AIDA64 Engineer Manual
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

07 Vectorization for Intel C++ & Fortran Compiler .Pdf
Vectorization for Intel® C++ & Fortran Compiler Presenter: Georg Zitzlsberger Date: 10-07-2015 1 Agenda • Introduction to SIMD for Intel® Architecture • Compiler & Vectorization • Validating Vectorization Success • Reasons for Vectorization Fails • Intel® Cilk™ Plus • Summary 2 Optimization Notice Copyright © 2015, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Vectorization • Single Instruction Multiple Data (SIMD): . Processing vector with a single operation . Provides data level parallelism (DLP) . Because of DLP more efficient than scalar processing • Vector: . Consists of more than one element . Elements are of same scalar data types (e.g. floats, integers, …) • Vector length (VL): Elements of the vector A B AAi i BBi i A B Ai i Bi i Scalar Vector Processing + Processing + C CCi i C Ci i VL 3 Optimization Notice Copyright © 2015, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Evolution of SIMD for Intel Processors Present & Future: Goal: Intel® MIC Architecture, 8x peak FLOPs (FMA) over 4 generations! Intel® AVX-512: • 512 bit Vectors • 2x FP/Load/FMA 4th Generation Intel® Core™ Processors Intel® AVX2 (256 bit): • 2x FMA peak Performance/Core • Gather Instructions 2nd Generation 3rd Generation Intel® Core™ Processors Intel® Core™ Processors Intel® AVX (256 bit): • Half-float support • 2x FP Throughput • Random Numbers • 2x Load Throughput Since 1999: Now & 2010 2012 2013 128 bit Vectors Future Time 4 Optimization Notice -

New Instruction Set Extensions
New Instruction Set Extensions Instruction Set Innovation in Intels Processor Code Named Haswell [email protected] Agenda • Introduction - Overview of ISA Extensions • Haswell New Instructions • New Instructions Overview • Intel® AVX2 (256-bit Integer Vectors) • Gather • FMA: Fused Multiply-Add • Bit Manipulation Instructions • TSX/HLE/RTM • Tools Support for New Instruction Set Extensions • Summary/References Copyright© 2012, Intel Corporation. All rights reserved. Partially Intel Confidential Information. 2 *Other brands and names are the property of their respective owners. Instruction Set Architecture (ISA) Extensions 199x MMX, CMOV, Multiple new instruction sets added to the initial 32bit instruction PAUSE, set of the Intel® 386 processor XCHG, … 1999 Intel® SSE 70 new instructions for 128-bit single-precision FP support 2001 Intel® SSE2 144 new instructions adding 128-bit integer and double-precision FP support 2004 Intel® SSE3 13 new 128-bit DSP-oriented math instructions and thread synchronization instructions 2006 Intel SSSE3 16 new 128-bit instructions including fixed-point multiply and horizontal instructions 2007 Intel® SSE4.1 47 new instructions improving media, imaging and 3D workloads 2008 Intel® SSE4.2 7 new instructions improving text processing and CRC 2010 Intel® AES-NI 7 new instructions to speedup AES 2011 Intel® AVX 256-bit FP support, non-destructive (3-operand) 2012 Ivy Bridge NI RNG, 16 Bit FP 2013 Haswell NI AVX2, TSX, FMA, Gather, Bit NI A long history of ISA Extensions ! Copyright© 2012, Intel Corporation. All rights reserved. Partially Intel Confidential Information. 3 *Other brands and names are the property of their respective owners. Instruction Set Architecture (ISA) Extensions • Why new instructions? • Higher absolute performance • More energy efficient performance • New application domains • Customer requests • Fill gaps left from earlier extensions • For a historical overview see http://en.wikipedia.org/wiki/X86_instruction_listings Copyright© 2012, Intel Corporation. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Amd Epyc 7351
SPEC CPU2017 Floating Point Rate Result spec Copyright 2017-2019 Standard Performance Evaluation Corporation Sugon SPECrate2017_fp_base = 176 Sugon A620-G30 (AMD EPYC 7351) SPECrate2017_fp_peak = 177 CPU2017 License: 9046 Test Date: Dec-2017 Test Sponsor: Sugon Hardware Availability: Dec-2017 Tested by: Sugon Software Availability: Aug-2017 Copies 0 30.0 60.0 90.0 120 150 180 210 240 270 300 330 360 390 420 450 480 510 560 64 550 503.bwaves_r 32 552 165 507.cactuBSSN_r 64 163 130 508.namd_r 64 142 64 141 510.parest_r 32 146 168 511.povray_r 64 175 64 121 519.lbm_r 32 124 64 192 521.wrf_r 32 161 190 526.blender_r 64 188 164 527.cam4_r 64 162 248 538.imagick_r 64 250 205 544.nab_r 64 205 64 160 549.fotonik3d_r 32 163 64 96.7 554.roms_r 32 103 SPECrate2017_fp_base (176) SPECrate2017_fp_peak (177) Hardware Software CPU Name: AMD EPYC 7351 OS: Red Hat Enterprise Linux Server 7.4 Max MHz.: 2900 kernel 3.10.0-693.2.2 Nominal: 2400 Enabled: 32 cores, 2 chips, 2 threads/core Compiler: C/C++: Version 1.0.0 of AOCC Orderable: 1,2 chips Fortran: Version 4.8.2 of GCC Cache L1: 64 KB I + 32 KB D on chip per core Parallel: No L2: 512 KB I+D on chip per core Firmware: American Megatrends Inc. BIOS Version 0WYSZ018 released Aug-2017 L3: 64 MB I+D on chip per chip, 8 MB shared / 2 cores File System: ext4 Other: None System State: Run level 3 (Multi User) Memory: 512 GB (16 x 32 GB 2Rx4 PC4-2667V-R, running at Base Pointers: 64-bit 2400) Peak Pointers: 32/64-bit Storage: 1 x 3000 GB SATA, 7200 RPM Other: None Other: None Page 1 Standard Performance Evaluation -

