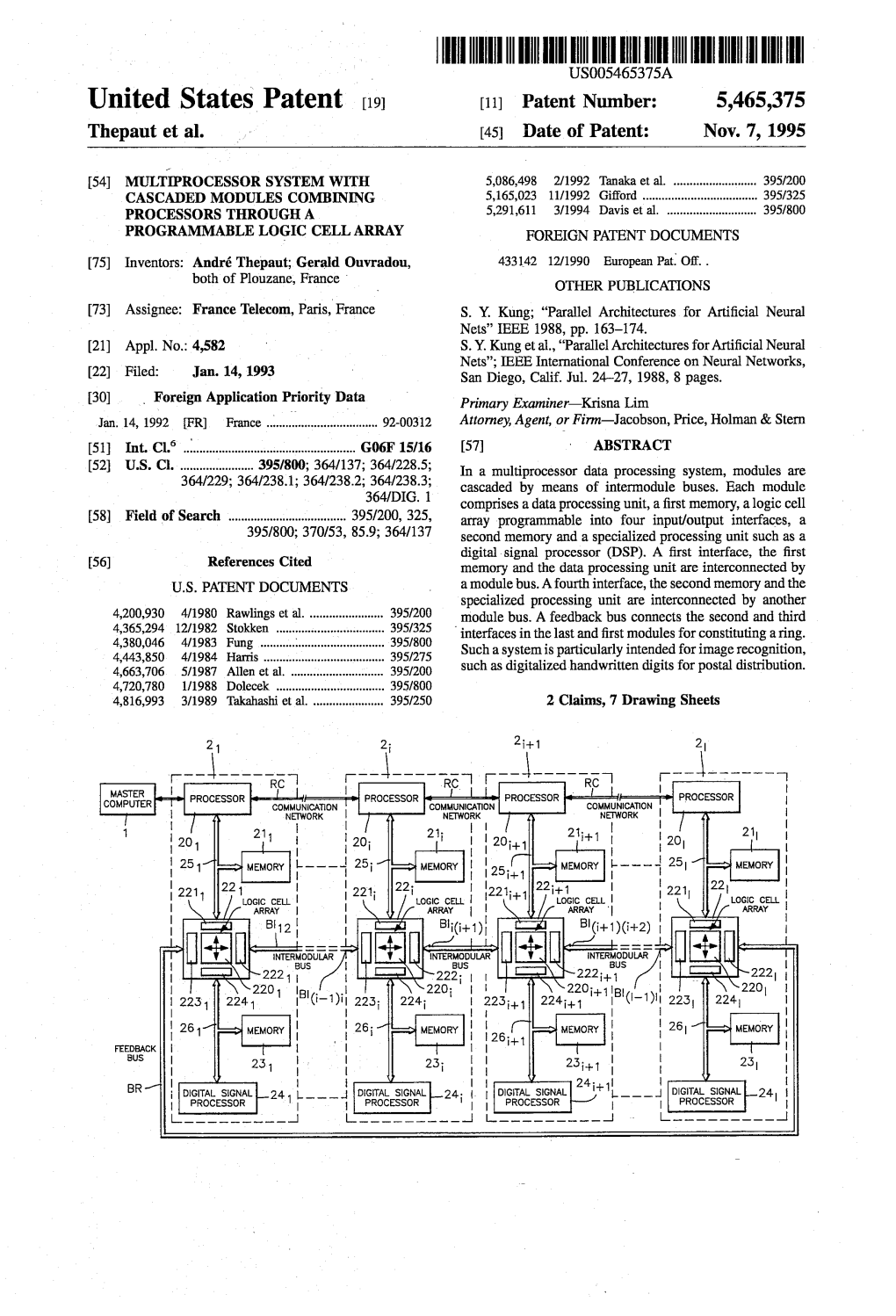
2611-Wevor ; 26.1 Evor FEECK 251 23; 23 BR- : Digital Signal
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

