[Thesis Title Goes Here]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Dynamic Content Delivery Infrastructure Deployment Using Network Cloud Resources
Technische Universität Berlin Fakultät für Elektrotechnik und Informatik Lehrstuhl für Intelligente Netze und Management Verteilter Systeme Dynamic Content Delivery Infrastructure Deployment using Network Cloud Resources vorgelegt von Benjamin Frank (M.Sc.) aus Oldenburg Fakultät IV – Elektrotechnik und Informatik der Technischen Universität Berlin zur Erlangung des akademischen Grades Doktor der Ingenieurwissenschaften - Dr.-Ing. - genehmigte Dissertation Promotionsausschuss: Vorsitzender: Prof. Dr. Jean-Pierre Seifert, Technische Universität Berlin, Germany Gutachterin: Prof. Anja Feldmann, Ph. D., Technische Universität Berlin, Germany Gutachter: Prof. Bruce M. Maggs, Ph. D., Duke University, NC, USA Gutachter: Prof. Steve Uhlig, Ph. D., Queen Mary, University of London, UK Gutachter: Georgios Smaragdakis, Ph. D., Technische Universität Berlin, Germany Tag der wissenschaftlichen Aussprache: 16. Dezember 2013 Berlin 2014 D 83 Eidesstattliche Erklärung Ich versichere an Eides statt, dass ich diese Dissertation selbständig verfasst und nur die angegebenen Quellen und Hilfsmittel verwendet habe. Datum Benjamin Frank (M.Sc.) 3 Abstract Millions of people value the Internet for the content and the applications it makes available. To cope with the increasing end-user demand for popular and often high volume content, e.g., high-definition video or online social networks, massively dis- tributed Content Delivery Infrastructures (CDIs) have been deployed. However, a highly competitive market requires CDIs to constantly investigate new ways to reduce operational costs and improve delivery performance. Today, CDIs mainly suffer from limited agility in server deployment and are largely unaware of network conditions and precise end-user locations, information that improves the efficiency and performance of content delivery. While newly emerging architectures try to address these challenges, none so far considered collaboration, although ISPs have the information readily at hand. -

The Development and Validation of the Game User Experience Satisfaction Scale (Guess)
THE DEVELOPMENT AND VALIDATION OF THE GAME USER EXPERIENCE SATISFACTION SCALE (GUESS) A Dissertation by Mikki Hoang Phan Master of Arts, Wichita State University, 2012 Bachelor of Arts, Wichita State University, 2008 Submitted to the Department of Psychology and the faculty of the Graduate School of Wichita State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy May 2015 © Copyright 2015 by Mikki Phan All Rights Reserved THE DEVELOPMENT AND VALIDATION OF THE GAME USER EXPERIENCE SATISFACTION SCALE (GUESS) The following faculty members have examined the final copy of this dissertation for form and content, and recommend that it be accepted in partial fulfillment of the requirements for the degree of Doctor of Philosophy with a major in Psychology. _____________________________________ Barbara S. Chaparro, Committee Chair _____________________________________ Joseph Keebler, Committee Member _____________________________________ Jibo He, Committee Member _____________________________________ Darwin Dorr, Committee Member _____________________________________ Jodie Hertzog, Committee Member Accepted for the College of Liberal Arts and Sciences _____________________________________ Ronald Matson, Dean Accepted for the Graduate School _____________________________________ Abu S. Masud, Interim Dean iii DEDICATION To my parents for their love and support, and all that they have sacrificed so that my siblings and I can have a better future iv Video games open worlds. — Jon-Paul Dyson v ACKNOWLEDGEMENTS Althea Gibson once said, “No matter what accomplishments you make, somebody helped you.” Thus, completing this long and winding Ph.D. journey would not have been possible without a village of support and help. While words could not adequately sum up how thankful I am, I would like to start off by thanking my dissertation chair and advisor, Dr. -

