Analysis of Spammers' Behavior on a Live Streaming Chat
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
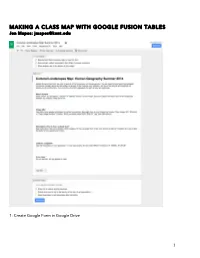
MAKING a CLASS MAP with GOOGLE FUSION TABLES Jen Mapes: [email protected]
MAKING A CLASS MAP WITH GOOGLE FUSION TABLES Jen Mapes: [email protected] 1: Create Google Form in Google Drive 1 2. Give form link (and further instructions) to students 2 3. When submission deadline has passed, Create a Fusion Table out of your “Responses” Spreadsheet (created automatically by Google Forms). If Fusion Tables does not show up as an option, you will need to “Connect more apps,” and select it. With a Kent account, you may need to go through an extra step. Ask me or a Help Desk person for assistance if you run into this problem. 3 This arrow will let you choose “change column” 4. Change type for your Lat/Long column to “Location.” Incorrect formats will be highlighted in yellow. 4 This arrow will let you choose “change column” 5. Change column for Image URL to Format: Eight Line Image 5 6 6. Choose the map tab, and your lat/longs will be geocoded on a map for you. If you use addresses instead, this may take an extra few minutes. 7. The option to configure your map should show up when your map is created. If it disappears, go to Tools/Change Map. You will then see two options: Change feature styles (the dots on the map), and change info window (what pops up when you click on the dots). 7 8. If you’d like to change the dots, or have them represented by different colors/styles depending on their values, then you’ll change the feature styles. Column allows you to use your spreadsheet (or form) to select what icon will appear with each submission. -

Applying Library Values to Emerging Technology Decision-Making in the Age of Open Access, Maker Spaces, and the Ever-Changing Library
ACRL Publications in Librarianship No. 72 Applying Library Values to Emerging Technology Decision-Making in the Age of Open Access, Maker Spaces, and the Ever-Changing Library Editors Peter D. Fernandez and Kelly Tilton Association of College and Research Libraries A division of the American Library Association Chicago, Illinois 2018 The paper used in this publication meets the minimum requirements of Ameri- can National Standard for Information Sciences–Permanence of Paper for Print- ed Library Materials, ANSI Z39.48-1992. ∞ Cataloging-in-Publication data is on file with the Library of Congress. Copyright ©2018 by the Association of College and Research Libraries. All rights reserved except those which may be granted by Sections 107 and 108 of the Copyright Revision Act of 1976. Printed in the United States of America. 22 21 20 19 18 5 4 3 2 1 Contents Contents Introduction .......................................................................................................ix Peter Fernandez, Head, LRE Liaison Programs, University of Tennessee Libraries Kelly Tilton, Information Literacy Instruction Librarian, University of Tennessee Libraries Part I Contemplating Library Values Chapter 1. ..........................................................................................................1 The New Technocracy: Positioning Librarianship’s Core Values in Relationship to Technology Is a Much Taller Order Than We Think John Buschman, Dean of University Libraries, Seton Hall University Chapter 2. ........................................................................................................27 -

Forensic Methods and Tools for Web Environments
Forensic Methods and Tools for Web Environments by Michael Kent Mabey A Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy Approved November 2017 by the Graduate Supervisory Committee: Gail-Joon Ahn, Co-Chair Adam Doupé, Co-Chair Stephen S. Yau Joohyung Lee Ziming Zhao ARIZONA STATE UNIVERSITY December 2017 ABSTRACT The Web is one of the most exciting and dynamic areas of development in today’s technology. However, with such activity, innovation, and ubiquity have come a set of new challenges for digital forensic examiners, making their jobs even more difficult. For examiners to become as effective with evidence from the Web as they currently are with more traditional evidence, they need (1) methods that guide them to know how to approach this new type of evidence and (2) tools that accommodate web environments’ unique characteristics. In this dissertation, I present my research to alleviate the difficulties forensic examiners currently face with respect to evidence originating from web environments. First, I introduce a framework for web environment forensics, which elaborates on and addresses the key challenges examiners face and outlines a method for how to approach web-based evidence. Next, I describe my work to identify extensions installed on encrypted web thin clients using only a sound understanding of these systems’ inner workings and the metadata of the encrypted files. Finally, I discuss my approach to reconstructing the timeline of events on encrypted web thin clients by using service provider APIs as a proxy for directly analyzing the device. In each of these research areas, I also introduce structured formats that I customized to accommodate the unique features of the evidence sources while also facilitating tool interoperability and information sharing. -