And Complex-Valued Multiply-Accumulate SIMD Unit for Digital Signal Processors
An Area Efficient Real- and Complex-Valued Multiply-Accumulate SIMD Unit for Digital Signal Processors Lukas Gerlach, Guillermo Paya-Vay´ a,´ and Holger Blume Cluster of Excellence Hearing4all, Institute of Microelectronic Systems Leibniz Universitat¨ Hannover, Appelstr. 4, 30167 Hannover, Germany Email: {gerlach, guipava, blume}@ims.uni-hannover.de Abstract—This paper explores a real- and complex-valued In the signal processing field, the fast Fourier transform multiply-accumulate (MAC) functional unit for digital signal pro- (FFT) is one of the mostly used transformations, which greatly cessors. MAC units with single-instruction-multiple-data (SIMD) pushes the performance requirements. The data parallelism support are often used to increase the processing performance inherent in the FFT processing allows operating with many in modern signal processing processors. Compared to a real- independent MAC operations simultaneously. Therefore, a valued SIMD-MAC units, the proposed unit uses the same performance increment can be achieved by MAC units with multipliers to also support complex-valued SIMD-MAC and butterfly operations. The area overhead for the complex mode SIMD mechanisms, but many instructions are still needed to is small. Complex-valued operations speed up signal processing operate the real- and imaginary parts of complex numbers algorithms and make the execution more efficient in terms of separately. The use of single instructions in DSPs, executing power consumption. As a case study, a fast Fourier transform operations with complex numbers, can lead to a significant (FFT) is implemented for a VLIW-processor with a complex- performance gain in many signal processing algorithms. valued SIMD butterfly extension. The proposed functional unit is quantitatively evaluated in terms of performance, silicon area, A SIMD-MAC unit that can handle both complex and and power consumption. -

A Many-Core Architecture for In-Memory Data Processing
A Many-core Architecture for In-Memory Data Processing Sandeep R Agrawal Sam Idicula Arun Raghavan [email protected] [email protected] [email protected] Oracle Labs Oracle Labs Oracle Labs Evangelos Vlachos Venkatraman Govindaraju Venkatanathan Varadarajan [email protected] [email protected] venkatanathan.varadarajan@oracle. Oracle Labs Oracle Labs com Oracle Labs Cagri Balkesen Georgios Giannikis Charlie Roth [email protected] [email protected] [email protected] Oracle Labs Oracle Labs Oracle Labs Nipun Agarwal Eric Sedlar [email protected] [email protected] Oracle Labs Oracle Labs ABSTRACT ACM Reference format: For many years, the highest energy cost in processing has been Sandeep R Agrawal, Sam Idicula, Arun Raghavan, Evangelos Vlachos, Venka- traman Govindaraju, Venkatanathan Varadarajan, Cagri Balkesen, Georgios data movement rather than computation, and energy is the limiting Giannikis, Charlie Roth, Nipun Agarwal, and Eric Sedlar. 2017. A Many-core factor in processor design [21]. As the data needed for a single Architecture for In-Memory Data Processing. In Proceedings of MICRO-50, application grows to exabytes [56], there is clearly an opportunity Cambridge, MA, USA, October 14–18, 2017, 14 pages. to design a bandwidth-optimized architecture for big data compu- https://doi.org/10.1145/3123939.3123985 tation by specializing hardware for data movement. We present the Data Processing Unit or DPU, a shared memory many-core that is specifically designed for high bandwidth analytics workloads. 1 INTRODUCTION The DPU contains a unique Data Movement System (DMS), which A large number of data analytics applications in areas varying provides hardware acceleration for data movement and partition- from business intelligence, health sciences and real time log and ing operations at the memory controller that is sufficient to keep telemetry analysis already benefit from working sets that span up with DDR bandwidth. -

