Multi-Labelled Value Networks for Computer Go
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
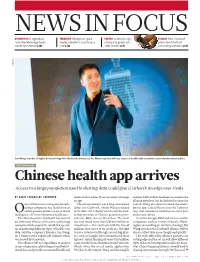
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

CSC321 Lecture 23: Go
CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 22 Final Exam Monday, April 24, 7-10pm A-O: NR 25 P-Z: ZZ VLAD Covers all lectures, tutorials, homeworks, and programming assignments 1/3 from the first half, 2/3 from the second half If there's a question on this lecture, it will be easy Emphasis on concepts covered in multiple of the above Similar in format and difficulty to the midterm, but about 3x longer Practice exams will be posted Roger Grosse CSC321 Lecture 23: Go 2 / 22 Overview Most of the problem domains we've discussed so far were natural application areas for deep learning (e.g. vision, language) We know they can be done on a neural architecture (i.e. the human brain) The predictions are inherently ambiguous, so we need to find statistical structure Board games are a classic AI domain which relied heavily on sophisticated search techniques with a little bit of machine learning Full observations, deterministic environment | why would we need uncertainty? This lecture is about AlphaGo, DeepMind's Go playing system which took the world by storm in 2016 by defeating the human Go champion Lee Sedol Roger Grosse CSC321 Lecture 23: Go 3 / 22 Overview Some milestones in computer game playing: 1949 | Claude Shannon proposes the idea of game tree search, explaining how games could be solved algorithmically in principle 1951 | Alan Turing writes a chess program that he executes by hand 1956 | Arthur Samuel writes a program that plays checkers better than he does 1968 | An algorithm defeats human novices at Go 1992 -

Fml-Based Dynamic Assessment Agent for Human-Machine Cooperative System on Game of Go
Accepted for publication in International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems in July, 2017 FML-BASED DYNAMIC ASSESSMENT AGENT FOR HUMAN-MACHINE COOPERATIVE SYSTEM ON GAME OF GO CHANG-SHING LEE* MEI-HUI WANG, SHENG-CHI YANG Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan *[email protected], [email protected], [email protected] PI-HSIA HUNG, SU-WEI LIN Department of Education, National University of Tainan, Tainan, Taiwan [email protected], [email protected] NAN SHUO, NAOYUKI KUBOTA Dept. of System Design, Tokyo Metropolitan University, Japan [email protected], [email protected] CHUN-HSUN CHOU, PING-CHIANG CHOU Haifong Weiqi Academy, Taiwan [email protected], [email protected] CHIA-HSIU KAO Department of Computer Science and Information Engineering, National University of Tainan, Tainan, Taiwan [email protected] Received (received date) Revised (revised date) Accepted (accepted date) In this paper, we demonstrate the application of Fuzzy Markup Language (FML) to construct an FML- based Dynamic Assessment Agent (FDAA), and we present an FML-based Human–Machine Cooperative System (FHMCS) for the game of Go. The proposed FDAA comprises an intelligent decision-making and learning mechanism, an intelligent game bot, a proximal development agent, and an intelligent agent. The intelligent game bot is based on the open-source code of Facebook’s Darkforest, and it features a representational state transfer application programming interface mechanism. The proximal development agent contains a dynamic assessment mechanism, a GoSocket mechanism, and an FML engine with a fuzzy knowledge base and rule base. -

Residual Networks for Computer Go Tristan Cazenave
Residual Networks for Computer Go Tristan Cazenave To cite this version: Tristan Cazenave. Residual Networks for Computer Go. IEEE Transactions on Games, Institute of Electrical and Electronics Engineers, 2018, 10 (1), 10.1109/TCIAIG.2017.2681042. hal-02098330 HAL Id: hal-02098330 https://hal.archives-ouvertes.fr/hal-02098330 Submitted on 12 Apr 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. IEEE TCIAIG 1 Residual Networks for Computer Go Tristan Cazenave Universite´ Paris-Dauphine, PSL Research University, CNRS, LAMSADE, 75016 PARIS, FRANCE Deep Learning for the game of Go recently had a tremendous success with the victory of AlphaGo against Lee Sedol in March 2016. We propose to use residual networks so as to improve the training of a policy network for computer Go. Training is faster than with usual convolutional networks and residual networks achieve high accuracy on our test set and a 4 dan level. Index Terms—Deep Learning, Computer Go, Residual Networks. I. INTRODUCTION Input EEP Learning for the game of Go with convolutional D neural networks has been addressed by Clark and Storkey [1]. It has been further improved by using larger networks [2]. -

