Network Measurement and Performance Analysis at Server Side
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Survey of Network Performance Monitoring Tools
A Survey of Network Performance Monitoring Tools Travis Keshav -- [email protected] Abstract In today's world of networks, it is not enough simply to have a network; assuring its optimal performance is key. This paper analyzes several facets of Network Performance Monitoring, evaluating several motivations as well as examining many commercial and public domain products. Keywords: network performance monitoring, application monitoring, flow monitoring, packet capture, sniffing, wireless networks, path analysis, bandwidth analysis, network monitoring platforms, Ethereal, Netflow, tcpdump, Wireshark, Ciscoworks Table Of Contents 1. Introduction 2. Application & Host-Based Monitoring 2.1 Basis of Application & Host-Based Monitoring 2.2 Public Domain Application & Host-Based Monitoring Tools 2.3 Commercial Application & Host-Based Monitoring Tools 3. Flow Monitoring 3.1 Basis of Flow Monitoring 3.2 Public Domain Flow Monitoring Tools 3.3 Commercial Flow Monitoring Protocols 4. Packet Capture/Sniffing 4.1 Basis of Packet Capture/Sniffing 4.2 Public Domain Packet Capture/Sniffing Tools 4.3 Commercial Packet Capture/Sniffing Tools 5. Path/Bandwidth Analysis 5.1 Basis of Path/Bandwidth Analysis 5.2 Public Domain Path/Bandwidth Analysis Tools 6. Wireless Network Monitoring 6.1 Basis of Wireless Network Monitoring 6.2 Public Domain Wireless Network Monitoring Tools 6.3 Commercial Wireless Network Monitoring Tools 7. Network Monitoring Platforms 7.1 Basis of Network Monitoring Platforms 7.2 Commercial Network Monitoring Platforms 8. Conclusion 9. References and Acronyms 1.0 Introduction http://www.cse.wustl.edu/~jain/cse567-06/ftp/net_perf_monitors/index.html 1 of 20 In today's world of networks, it is not enough simply to have a network; assuring its optimal performance is key. -

An Introduction
This chapter is from Social Media Mining: An Introduction. By Reza Zafarani, Mohammad Ali Abbasi, and Huan Liu. Cambridge University Press, 2014. Draft version: April 20, 2014. Complete Draft and Slides Available at: http://dmml.asu.edu/smm Chapter 10 Behavior Analytics What motivates individuals to join an online group? When individuals abandon social media sites, where do they migrate to? Can we predict box office revenues for movies from tweets posted by individuals? These questions are a few of many whose answers require us to analyze or predict behaviors on social media. Individuals exhibit different behaviors in social media: as individuals or as part of a broader collective behavior. When discussing individual be- havior, our focus is on one individual. Collective behavior emerges when a population of individuals behave in a similar way with or without coordi- nation or planning. In this chapter we provide examples of individual and collective be- haviors and elaborate techniques used to analyze, model, and predict these behaviors. 10.1 Individual Behavior We read online news; comment on posts, blogs, and videos; write reviews for products; post; like; share; tweet; rate; recommend; listen to music; and watch videos, among many other daily behaviors that we exhibit on social media. What are the types of individual behavior that leave a trace on social media? We can generally categorize individual online behavior into three cate- gories (shown in Figure 10.1): 319 Figure 10.1: Individual Behavior. 1. User-User Behavior. This is the behavior individuals exhibit with re- spect to other individuals. For instance, when befriending someone, sending a message to another individual, playing games, following, inviting, blocking, subscribing, or chatting, we are demonstrating a user-user behavior. -