NVIDIA Bluefield-2 Datasheet
NVIDIA BLUEFIELD-2 DPU DATA CENTER INFRASTRUCTURE ON A CHIP The NVIDIA® BlueField®-2 data processing unit (DPU) is the world’s first data center Key Features infrastructure-on-a-chip optimized for traditional enterprises’ modern cloud workloads and high performance computing. It delivers a broad set of accelerated software- Security defined networking, storage, security, and management services with the ability to > Hardened isolation layer offload, accelerate and isolate data center infrastructure. With its 200Gb/s Ethernet or > Hardware root of trust > IPsec/TLS and AES-XTS encryption InfiniBand connectivity, the BlueField-2 DPU enables organizations to transform their IT acceleration infrastructures into state-of-the-art data centers that are accelerated, fully > Connection tracking for stateful firewall and programmable, and armed with “zero trust” security to prevent data breaches and IDS/IPS cyber attacks. > Regular expression (RegEx) matching processor ® By combining the industry-leading NVIDIA ConnectX -6 Dx network adapter with an Storage ® array of Arm cores and infrastructure-specific offloads, BlueField-2 offers purpose- > NVIDIA GPUDirect® Storage built, hardware-acceleration engines with full software programmability. Sitting at the > Elastic block storage enabled by BlueField edge of every server, BlueField-2 empowers agile, secured and high-performance cloud SNAP storage virtualization > Compression and decompression and artificial intelligence (AI) workloads, all while reducing the total cost of ownership acceleration and increasing data center efficiency. > NVMe-oF acceleration > VirtIO-blk acceleration The NVIDIA DOCA™ software framework enables developers to rapidly create applications and services for the BlueField-2 DPU. NVIDIA DOCA makes it easy to Networking leverage DPU hardware accelerators, providing breakthrough data center performance, > RoCE, Zero Touch RoCE efficiency and security. -

Bluefield As Platform
VISION ON NETWORKING IN THE AGE OF AI January 2021 J.J. Vegas Olmos, L. Liss, T. Oved, Z. Binshtock, D. Goldenberg DISCLAIMER • I only have 15 minutes and certainly the deck is long • I will go through some slides quickly • We can always engage in a conversation off-line [email protected] • You will notice throughout the presentation we are transmission media agnostic • Fiber, copper, wireless… not really relevant • Each media has its place and time • Whenever I say “Currently it is like this, but it will be like that” – that is a research line that requires efforts 2 DATA PROCESSING UNIT VISION NVIDIA’s DPU (Data Processing Unit) are the smallest DC you can have • A DPU is • A network interface • A SoC for programmability • A GPU • An acceleration enginee…. NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE. 3 A LITTLE BIT OF BACKGROUND: THE DATA CENTER IS THE NEW UNIT OF COMPUTING Accelerated Disaggregated Infrastructure (ADI) Accelerated Computing Software defined, GPU: AI & machine learning Hardware-accelerated DPU (data processing unit) GPU critical for AI & machine learning Every workload will become AI Accelerated DPU essential to disaggregate resources & make composable ADI NVIDIA Networking You can do 3 things with data: transport it, processed it, use it. As of 2020, NVIDIA covers these three pilars with the incorporation of Mellanox Technologies 4 DISAGGREGATION & COMPOSABILITY All Resources Become Virtualized and Composable GPUs CPUs Ethernet Switches Ethernet Adapter Cards (NICs) Storage MEM/PMEM The NVIDIA Network is the Backplane of the Data Center | Dynamically Compose the Computer You Need! NVIDIA CONFIDENTIAL. DO NOT DISTRIBUTE. -