Spy on Me #2 – Artistic Manoevres for the Digital Present
Spy on Me Artistic Manoeuvres for the Digital Present #2 19. –29.3.2020 Spy on Me #2 – Artistic Manoeuvres for the Digital Present 19.–29.3.2020 / HAU1, HAU2, HAU3 We have arrived in the reality of digital transformation. Life with screens, apps and algorithms influences our behaviour, our atten - tion and desires. Meanwhile the idea of the public space and of democracy is being reorganized by digital means. The festival “Spy on Me” goes into its second round after 2018, searching for manoeuvres for the digital present together with Berlin-based and international artists. Performances, interactive spatial installati - ons and discursive events examine the complex effects of the digi - tal transformation of society. In theatre, where live encounters are the focus, we come close to the intermediate spaces of digital life, searching for ways out of feeling powerless and overwhelmed, as currently experienced by many users of internet-based technolo - gies. For it is not just in some future digital utopia, but here, in the midst of this present, that we have to deal with the basic conditi - ons of living together as a society and of planetary survival. Are we at the edge of a great digital darkness or at the decisive tur - ning point of perspective? A Festival by HAU Hebbel am Ufer. Funded by: Hauptstadtkulturfonds. What is our rela - tionship with alien conscious - nesses? As we build rivals to human intelligence, James Bridle looks at our relationship with the planet’s other alien consciousnesses. 5 On 27 June 1835, two masters of the ancient DeepBlue defeated Garry Kasparov at chess, prise, strangeness and even horror that Chinese game of Go faced off in a match up to that point a game with Go-like status as AlphaGo evokes will become a feature of more which was the culmination of a years-long a bastion of human imagination and mental and more areas of our lives. -

Achieving Master Level Play in 9X9 Computer Go
Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (2008) Achieving Master Level Play in 9 9 Computer Go × Sylvain Gelly∗ David Silver† Univ. Paris Sud, LRI, CNRS, INRIA, France University of Alberta, Edmonton, Alberta, Canada Abstract simulated, using self-play, starting from the current position. Each position in the search tree is evaluated by the average The UCT algorithm uses Monte-Carlo simulation to estimate outcome of all simulated games that pass through that po- the value of states in a search tree from the current state. However, the first time a state is encountered, UCT has no sition. The search tree is used to guide simulations along knowledge, and is unable to generalise from previous expe- promising paths. This results in a highly selective search rience. We describe two extensions that address these weak- that is grounded in simulated experience, rather than an ex- nesses. Our first algorithm, heuristic UCT, incorporates prior ternal heuristic. Programs using UCT search have outper- knowledge in the form of a value function. The value function formed all previous Computer Go programs (Coulom 2006; can be learned offline, using a linear combination of a million Gelly et al. 2006). binary features, with weights trained by temporal-difference Monte-Carlo tree search algorithms suffer from two learning. Our second algorithm, UCT–RAVE, forms a rapid sources of inefficiency. First, when a position is encoun- online generalisation based on the value of moves. We ap- tered for the first time, no knowledge is available to guide plied our algorithms to the domain of 9 9 Computer Go, the search. -

