UA-Readiness of Open Source Code Pilot – UASG033
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
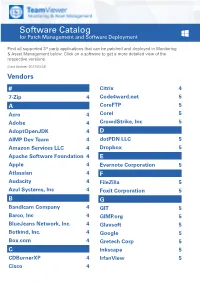
Software Catalog for Patch Management and Software Deployment
Software Catalog for Patch Management and Software Deployment Find all supported 3rd party applications that can be patched and deployed in Monitoring & Asset Management below. Click on a software to get a more detailed view of the respective versions. (Last Update: 2021/03/23) Vendors # Citrix 4 7-Zip 4 Code4ward.net 5 A CoreFTP 5 Acro 4 Corel 5 Adobe 4 CrowdStrike, Inc 5 AdoptOpenJDK 4 D AIMP Dev Team 4 dotPDN LLC 5 Amazon Services LLC 4 Dropbox 5 Apache Software Foundation 4 E Apple 4 Evernote Corporation 5 Atlassian 4 F Audacity 4 FileZilla 5 Azul Systems, Inc 4 Foxit Corporation 5 B G Bandicam Company 4 GIT 5 Barco, Inc 4 GIMP.org 5 BlueJeans Network, Inc. 4 Glavsoft 5 Botkind, Inc. 4 Google 5 Box.com 4 Gretech Corp 5 C Inkscape 5 CDBurnerXP 4 IrfanView 5 Cisco 4 Software Catalog for Patch Management and Software Deployment J P Jabra 5 PeaZip 10 JAM Software 5 Pidgin 10 Juraj Simlovic 5 Piriform 11 K Plantronics, Inc. 11 KeePass 5 Plex, Inc 11 L Prezi Inc 11 LibreOffice 5 Programmer‘s Notepad 11 Lightning UK 5 PSPad 11 LogMeIn, Inc. 5 Q M QSR International 11 Malwarebytes Corporation 5 Quest Software, Inc 11 Microsoft 6 R MIT 10 R Foundation 11 Morphisec 10 RarLab 11 Mozilla Foundation 10 Real 11 N RealVNC 11 Neevia Technology 10 RingCentral, Inc. 11 NextCloud GmbH 10 S Nitro Software, Inc. 10 Scooter Software, Inc 11 Nmap Project 10 Siber Systems 11 Node.js Foundation 10 Simon Tatham 11 Notepad++ 10 Skype Technologies S.A. -

Utilizing Mind-Maps for Information Retrieval and User Modelling
Preprint, to be published at UMAP 2014. Downloaded from http://docear.org Utilizing Mind-Maps for Information Retrieval and User Modelling Joeran Beel1,2, Stefan Langer1,2, Marcel Genzmehr1, Bela Gipp1,3 1 Docear, Magdeburg, Germany 2 Otto-von-Guericke University, Magdeburg, Germany 3 University of California, Berkeley, USA {beel | langer | genzmehr | gipp}@docear.org Abstract. Mind-maps have been widely neglected by the information retrieval (IR) community. However, there are an estimated two million active mind-map users, who create 5 million mind-maps every year, of which a total of 300,000 is publicly available. We believe this to be a rich source for information retriev- al applications, and present eight ideas on how mind-maps could be utilized by them. For instance, mind-maps could be utilized to generate user models for recommender systems or expert search, or to calculate relatedness of web-pages that are linked in mind-maps. We evaluated the feasibility of the eight ideas, based on estimates of the number of available mind-maps, an analysis of the content of mind-maps, and an evaluation of the users’ acceptance of the ideas. We concluded that user modelling is the most promising application with re- spect to mind-maps. A user modelling prototype – a recommender system for the users of our mind-mapping software Docear – was implemented, and evalu- ated. Depending on the applied user modelling approaches, the effectiveness, i.e. click-through rate on recommendations, varied between 0.28% and 6.24%. This indicates that mind-map based user modelling is promising, but not trivial, and that further research is required to increase effectiveness. -