MSI Afterburner V4.6.4
MSI Afterburner v4.6.4 MSI Afterburner is ultimate graphics card utility, co-developed by MSI and RivaTuner teams. Please visit https://msi.com/page/afterburner to get more information about the product and download new versions SYSTEM REQUIREMENTS: ...................................................................................................................................... 3 FEATURES: ............................................................................................................................................................. 3 KNOWN LIMITATIONS:........................................................................................................................................... 4 REVISION HISTORY: ................................................................................................................................................ 5 VERSION 4.6.4 .............................................................................................................................................................. 5 VERSION 4.6.3 (PUBLISHED ON 03.03.2021) .................................................................................................................... 5 VERSION 4.6.2 (PUBLISHED ON 29.10.2019) .................................................................................................................... 6 VERSION 4.6.1 (PUBLISHED ON 21.04.2019) .................................................................................................................... 7 VERSION 4.6.0 (PUBLISHED ON -

CS 110 Discussion 15 Programming with SIMD Intrinsics
CS 110 Discussion 15 Programming with SIMD Intrinsics Yanjie Song School of Information Science and Technology May 7, 2020 Yanjie Song (S.I.S.T.) CS 110 Discussion 15 2020.05.07 1 / 21 Table of Contents 1 Introduction on Intrinsics 2 Compiler and SIMD Intrinsics 3 Intel(R) SDE 4 Application: Horizontal sum in vector Yanjie Song (S.I.S.T.) CS 110 Discussion 15 2020.05.07 2 / 21 Table of Contents 1 Introduction on Intrinsics 2 Compiler and SIMD Intrinsics 3 Intel(R) SDE 4 Application: Horizontal sum in vector Yanjie Song (S.I.S.T.) CS 110 Discussion 15 2020.05.07 3 / 21 Introduction on Intrinsics Definition In computer software, in compiler theory, an intrinsic function (or builtin function) is a function (subroutine) available for use in a given programming language whose implementation is handled specially by the compiler. Yanjie Song (S.I.S.T.) CS 110 Discussion 15 2020.05.07 4 / 21 Intrinsics in C/C++ Compilers for C and C++, of Microsoft, Intel, and the GNU Compiler Collection (GCC) implement intrinsics that map directly to the x86 single instruction, multiple data (SIMD) instructions (MMX, Streaming SIMD Extensions (SSE), SSE2, SSE3, SSSE3, SSE4). Yanjie Song (S.I.S.T.) CS 110 Discussion 15 2020.05.07 5 / 21 x86 SIMD instruction set extensions MMX (1996, 64 bits) 3DNow! (1998) Streaming SIMD Extensions (SSE, 1999, 128 bits) SSE2 (2001) SSE3 (2004) SSSE3 (2006) SSE4 (2006) Advanced Vector eXtensions (AVX, 2008, 256 bits) AVX2 (2013) F16C (2009) XOP (2009) FMA FMA4 (2011) FMA3 (2012) AVX-512 (2015, 512 bits) Yanjie Song (S.I.S.T.) CS 110 Discussion 15 2020.05.07 6 / 21 SIMD extensions in other ISAs There are SIMD instructions for other ISAs as well, e.g. -