Computer Go: from the Beginnings to Alphago Martin Müller, University of Alberta
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk ✤ Game of Go ✤ Short history - Computer Go from the beginnings to AlphaGo ✤ The science behind AlphaGo ✤ The legacy of AlphaGo The Game of Go Go ✤ Classic two-player board game ✤ Invented in China thousands of years ago ✤ Simple rules, complex strategy ✤ Played by millions ✤ Hundreds of top experts - professional players ✤ Until 2016, computers weaker than humans Go Rules ✤ Start with empty board ✤ Place stone of your own color ✤ Goal: surround empty points or opponent - capture ✤ Win: control more than half the board Final score, 9x9 board ✤ Komi: first player advantage Measuring Go Strength ✤ People in Europe and America use the traditional Japanese ranking system ✤ Kyu (student) and Dan (master) levels ✤ Separate Dan ranks for professional players ✤ Kyu grades go down from 30 (absolute beginner) to 1 (best) ✤ Dan grades go up from 1 (weakest) to about 6 ✤ There is also a numerical (Elo) system, e.g. 2500 = 5 Dan Short History of Computer Go Computer Go History - Beginnings ✤ 1960’s: initial ideas, designs on paper ✤ 1970’s: first serious program - Reitman & Wilcox ✤ Interviews with strong human players ✤ Try to build a model of human decision-making ✤ Level: “advanced beginner”, 15-20 kyu ✤ One game costs thousands of dollars in computer time 1980-89 The Arrival of PC ✤ From 1980: PC (personal computers) arrive ✤ Many people get cheap access to computers ✤ Many start writing Go programs ✤ First competitions, Computer Olympiad, Ing Cup ✤ Level 10-15 kyu 1990-2005: Slow Progress ✤ Slow progress, commercial successes ✤ 1990 Ing Cup in Beijing ✤ 1993 Ing Cup in Chengdu ✤ Top programs Handtalk (Prof. -

Reinforcement Learning of Local Shape in the Game of Go
Reinforcement Learning of Local Shape in the Game of Go David Silver, Richard Sutton, and Martin Muller¨ Department of Computing Science University of Alberta Edmonton, Canada T6G 2E8 {silver, sutton, mmueller}@cs.ualberta.ca Abstract effective. They are fast to compute; easy to interpret, modify and debug; and they have good convergence properties. We explore an application to the game of Go of Secondly, weights are trained by temporal difference learn- a reinforcement learning approach based on a lin- ing and self-play. The world champion Checkers program ear evaluation function and large numbers of bi- Chinook was hand-tuned by expert players over 5 years. nary features. This strategy has proved effective When weights were trained instead by self-play using a tem- in game playing programs and other reinforcement poral difference learning algorithm, the program equalled learning applications. We apply this strategy to Go the performance of the original version [7]. A similar ap- by creating over a million features based on tem- proach attained master level play in Chess [1]. TD-Gammon plates for small fragments of the board, and then achieved world class Backgammon performance after train- use temporal difference learning and self-play. This ingbyTD(0)andself-play[13]. A program trained by method identifies hundreds of low level shapes with TD(λ) and self-play outperformed an expert, hand-tuned ver- recognisable significance to expert Go players, and sion at the card game Hearts [11]. Experience generated provides quantitive estimates of their values. We by self-play was also used to train the weights of the world analyse the relative contributions to performance of champion Othello and Scrabble programs, using least squares templates of different types and sizes. -

Weiqi, Baduk): a Beautiful Game
Go (Weiqi, Baduk): A Beautiful Game Description Go is a strategy board game originating from China more than two thousand years ago. Though its rules are simple, the game is intractably complex; a top professional can easily defeat the best supercomputers today. It was considered one of the four essential skills of a Chinese scholar. The game spread to Korea and Japan, has flourished in East Asia, and is becoming more well-known in the West. Today, Go is enjoyed by more than 40 million players in the world. Objectives Students will learn the rules of go and become able to play at an intermediate level. They will also understand the game in a historical and/or mathematical context. We hope (but do not require) that students will be able to play at a single-digit kyu level (1k-9k). Students will also learn something significant from one of the following (or both): ◦ The culture and history of go, including its origins, historical figure, and presence in East Asia and the western world. ◦ Some mathematical results of go, including a treatment of go using combinatorial game theory. This will offer enough flexibility for students of all majors. Prerequisites None. We expect all students to be able to understand the course material. The course is designed to suit students of all majors. This course is not designed for dan-level players. We will not allow dan-level players to take this course. Course Format This course will be taught by Joshua Wu in both lecture and interactive formats. We hope to emphasize student participation. -