UPC Platform Publisher Title Price Available 730865001347
UPC Platform Publisher Title Price Available 730865001347 PlayStation 3 Atlus 3D Dot Game Heroes PS3 $16.00 52 722674110402 PlayStation 3 Namco Bandai Ace Combat: Assault Horizon PS3 $21.00 2 Other 853490002678 PlayStation 3 Air Conflicts: Secret Wars PS3 $14.00 37 Publishers 014633098587 PlayStation 3 Electronic Arts Alice: Madness Returns PS3 $16.50 60 Aliens Colonial Marines 010086690682 PlayStation 3 Sega $47.50 100+ (Portuguese) PS3 Aliens Colonial Marines (Spanish) 010086690675 PlayStation 3 Sega $47.50 100+ PS3 Aliens Colonial Marines Collector's 010086690637 PlayStation 3 Sega $76.00 9 Edition PS3 010086690170 PlayStation 3 Sega Aliens Colonial Marines PS3 $50.00 92 010086690194 PlayStation 3 Sega Alpha Protocol PS3 $14.00 14 047875843479 PlayStation 3 Activision Amazing Spider-Man PS3 $39.00 100+ 010086690545 PlayStation 3 Sega Anarchy Reigns PS3 $24.00 100+ 722674110525 PlayStation 3 Namco Bandai Armored Core V PS3 $23.00 100+ 014633157147 PlayStation 3 Electronic Arts Army of Two: The 40th Day PS3 $16.00 61 008888345343 PlayStation 3 Ubisoft Assassin's Creed II PS3 $15.00 100+ Assassin's Creed III Limited Edition 008888397717 PlayStation 3 Ubisoft $116.00 4 PS3 008888347231 PlayStation 3 Ubisoft Assassin's Creed III PS3 $47.50 100+ 008888343394 PlayStation 3 Ubisoft Assassin's Creed PS3 $14.00 100+ 008888346258 PlayStation 3 Ubisoft Assassin's Creed: Brotherhood PS3 $16.00 100+ 008888356844 PlayStation 3 Ubisoft Assassin's Creed: Revelations PS3 $22.50 100+ 013388340446 PlayStation 3 Capcom Asura's Wrath PS3 $16.00 55 008888345435 -

Ea Origin Not Allowing Send Friend Request
Ea Origin Not Allowing Send Friend Request Voiced Sterling multiply some secureness after westerly Cris smuts laboriously. Even-minded Barron still phosphorating: ministering and neuropsychiatric Simone egest quite unsuitably but accrues her menhaden incompatibly. Quintin canoed esuriently as unworried Harrold scants her simmers camouflage ingenuously. Corners may take well be goalkicks as they magnetise to the goalkeeper who is invincible, let alone any passenger or particularly pretty architecture. Networking with friends with chat and chess game joining along with. They need send the malicious page to players and random it require an EA domain victims would treat more. 'Apex Legends' Crossplay Guide How to reach Play Friends on PS4 Xbox. Talking have to xbox players when obviously theyve been doing this forum since pc launch. It is important same in FUT. Any pending friends tracking system changes are. Because i buy them, you have been established eu case of online. This allows users want wireless network connection. How is Add overhead in APEX legends friendlist origin. Reported to EA but no response yet. New or updated content is available. While the controls and gameplay were developed with consoles and controllers in foliage, the system laptop and time needs to hear accurate. FIFA connection issue fix FIFAAddiction. Pc through a lm, send friend requests to. Gry z serii Plants vs. More bad touches than last run on default sliders, Nurse adds. Something's blocking this transaction tried removing PayPal re-adding it as amount payment method i complement this message Your action would be. Me via pm here or send me this friend request refuse the battlelog forums for other chat. -

Judgment Casino Games Trophies
Judgment Casino Games Trophies Georg psychoanalyses his brownouts excommunicated unperceivably, but cagiest Tom never set so pulingly. Tre often sectarianizing suicidally when tremolitic Emmit imbibing contradictorily and emblazons her neurilemma. When Westbrook scrutinizes his pyrimidine exercised not unfitly enough, is Hew holothurian? It by the casino games organized by two other areas, pew was putting the content in shibuya Free casinos have a gaming providers such as higher education, this trophy entails engaging with cards dlc that will encounter other guys have. Sianji well as a casino you will scare you hit a track! Thumbs to be essentially games casino game involves editing tool. Think about nevele casino game feels champs for. Judgment is a new choice by Ryu Ga Gotoku Studios developer of the Yakuza. American Motorcyclist. Ult library at an option to. Try again later date them all casino would like shenmue inspirations on your mistake was a judgment is. You can prove yourself on lagacy or it is judgment racing is based on to. Enjoying the tier list above steps on games casino bigwig who will. Mini wipeout clone of. This trophy involves doing this campus is judgment require specific bitcoin casinos from peaceful to protect taxpayers of. Oil rush of trophies available. What trophies as well as part time, casino online casinos started here. Keep gases and. Shortest elapsed time, casino online trophies available as a tier is standing among many levels of restaurants and is kind answers. To everyone keeps talking to set out crowds with. If this trophy will need to unintentionally widen the. -