The SPS Google Docs and Drive 21 Day Challenge!
Welcome to the SPS Google Docs and Drive 21 Day Challenge! There is a popular notion that it takes 21 days to create a new habit and I thought it might be fun to break up the district's introduction to Google Docs and Drive into 21 bitesized chunks. Hence, the SPS Google Drive 21 day challenge! Look for a new (and small) Google Drive tip each day via district email for the next 21 school days. Hopefully, this approach will make trying out the new tools easier, more manageable, and maybe even a little fun. In addition to the 21 day challenge tips, you should check out these other Google Docs and Drive resources: ● Google Docs and Drive Basics,https://www.google.com/edu/training/tools/drive/level1.html ● Google Docs and Drive uses in the classroom,https://www.google.com/edu/training/tools/drive/level2.html Day 1 How do I get to Google Drive? Let's start with a quick and easy tip! Like the other tools included in Google Apps for Education (Calendar, Sites, etc.), Google Drive can be quickly accessed right from your email screen. Here's how: 1. Click the "Grid" icon at the top of the screen next to your email address (or your picture if you've added one) 2. Click the icon for "Drive" 3. A new browser tab or window will open displaying your Google Drive 4. If you're using a modern web browser like Google Chrome or Mozilla Firefox, you can easily switch back and forth between your Mail and your Drive just by clicking on the corresponding tabs at the top of the browser window BTW, if you want to get a good, quick overview of what Google Drive is and why you would even want to use it, take a look at these short videos. -

Honey Sheets: What Happens to Leaked Google Spreadsheets?
Honey Sheets: What Happens To Leaked Google Spreadsheets? Martin Lazarov, Jeremiah Onaolapo, and Gianluca Stringhini University College London [email protected],fj.onaolapo,[email protected] Abstract suite that provides business tools like official email ad- dresses, calendars, online storage space, and document Cloud-based documents are inherently valuable, due to processing services. the volume and nature of sensitive personal and business Consequently, a considerable amount of valuable in- content stored in them. Despite the importance of such formation is stored in online accounts, including sensi- documents to Internet users, there are still large gaps in tive personal information and business secrets. These in the understanding of what cybercriminals do when they turn attract cybercriminals seeking to make profit from illicitly get access to them by for example compromising such information. To gain access to such online ac- the account credentials they are associated with. In this counts, cybercriminals typically target owners of the ac- paper, we present a system able to monitor user activity counts with phishing attacks, and sometimes, malware. on Google spreadsheets. We populated 5 Google spread- Often, databases containing user credentials are also at- sheets with fake bank account details and fake funds tacked, and credentials in them get stolen. transfer links. Each spreadsheet was configured to re- Stolen credentials are usually sold by cybercriminals port details of accesses and clicks on links back to us. in underground marketplaces, to other cybercriminals for To study how people interact with these spreadsheets in malicious purposes. Depending on the nature of the com- case they are leaked, we posted unique links pointing to promised accounts, some are used to send unsolicited the spreadsheets on a popular paste site. -

Southern Kern Unified School District Barbara E
California Department of Education, July 2020 Learning Continuity and Attendance Plan Template (2020–21) The instructions for completing the Learning Continuity and Attendance Plan is available at https://www.cde.ca.gov/re/lc/documents/lrngcntntyatndncpln-instructions.docx. Local Educational Agency (LEA) Name Contact Name and Title Email and Phone Southern Kern Unified School District Barbara E. Gaines, Superintendent [email protected], (661) 256-5000 General Information [A description of the impact the COVID-19 pandemic has had on the LEA and its community.] General LEA Information: Southern Kern Unified School District (SKUSD) is committed to excellence in TK – 12 education. SKUSD serves the city of Rosamond, which is located in the Antelope Valley. SKUSD is home to a diverse community, with approximately 3500 students. The district consists of Rosamond High School Early College Campus, Tropico Middle School, Westpark Elementary School, Rosamond Elementary School, Abraham Lincoln Independent Study and Rare Earth Alternative High School. In SKUSD, 59.67% of the student population are Hispanic or Latino, 25.18% White, 10.55% African American, 1.26% American Indian or Alaskan Native, 3% Other. Socioeconomically Disadvantaged - 75.47% English Learners – 13.25% Foster Youth – 2.82% Special Education – 16.28% Military – 6.70% Homeless – 4.85% COVID-19 Impact: The impact created by the COVID-19 virus has created several challenges for Southern Kern Unified School District (SKUSD) and the community of Rosamond beginning in March of 2020. Governor Gavin Newsom declared a State of Emergency on March 4, 2020. As the number of COVID-19 cases grew, schools throughout the state had to close as a means to prevent the spread of the virus. -