Learning to Play the Game of Go
Learning to Play the Game of Go James Foulds October 17, 2006 Abstract The problem of creating a successful artificial intelligence game playing program for the game of Go represents an important milestone in the history of computer science, and provides an interesting domain for the development of both new and existing problem-solving methods. In particular, the problem of Go can be used as a benchmark for machine learning techniques. Most commercial Go playing programs use rule-based expert systems, re- lying heavily on manually entered domain knowledge. Due to the complexity of strategy possible in the game, these programs can only play at an amateur level of skill. A more recent approach is to apply machine learning to the prob- lem. Machine learning-based Go playing systems are currently weaker than the rule-based programs, but this is still an active area of research. This project compares the performance of an extensive set of supervised machine learning algorithms in the context of learning from a set of features generated from the common fate graph – a graph representation of a Go playing board. The method is applied to a collection of life-and-death problems and to 9 × 9 games, using a variety of learning algorithms. A comparative study is performed to determine the effectiveness of each learning algorithm in this context. Contents 1 Introduction 4 2 Background 4 2.1 Go................................... 4 2.1.1 DescriptionoftheGame. 5 2.1.2 TheHistoryofGo ...................... 6 2.1.3 Elementary Strategy . 7 2.1.4 Player Rankings and Handicaps . 7 2.1.5 Tsumego .......................... -

Human Vs. Computer Go: Review and Prospect
This article is accepted and will be published in IEEE Computational Intelligence Magazine in August 2016 Human vs. Computer Go: Review and Prospect Chang-Shing Lee*, Mei-Hui Wang Department of Computer Science and Information Engineering, National University of Tainan, TAIWAN Shi-Jim Yen Department of Computer Science and Information Engineering, National Dong Hwa University, TAIWAN Ting-Han Wei, I-Chen Wu Department of Computer Science, National Chiao Tung University, TAIWAN Ping-Chiang Chou, Chun-Hsun Chou Taiwan Go Association, TAIWAN Ming-Wan Wang Nihon Ki-in Go Institute, JAPAN Tai-Hsiung Yang Haifong Weiqi Academy, TAIWAN Abstract The Google DeepMind challenge match in March 2016 was a historic achievement for computer Go development. This article discusses the development of computational intelligence (CI) and its relative strength in comparison with human intelligence for the game of Go. We first summarize the milestones achieved for computer Go from 1998 to 2016. Then, the computer Go programs that have participated in previous IEEE CIS competitions as well as methods and techniques used in AlphaGo are briefly introduced. Commentaries from three high-level professional Go players on the five AlphaGo versus Lee Sedol games are also included. We conclude that AlphaGo beating Lee Sedol is a huge achievement in artificial intelligence (AI) based largely on CI methods. In the future, powerful computer Go programs such as AlphaGo are expected to be instrumental in promoting Go education and AI real-world applications. I. Computer Go Competitions The IEEE Computational Intelligence Society (CIS) has funded human vs. computer Go competitions in IEEE CIS flagship conferences since 2009. -

Computer Go: an AI Oriented Survey
Computer Go: an AI Oriented Survey Bruno Bouzy Université Paris 5, UFR de mathématiques et d'informatique, C.R.I.P.5, 45, rue des Saints-Pères 75270 Paris Cedex 06 France tel: (33) (0)1 44 55 35 58, fax: (33) (0)1 44 55 35 35 e-mail: [email protected] http://www.math-info.univ-paris5.fr/~bouzy/ Tristan Cazenave Université Paris 8, Département Informatique, Laboratoire IA 2, rue de la Liberté 93526 Saint-Denis Cedex France e-mail: [email protected] http://www.ai.univ-paris8.fr/~cazenave/ Abstract Since the beginning of AI, mind games have been studied as relevant application fields. Nowadays, some programs are better than human players in most classical games. Their results highlight the efficiency of AI methods that are now quite standard. Such methods are very useful to Go programs, but they do not enable a strong Go program to be built. The problems related to Computer Go require new AI problem solving methods. Given the great number of problems and the diversity of possible solutions, Computer Go is an attractive research domain for AI. Prospective methods of programming the game of Go will probably be of interest in other domains as well. The goal of this paper is to present Computer Go by showing the links between existing studies on Computer Go and different AI related domains: evaluation function, heuristic search, machine learning, automatic knowledge generation, mathematical morphology and cognitive science. In addition, this paper describes both the practical aspects of Go programming, such as program optimization, and various theoretical aspects such as combinatorial game theory, mathematical morphology, and Monte- Carlo methods.