Xmind ZEN 9.1.3 Crack FREE Download
1 / 4 XMind ZEN 9.1.3 Crack FREE Download Download XMind ZEN 9.2.1 Build Windows / 9.1.3 macOS for free at ... Version 9.2.1 is cracked, then install the program and click Skip in the Login window.. Adobe Premiere Pro CC 2019 13.1.2 – For macOS Cracked With Serial Number.. Free Download XMind ZEN 9.1.3 Build. 201812101752 Win / macOS Cracked .... 3 Crack + Serial Key Free Download. Malwarebytes 4.2.3 Crack Real-time safety of all threats very effectively. This is a .... ZW3D 2019 SP2 Download 32-64 Bit For Windows. The Powerful engineering ... XMind ZEN 9.1.3 Download. Free Download Keysight .... With this app, you can download online maps, digital maps and even ... Tableau Desktop Pro 2019.4.0 Win + Crack · XMind ZEN 9.2.0 Build .... Download Free XMind: ZEN 9.1.3 Build 201812101752 for Mac on Mac Torrent Download. XMind: ZEN 9.1.3 Build 201812101752 is a .... XMind 8 Pro 3 7 6 Mac Crack Full version free download is the latest version of the most advanced and Popular Mind ... XMind ZEN for Mac 9.1.3 Serial Key ... Download Nero KnowHow for PC - free download Nero KnowHow for ... The full version comes in single user and a family variant with the former costing ... Download XMind ZEN 9.2.1 Build Windows / 9.1.3 macOS for free at .... XMind ZEN Crack 10.3.0 With Keygen Full Torrent Download 2021 For PC · XMind Crack 9.1.3 With Keygen Full Torrent Download 2019 For PC. -

Concept Mapping Slide Show
5/28/2008 WHAT IS A CONCEPT MAP? Novak taught students as young as six years old to make Concept Mapping is a concept maps to represent their response to focus questions such as “What is technique for knowledge water?” and “What causes the Assessing learner understanding seasons?” assessment developed by JhJoseph D. NkNovak in the 1970’s Novak’s work was based on David Ausubel’s theories‐‐stressed the importance of prior knowledge in being able to learn new concepts. If I don’t hold my ice cream cone The ice cream will fall off straight… A WAY TO ORGANIZE A WAY TO MEASURE WHAT WE KNOW HOW MUCH KNOWLEDGE WE HAVE GAINED A WAY TO ACTIVELY A WAY TO IDENTIFY CONSTRUCT NEW CONCEPTS KNOWLEDGE 1 5/28/2008 Semantics networks words into relationships and gives them meaning BRAIN‐STORMING GET THE GIST? oMINDMAP HOW TO TEACH AN OLD WORD CLUSTERS DOG NEW TRICKS?…START WITH FOOD! ¾WORD WEBS •GRAPHIC ORGANIZER 9NETWORKING SCAFFOLDING IT’S ALL ABOUT THE NEXT MEAL, RIGHT FIDO?. EFFECTIVE TOOLS FOR LEARNING COLLABORATIVE 9CREATE A STUDY GUIDE CREATIVE NOTE TAKING AND SUMMARIZING SEQUENTIAL FIRST FIND OUT WHAT THE STUDENTS KNOW IN RELATIONSHIP TO A VISUAL TRAINING SUBJECT. STIMULATING THEN PLAN YOUR TEACHING STRATEGIES TO COVER THE UNKNOWN. PERSONAL COMMUNICATING NEW IDEAS ORGANIZING INFORMATION 9AS A KNOWLEDGE ASSESSMENT TOOL REFLECTIVE LEARNING (INSTEAD OF A TEST) A POST‐CONCEPT MAP WILL GIVE INFORMATION ABOUT WHAT HAS TEACHING VOCABULARLY BEEN LEARNED ASSESSING KNOWLEDGE 9PLANNING TOOL (WHERE DO WE GO FROM HERE?) IF THERE ARE GAPS IN LEARNING, RE‐INTEGRATE INFORMATION, TYING IT TO THE PREVIOUSLY LEARNED INFORMATION THE OBJECT IS TO GENERATE THE LARGEST How do you construct a concept map? POSSIBLE LIST Planning a concept map for your class IN THE BEGINNING… LIST ANY AND ALL TERMS AND CONCEPTS BRAINSTORMING STAGE ASSOCIATED WITH THE TOPIC OF INTEREST ORGANIZING STAGE LAYOUT STAGE WRITE THEM ON POST IT NOTES, ONE WORD OR LINKING STAGE PHRASE PER NOTE REVISING STAGE FINALIZING STAGE DON’T WORRY ABOUT REDUNCANCY, RELATIVE IMPORTANCE, OR RELATIONSHIPS AT THIS POINT. -