Application Note Pre-Deployment and Network Readiness Assessment Is
Application Note Contents Title Six Steps To Getting Your Network Overview.......................................................... 1 Ready For Voice Over IP Pre-Deployment and Network Readiness Assessment Is Essential ..................... 1 Date January 2005 Types of VoIP Overview Performance Problems ...... ............................. 1 This Application Note provides enterprise network managers with a six step methodology, including pre- Six Steps To Getting deployment testing and network readiness assessment, Your Network Ready For VoIP ........................ 2 to follow when preparing their network for Voice over Deploy Network In Stages ................................. 7 IP service. Designed to help alleviate or significantly reduce call quality and network performance related Summary .......................................................... 7 problems, this document also includes useful problem descriptions and other information essential for successful VoIP deployment. Pre-Deployment and Network IP Telephony: IP Network Problems, Equipment Readiness Assessment Is Essential Configuration and Signaling Problems and Analog/ TDM Interface Problems. IP Telephony is very different from conventional data applications in that call quality IP Network Problems: is especially sensitive to IP network impairments. Existing network and “traditional” call quality Jitter -- Variation in packet transmission problems become much more obvious with time that leads to packets being the deployment of VoIP service. For network discarded in VoIP -
Three-Dimensional Integrated Circuit Design: EDA, Design And
Integrated Circuits and Systems Series Editor Anantha Chandrakasan, Massachusetts Institute of Technology Cambridge, Massachusetts For other titles published in this series, go to http://www.springer.com/series/7236 Yuan Xie · Jason Cong · Sachin Sapatnekar Editors Three-Dimensional Integrated Circuit Design EDA, Design and Microarchitectures 123 Editors Yuan Xie Jason Cong Department of Computer Science and Department of Computer Science Engineering University of California, Los Angeles Pennsylvania State University [email protected] [email protected] Sachin Sapatnekar Department of Electrical and Computer Engineering University of Minnesota [email protected] ISBN 978-1-4419-0783-7 e-ISBN 978-1-4419-0784-4 DOI 10.1007/978-1-4419-0784-4 Springer New York Dordrecht Heidelberg London Library of Congress Control Number: 2009939282 © Springer Science+Business Media, LLC 2010 All rights reserved. This work may not be translated or copied in whole or in part without the written permission of the publisher (Springer Science+Business Media, LLC, 233 Spring Street, New York, NY 10013, USA), except for brief excerpts in connection with reviews or scholarly analysis. Use in connection with any form of information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed is forbidden. The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identified as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights. Printed on acid-free paper Springer is part of Springer Science+Business Media (www.springer.com) Foreword We live in a time of great change. -

Learning to Predict End-To-End Network Performance
CORE Metadata, citation and similar papers at core.ac.uk Provided by BICTEL/e - ULg UNIVERSITÉ DE LIÈGE Faculté des Sciences Appliquées Institut d’Électricité Montefiore RUN - Research Unit in Networking Learning to Predict End-to-End Network Performance Yongjun Liao Thèse présentée en vue de l’obtention du titre de Docteur en Sciences de l’Ingénieur Année Académique 2012-2013 ii iii Abstract The knowledge of end-to-end network performance is essential to many Internet applications and systems including traffic engineering, content distribution networks, overlay routing, application- level multicast, and peer-to-peer applications. On the one hand, such knowledge allows service providers to adjust their services according to the dynamic network conditions. On the other hand, as many systems are flexible in choosing their communication paths and targets, knowing network performance enables to optimize services by e.g. intelligent path selection. In the networking field, end-to-end network performance refers to some property of a network path measured by various metrics such as round-trip time (RTT), available bandwidth (ABW) and packet loss rate (PLR). While much progress has been made in network measurement, a main challenge in the acquisition of network performance on large-scale networks is the quadratical growth of the measurement overheads with respect to the number of network nodes, which ren- ders the active probing of all paths infeasible. Thus, a natural idea is to measure a small set of paths and then predict the others where there are no direct measurements. This understanding has motivated numerous research on approaches to network performance prediction. -

Latency and Throughput Optimization in Modern Networks: a Comprehensive Survey Amir Mirzaeinnia, Mehdi Mirzaeinia, and Abdelmounaam Rezgui
READY TO SUBMIT TO IEEE COMMUNICATIONS SURVEYS & TUTORIALS JOURNAL 1 Latency and Throughput Optimization in Modern Networks: A Comprehensive Survey Amir Mirzaeinnia, Mehdi Mirzaeinia, and Abdelmounaam Rezgui Abstract—Modern applications are highly sensitive to com- On one hand every user likes to send and receive their munication delays and throughput. This paper surveys major data as quickly as possible. On the other hand the network attempts on reducing latency and increasing the throughput. infrastructure that connects users has limited capacities and These methods are surveyed on different networks and surrond- ings such as wired networks, wireless networks, application layer these are usually shared among users. There are some tech- transport control, Remote Direct Memory Access, and machine nologies that dedicate their resources to some users but they learning based transport control, are not very much commonly used. The reason is that although Index Terms—Rate and Congestion Control , Internet, Data dedicated resources are more secure they are more expensive Center, 5G, Cellular Networks, Remote Direct Memory Access, to implement. Sharing a physical channel among multiple Named Data Network, Machine Learning transmitters needs a technique to control their rate in proper time. The very first congestion network collapse was observed and reported by Van Jacobson in 1986. This caused about a I. INTRODUCTION thousand time rate reduction from 32kbps to 40bps [3] which Recent applications such as Virtual Reality (VR), au- is about a thousand times rate reduction. Since then very tonomous cars or aerial vehicles, and telehealth need high different variations of the Transport Control Protocol (TCP) throughput and low latency communication. -

