates the acoustic performance of a system of two Helmholtz resonators experimentally and numerically. The distance between the Helmholtz resonators was varied to assess its effect on the acoustic performance of the system quantitatively. Experiments were performed using an impedance tube with two instrumented Helmholtz resonators and several microphones along the impedance tube. The relation between the noise attenuation performance of the system and the distance between two resonators is presented in terms of the transmission loss, transmission coefficient, and change in the sound pressure level along the tube. The underlying mechanisms of the spacing effect are further elaborated by studying pressure and the particle velocity fields in the resonators obtained through finite element analysis. The results showed that there might exist an optimum resonators spacing for achieving maximum transmission loss. However, the maximum transmission loss is not accompanied by the broadest bandwidth of attenuation. The pressure field and the sound pressure level spectra of the pressure field inside the resonators showed that the maximum transmission loss is achieved when the resonators are spaced half wavelength of the associated resonance frequency wavelength and resonate in-phase. To achieve sound attenuation over a broad frequency bandwidth, a resonator spacing of a quarter of the wavelength is required, in which case the two resonators operate out-of-phase. -

Description and Validation of a Muffler Insertion Loss Flow Rig
Description and validation of a muffler insertion loss flow rig Chen, Jonathan1 Herrin, D. W.2 University of Kentucky 151 Ralph G. Anderson Building Lexington, KY 40506-0503 ABSTRACT The performance of mufflers and silencers is greatly influenced by flow in many instances. Most labs, however, quantify performance sans flow with the use of an impedance tube using the two-load or two-source method. Measurements with flow are considerably more difficult. In this work, a test fixture capable of measuring insertion loss with flow is described. The flow is generated by an electric blower followed by a silencer to reduce the flow generated noise. Two loudspeakers are mounted downstream of the silencer but upstream of the tested muffler. Initial qualification of the system is detailed by comparing the transmission loss, noise reduction, and insertion loss to predictions using one-dimensional plane wave models. Keywords: Mufflers, Insertion Loss, Flow-Induced Noise I-INCE Classification of Subject Number: 34 1. INTRODUCTION Measurements for determining muffler transmission loss are well-established and standardized. In most cases, either the two-load [1], two-source [2], or scattering [3] method is used. These approaches require four measurement locations; two each on both the upstream and downstream sides of the test article. A four-channel data acquisition system is typically used through a two-channel system can be used. If only two microphones are used, phase calibration between microphones is no longer necessary since that term drops out in the calculation. The aforementioned techniques are straightforward and are frequently employed in both academia and industry. -
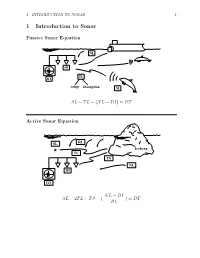
1 Introduction to Sonar 1
1 INTRODUCTION TO SONAR 1 1 Introduction to Sonar Passive Sonar Equation NL DI TL DT range absorption SL SL − TL− (NL− DI)=DT Active Sonar Equation SL RL Iceberg * TL TS NL DI DT NL− DI SL − TL TS − DT 2 + ( RL )= 1 INTRODUCTION TO SONAR 2 Tomography NL SL DT DI USA * TL Hawaii SL − TL− (NL− DI)=DT Parameter definitions: • SL = Source Level • TL = Transmission Loss • NL = Noise Level • DI = Directivity Index • RL = Reverberation Level • TS = Target Strength • DT = Detection Threshold 1 INTRODUCTION TO SONAR 3 Summary of array formulas Source Level I p2 • SL = 10 log I = 10 log 2 (general) ref pref • SL = 171 + 10 log P (omni) • SL = 171 + 10 log P + DI (directional) Directivity Index • DI = 10 log(ID ) (general) IO ID = directional intensity (measured at center of beam) IO = omnidirectional intensity (same source power radiated equally in all directions) 2L • DI = 10 log( λ ) (line array) πD 2 πD • DI = 10 log(( λ ) ) = 20 log( λ ) (disc array) • 4πLxLy DI = 10 log( λ2 ) (rect. array) 3-dB Beamwidth θ3dB 25.3λ • θ3dB = ± L deg. (line array) • ±29.5λ θ3dB = D deg. (disc array) 25.3λ 25.3λ • dB ± ± θ3 = Lx , Ly deg. (rect. array) 1 INTRODUCTION TO SONAR 4 f = 12 kHz D = 0.25 m beamwidth = +−14.65 deg −20 −40 −60 −80 −90 −60 −30 0 30 60 90 theta (degrees) f = 12 kHz D = 0.5 m beamwidth = +−7.325 deg −20 −40 −60 −80 −90 −60 −30 0 30 60 90 theta (degrees) f = 12 kHz D = 1 m beamwidth = +−3.663 deg Source level normalized to on−axis response −20 −40 −60 −80 −90 −60 −30 0 30 60 90 theta (degrees) This figure shows the beam pattern for a circular transducer for D/λ equal to 2, 4, and 8.