Lecture 11 Web Mining and Recommender Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Uk's Top 200 Most Requested Songs in 2014
The Uk’s top 200 most requested songs in 2014 1 Killers Mr. Brightside 2 Kings Of Leon Sex On Fire 3 Black Eyed Peas I Gotta Feeling 4 Pharrell Williams Happy 5 Bon Jovi Livin' On A Prayer 6 Robin Thicke Blurred Lines 7 Whitney Houston I Wanna Dance With Somebody 8 Daft Punk Get Lucky 9 Journey Don't Stop Believin' 10 Bryan Adams Summer Of '69 11 Maroon 5 MovesLike Jagger 12 Beyonce Single Ladies (Put A Ring On It) 13 Bruno Mars Marry You 14 Psy Gangam Style 15 ABBA Dancing Queen 16 Queen Don't Stop Me Now 17 Rihanna We Found Love 18 Foundations Build Me Up Buttercup 19 Dexys Midnight Runners Come On Eileen 20 LMFAO Sexy And I Know It 21 Van Morrison Brown Eyed Girl 22 B-52's Love Shack 23 Beyonce Crazy In Love 24 Michael Jackson Billie Jean 25 LMFAO Party Rock Anthem 26 Amy Winehouse Valerie 27 Avicii Wake Me Up! 28 Katy Perry Firework 29 Arctic Monkeys I Bet You Look Good On The Dancefloor 30 John Travolta & Olivia Newton-John Grease Megamix 31 Guns N' Roses Sweet Child O' Mine 32 Kenny Loggins Footloose 33 Olly Murs Dance With Me Tonight 34 OutKast Hey Ya! 35 Beatles Twist And Shout 36 One Direction What Makes You Beautiful 37 DJ Casper Cha Cha Slide 38 Clean Bandit Rather Be 39 Proclaimers I'm Gonna Be (500 Miles) 40 Stevie Wonder Superstition 41 Bill Medley & Jennifer Warnes (I've Had) The Time Of My Life 42 Swedish House Mafia Don't You Worry Child 43 House Of Pain Jump Around 44 Oasis Wonderwall 45 Wham! Wake Me Up Before You Go-go 46 Cyndi Lauper Girls Just Want To Have Fun 47 David Guetta Titanium 48 Village People Y.M.C.A. -

Uptownlive.Song List Copy.Pages
Uptown Live Sample - Song List Top 40/ Pop 24k Gold - Bruno Mars Adventure of A Lifetime - Coldplay Aint My Fault - Zara Larsson All of Me (John Legend) Another You - Armin Van Buren Bad Romance -Lady Gaga Better Together -Jack Johnson Blame - Calvin Harris Blurred Lines -Robin Thicke Body Moves - DNCE Boom Boom Pow - Black Eyed Peas Cake By The Ocean - DNCE California Girls - Katy Perry Call Me Maybe - Carly Rae Jepsen Can’t Feel My Face - The Weeknd Can’t Stop The Feeling - Justin Timberlake Cheap Thrills - Sia Cheerleader - OMI Clarity - Zedd feat. Foxes Closer - Chainsmokers Closer – Ne-Yo Cold Water - Major Lazer feat. Beiber Crazy - Cee Lo Crazy In Love - Beyoncé Despacito - Luis Fonsi, Daddy Yankee and Beiber DJ Got Us Falling In Love Again - Usher Don’t Know Why - Norah Jones Don’t Let Me Down - Chainsmokers Don’t Wanna Know - Maroon 5 Don’t You Worry Child - Sweedish House Mafia Dynamite - Taio Cruz Edge of Glory - Lady Gaga ET - Katy Perry Everything - Michael Bublé Feel So Close - Calvin Harris Firework - Katy Perry Forget You - Cee Lo FUN- Pitbull/Chris Brown Get Lucky - Daft Punk Girlfriend – Justin Bieber Grow Old With You - Adam Sandler Happy – Pharrel Hey Soul Sister – Train Hideaway - Kiesza Home - Michael Bublé Hot In Here- Nelly Hot n Cold - Katy Perry How Deep Is Your Love - Calvin Harris I Feel It Coming - The Weeknd I Gotta Feelin’ - Black Eyed Peas I Kissed A Girl - Katy Perry I Knew You Were Trouble - Taylor Swift I Want You To Know - Zedd feat. Selena Gomez I’ll Be - Edwin McCain I’m Yours - Jason Mraz In The Name of Love - Martin Garrix Into You - Ariana Grande It Aint Me - Kygo and Selena Gomez Jealous - Nick Jonas Just Dance - Lady Gaga Kids - OneRepublic Last Friday Night - Katy Perry Lean On - Major Lazer feat. -
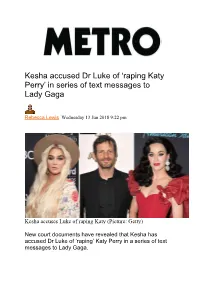
