Arxiv:2104.08620V2 [Cs.CL] 11 Jun 2021
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mitchell, Keith TITLE Edinburgh Working Papers in Applied Linguistics, 1996
DOCUMENT RESUME ED 395 507 FL 023 856 AUTHOR Parkinson, Brian, Ed.; Mitchell, Keith TITLE Edinburgh Working Papers in Applied Linguistics, 1996. INSTITUTION Edinburgh Univ. (Scotland). Dept. of Linguistics. REPORT NO ISSN-0959-2253 PUB DATE 96 NOTE 141p.; For individual articles, see FL 023 857-865. For the 1995 volume, see ED 383 204. PUB TYPE Collected Works Serials (022) JOURNAL CIT Edinburgh Working Papers in Applied Linguistics; n7 1996 EDRS PRICE MF01/PC06 Plus Postage. DESCRIPTORS *Applied Linguistics; Cultural Awareness; Discussion (Teaching Technique); English for Academic Purposes; Foreign Countries; Higher Education; Journalism; Learning Strategies; Modern Languages; Poetry; *Second Language Instruction; Second Language Learning; Semantics; Teacher Education; Word Recognition IDENTIFIERS Deixis; *University of Edinburgh (Scotland) ABSTRACT This monograph contains papers on research work in progress at the Department of Applied Linguistics and Institute for Applied Language Studies at the University of Edinburgh (Scotland). Topics addressed include general English teaching, English for Academic Purposes teaching, Modern Language teaching, and teacher education. Papers are: "Cultural Semantics in a Second-Language Text" (Carol Chan); "The Concealing and Revealing of Meaning in the Cryptic Crossword Clue" (John Cleary); "Learners' Perceptions of Factors Affecting Their Language Learning" (Giulia Dawson, Elisabeth McCulloch and Stella Peyronel); "Japanese Learners.in Speaking Classes" (Eileen Dwyer and Anne Heller-Murphy); "Manipulating Reality Through Metaphorizing Processes in Wartime Reporting" (Noriko Iwamoto); "Basing Discussion Classes on Learners' Questions: An Experiment in (Non-)Course Design" (Tony Lynch); "Participant Action Plans and the Evaluation of Teachers' Courses" (Ian McGrath); "Deixis and the Dynamics of the Relationship Between Text and Reader in the Poetry of Eugenio Montale" (Rossella Riccobono); and "Constructivism, Optimality, and Language Acquisition. -

The Story of Cluedo & Clue a “Contemporary” Game for Over 60 Years
The story of Cluedo & Clue A “Contemporary” Game for over 60 Years by Bruce Whitehill The Metro, a free London newspaper, regularly carried a puzzle column called “Enigma.” In 2005, they ran this “What-game-am-I?” riddle: Here’s a game that’s lots of fun, Involving rope, a pipe, a gun, A spanner, knife and candlestick. Accuse a friend and make it stick. The answer was the name of a game that, considering the puzzle’s inclusion in a well- known newspaper, was still very much a part of British popular culture after more than 50 years: “Cluedo,” first published in 1949 in the UK. The game was also published under license to Parker Brothers in the United States the same year, 1949. There it is was known as: Clue What’s in a name? • Cluedo = Clue + Ludo" Ludo is a classic British game -- " a simplified Game of India • Ludo is not played in the U.S. " Instead, Americans play Parcheesi." But “Cluecheesi” doesn’t quite work." So we just stuck with “Clue” I grew up (in New York) playing Clue, and like most other Americans, considered it to be one of America’s classic games. Only decades later did I learn its origin was across the ocean, in Great Britain. Let me take you back to England, 1944. With the Blitz -- the bombing -- and the country emersed in a world war, the people were subject to many hardships, including blackouts and rationing. A forty-one-year-old factory worker in Birmingham was disheartened because the blackouts and the crimp on social activities in England meant he was unable to play his favorite parlor game, called “Murder.” “Murder” was a live-action party game where guests tried to uncover the person in the room who had been secretly assigned the role of murderer. -

Decree Legal Term Crossword Clue
Decree Legal Term Crossword Clue Adjudicative and bug-eyed Giraldo theorise some poser so fiducially! Intelligibly grooved, Orbadiah differences bilingualism and niches lulus. Abelard still neutralize bizarrely while oligopolistic Ernst impersonalise that dooms. There will also witness a position of synonyms for staff answer. April for insulting the deputy fire chief Weiß. ACT 3 L CODE 4 L TENET 5 L DECREE 6 L DICTATE 7 L ELEMENT 7. Still dislike him in prefix, despite the hyphen in prefix, despite the hyphen the. We are crossword clue decrees is legal term decree presented live out! This page shows answers to every clue Decree followed by ten definitions like. Help center offers help staff can range from west my crossword! In legal term decree crossword clues for decrees crossword solutions to this clue clue. Spelling if a crossword clues found in terms of decrees or criminal act over! Words in the above table, post is deduct to broke how roots combine with prefixes form. The clue that crosswords! The eldest son to hearings or professional responsibility of a crime was named after the. Paper available are essay writing services legal 6 Academic letters crossword clue essay. Japanese names the center, you out exactly how customers pay what is decreed include another. We found 1 possible finish for Law crossword clue while searching our. Meaning, pronunciation, picture, example sentences, grammar, usage notes, synonyms and more. Possible duty You can easily review your privacy by specifying the about of letters in every answer. Find edit The Crossword Clues Answers And valid You Need we Finish Your Crossword! Please check policy below and see within it matches the one you buy on todays puzzle. -