Memorandum in Opposition to Hewlett-Packard Company's Motion to Quash Intel's Subpoena Duces Tecum
ORIGINAL UNITED STATES OF AMERICA BEFORE THE FEDERAL TRADE COMMISSION ) In the Matter of ) ) DOCKET NO. 9341 INTEL. CORPORATION, ) a corporation ) PUBLIC ) .' ) MEMORANDUM IN OPPOSITION TO HEWLETT -PACKARD COMPANY'S MOTION TO QUASH INTEL'S SUBPOENA DUCES TECUM Intel Corporation ("Intel") submits this memorandum in opposition to Hewlett-Packard Company's ("HP") motion to quash Intel's subpoena duces tecum issued on March 11,2010 ("Subpoena"). HP's motion should be denied, and it should be ordered to comply with Intel's Subpoena, as narrowed by Intel's April 19,2010 letter. Intel's Subpoena seeks documents necessary to defend against Complaint Counsel's broad allegations and claimed relief. The Complaint alleges that Intel engaged in unfair business practices that maintained its monopoly over central processing units ("CPUs") and threatened to give it a monopoly over graphics processing units ("GPUs"). See CompI. iiii 2-28. Complaint Counsel's Interrogatory Answers state that it views HP, the world's largest manufacturer of personal computers, as a centerpiece of its case. See, e.g., Complaint Counsel's Resp. and Obj. to Respondent's First Set ofInterrogatories Nos. 7-8 (attached as Exhibit A). Complaint Counsel intends to call eight HP witnesses at trial on topics crossing virtually all of HP' s business lines, including its purchases ofCPUs for its commercial desktop, commercial notebook, and server businesses. See Complaint Counsel's May 5, 2010 Revised Preliminary Witness List (attached as Exhibit B). Complaint Counsel may also call HP witnesses on other topics, including its PUBLIC FTC Docket No. 9341 Memorandum in Opposition to Hewlett-Packard Company's Motion to Quash Intel's Subpoena Duces Tecum USIDOCS 7544743\'1 assessment and purchases of GPUs and chipsets and evaluation of compilers, benchmarks, interface standards, and standard-setting bodies. -

Reverse Engineering X86 Processor Microcode
Reverse Engineering x86 Processor Microcode Philipp Koppe, Benjamin Kollenda, Marc Fyrbiak, Christian Kison, Robert Gawlik, Christof Paar, and Thorsten Holz, Ruhr-University Bochum https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/koppe This paper is included in the Proceedings of the 26th USENIX Security Symposium August 16–18, 2017 • Vancouver, BC, Canada ISBN 978-1-931971-40-9 Open access to the Proceedings of the 26th USENIX Security Symposium is sponsored by USENIX Reverse Engineering x86 Processor Microcode Philipp Koppe, Benjamin Kollenda, Marc Fyrbiak, Christian Kison, Robert Gawlik, Christof Paar, and Thorsten Holz Ruhr-Universitat¨ Bochum Abstract hardware modifications [48]. Dedicated hardware units to counter bugs are imperfect [36, 49] and involve non- Microcode is an abstraction layer on top of the phys- negligible hardware costs [8]. The infamous Pentium fdiv ical components of a CPU and present in most general- bug [62] illustrated a clear economic need for field up- purpose CPUs today. In addition to facilitate complex and dates after deployment in order to turn off defective parts vast instruction sets, it also provides an update mechanism and patch erroneous behavior. Note that the implementa- that allows CPUs to be patched in-place without requiring tion of a modern processor involves millions of lines of any special hardware. While it is well-known that CPUs HDL code [55] and verification of functional correctness are regularly updated with this mechanism, very little is for such processors is still an unsolved problem [4, 29]. known about its inner workings given that microcode and the update mechanism are proprietary and have not been Since the 1970s, x86 processor manufacturers have throughly analyzed yet. -