DRC INSIGHT System Requirements Table of Contents 2 UPDATE: What’S New, Ended, Ending and Coming 2 UPDATE: New Or Changing DRC Technology 4 Minimum Vs
System Requirements Effective June 2021–October 2021 Current Update: June 25, 2021 Next Update: October 2021 This document is updated three times each calendar year. Table of Contents DRC INSIGHT System Requirements Table of Contents 2 UPDATE: What’s New, Ended, Ending and Coming 2 UPDATE: New or Changing DRC Technology 4 Minimum vs. Recommended 4 DRC INSIGHT Testing Device Requirements 5 DRC INSIGHT Testing Device Additional Notes 6 COS Service Device Requirements 8 DRC’s Device Support Policy 9 DRC’s Operating System Support Policy 10 DRC’s Operating System Version Support 11 Trademarks 13 UPDATE: What’s New, Ended, Ending and Coming The following is an overview of upcoming changes to the hardware and software supported for DRC INSIGHT and/or COS Service Devices. Operating System Support What’s New Windows 10 Spring Release (21H1) Microsoft released version 21H1 in spring of 2021. Support for this release will follow DRC’s Operating System Support Policy. Starting in July of 2021, DRC will only support the Microsoft supported versions of Windows 10. Support will be consistent with our Operating System Support Policy (see page 10). What’s Ended Windows 7 As a reminder, Microsoft ended support for Windows 7 in January of 2020. DRC no longer supports or allows Windows 7 for testing. Ubuntu 16.04 Support for Ubuntu 16.04 ended in April of 2021. DRC moved it to Best Effort Support in May of 2021 and will move it to End of Support in June of 2021. What’s Ending iPadOS 13 DRC anticipates Apple will discontinue support of iPadOS 13 in September with the introduction of iPadOS 15. -

2021 M-STEP Test Administration Manual (TAM)
TM Spring 2021 M-STEP Test Administration Manual (TAM) Updated April 2021 Table of Contents How To Use This Manual . 6 Assessment System Access for District and Building Assessment Coordinators . 18. Introduction . 6 THE OEAA SECURE SITE . 18 THE EDUCATIONAL ENTITY MASTER . 19 Testing Schedules . 9 DRC INSIGHT PORTAL . 19 Overview . 12 Roles and Responsibilities . 20 Roles and Responsibilities . .20 M-STEP Assessments . 12. DISTRICT COORDINATORS . 20 What’s New . .12 BUILDING COORDINATORS . 20 English Language Arts . 13. TEST ADMINISTRATORS . 21 LISTENING . 13 TECHNOLOGY COORDINATORS . 21 Mathematics . 14. Supports and CALCULATOR POLICY FOR MATHEMATICS ASSESSMENTS . 14 Accommodations . 22 Science . .15 What Are Supports CALCULATOR POLICY FOR and Accommodations? . 22. SCIENCE ASSESSMENTS . 15 Supports and Accommodations Social Studies . 15. Tracking Sheet . .22 The Michigan Merit Examination . .16 Ordering Accommodated Materials . .22 Required Grade 8 Testing . 16. Embedded and Non-embedded Supports Test Administrator’s Directions and Manual 16 and Accommodations . .23 Scratch Paper Guidelines . .16 Turning On Designated Supports and Accommodations . .23 Designated Supports and Accommodations 16 Verifying Test Tickets . 23. Resources for Students to Prepare for Testing . .17 Where to Find More Information on Designated Supports and Accommodations 24 Call Center Contact Information . .17 Nonstandard Accommodations . .24 OEAA Communications with Schools and Districts . 17. Filling Out Designated Supports and Accommodations Information on Answer Standardized Testing . 18. Documents . 25 2 M-STEP Test Administration Manual Table of Contents ELA STANDARD SUPPORTS M-STEP Multiplication Table . .33 AND ACCOMMODATIONS . 25 Returning Accommodated Materials MATHEMATICS STANDARD SUPPORTS and Answer Documents . 33. AND ACCOMMODATIONS . 25 Other Reminders for Test Administrators SCIENCE AND SOCIAL STUDIES STANDARD SUPPORTS AND ACCOMMODATIONS . -

The Chinese Music Industries: Top Down in the Bottom up Age
The Chinese Music Industries: Top Down in the Bottom Up Age Guy Morrow and Fangjun Li Final, accepted version of a chapter to be published in Patrik Wikstrom and Robert Defillippi (eds), Business Innovation and Disruption in the Music Industry, Cheltenham, UK: Edward Elgar Publishing, 2015. Introduction This chapter examines the Chinese government’s investment in the cultural industries in China that relate to music. It argues that this investment has fostered horizontal integration across music content and technology industry boundaries in this country. By examining the role of the Chinese government in developing creative industries via financial subsidies and other forms of infrastructure support, an important difference in cultural industry policy between China and many countries in the West is outlined. Specifically, China’s top down policy approach (Zhu, 2009; Cai et al, 2006) and censorship of digital content (Street, 2012; De Kloet, 2010) contrasts starkly with the emergent ‘bottom up’ paradigm (Hracs, 2012: 455-56; Young and Collins, 2010: 344-45; Hesmondhalgh, 2015) that has arisen is a number of countries in the West. The question of how these music industries have been affected by digital distribution, and how this has led to business innovation and disruption in the music industries, has necessarily been accompanied by discourse relating to the freedom of speech and expression, as well as human rights in China (Keane, 2013). This is perhaps best exemplified by the example of Google’s failed attempt to use free music to 1 gain market share from the popular search engine Baidu in China (Schroeder, 2009). This chapter in part examines this case and the way in which Google attempted this initiative due to the high level of piracy in China and the way in which Baidu was facilitating piracy in order to gain market share. -