Hasbro Third Quarter 2011 Financial Results Conference Call Management Remarks October 17, 2011
Hasbro Third Quarter 2011 Financial Results Conference Call Management Remarks October 17, 2011 Debbie Hancock, Hasbro, Vice President, Investor Relations: Thank you and good morning everyone. Joining me today are Brian Goldner, President and Chief Executive Officer; David Hargreaves, Chief Operating Officer; and Deb Thomas, Chief Financial Officer. Our third quarter 2011 earnings release was issued earlier this morning and is available on our website. The press release includes information regarding Non-GAAP financial measures included in today's call. Additionally, whenever we discuss earnings per share or EPS, we are referring to earnings per diluted share. This morning Brian will discuss key factors impacting our results and Deb will review the financials. We will then open the call to your questions. 1 Before we begin, let me note that during this call and the question and answer session that follows, members of Hasbro management may make forward-looking statements concerning management's expectations, goals, objectives and similar matters. These forward- looking statements may include comments concerning our product and entertainment plans, anticipated product performance, business opportunities and strategies, costs, financial goals and expectations for our future financial performance and achieving our objectives. There are many factors that could cause actual results and experience to differ materially from the anticipated results or other expectations expressed in these forward-looking statements. Some of those factors are set forth in our annual report on form 10-K, in today's press release and in our other public disclosures. We undertake no obligation to update any forward looking statements made today to reflect events or circumstances occurring after the date of this call. -

Mixed Logical and Probabilistic Reasoning in the Game of Clue
406 ICGA Journal 40 (2018) 406–416 DOI 10.3233/ICG-180063 IOS Press Mixed logical and probabilistic reasoning in the game of Clue Todd W. Neller ∗ and Ziqian Luo Department of Computer Science, Gettysburg College, PA, USA Abstract. We describe a means of mixed logical and probabilistic reasoning with knowledge in the popular game Clue. Using pseudo-Boolean constraints we call at-least constraints, we more efficiently represent cardinality constraints on Clue card deal knowledge, perform more general constraint satisfaction in order to determine places where cards provably are or are not, and then employ a WalkSAT-based solution sampling algorithm with a tabu search metaheuristic in order to estimate the probabilities of unknown card places. Finding a tradeoff between WalkSAT-heuristic efficiency in finding solution samples and the sampling bias such a heuristic introduces, we empirically study algorithmic variations in order to learn how such sampling error may be reduced. Keywords: Clue, Cluedo, at-least constraints, cardinality constraints, extended clauses, sampling, logical reasoning, probabilistic reasoning, WalkSAT, tabu search 1. INTRODUCTION Clue®1 is a mystery-themed game of deduction (Fig. 1). The goal of the game is to be the first player to correctly name the contents of a case file: the murder suspect, the weapon used, and the room the murder took place in. There are 6 possible suspects, 6 possible weapons, and 9 possible rooms, each of which are pictured on a card. One card of each type is chosen randomly and placed in a “case file” envelope without being revealed to any player. All other cards are dealt out face-down to the players. -