Kesha Accused Dr Luke of 'Raping Katy Perry' in Series of Text
Kesha accused Dr Luke of ‘raping Katy Perry’ in series of text messages to Lady Gaga Rebecca Lewis Wednesday 13 Jun 2018 9:22 pm Kesha accuses Luke of raping Katy (Picture: Getty) New court documents have revealed that Kesha has accused Dr Luke of ‘raping’ Katy Perry in a series of text messages to Lady Gaga. Luke has denied the claims. The documents in the ongoing case between Kesha and Dr Luke were filed in New York as part of the on-going legal battle between the music producer, real name Lukas Gottwald, and the singer. Obtained by The Blast, the documents – filed by Luke’s team – read: ‘On February 26, 2016 [Kesha] sent a text message to Stefani Germanotta p/k/a/ Lady Gaga which repeated [Kesha’s] false claim that [Luke] had raped her.’ ‘[Kesha] also falsely asserted that [Luke] had also raped Kathryn Hudson p/k/a/ Katy Perry.’ and that, ‘following this text message conversation, and with [Kesha’s] encouragement, [Lady Gaga] spread negative messages about [Luke] in the press and on social media’. Lukasz Gottwald (L), better known as Dr. Luke, and Kesha (R) in 2011 (Picture: Reuters) Perry has been deposed in the case and gave a written statement but her comments have not been revealed. Perry has never publicly accused Dr. Luke of any sexual misconduct. She previously admitted she had chosen to no longer work with him, simply using the phrase: ‘I had to leave the nest’. Katy Perry (Picture: Rex) Kesha dropped all sexual assault claims in her lawsuit against Dr Luke in August 2016 after years of controversy and legal battles. -
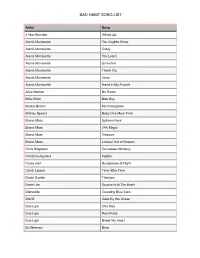
Bad Habit Song List
BAD HABIT SONG LIST Artist Song 4 Non Blondes Whats Up Alanis Morissette You Oughta Know Alanis Morissette Crazy Alanis Morissette You Learn Alanis Morissette Uninvited Alanis Morissette Thank You Alanis Morissette Ironic Alanis Morissette Hand In My Pocket Alice Merton No Roots Billie Eilish Bad Guy Bobby Brown My Prerogative Britney Spears Baby One More Time Bruno Mars Uptown Funk Bruno Mars 24K Magic Bruno Mars Treasure Bruno Mars Locked Out of Heaven Chris Stapleton Tennessee Whiskey Christina Aguilera Fighter Corey Hart Sunglasses at Night Cyndi Lauper Time After Time David Guetta Titanium Deee-Lite Groove Is In The Heart Dishwalla Counting Blue Cars DNCE Cake By the Ocean Dua Lipa One Kiss Dua Lipa New Rules Dua Lipa Break My Heart Ed Sheeran Blow BAD HABIT SONG LIST Artist Song Elle King Ex’s & Oh’s En Vogue Free Your Mind Eurythmics Sweet Dreams Fall Out Boy Beat It George Michael Faith Guns N’ Roses Sweet Child O’ Mine Hailee Steinfeld Starving Halsey Graveyard Imagine Dragons Whatever It Takes Janet Jackson Rhythm Nation Jessie J Price Tag Jet Are You Gonna Be My Girl Jewel Who Will Save Your Soul Jo Dee Messina Heads Carolina, Tails California Jonas Brothers Sucker Journey Separate Ways Justin Timberlake Can’t Stop The Feeling Justin Timberlake Say Something Katy Perry Teenage Dream Katy Perry Dark Horse Katy Perry I Kissed a Girl Kings Of Leon Sex On Fire Lady Gaga Born This Way Lady Gaga Bad Romance Lady Gaga Just Dance Lady Gaga Poker Face Lady Gaga Yoü and I Lady Gaga Telephone BAD HABIT SONG LIST Artist Song Lady Gaga Shallow Letters to Cleo Here and Now Lizzo Truth Hurts Lorde Royals Madonna Vogue Madonna Into The Groove Madonna Holiday Madonna Border Line Madonna Lucky Star Madonna Ray of Light Meghan Trainor All About That Bass Michael Jackson Dirty Diana Michael Jackson Billie Jean Michael Jackson Human Nature Michael Jackson Black Or White Michael Jackson Bad Michael Jackson Wanna Be Startin’ Something Michael Jackson P.Y.T. -