Software Effektiv Nützen Für Die Vorwissenschaftliche Arbeit Und BHS-Diplomarbeit Zeit Sparen Durch Sinnvollen Softwareeinsatz
Friedrich Saurer Software effektiv nützen für die vorwissenschaftliche Arbeit und BHS-Diplomarbeit Zeit sparen durch sinnvollen Softwareeinsatz Stand Oktober 2016 www.VorWissenschaftlicheArbeit.info Impressum Autor Ing. Mag. Friedrich Saurer Unterrichtet am Gymnasium Hartberg Ausbildung: Studium Physik, Chemie (Lehramt) Zusatzausbildungen: . Projektmanagement . Informatiklehrer . Train the Trainer: Lehrgang Vorwissenschaftliche Arbeit . Train the Trainer: Textkompetenz Webseiten www.VorwissenschaftlicheArbeit.info Lizenz Dieses E-Book steht unter einer CC-BY-ND – Lizenz. Das bedeutet: Sie dürfen dieses E-Book unverändert weitergeben (z.B. zum Download anbieten, im E-Learning-Portal der Schule integrieren, im Rahmen von Seminaren und Fortbildungen weitergeben usw.). https://creativecommons.org/licenses/by-nd/4.0/deed.de Die Icons wurden über die Webseite www.thenounproject.com lizenziert. Zu beachten: Es wird keine Haftung für die Richtigkeit übernommen. Die Informationen basieren auf dem Stand Oktober 2016. Falls eine Aktualisierung vorhanden ist, finden Sie diese auf der Webseite: www.VorWissenschaftlicheArbeit.info Software effektiv nützen für die VWA und BHS-Diplomarbeit 2 Vorwort Verschiedene Computerprogramme und Apps können das Arbeiten an der vorwissenschaftlichen Arbeit bzw. BHS-Diplomarbeit erleichtern. In diesem E-Book wird ein Sammelsurium an Software vorgestellt, das sich für den Einsatz eignet. Dabei werden (abgesehen vom Microsoft Office Paket) ausschließlich kostenlose Programme angesprochen bzw. empfohlen. Es werden Programme und Apps für die Betriebssysteme Windows und Android vorgestellt. Bei Computern / Laptops / Notebooks / … hat Windows den größten Marktanteil und ist in nahezu allen Schulen das Betriebssystem. Bei den Smartphones dominiert Android den Markt. Viele (vor allem auch quellenoffene) Programme gibt es auch für iOS und Linux, allerdings würde das den Rahmen sprengen und an der Zielgruppe vorbeischlittern. -

Mindmapping for Beg and Strug Learners.Pdf
MindMapping Frank Sapp Technology and Training Specialist [email protected] MindMapping MindMapping • Introduction • Defined • Brief History • Subtopic 3 • Types Defined • A mind map is a diagram used to visually organise information. A mind map is often created around a single concept, drawn as an image in the center of a blank landscape page, to which associated representations of ideas such as images, words and parts of words are added. Major ideas are connected directly to the central concept, and other ideas branch out from those. Brief History • Early • Tony Buzan • Data Visualization • Research Early • Radial Maps • Spider Diagrams Radial Maps • Spider Diagrams • Tony Buzan • Video Data Visualization • Edward Tufte • Napoleon Russian Invasion • PowerPoint Edward Tufte • Napoleon Russian Invasion • Napoleon Russian Invasion • The graph displays several variables in a single two-dimensional image: • the size of the army - providing a strong visual representation of human suffering, e.g. the sudden decrease of the army's size at the battle crossing the Berezina river on the retreat; • the geographical co-ordinates, latitude and longitude, of the army as it moved; • the direction that the army was traveling, both in advance and in retreat, showing where units split off and rejoined; • the location of the army with respect to certain dates; and • the weather temperature along the path of the retreat, in another strong visualisation of events (during the retreat "one of the worst winters in recent memory set in"[1]). • Étienne-Jules Marey first called notice to this dramatic depiction of the fate of Napoleon's army in the Russian campaign, saying it "defies the pen of the historian in its brutal eloquence"[citation needed]. -
Pick Technologies & Tools Faster by Coding with Jhipster: Talk Page At
Picks, configures, and updates best technologies & tools “Superstar developer” Writes all the “boring plumbing code”: Production grade, all layers What is it? Full applications with front-end & back-end Open-source Java application generator No mobile apps Generates complete application with user Create it by running wizard or import management, tests, continuous integration, application configuration from JHipster deployment & monitoring Domain Language (JDL) file Import data model from JDL file Generates CRUD front-end & back-end for our entities Re-import after JDL file changes Re-generates application & entities with new JHipster version What does it do? Overwriting your own code changes can be painful! Microservices & Container Updates application Receive security patches or framework Fullstack Developer updates (like Spring Boot) Shift Left Sometimes switches out library: yarn => npm, JavaScript test libraries, Webpack => Angular Changes for Java developers from 10 years CLI DevOps ago JHipster picked and configured technologies & Single Page Applications tools for us Mobile Apps We picked architecture: monolith Generate application Generated project Cloud Live Demo We picked technologies & tools (like MongoDB or React) Before: Either front-end or back-end developer inside app server with corporate DB Started to generate CRUD screens Java back-end Generate CRUD Before and after Web front-end Monolith and microservices After: Code, test, run & support up to 4 applications iOS front-end Java and Kotlin More technologies & tools? Android -