Smartnics: Current Trends in Research and Industry
SmartNICs: Current Trends in Research and Industry Tristan Döring, Henning Stubbe∗, Kilian Holzinger∗ ∗Chair of Network Architectures and Services, Department of Informatics Technical University of Munich, Germany Email: [email protected], [email protected], [email protected] Abstract—With ever rising demand, modern cloud environ- 2. Trends and Technological Demands in ments had to evolve fast in the last years. One of these novel Cloud/Hosting Industry problems are the increasing speed requirements in com- bination with present Software-Defined Networks (SDNs). Before diving deeper into the topic of SmartNICs this This paper gives an overview on a new hardware trend section will give a short overview on the current state resulting from this. We illustrate the demand, development, of the industry. The new guiding trend is the virtualiza- implementation and use of the network accelerating Smart- tion of networks, storage, GPUs etc. These techniques NICs. SmartNICs tackle existing problems of NIC-hardware generate network related workloads not only on network such as the lack of flexibility, a requirement for virtualized devices as virtualization can not independently run on e.g. networks. Furthermore the SmartNIC term will be analyzed NICs. The network processing can be divided into two to provide an universal definition. categories, i.e. the data plane and the control plane. The control plane is responsible for the control of the network Index Terms—SmartNIC, network accelerator, data process- structure, i.e. communications between network devices ing unit, fpga-based smartnic, asic-based smartnic, soc-based and assigning tasks to network devices. In other words smartnic it is the implementation of network policies. -

Opportunities for Near Data Computing in Mapreduce Workloads
OPPORTUNITIES FOR NEAR DATA COMPUTING IN MAPREDUCE WORKLOADS by Seth Hintze Pugsley A dissertation submitted to the faculty of The University of Utah in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science School of Computing The University of Utah May 2015 Copyright ⃝c Seth Hintze Pugsley 2015 All Rights Reserved The University of Utah Graduate School STATEMENT OF DISSERTATION APPROVAL The dissertation of Seth Hintze Pugsley has been approved by the following supervisory committee members: Rajeev Balasubramonian , Chair 12 May 2014 Date Approved Alan L. Davis , Member 12 May 2014 Date Approved Erik L. Brunvand , Member 3 June 2014 Date Approved Feifei Li , Member 15 May 2014 Date Approved Vijayalakshmi Srinivasan , Member 19 June 2014 Date Approved and by Ross Whitaker , Chair/Dean of the Department/College/School of Computing and by David B. Kieda, Dean of The Graduate School. ABSTRACT In-memory big data applications are growing in popularity, including in-memory versions of the MapReduce framework. The move away from disk-based datasets shifts the performance bottleneck from slow disk accesses to memory bandwidth. MapReduce is a data-parallel application, and is therefore amenable to being executed on as many parallel processors as possible, with each processor requiring high amounts of memory bandwidth. We propose using Near Data Computing (NDC) as a means to develop systems that are optimized for in-memory MapReduce workloads, offering high compute parallelism and even higher memory bandwidth. This dissertation explores three different implementations and styles of NDC to improveMapReduce execution. First, we use 3D-stacked memory+logic devices to process the Map phase on compute elements in close proximity to database splits. -

Dpus: Acceleration Through Disaggregation
DPUS: ACCELERATION THROUGH DISAGGREGATION Hussein Baligh Ebrahim Serag Senior Advisor, Sales Engineer Analyst Sales Engineer Analyst Dell Technologies Dell Technologies [email protected] [email protected] Sameh Talaat Yehia Gaballah Senior Advisor, Customer/Technical Training Sales Engineer Analyst, Data Protection Solutions Dell Technologies Dell Technologies [email protected] [email protected] Knowledge Sharing Article © 2020 Dell Inc. or its subsidiaries. The Dell Technologies Proven Professional Certification program validates a wide range of skills and competencies across multiple technologies and products. From Associate, entry-level courses to Expert-level, experience-based exams, all professionals in or looking to begin a career in IT benefit from industry-leading training and certification paths from one of the world’s most trusted technology partners. Proven Professional certifications include: • Cloud • Converged/Hyperconverged Infrastructure • Data Protection • Data Science • Networking • Security • Servers • Storage • Enterprise Architect Courses are offered to meet different learning styles and schedules, including self-paced On Demand, remote-based Virtual Instructor-Led and in-person Classrooms. Whether you are an experienced IT professional or just getting started, Dell Technologies Proven Professional certifications are designed to clearly signal proficiency to colleagues and employers. Learn more at www.dell.com/certification 2021 Dell Technologies Proven Professional Knowledge Sharing 2 Table of -