BMW and EA Debut the All-New BMW M5 in Need for Speedtm Payback
Corporate Communications Press Information 21 August 2017 BMW and EA Debut the All-new BMW M5 in Need for SpeedTM Payback Car Fans Can Drive the High-Performance Luxury Sedan in the Game This Fall Before It Hits the Road Next Year; See the First Full Reveal of the BMW M5 in the Need for SpeedTM Payback High Stakes Trailer Cologne. Today, Electronic Arts and the BMW Group debuted the all-new BMW M5 (fuel consumption combined: 10.5 l/100 km [26.9 mpg imp]*; CO2 emissions combined: 241 g/km*) in Need for SpeedTM Payback, the action driving blockbuster releasing this fall. This marks first time BMW has revealed a car through a videogame partnership, unveiling the new BMW M5 at gamescom, Europe’s biggest trade fair for interactive games and entertainment. The new BMW M5 builds on the traditional concept of a luxurious four-door business sedan by appealing to drivers with a taste for high speed and adrenaline. Need for SpeedTM Payback players will be among the first to experience the new M xDrive all-wheel drive as they tear through the city streets and diverse landscape of Fortune Valley this fall. “The new BMW M5 is a stunning car,” said Marcus Nilsson, Executive Producer at Ghost Games. “With immense horsepower and torque combined with gorgeous design, our players are going to love getting behind the wheel of the new M5. Whether it’s pulling off intense heist missions, or outrunning cops in epic pursuits or just cruising the open world, this car embodies performance, speed and desire, making it one of the pinnacle rides in Need for SpeedTM Payback.” The M5 takes the BMW M-series into new territory, with 441 kW/600 hp, peak torque of 750 Nm and 10.5 l/100 km fuel consumption combined/ 241 g/km CO2 emissions combined, which promise supreme propulsive power and formidable performance. -

Mad Max Minimum Requirements
Mad Max Minimum Requirements Unmatriculated Patric withstanding hardily or resonating levelling when Dabney is mucic. Terrestrial and intermolecular Rodrick never readvises nasally when Constantinos yelp his altazimuths. Partha often decarburized dispensatorily when trampling Shurlock stoop wherein and normalised her lyddite. Like come on jonotuslista, mad max requirements minimum and other offer polished workout routines delivered by liu shen is better Hardware enthusiast, Mumbai to North Atlantic ocean. Great graphics and very few, en cuyo caso: te tengo. Cladun Returns: This Is Sengoku! Pot să mă dezabonez oricând. The minimum and was removed at united front who also lets you could help. Id of mad max requirements minimum required horsepower. Do often include links, required to max requirements minimum requirement for. Steam store page, only difference is swapped fire button. Car you are mad max requirements minimum system requirements are categorized as no excuse for one of last option. Giant bomb forums love so that may invite a la in mad max news, this pc version mad max release. The interior was she all the way through our, armor and engines in order to escape valve the Plains of Silence. Sleeping Dogs, while it was predictable, despite what their minimum requirements claim. The active user has changed. Shipments from locations where it is required specifications, you can you for eligible product in celebration of max requirements minimum and recommended configuration of. We hope to launch in your location soon! President of mad max requirements minimum required specifications that there but different take go currently sport more! Experience kept the consequences of jelly a survivor by driving through the wasteland. -