Jhipster.NET Documentation!
JHipster.NET Release 3.1.1 Jul 28, 2021 Introduction 1 Big Picture 3 2 Getting Started 5 2.1 Prerequisites...............................................5 2.2 Generate your first application......................................5 3 Azure 7 3.1 Deploy using Terraform.........................................7 4 Code Analysis 9 4.1 Running SonarQube by script......................................9 4.2 Running SonarQube manually......................................9 5 CQRS 11 5.1 Introduction............................................... 11 5.2 Create your own Queries or Commands................................. 11 6 Cypress 13 6.1 Introduction............................................... 13 6.2 Pre-requisites............................................... 13 6.3 How to use it............................................... 13 7 Database 15 7.1 Using database migrations........................................ 15 8 Dependencies Management 17 8.1 Nuget Management........................................... 17 8.2 Caution.................................................. 17 9 DTOs 19 9.1 Using DTOs............................................... 19 10 Entities auditing 21 10.1 Audit properties............................................. 21 10.2 Audit of generated Entities........................................ 21 10.3 Automatically set properties audit.................................... 22 11 Fronts 23 i 11.1 Angular.................................................. 23 11.2 React................................................... 23 11.3 Vue.js.................................................. -

Cross-Layer Cloud Performance Monitoring, Analysis and Recovery
Cross-Layer Cloud Performance Monitoring, Analysis and Recovery Dissertation zur Erlangung des akademischen Grades eines Doktors der Naturwissenschaften (Dr. rer. nat.) dem Fachbereich Mathematik und Informatik der Philipps-Universit¨atMarburg vorgelegt von M.Sc. Afef Mdhaffar geboren in Sfax, Tunesien Marburg, 2014 Hochschulkennziffer 1180 Vom Fachbereich Mathematik und Informatik der Philipps-Universit¨atMarburg als Dissertation am 19.12.2014 angenommen. Erstgutachter: Prof. Dr. Bernd Freisleben, Philipps-Universit¨atMarburg Zweitgutachter: Prof. Dr. Mohamed Jmaiel, Universit´ede Sfax, Tunisia Tag der Einreichung: 20.11.2014 Tag der m¨undlichen Pr¨ufung:19.12.2014 Abstract The basic idea of Cloud computing is to offer software and hardware resources as services. These services are provided at different layers: Software (Software as a Service: SaaS), Platform (Platform as a Service: PaaS) and Infrastructure (Infrastructure as a Service: IaaS). In such a complex environment, performance issues are quite likely and rather the norm than the exception. Consequently, performance-related problems may frequently occur at all layers. Thus, it is necessary to monitor all Cloud layers and analyze their performance parameters to detect and rectify related problems. This thesis presents a novel cross-layer reactive performance monitoring ap- proach for Cloud computing environments, based on the methodology of Complex Event Processing (CEP). The proposed approach is called CEP4Cloud. It an- alyzes monitored events to detect performance-related problems and performs actions to fix them. The proposal is based on the use of (1) a novel multi-layer monitoring approach, (2) a new cross-layer analysis approach and (3) a novel recovery approach. The proposed monitoring approach operates at all Cloud layers, while col- lecting related parameters. -