Designing Vertical Bandwidth Reconfigurable 3D Nocs for Many
Designing Vertical Bandwidth Reconfigurable 3D NoCs for Many Core Systems Qiaosha Zou∗, Jia Zhany, Fen Gez, Matt Poremba∗, Yuan Xiey ∗ Computer Science and Engineering, The Pennsylvania State University, USA y Electrical and Computer Engineering, University of California, Santa Barbara, USA z Nanjing University of Aeronautics and Astronautics, China Email: ∗fqszou, [email protected], yfjzhan, [email protected], z [email protected] Abstract—As the number of processing elements increases in a single Routers chip, the interconnect backbone becomes more and more stressed when Core 1 Cache/ Cache/Memory serving frequent memory and cache accesses. Network-on-Chip (NoC) Memory has emerged as a potential solution to provide a flexible and scalable Core 0 interconnect in a planar platform. In the mean time, three-dimensional TSVs (3D) integration technology pushes circuit design beyond Moore’s law and provides short vertical connections between different layers. As a result, the innovative solution that combines 3D integrations and NoC designs can further enhance the system performance. However, due Core 0 Core 1 to the unpredictable workload characteristics, NoC may suffer from intermittent congestions and channel overflows, especially when the (a) (b) network bandwidth is limited by the area and energy budget. In this work, we explore the performance bottlenecks in 3D NoC, and then leverage Fig. 1. Overview of core-to-cache/memory 3D stacking. (a). Cores are redundant TSVs, which are conventionally used for fault tolerance only, allocated in all layers with part of cache/memory; (b). All cores are located as vertical links to provide additional channel bandwidth for instant in the same layers while cache/memory in others. -

Lab 6: Understanding Traditional TCP Congestion Control (HTCP, Cubic, Reno)
NETWORK TOOLS AND PROTOCOLS Lab 6: Understanding Traditional TCP Congestion Control (HTCP, Cubic, Reno) Document Version: 06-14-2019 Award 1829698 “CyberTraining CIP: Cyberinfrastructure Expertise on High-throughput Networks for Big Science Data Transfers” Lab 6: Understanding Traditional TCP Congestion Control Contents Overview ............................................................................................................................. 3 Objectives............................................................................................................................ 3 Lab settings ......................................................................................................................... 3 Lab roadmap ....................................................................................................................... 3 1 Introduction to TCP ..................................................................................................... 3 1.1 TCP review ............................................................................................................ 4 1.2 TCP throughput .................................................................................................... 4 1.3 TCP packet loss event ........................................................................................... 5 1.4 Impact of packet loss in high-latency networks ................................................... 6 2 Lab topology............................................................................................................... -

A Social Network Matrix for Implicit and Explicit Social Network Plates
A Social Network Matrix for Implicit and Explicit Social Network Plates Wei Zhou1;4, Wenjing Duan2, Selwyn Piramuthu3;4 1Information & Operations Management, ESCP Europe, Paris, France 2Information Systems and Technology Management, George Washington University, U.S.A. 3Information Systems and Operations Management, University of Florida, U.S.A. Gainesville, Florida 32611-7169, USA 4RFID European Lab, Paris, France. [email protected], [email protected], selwyn@ufl.edu Abstract A majority of social network research deals with explicitly formed social networks. Although only rarely acknowledged for its existence, we believe that implicit social networks play a significant role in the overall dynamics of social networks. We propose a framework to evalu- ate the dynamics and characteristics of a set of explicit and associated implicit social networks. Specifically, we propose a social network ma- trix to measure the implicit relationships among the entities in various social networks. We also derive several indicators to characterize the dynamics in online social networks. We proceed by incorporating im- plicit social networks in a traditional network flow context to evaluate key network performance indicators such as the lowest communication cost, maximum information flow, and the budgetary constraints. Keywords: Implicit Social Network, Online Social Network 1 1 Introduction In recent years, several online social network platforms have witnessed huge public attention from social and financial perspectives. However, there are different facets to this interest. Facebook, for example, has gained a large set of users but failed to excel on profitability. Online social networks can be broadly classified as explicit and implicit social networks. Explicit social networks (e.g., Facebook, LinkedIn, Twitter, and MySpace) are where the users define the network by explicitly connect- ing with other users, possibly, but not necessarily, based on shared interests. -