Movie Review: Katy Perry: Part of Me
Movie Review: Katy Perry: Part of Me By John Mulderig Catholic News Service NEW YORK – An interesting sociological study could be made that less than a decade separated the Billboard chart appearances of the Beatles’ “I Want to Hold Your Hand” and the Raspberries’ “Go All the Way.” Fast forward to 2008 and the campily costumed central figure of the concert film “Katy Perry: Part of Me” (Paramount) was having a breakthrough hit with a ditty called “I Kissed a Girl.” Sensing a trend? Suggestive and even blatantly sexual lyrics are nothing new in pop music of course. The issue here is the youthful following Perry attracts: On screen at least, her fans seem to range from toddlers on up, but with a heavy concentration in the pre- and early teens. Yet the sight of Perry imploring an imaginary young man of her fancy to “Show Me Your Peacock” is one that parents will almost certainly find unsuitable for their kids. Add to that a strongly reinforced message promoting individualism without limit – and at least implying acceptance of a gay lifestyle – and it would seem imperative to mark these mildly entertaining but overlong proceedings, helmed by Dan Cutforth and Jane Lipsitz, as off limits to the target demographic. None of which is to deny that the Perry who emerges in this profile has her moral strong points. Her generous interaction with her star-struck admirers reaches a poignant climax when she fulfills the titular mission of the Make-A-Wish Foundation for one ailing but delightedly dazzled boy. We also see her making apparently extraordinary – though, sadly, unsuccessful – efforts to salvage her short-lived marriage to British comedian and actor Russell Brand. -

Velocity Current Rotation
VELOCITY - CURRENT ROTATION CONTEMPORARY DANCE 24K Magic – Bruno Mars That's What I Like – Bruno Mars This is What You Came For – Calvin Harris ft. Rihanna Ain’t It Fun - Paramore All About That Bass – Meghan Trainor Timber – Ke$ha/Pitbull All of Me – John Legend Treasure – Bruno Mars Applause – Lady Gaga Uptown Funk – Mark Ronson ft. Bruno Mars Blurred Lines – Robin Thicke/Pharrell We Found Love – Rihanna Born This Way – Lady Gaga What Lovers Do – Maroon 5 Bang Bang – Jessie J, Ariana Grande, Nicki Minaj Wild One – Sia/FloRida Break Free – Ariana Grande Cake By The Ocean – DNCE ROCK AND HIGH ENERGY (‘60s-Current) Call Me Maybe – Carly Rae Jepson American Girl – Tom Petty Can't Feel My Face – The Weeknd Any Way You Want It – Journey Can’t Stop The Feeling – Justin Timberlake Are You Gonna Be My Girl – Jet Cheap Thrills – Sia Beautiful Day – U2 Cheerleader – OMI Blister in the Sun – Violent Femmes Closer – Chainsmokers Brown Eyed Girl – Van Morrison Counting Stars – One Republic Build Me Up Buttercup – The Foundations Crazy In Love – Beyoncé Chelsea Dagger – The Fratellis Despacito – Luis Fonsi ft. Justin Bieber Dancing In the Dark – Bruce Springsteen Domino – Jessie J Don’t Stop Believing – Journey Dynamite – Taio Cruz Everlong – Foo Fighters Ex’s and Oh’s – Elle King Gimme Some Lovin’ – Spencer Davis Group Feel It Still – Portugal. The Man Hit Me With Your Best Shot – Pat Benatar Feel So Close – Calvin Harris Honky Tonk Woman – The Rolling Stones Finesse – Bruno Mars I Love Rock and Roll – Joan Jett Fireball – Pitbull I Saw Her Standing There – The Beatles Firework – Katy Perry Jessie’s Girl – Rick Springfield Forget You – Cee Lo Green Livin’ On A Prayer – Bon Jovi Give Me Everything – Pitbull/Ne-Yo Mr. -

Skyline Orchestras