Big Data Meets HPC Log Analytics: Scalable Approach to Understanding Systems at Extreme Scale
Big Data Meets HPC Log Analytics: Scalable Approach to Understanding Systems at Extreme Scale Byung H. Park∗, Saurabh Hukerikar∗, Ryan Adamsony, and Christian Engelmann∗ ∗Computer Science and Mathematics Division yNational Center for Computational Sciences Oak Ridge National Laboratory Oak Ridge, TN, USA Email: fparkbh, hukerikarsr, adamsonrm, [email protected] Abstract—Today’s high-performance computing (HPC) sys- This system activity and event information is logged for mon- tems are heavily instrumented, generating logs containing in- itoring and analysis. Large-scale HPC installations produce formation about abnormal events, such as critical conditions, various types of log data. For example, job logs maintain faults, errors and failures, system resource utilization, and about the resource usage of user applications. These logs, once fully a history of application runs, the allocated resources, their analyzed and correlated, can produce detailed information about sizes, user information, and exit statuses, i.e., successful vs. the system health, root causes of failures, and analyze an failed. Reliability, availability and serviceability (RAS) system application’s interactions with the system, providing valuable logs derive data from various hardware and software sensors, insights to domain scientists and system administrators. However, such as temperature sensors, memory errors and processor processing HPC logs requires a deep understanding of hardware and software components at multiple layers of the system stack. utilization. Network systems collect data about network link Moreover, most log data is unstructured and voluminous, making bandwidth, congestion and routing and link faults. Input/output it more difficult for system users and administrators to manually (I/O) and storage systems produce logs that record perfor- inspect the data. -

Hardware Acceleration of Biophotonic Simulations by Tanner Young
Hardware Acceleration of Biophotonic Simulations by Tanner Young-Schultz A thesis submitted in conformity with the requirements for the degree of Master of Applied Science Graduate Department of Electrical and Computer Engineering University of Toronto c Copyright 2020 by Tanner Young-Schultz Abstract Hardware Acceleration of Biophotonic Simulations Tanner Young-Schultz Master of Applied Science Graduate Department of Electrical and Computer Engineering University of Toronto 2020 The simulation of light propagation through tissue is important for medical applications like diffuse optical tomography (DOT), bioluminescence imaging (BLI) and photodynamic therapy (PDT). These applications involve solving an inverse problem, which works backwards from a light distribution to the parameters that caused it. These inverse problems have no general closed-form solution and therefore are approximated using iterative techniques. Increasing the accuracy of the approximation requires performing many light propagation simulations which is time-consuming and computationally intensive. We describe algorithmic techniques to improve the performance, accuracy and usability of the fastest software simulator for forward light propagation, FullMonteSW. Additionally, we explore two acceler- ation methods using a GPU and an FPGA. Our results show that the GPU and FPGA accelerator improve the performance by 4-13x and 4x, respectively, over the software baseline. We give insight for improving the performance and usability of the GPU- and FPGA-accelerated simulators for various medical applications. ii Acknowledgements To my lab mates, I am extremely grateful for the fun times and support. Over the last two years, I have enjoyed everything from the laughs to the heated (friendly) arguments. To my supervisors, Vaughan Betz and Stephen Brown. -