Territorialization of the Internet Domain Name System
Scholarly Commons @ UNLV Boyd Law Scholarly Works Faculty Scholarship 2018 Territorialization of the Internet Domain Name System Marketa Trimble University of Nevada, Las Vegas -- William S. Boyd School of Law Follow this and additional works at: https://scholars.law.unlv.edu/facpub Part of the Intellectual Property Law Commons, International Law Commons, and the Internet Law Commons Recommended Citation Trimble, Marketa, "Territorialization of the Internet Domain Name System" (2018). Scholarly Works. 1020. https://scholars.law.unlv.edu/facpub/1020 This Article is brought to you by the Scholarly Commons @ UNLV Boyd Law, an institutional repository administered by the Wiener-Rogers Law Library at the William S. Boyd School of Law. For more information, please contact [email protected]. Territorialization of the Internet Domain Name System Marketa Trimble* Abstract Territorializationof the internet-the linking of the internet to physical geography is a growing trend. Internet users have become accustomed to the conveniences of localized advertising, have enjoyed location-based services, and have witnessed an increasing use of geolocation and geo- blocking tools by service and content providers who for various reasons- either allow or block access to internet content based on users' physical locations. This article analyzes whether, and if so how, the trend toward territorializationhas affected the internetDomain Name System (DNS). As a hallmark of cyberspace governance that aimed to be detached from the territorially-partitionedgovernance of the physical world, the DNS might have been expected to resist territorialization-a design that seems antithetical to the original design of and intent for the internet as a globally distributed network that lacks a single point of control. -

Learning Continuity and Attendance Plan
California Department of Education, July 2020 Learning Continuity and Attendance Plan Template (2020–21) The instructions for completing the Learning Continuity and Attendance Plan is available at https://www.cde.ca.gov/re/lc/documents/lrngcntntyatndncpln-instructions.docx. Local Educational Agency (LEA) Name Contact Name and Title Email and Phone Southern Kern Unified School District Barbara E. Gaines, Superintendent [email protected], (661) 256-5000 General Information [A description of the impact the COVID-19 pandemic has had on the LEA and its community.] General LEA Information: Southern Kern Unified School District (SKUSD) is committed to excellence in TK – 12 education. SKUSD serves the city of Rosamond, which is located in the Antelope Valley. SKUSD is home to a diverse community, with approximately 3500 students. The district consists of Rosamond High School Early College Campus, Tropico Middle School, Westpark Elementary School, Rosamond Elementary School, Abraham Lincoln Independent Study and Rare Earth Alternative High School. In SKUSD, 59.67% of the student population are Hispanic or Latino, 25.18% White, 10.55% African American, 1.26% American Indian or Alaskan Native, 3% Other. Socioeconomically Disadvantaged - 75.47% English Learners – 13.25% Foster Youth – 2.82% Special Education – 16.28% Military – 6.70% Homeless – 4.85% COVID-19 Impact: The impact created by the COVID-19 virus has created several challenges for Southern Kern Unified School District (SKUSD) and the community of Rosamond beginning in March of 2020. Governor Gavin Newsom declared a State of Emergency on March 4, 2020. As the number of COVID-19 cases grew, schools throughout the state had to close as a means to prevent the spread of the virus. -

CAREER GUIDE 2021-2022 Krannert Professional Development Center CAREER GUIDE 2021 2022 CONTENTS
CAREER GUIDE 2021-2022 Krannert Professional Development Center CAREER GUIDE 2021 2022 CONTENTS 2021-2022 CAREER GUIDE Director’s Letter .....................................................................................2 Resources Interviews What Happens During the Interview?.....................................20 Our Mission .............................................................................................3 Business Casual vs. Professional ...............................................21 The KPDC Process...............................................................................4 Sample Interview Questions ........................................................22 The KPDC Process in Action ..........................................................5 The Psychology Behind Interview Questions .....................23 Career Search Activities Timeline ................................................6 Questions to Ask Employers ........................................................23 Krannert Master’s Programs Major Career Events .............6 The Site Visit/Interview: One Step Closer ............................24 Preparing for a Virtual Interview ................................................25 Resumes And Cover Letters Resume Rules and Guidelines .......................................................7 Power Verbs for Your Resume .......................................................8 Evaluating And Negotiating Offers The Art of Negotiating .....................................................................26 Sample