PRESENTS… SKYLINE Thank you for joining us at our showcase this evening. Tonight, you’ll be viewing the band Skyline, led by Ross Kash. Skyline has been performing successfully in the wedding industry for over 10 years. Their experience and professionalism will ensure a great party and a memorable occasion for you and your guests. In addition to the music you’ll be hearing tonight, we’ve supplied a song playlist for your convenience. The list is just a part of what the band has done at prior affairs. If you don’t see your favorite songs listed, please ask. Every concern and detail for your musical tastes will be held in the highest regard. Please inquire regarding the many options available. Skyline Members: • VOCALS AND MASTER OF CEREMONIES…………………………..…….…ROSS KASH • VOCALS……..……………………….……………………………….….BRIDGET SCHLEIER • VOCALS AND KEYBOARDS..………….…………………….……VINCENT FONTANETTA • GUITAR………………………………….………………………………..…….JOHN HERRITT • SAXOPHONE AND FLUTE……………………..…………..………………DAN GIACOMINI • DRUMS, PERCUSSION AND VOCALS……………………………….…JOEY ANDERSON • BASS GUITAR, VOCALS AND UKULELE………………….……….………TOM MCGUIRE • TRUMPET…….………………………………………………………LEE SCHAARSCHMIDT • TROMBONE……………………………………………………………………..TIM CASSERA • ALTO SAX AND CLARINET………………………………………..ANTHONY POMPPNION www.skylineorchestras.com (631) 277 – 7777 DANCE: 24K — BRUNO MARS A LITTLE PARTY NEVER KILLED NOBODY — FERGIE A SKY FULL OF STARS — COLD PLAY LONELY BOY — BLACK KEYS AIN’T IT FUN — PARAMORE LOVE AND MEMORIES — O.A.R. ALL ABOUT THAT BASS — MEGHAN TRAINOR LOVE ON TOP — BEYONCE BAD ROMANCE — LADY GAGA MANGO TREE — ZAC BROWN BAND BANG BANG — JESSIE J, ARIANA GRANDE & NIKKI MARRY YOU — BRUNO MARS MINAJ MOVES LIKE JAGGER — MAROON 5 BE MY FOREVER — CHRISTINA PERRI FT. ED SHEERAN MR. SAXOBEAT — ALEXANDRA STAN BEST DAY OF MY LIFE — AMERICAN AUTHORS NO EXCUSES — MEGHAN TRAINOR BETTER PLACE — RACHEL PLATTEN NOTHING HOLDING ME BACK — SHAWN MENDES BLOW — KE$HA ON THE FLOOR — J. -

Free Part of Me Katty
Free part of me katty click here to download Katy Perry - On Tour. i love katy so much and this song and a music video are just amazing like the rest. Get “Part Of Me” from Katy Perry's 'Teenage Dream: The Complete Confection': www.doorway.ru Thanks for watching! This song is so uplifting, I love it. Lyrics to 'Part Of Me' by Katy Perry. Days like this I want to drive away / Pack my bags and watch your shadow fade / You chewed me up and spit me out / Like I. "Part of Me" is a song by American singer Katy Perry, released as the lead single from Teenage Dream: The Complete Confection. It was written by Perry, and Bonnie McKee, with production and additional writing by Dr. Luke, Max Martin, and Cirkut. The song was not included on the original edition of Teenage Dream Composition and lyrical · Music video · Live performances · Usage in media. Katy Perry: Part of Me Katy Perry who is a pop star has a huge number of fan in the world. She is always herself why she gets great successes in her life. Watch Katy Perry: Part Of Me Online | katy perry: part of me | Katy Perry: Part Of Me () | Director. Part of Me Lyrics: Days like this, I want to drive away / Pack my bags and watch your shadow fade / You chewed me up and spit me out / Like I was poison in your mouth / You took my light, you drain. Lyrics to "Part Of Me" song by Katy Perry: Days like this I want to drive away Pack my bags and watch your shadow fade You chewed me up and sp. -

The Derailment of Feminism: a Qualitative Study of Girl Empowerment and the Popular Music Artist