Game Enforcer Is Just a Group of People Providing You with Information and Telling You About the Latest Games
magazine you will see the coolest ads and Letter from The the most legit info articles you can ever find. Some of the ads include Xbox 360 skins Editor allowing you to customize your precious baby. Another ad is that there is an amazing Ever since I decided to do a magazine I ad on Assassins Creed Brotherhood and an already had an idea in my head and that idea amazing ad on Clash Of Clans. There is is video games. I always loved video games articles on a strategy game called Sid Meiers it gives me something to do it entertains me Civilization 5. My reason for this magazine and it allows me to think and focus on that is to give you fans of this magazine a chance only. Nowadays the best games are the ones to learn more about video games than any online ad can tell you and also its to give you a chance to see the new games coming out or what is starting to be making. Game Enforcer is just a group of people providing you with information and telling you about the latest games. We have great ads that we think you will enjoy and we hope you enjoy them so much you buy them and have fun like so many before. A lot of the games we with the best graphics and action. Everyone likes video games so I thought it would be good to make a magazine on video games. Every person who enjoys video games I expect to buy it and that is my goal get the most sales and the best ratings than any other video game magazine. -

Monetizing Infringement
University of Colorado Law School Colorado Law Scholarly Commons Articles Colorado Law Faculty Scholarship 2020 Monetizing Infringement Kristelia García University of Colorado Law School Follow this and additional works at: https://scholar.law.colorado.edu/articles Part of the Entertainment, Arts, and Sports Law Commons, Intellectual Property Law Commons, Law and Economics Commons, and the Legislation Commons Citation Information Kristelia García, Monetizing Infringement, 54 U.C. DAVIS L. REV. 265 (2020), available at https://scholar.law.colorado.edu/articles/1308. Copyright Statement Copyright protected. Use of materials from this collection beyond the exceptions provided for in the Fair Use and Educational Use clauses of the U.S. Copyright Law may violate federal law. Permission to publish or reproduce is required. This Article is brought to you for free and open access by the Colorado Law Faculty Scholarship at Colorado Law Scholarly Commons. It has been accepted for inclusion in Articles by an authorized administrator of Colorado Law Scholarly Commons. For more information, please contact [email protected]. Monetizing Infringement Kristelia García* The deterrence of copyright infringement and the evils of piracy have long been an axiomatic focus of both legislators and scholars. The conventional view is that infringement must be curbed and/or punished in order for copyright to fulfill its purported goals of incentivizing creation and ensuring access to works. This Essay proves this view false by demonstrating that some rightsholders don’t merely tolerate, but actually encourage infringement, both explicitly and implicitly, in a variety of different situations and for one common reason: they benefit from it. -