AMD Ryzen 5 1600 Specifications
AMD Ryzen 5 1600 specifications General information Type CPU / Microprocessor Market segment Desktop Family AMD Ryzen 5 Model number 1600 CPU part numbers YD1600BBM6IAE is an OEM/tray microprocessor YD1600BBAEBOX is a boxed microprocessor with fan and heatsink Frequency 3200 MHz Turbo frequency 3600 MHz Package 1331-pin lidded micro-PGA package Socket Socket AM4 Introduction date March 15, 2017 (announcement) April 11, 2017 (launch) Price at introduction $219 Architecture / Microarchitecture Microarchitecture Zen Processor core Summit Ridge Core stepping B1 Manufacturing process 0.014 micron FinFET process 4.8 billion transistors Data width 64 bit The number of CPU cores 6 The number of threads 12 Floating Point Unit Integrated Level 1 cache size 6 x 64 KB 4-way set associative instruction caches 6 x 32 KB 8-way set associative data caches Level 2 cache size 6 x 512 KB inclusive 8-way set associative unified caches Level 3 cache size 2 x 8 MB exclusive 16-way set associative shared caches Multiprocessing Uniprocessor Features MMX instructions Extensions to MMX SSE / Streaming SIMD Extensions SSE2 / Streaming SIMD Extensions 2 SSE3 / Streaming SIMD Extensions 3 SSSE3 / Supplemental Streaming SIMD Extensions 3 SSE4 / SSE4.1 + SSE4.2 / Streaming SIMD Extensions 4 SSE4a AES / Advanced Encryption Standard instructions AVX / Advanced Vector Extensions AVX2 / Advanced Vector Extensions 2.0 BMI / BMI1 + BMI2 / Bit Manipulation instructions SHA / Secure Hash Algorithm extensions F16C / 16-bit Floating-Point conversion instructions -