THE DERAILMENT OF FEMINISM: A QUALITATIVE STUDY OF GIRL EMPOWERMENT AND THE POPULAR MUSIC ARTIST A Thesis by Jodie Christine Simon Master of Arts, Wichita State University, 2010 Bachelor of Arts. Wichita State University, 2006 Submitted to the Department of Liberal Studies and the faculty of the Graduate School of Wichita State University in partial fulfillment of the requirements for the degree of Master of Arts July 2012 @ Copyright 2012 by Jodie Christine Simon All Rights Reserved THE DERAILMENT OF FEMINISM: A QUALITATIVE STUDY OF GIRL EMPOWERMENT AND THE POPULAR MUSIC ARTIST The following faculty members have examined the final copy of this thesis for form and content, and recommend that it be accepted in partial fulfillment of the requirement for the degree of Masters of Arts with a major in Liberal Studies. __________________________________________________________ Jodie Hertzog, Committee Chair __________________________________________________________ Jeff Jarman, Committee Member __________________________________________________________ Chuck Koeber, Committee Member iii DEDICATION To my husband, my mother, and my children iv ACKNOWLEDGMENTS I would like to thank my adviser, Dr. Jodie Hertzog, for her patient and insightful advice and support. A mentor in every sense of the word, Jodie Hertzog embodies the very nature of adviser; her council was very much appreciated through the course of my study. v ABSTRACT “Girl Power!” is a message that parents raising young women in today’s media- saturated society should be able to turn to with a modicum of relief from the relentlessly harmful messages normally found within popular music. But what happens when we turn a critical eye toward the messages cloaked within this supposedly feminist missive? A close examination of popular music associated with girl empowerment reveals that many of the messages found within these lyrics are frighteningly just as damaging as the misogynistic, violent, and explicitly sexual ones found in the usual fare of top 100 Hits. -

Bad Blood APPEARS in ROCK & POP 2018
ACCESS ALL AREAS... bad blood APPEARS IN ROCK & POP 2018 Released: 2015 Album: 1989 Label: Big machine, Republic ABOUT THE SONG ‘Bad Blood’ — from Taylor Swift’s Grammy award- winning 2014 album 1989 — was a worldwide hit, reaching No. 1 in the USA, Australia, Canada, Israel, CAUSE BABY NOW WE’VE GOT New Zealand and Scotland. Written and performed by Taylor Swift, Max Martin and Shellback, the remixed single version was released on 17 May 2015 with added verses by rapper Kendrick Lamar. Inspired by the pop BAD BLOOD scene of the 1980s, Swift described 1989 as her ‘first “ documented official pop album’. YOU KNOW IT USED TO BE Like many of her songs, Taylor Swift draws on her own experiences for inspiration in ‘Bad Blood’. The song describes the betrayal of a close friend, and the resulting breakdown of the friendship. Despite intense speculation that the friend involved could be another well-known MAD LOVE artist, Swift has always refused to name them. SO TAKE A LOOK WHAT YOU’VE DONE RECORDING AND PRODUCTION ‘Bad Blood’ was produced by Swedish songwriter, record producer and singer Max Martin, who worked with Swift on ‘Black Space’ in 2014. Martin has also written, co-written and/or produced hits for Britney Spears, Katy Perry, Maroon 5 and The Weeknd among many others. ‘Bad Blood’ was recorded at MXM Studios in Stockholm and mixed at MixStar Studios in Virginia Beach, Virginia. It was mastered at Sterling Sound in New York. COMPOSITION AWARDS ” Unusually, the song starts with a chorus, with powerhouse drums adding a stadium-anthem feel to the otherwise a cappella vocals. -