A Many-Core Architecture for In-Memory Data Processing
MICRO 2017 Submission #XXX – Confidential Draft – Do NOT Distribute!! A Many-core Architecture for In-Memory Data Processing ABSTRACT program due to their SIMT programming model and intoler- We live in an information age, with data and analytics guiding ance to control flow divergence. Their dependence on high a large portion of our daily decisions. Data is being generated bandwidth graphics memory to sustain the large number of at a tremendous pace from connected cars, connected homes on-die cores severely constraints their memory capacity. A and connected workplaces, and extracting useful knowledge single GPU with 300+ GB/s of memory bandwidth still sits from this data is a quickly becoming an impractical task. on a PCIE 3.0 link, reducing their data load and data move- Single-threaded performance has become saturated in the last ment capabilities, which is essential for high ingest streaming decade, and there is a growing need for custom solutions to workloads as well as SQL queries involving large to large keep pace with these workloads in a scalable and efficient joins. manner. We analyzed the performance of complex analytics queries A big portion of the power in analytics workloads involves on large data structures, and identified several key areas that bringing data to the processing cores, and we aim to optimize can improve efficiency. Firstly, most analytics queries needs that. We present the Database Processing Unit or DPU, a lots of joins and group-bys. Secondly, these queries need shared memory many-core that is specifically designed for to be broken down into simple streaming primitives, which in-memory analytics workloads. -

Unit – V– Sbs1203 – Computer Architecture
CENTROL PROCESSING UNIT SCHOOL OF COMPUTING DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT – V– SBS1203 – COMPUTER ARCHITECTURE 1 CENTROL PROCESSING UNIT 5.1.GENERAL PURPOSE REGISTERS 2 CENTROL PROCESSING UNIT The output of each register is connected to two multiplexers (MUX) to form the two buses A and B. The selection lines in each multiplexer select one register or the input data for the particular bus. The A and B buses form the inputs to a common arithmetic logic unit (ALU). The operation selected in the ALU determines the arithmetic or logic micro operation that is to be performed. The result of the micro operation is available for output data and also goes into the inputs of all the registers.The register that receives the information from the output bus is selected by a decoder. The decoder activates one of the register load inputs, thus providing a transfer path between the data in the output bus and the inputs of the selected destination register. 3 CENTROL PROCESSING UNIT The control unit that operates the CPU bus system directs the information flow through the registers and ALU by selecting the various components in the system. For example, to perform the operation R1<--R2 + R3 the control must provide binary selection variables to the following selector inputs: 1. MUX A selector (SELA): to place the content of R2 into bus A. 2. MUX B selector (SELB): to place the content of R3 into bus B. 3. ALU operation selector (OPR): to provide the arithmetic addition A+ B. 4. Decoder destination selector (SELD): to transfer the content of the output bus into R 1. -

In Storage Process, the Next Generation of Storage System
University of Rhode Island DigitalCommons@URI Open Access Dissertations 2019 In storage process, the next generation of storage system Dongyang Li University of Rhode Island, [email protected] Follow this and additional works at: https://digitalcommons.uri.edu/oa_diss Recommended Citation Li, Dongyang, "In storage process, the next generation of storage system" (2019). Open Access Dissertations. Paper 839. https://digitalcommons.uri.edu/oa_diss/839 This Dissertation is brought to you for free and open access by DigitalCommons@URI. It has been accepted for inclusion in Open Access Dissertations by an authorized administrator of DigitalCommons@URI. For more information, please contact [email protected]. PROCESSING IN STORAGE, THE NEXT GENERATION OF STORAGE SYSTEM BY DONGYANG LI A DISSERTATION SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN ELECTRICAL ENGINEERING UNIVERSITY OF RHODE ISLAND 2019 DOCTOR OF PHILOSOPHY DISSERTATION OF DONGYANG LI APPROVED: Dissertation Committee: Major Professor Qing Yang Jien-Chung Lo Lutz Hamel Manbir Sodhi Nasser H. Zawia DEAN OF THE GRADUATE SCHOOL UNIVERSITY OF RHODE ISLAND 2019 ABSTRACT In conventional computer systems, software relies on the CPU to handle the process applications and assign computation tasks to heterogeneous accelerators such as GPU, TPU and FPGA. It requires the CPU to fetch data out of the storage device and move the data to the heterogeneous accelerators. After the accelerators complete computation tasks, the results are flushed to the main memory of the host server for software applications. In this architecture, the heterogeneous accel- erators are located far away from the storage device. There are data movements on the system bus (NVM-express/PCI-express), which requires a lot of transmission time and bus bandwidth.