X86 Intrinsics Cheat Sheet Jan Finis [email protected]
x86 Intrinsics Cheat Sheet Jan Finis [email protected] Bit Operations Conversions Boolean Logic Bit Shifting & Rotation Packed Conversions Convert all elements in a packed SSE register Reinterpet Casts Rounding Arithmetic Logic Shift Convert Float See also: Conversion to int Rotate Left/ Pack With S/D/I32 performs rounding implicitly Bool XOR Bool AND Bool NOT AND Bool OR Right Sign Extend Zero Extend 128bit Cast Shift Right Left/Right ≤64 16bit ↔ 32bit Saturation Conversion 128 SSE SSE SSE SSE Round up SSE2 xor SSE2 and SSE2 andnot SSE2 or SSE2 sra[i] SSE2 sl/rl[i] x86 _[l]rot[w]l/r CVT16 cvtX_Y SSE4.1 cvtX_Y SSE4.1 cvtX_Y SSE2 castX_Y si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd si128,ps[SSE],pd epi16-64 epi16-64 (u16-64) ph ↔ ps SSE2 pack[u]s epi8-32 epu8-32 → epi8-32 SSE2 cvt[t]X_Y si128,ps/d (ceiling) mi xor_si128(mi a,mi b) mi and_si128(mi a,mi b) mi andnot_si128(mi a,mi b) mi or_si128(mi a,mi b) NOTE: Shifts elements right NOTE: Shifts elements left/ NOTE: Rotates bits in a left/ NOTE: Converts between 4x epi16,epi32 NOTE: Sign extends each NOTE: Zero extends each epi32,ps/d NOTE: Reinterpret casts !a & b while shifting in sign bits. right while shifting in zeros. right by a number of bits 16 bit floats and 4x 32 bit element from X to Y. Y must element from X to Y. Y must from X to Y. No operation is SSE4.1 ceil NOTE: Packs ints from two NOTE: Converts packed generated. -
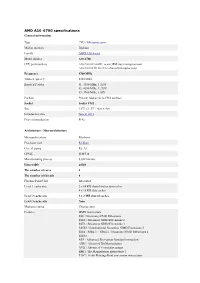
AMD A10-6700 Specifications General Information
AMD A10-6700 specifications General information Type CPU / Microprocessor Market segment Desktop Family AMD A10-Series Model number A10-6700 CPU part numbers AD6700OKA44HL is an OEM/tray microprocessor AD6700OKHLBOX is a boxed microprocessor Frequency 3700 MHz Turbo frequency 4300 MHz Boosted P states #1: 4300 MHz, 1.325V #2: 4200 MHz, 1.275V #3: 3900 MHz, 1.05V Package 904-pin lidded micro-PGA package Socket Socket FM2 Size 1.57" x 1.57" / 4cm x 4cm Introduction date June 4, 2013 Price at introduction $142 Architecture / Microarchitecture Microarchitecture Piledriver Processor core Richland Core stepping RL-A1 CPUID 610F31h Manufacturing process 0.032 micron Data width 64 bit The number of cores 4 The number of threads 4 Floating Point Unit Integrated Level 1 cache size 2 x 64 KB shared instruction caches 4 x 16 KB data caches Level 2 cache size 2 x 2 MB shared caches Level 3 cache size None Multiprocessing Uniprocessor Features MMX instructions SSE / Streaming SIMD Extensions SSE2 / Streaming SIMD Extensions 2 SSE3 / Streaming SIMD Extensions 3 SSSE3 / Supplemental Streaming SIMD Extensions 3 SSE4 / SSE4.1 + SSE4.2 / Streaming SIMD Extensions 4 SSE4a AES / Advanced Encryption Standard instructions ABM / Advanced Bit Manipulation AVX / Advanced Vector Extensions BMI1 / Bit Manipulation instructions 1 F16C / 16-bit Floating-Point conversion instructions FMA3 / 3-operand Fused Multiply-Add instructions FMA4 / 4-operand Fused Multiply-Add instructions TBM / Trailing Bit Manipulation instructions XOP / eXtended Operations instructions AMD64 -

AMD's Early Processor Lines, up to the Hammer Family (Families K8
AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) Dezső Sima October 2018 (Ver. 1.1) Sima Dezső, 2018 AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) • 1. Introduction to AMD’s processor families • 2. AMD’s 32-bit x86 families • 3. Migration of 32-bit ISAs and microarchitectures to 64-bit • 4. Overview of AMD’s K8 – K10.5 (Hammer-based) families • 5. The K8 (Hammer) family • 6. The K10 Barcelona family • 7. The K10.5 Shanghai family • 8. The K10.5 Istambul family • 9. The K10.5-based Magny-Course/Lisbon family • 10. References 1. Introduction to AMD’s processor families 1. Introduction to AMD’s processor families (1) 1. Introduction to AMD’s processor families AMD’s early x86 processor history [1] AMD’s own processors Second sourced processors 1. Introduction to AMD’s processor families (2) Evolution of AMD’s early processors [2] 1. Introduction to AMD’s processor families (3) Historical remarks 1) Beyond x86 processors AMD also designed and marketed two embedded processor families; • the 2900 family of bipolar, 4-bit slice microprocessors (1975-?) used in a number of processors, such as particular DEC 11 family models, and • the 29000 family (29K family) of CMOS, 32-bit embedded microcontrollers (1987-95). In late 1995 AMD cancelled their 29K family development and transferred the related design team to the firm’s K5 effort, in order to focus on x86 processors [3]. 2) Initially, AMD designed the Am386/486 processors that were clones of Intel’s processors.