The Revels Repertoire
THE REVELS REPERTOIRE POP Ain’t It Fun – Paramore Don’t StoP the Music – Rihanna All About That Bass – Meghan Trainor Dynamite – Taio Cruz American Boy – Estelle Everybody – Backstreet Boys Animal – Neon Trees Everybody Talks – Neon Trees Baby I Love Your Way – Big Mountain, Tom Exs and Ohs – Elle King Lord-Alge Firework – Katy Perry Back to Black – Amy Winehouse Forever – Chris Brown Bad Guy – Billie Eilish Forget You – CeeLo Green Bad Romance – Lady Gaga Feels – Calvin Harris, Pharrell Williams, Bang Bang – Jessie J, Ariana Grande, Nicki Katy Perry Minaj Feel It Coming – The Weeknd Believe – Cher Feel It Still – Portugal. The Man Best Day of My Life – American Authors Get Lucky – Daft Punk Born This Way – Lady Gaga Get the Party Started – P!nk Bye Bye Bye – *NSYNC Give Me Everything – Ne-yo and Pitbull Cake by the Ocean – DNCE Good as Hell – Lizzo California Gurls – Katy Perry HaPPy – Pharrel Call Me Maybe – Carly Rae JePsen Havana – Camila Cabello Can’t Hold Us – Macklemore & Ryan Lewis Heaven – Los Lonely Boys Can’t StoP the Feeling – Justin Timberlake Hey Soul Sister – Train Candyman – Christina Aguilera High Horse – Kacey Musgraves Chandelier – Sia Ho Hey – The Lumineers CheaP Thrills – Sia Hold My Hand – Jess Glynne Cheerleader – OMI Holiday – Madonna Closer – The Chainsmokers I Don’t Like It, I Love It – Flo Rida and Robin Counting Stars – OneRePublic Thicke Crazy – Gnarls Barkley I Kissed a Girl – Katy Perry CreeP – TLC I Love It – Icona PoP Cruel Summer – Bananarama I Love You Always Forever – Donna Lewis Dancing on My Own – Robyn Into You – Ariana Grande Dear Future Husband – Meghan Trainor I Will Wait – Mumford & Sons Déjà Vu – Beyonce Ice Ice Baby – Vanilla Ice Domino – Jessie J Juice – Lizzo 1 Just Dance – Lady Gaga ShaPe of You – Ed Sheeran Just Fine – Mary J. -

Taylor Swift, 'Bad Blood'
Taylor Swift, ‘Bad Blood’ - Factsheet Taylor Swift, ‘Bad Blood’ (2015) https://youtu.be/QcIy9NiNbmo Subject content focus area Media language Representation Media industries Audiences Contexts Background context • ‘Bad Blood’ was released in May 2015. It was the fourth single to be released from the album 1989 (2014). • The single is a remixed version of the album track, with added guest vocals from Kendrick Lamar. It was premiered at the Billboard Music Awards. • The video broke video-streaming service Vevo’s 24-hour viewing record (accumulating 20.1 million views in its first day of release). • It won Video of the Year and Best Collaboration at the MTV Music Awards. It also won Best Music Video Grammy Award. • The video includes many references to popular action films of the past twenty years, contains captions and titles like a movie, and was marketed using ‘teaser’ posters featuring famous women from the ensemble cast, bearing the name of their character. This is a marketing technique often used in the film industry (e.g. Pulp Fiction) to introduce characters. • Swift also posted stills and behind-the-scenes shots on her Instagram account to build expectations. • Encouraged by comments by Swift on Twitter and Instagram, speculation was rife amongst fans about who the song is about. Many believed the target was Katy Perry, although the identity of the person has never been revealed. Part 1: Starting points - Media language • The setting for the video is modern-day London, and Swift’s secret training facility beneath the streets. • The colour palette for the video is mostly shiny and reflective black and white.