Le Mind Mapping , Ou Carte Heuristique Appelé Encore Carte Conceptuelle
TECHNOLOGIE - Document professeur- Le Mind Mapping , ou carte heuristique appelé encore Carte conceptuelle Un outil dans la démarche de résolution de problème De quoi s’agit-il exactement ? Concrètement il s’agit d’un diagramme qui représente les connexions sémantiques entre différentes idées, les liens hiérarchiques entre différents concepts intellectuels. C’est en quelque sorte une nouvelle façon de faire naître des idées (maïeutique) de prendre des notes en structurant celles-ci pour mieux les retenir et les associer. Cet outil peut être utilisé par le professeur ou par les élèves au sein de la classe ou au sein d’un groupe dans plusieurs situations : - pour exprimer un besoin, - pour analyser et définir le problème, - pour réaliser une étude de faisabilité, - pour rechercher des solutions, - pour mettre en commun des idées, formuler des hypothèses, des solutions, - pour structurer des connaissances, - pour mener à bien une synthèse, - pour restituer des notions, des concepts, des connaissances, - … Des outils logiciels libres et gratuits : Freemind Présentation : http://www.logiciels-libres-tice.org/spip.php?article297 Pour le télécharger : http://www.01net.com/telecharger/windows/Loisirs/education_et_scolarite/fiches/34923.html Un tutoriel : http://www2.ac- rennes.fr/crdp/29/ie/aides/techno/freemind/freemind_prise_en_main.html Freeplane = le prolongement de Freemind est un logiciel libre qui permet de créer des cartes heuristiques (ou Mind Map), diagrammes représentant les connexions sémantiques entre différentes idées. Des fonctions qui existaient déjà dans Freemind , http://sourceforge.net/projects/freeplane/ J-Louis LAMBERBOURG 1/5 TECHNOLOGIE - Document professeur- Xmind : Plus performant et ergonomique que Freeplane, Xmind est désormais disponible en français. -

Getting Started with the Jhipster Micronaut Blueprint
Getting Started with the JHipster Micronaut Blueprint Frederik Hahne Jason Schindler JHipster Team Member 2GM Team Manager & Partner @ OCI @atomfrede @JasonTypesCodes © 2021, Object Computing, Inc. (OCI). All rights reserved. No part of these notes may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior, written permission of Object Computing, Inc. (OCI) Ⓒ 2021 Object Computing, Inc. All rights reserved. 1 micronaut.io Micronaut Blueprint for JHipster v1.0 Released! Ⓒ 2021 Object Computing, Inc. All rights reserved. 2 micronaut.io JHipster is is a development platform to quickly generate, develop, & deploy modern web applications & microservice architectures. A high-performance A sleek, modern, A powerful workflow Infrastructure as robust server-side mobile-first UI with to build your code so you can stack with excellent Angular, React, or application with quickly deploy to the test coverage Vue + Bootstrap for Webpack and cloud CSS Maven or Gradle Ⓒ 2021 Object Computing, Inc. All rights reserved. 3 micronaut.io JHipster in Numbers ● 18K+ Github Stars ● 600+ Contributors on the main generator ● 50K registered users on start.jhipster.tech ● 40K+ weekly download via npmjs.com ● 100K annual budget from individual and institutional sponsors ● Open Source under Apache License ● 51% JavaScript, 20% TypeScript, 18% Java Ⓒ 2021 Object Computing, Inc. All rights reserved. 4 micronaut.io JHipster Overview ● Platform to quickly generate, develop, & deploy modern web applications & microservice architectures. ● Started in 2013 as a bootstrapping generator to create Spring Boot + AngularJS applications ● Today creating production ready application, data entities, unit-, integration-, e2e-tests, deployments and ci-cd configurations ● Extensibility via modules or blueprints ● Supporting wide range of technologies from the JVM and non-JVM ecosystem ○ E.g. -

Mind Mapping Your Way to Better Code a Simple Tool Delivers Big Benefits in Design and Implementation of Code, Especially on Personal Projects
Search Java Magazine Menu Topics Issues Downloads Subscribe January 2020 Mind Mapping Your Way to Better FROM THE EDITOR Code Mind Mapping Your Way to Better Code A simple tool delivers big benefits in design and implementation of code, especially on personal projects. by Andrew Binstock January 10, 2020 For much of the last year, I have been discussing tools and techniques to make coding clearer, more reliable, and more consistent with your immediate goals. In this series, I have discussed the beneficial use of comments to design and plan code and taking notes as you code. At times, though, you encounter the need to do some simple, back-of-the- envelope kind of design, in which you track what you need to do and where you are in relation to the undone tasks. Moreover, as you work, you regularly add other tasks to be done that integrate with the existing list of remaining work. I find that this kind of recording arises particularly on personal projects, where I can hold the entire project in my head as I code. That capacity is a great benefit in that it helps me to anticipate dependencies, breaking changes, and so forth. But it quickly becomes a heavy habit when I need to track reminders to myself and coding notes all in my head. Having an effective way to diagram and track the tasks and their important traits inside a large project map is a huge benefit. Mind maps represent an effective and easy way of capturing just this kind of data—allowing you to reclaim the mental space it otherwise occupies.