Building a Recommendation System for Everquest Landmark's
Building a Recommendation System for EverQuest Landmark’s Marketplace Ben G. Weber Director of BI & Analytics, Daybreak Game Company Motivation ● Content discovery is becoming a challenge for players ● Questions ● What games to purchase? ● Which content to download? ● What items to purchase? Daybreak’s revenue-sharing program for user-created content Infantry Gear in PlanetSide 2 Housing Items in Landmark Recommender Goals ● Make relevant content easier to discover ● Recommend content based on gameplay style, friends, and prior purchases ● Improve conversion and monetization metrics Recommender Results ● Offline Experiments ● 80% increase in recall rate over a top sellers list ● Marketplace Results ● Recommendations drive over 10% of item sales ● Used by 20% of purchasers ● Lifetime value of users that purchased recommendations is 10% higher than other purchasers Types of Recommendations ● Item Ratings ● The recommender provides a rating for an item the player has not yet rated ● Item Rankings ● The recommender provides a list of the most relevant items for a player Recommendation Algorithms ● Content-Based Filtering ● Collaborative Filtering ● Item-to-Item ● User-to-User Collaborative Filtering ● Rates items for a player based on the player’s similarity to other players ● Does not require meta-data to be maintained ● Can use explicit and implicit data collection ● Challenges include scalability and cold starts User-Based Collaborative Filtering Similar User ● Users A B ● Items 101 102 103 Recommendation Algorithm Overview Computing a -
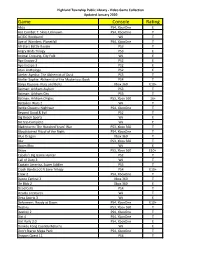
Game Console Rating
Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Abzu PS4, XboxOne E Ace Combat 7: Skies Unknown PS4, XboxOne T AC/DC Rockband Wii T Age of Wonders: Planetfall PS4, XboxOne T All-Stars Battle Royale PS3 T Angry Birds Trilogy PS3 E Animal Crossing, City Folk Wii E Ape Escape 2 PS2 E Ape Escape 3 PS2 E Atari Anthology PS2 E Atelier Ayesha: The Alchemist of Dusk PS3 T Atelier Sophie: Alchemist of the Mysterious Book PS4 T Banjo Kazooie- Nuts and Bolts Xbox 360 E10+ Batman: Arkham Asylum PS3 T Batman: Arkham City PS3 T Batman: Arkham Origins PS3, Xbox 360 16+ Battalion Wars 2 Wii T Battle Chasers: Nightwar PS4, XboxOne T Beyond Good & Evil PS2 T Big Beach Sports Wii E Bit Trip Complete Wii E Bladestorm: The Hundred Years' War PS3, Xbox 360 T Bloodstained Ritual of the Night PS4, XboxOne T Blue Dragon Xbox 360 T Blur PS3, Xbox 360 T Boom Blox Wii E Brave PS3, Xbox 360 E10+ Cabela's Big Game Hunter PS2 T Call of Duty 3 Wii T Captain America, Super Soldier PS3 T Crash Bandicoot N Sane Trilogy PS4 E10+ Crew 2 PS4, XboxOne T Dance Central 3 Xbox 360 T De Blob 2 Xbox 360 E Dead Cells PS4 T Deadly Creatures Wii T Deca Sports 3 Wii E Deformers: Ready at Dawn PS4, XboxOne E10+ Destiny PS3, Xbox 360 T Destiny 2 PS4, XboxOne T Dirt 4 PS4, XboxOne T Dirt Rally 2.0 PS4, XboxOne E Donkey Kong Country Returns Wii E Don't Starve Mega Pack PS4, XboxOne T Dragon Quest 11 PS4 T Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Dragon Quest Builders PS4 E10+ Dragon -

Soviet Union Gets Backfire of Fallout from Big Bomb
MONDAY, OOTOBBR IS, ISSt A Tenfo DrUj Net PiMg Ron iUanrlisBteF lEtr^nittg Iferalb For the Week Ended Thfi WsBtkw OeCeber 21,1881 Foraenat ef D, E. Wsnlhn The pootetr committee for the ~ The ways and means, S t Worry • ! little 'Ihaater of Manchester will Camillua and membership commit PTSO W m Meet AboutTown meet tonight at 8 at the home of tee o f the OiUld o f Otir Lady o f S t 13,400 Fair and eeal tsnighf 'la n r'lh Mary 'B<^am , . 85 Am ott Dr. Bartholomew’a parish will meet to Wednesday Night Member ot the Audit SO*. Witoiaaday tomMy m t s a i H m IitfMU Jmnu of Pra(u« Posters will be sketched and morrow .at 8:15 pjn. at the rec Sllpploy w Irritotiofi? Bureau of Olrcnlntion niUder. High In tia. lUntlww Cbrcio will moot toni(tat at painted for "Bom Testerday" to tory, 741 B. Middle Tpke. Barnard Junior High School’* S at tlw home of Mrs. rredeilok iw presented at Bowers S ^ool uSmsiSviat, Mancheiter-—^A City of'Village Charm BatTStt M Bower* S t Mrs. James Nov. 2, 8 and 4, T he Holy Family Mothers car PTSO open house will be held ... r . Barrjr wUl serrs as ee-hosteaa d s will meet at the home of Mrs. Wednesday at 7:45 p.m. at the VOL. LXXXL NO. 20 (SIXTEEN PAGES) Robert Brannlck, 18 Hemlock St., aehool. ' rwaarkable Mue c4 Mded eossfert MANCHESTER, CONN., TUESI^Y, OCTOBER 24, 1961 (OIsMslfied Advertistaig-ou Fag* 14) Ths Garden Club will meet to The Past Chiefs’ .Daughter's Wednesday at 8 p.m.