Adaptive Method for Packet Loss Types in Iot: an Naive Bayes Distinguisher
electronics Article Adaptive Method for Packet Loss Types in IoT: An Naive Bayes Distinguisher Yating Chen , Lingyun Lu *, Xiaohan Yu * and Xiang Li School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044, China; [email protected] (Y.C.); [email protected] (X.L.) * Correspondence: [email protected] (L.L.); [email protected] (X.Y.) Received: 31 December 2018; Accepted: 23 January 2019; Published: 28 January 2019 Abstract: With the rapid development of IoT (Internet of Things), massive data is delivered through trillions of interconnected smart devices. The heterogeneous networks trigger frequently the congestion and influence indirectly the application of IoT. The traditional TCP will highly possible to be reformed supporting the IoT. In this paper, we find the different characteristics of packet loss in hybrid wireless and wired channels, and develop a novel congestion control called NB-TCP (Naive Bayesian) in IoT. NB-TCP constructs a Naive Bayesian distinguisher model, which can capture the packet loss state and effectively classify the packet loss types from the wireless or the wired. More importantly, it cannot cause too much load on the network, but has fast classification speed, high accuracy and stability. Simulation results using NS2 show that NB-TCP achieves up to 0.95 classification accuracy and achieves good throughput, fairness and friendliness in the hybrid network. Keywords: Internet of Things; wired/wireless hybrid network; TCP; naive bayesian model 1. Introduction The Internet of Things (IoT) is a new network industry based on Internet, mobile communication networks and other technologies, which has wide applications in industrial production, intelligent transportation, environmental monitoring and smart homes. -

Social Network Analysis and Information Propagation: a Case Study Using Flickr and Youtube Networks
International Journal of Future Computer and Communication, Vol. 2, No. 3, June 2013 Social Network Analysis and Information Propagation: A Case Study Using Flickr and YouTube Networks Samir Akrouf, Laifa Meriem, Belayadi Yahia, and Mouhoub Nasser Eddine, Member, IACSIT 1 makes decisions based on what other people do because their Abstract—Social media and Social Network Analysis (SNA) decisions may reflect information that they have and he or acquired a huge popularity and represent one of the most she does not. This concept is called ″herding″ or ″information important social and computer science phenomena of recent cascades″. Therefore, analyzing the flow of information on years. One of the most studied problems in this research area is influence and information propagation. The aim of this paper is social media and predicting users’ influence in a network to analyze the information diffusion process and predict the became so important to make various kinds of advantages influence (represented by the rate of infected nodes at the end of and decisions. In [2]-[3], the marketing strategies were the diffusion process) of an initial set of nodes in two networks: enhanced with a word-of-mouth approach using probabilistic Flickr user’s contacts and YouTube videos users commenting models of interactions to choose the best viral marketing plan. these videos. These networks are dissimilar in their structure Some other researchers focused on information diffusion in (size, type, diameter, density, components), and the type of the relationships (explicit relationship represented by the contacts certain special cases. Given an example, the study of Sadikov links, and implicit relationship created by commenting on et.al [6], where they addressed the problem of missing data in videos), they are extracted using NodeXL tool. -
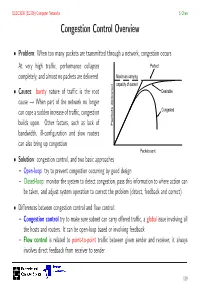
Congestion Control Overview
ELEC3030 (EL336) Computer Networks S Chen Congestion Control Overview • Problem: When too many packets are transmitted through a network, congestion occurs At very high traffic, performance collapses Perfect completely, and almost no packets are delivered Maximum carrying capacity of subnet • Causes: bursty nature of traffic is the root Desirable cause → When part of the network no longer can cope a sudden increase of traffic, congestion Congested builds upon. Other factors, such as lack of Packets delivered bandwidth, ill-configuration and slow routers can also bring up congestion Packets sent • Solution: congestion control, and two basic approaches – Open-loop: try to prevent congestion occurring by good design – Closed-loop: monitor the system to detect congestion, pass this information to where action can be taken, and adjust system operation to correct the problem (detect, feedback and correct) • Differences between congestion control and flow control: – Congestion control try to make sure subnet can carry offered traffic, a global issue involving all the hosts and routers. It can be open-loop based or involving feedback – Flow control is related to point-to-point traffic between given sender and receiver, it always involves direct feedback from receiver to sender 119 ELEC3030 (EL336) Computer Networks S Chen Open-Loop Congestion Control • Prevention: Different policies at various layers can affect congestion, and these are summarised in the table • e.g. retransmission policy at data link layer Transport Retransmission policy • Out-of-order caching