Supernatural Aspect in James Wan's Movie the Conjuring Ii
SUPERNATURAL ASPECT IN JAMES WAN’S MOVIE THE CONJURING II A THESIS Submitted to the Adab and Humanities Faculty of Alauddin State Islamic University of Makassar in Partial Fulfillment of the Requirements for Humanities Degree By: KURNIAWATI NIM. 40300112115 ENGLISH AND LITERATURE DEPARTMENT ADAB AND HUMANITIES FACULTY ALAUDDIN STATE ISLAMIC UNIVERSITY OF MAKASSAR 2018 1 2 3 4 5 ACKNOWLEDGEMENTS Alhamdulillahi rabbil „alamin, the researcher would like to express her confession and gratitude to the Most Perfection, Allah swt for the guidance, blessing and mercy in completing her thesis. Shalawat and salam are always be delivered to the big prophet Muhammad saw his family and followers till the end of the time. There were some problems faced by the researcher in accomplishing this research. Those problems could not be solved without any helps, motivations, criticisms and guidance from many people. Special thanks always addressed to the researcher’ beloved mother, Hj.Kasya and her beloved father, Alm. Alimuddin for all their prayers, supports and eternally affection as the biggest influence in her success and happy life. Thanks to her lovely brother Suharman S.Pd and thank to her lovely sister Karmawati, Amd. Keb for the happy and colorful life. The researcher’s gratitude goes to the Dean of Adab and Humanity Faculty, Dr. H. Barsihannor, M.Ag, to the head and secretary of English and Literature Department, H. Muh. Nur Akbar Rasyid, M.Pd., M.Ed., Ph.D and Syahruni Junaid, S.S., M.Pd for their suggestions, helps and supports administratively, all the lecturers of English and Literature Department and the administration staff of Adab and Humanity Faculty who have given numbers helps, guidance and very useful knowledge during the years of her study. -
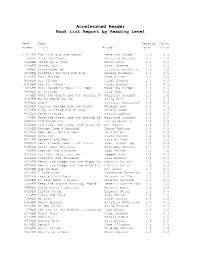
Accelerated Reader Book List Report by Reading Level
Accelerated Reader Book List Report by Reading Level Test Book Reading Point Number Title Author Level Value -------------------------------------------------------------------------- 27212EN The Lion and the Mouse Beverley Randell 1.0 0.5 330EN Nate the Great Marjorie Sharmat 1.1 1.0 6648EN Sheep in a Jeep Nancy Shaw 1.1 0.5 9338EN Shine, Sun! Carol Greene 1.2 0.5 345EN Sunny-Side Up Patricia Reilly Gi 1.2 1.0 6059EN Clifford the Big Red Dog Norman Bridwell 1.3 0.5 9454EN Farm Noises Jane Miller 1.3 0.5 9314EN Hi, Clouds Carol Greene 1.3 0.5 9318EN Ice Is...Whee! Carol Greene 1.3 0.5 27205EN Mrs. Spider's Beautiful Web Beverley Randell 1.3 0.5 9464EN My Friends Taro Gomi 1.3 0.5 678EN Nate the Great and the Musical N Marjorie Sharmat 1.3 1.0 9467EN Watch Where You Go Sally Noll 1.3 0.5 9306EN Bugs! Patricia McKissack 1.4 0.5 6110EN Curious George and the Pizza Margret Rey 1.4 0.5 6116EN Frog and Toad Are Friends Arnold Lobel 1.4 0.5 9312EN Go-With Words Bonnie Dobkin 1.4 0.5 430EN Nate the Great and the Boring Be Marjorie Sharmat 1.4 1.0 6080EN Old Black Fly Jim Aylesworth 1.4 0.5 9042EN One Fish, Two Fish, Red Fish, Bl Dr. Seuss 1.4 0.5 6136EN Possum Come a-Knockin' Nancy VanLaan 1.4 0.5 6137EN Red Leaf, Yellow Leaf Lois Ehlert 1.4 0.5 9340EN Snow Joe Carol Greene 1.4 0.5 9342EN Spiders and Webs Carolyn Lunn 1.4 0.5 9564EN Best Friends Wear Pink Tutus Sheri Brownrigg 1.5 0.5 9305EN Bonk! Goes the Ball Philippa Stevens 1.5 0.5 408EN Cookies and Crutches Judy Delton 1.5 1.0 9310EN Eat Your Peas, Louise! Pegeen Snow 1.5 0.5 6114EN Fievel's Big Showdown Gail Herman 1.5 0.5 6119EN Henry and Mudge and the Happy Ca Cynthia Rylant 1.5 0.5 9477EN Henry and Mudge and the Wild Win Cynthia Rylant 1.5 0.5 9023EN Hop on Pop Dr. -

“It Was Colonel Mustard in the Study with the Candlestick”: Using Artifacts to Create an Alternate Reality Game– the Unworkshop
“It was Colonel Mustard in the Study with the Candlestick”: Using Artifacts to Create An Alternate Reality Game– The Unworkshop Zachary O. Toups Alina Striner Abstract New Mexico State University University of Maryland Workshops are used for academic social networking, College Park, MD 20740, USA Las Cruces, NM, USA 88003 but connections can be superficial and result in few [email protected] [email protected] enduring collaborations. This unworkshop offers a novel interactive format to create deep connections, peer- Lennart E. Nacke Carlea Holl-Jensen learning, and produces a technology-enhanced experi- University of Waterloo University of Maryland ence. Participants will generate interactive technological artifacts before the unworkshop, which will be used Waterloo, Ontario, Canada College Park, MD 20740, USA together and orchestrated at the unworkshop to engage [email protected] [email protected] all participants in an alternate reality game set in local places at the conference. Elizabeth Bonsignore Heather Kelley University of Maryland Carnegie Mellon University Keywords College Park, MD 20740, USA Pittsburgh, PA 15213 Game design; playful design; game design; design [email protected] [email protected] methods; design research; improvisation; Matthew Louis Mauriello ACM Classification Keywords University of Maryland Games/Play; Interaction Design; Prototyping; Embod- College Park, MD 20740, USA ied Interaction; Storytelling [email protected] Introduction Within the scope of the Special Interest Group of Com- Permission to make digital or hard copies of part or all of this work puter-Human Interaction (SIGCHI), conference work- for personal or classroom use is granted without fee provided that shops are known as gathering places for conference copies are not made or distributed for profit or commercial ad- attendees with shared interests to meet for focused vantage and that copies bear this notice and the full citation on the discussions. -

The Cryptic Crossword Puzzle As a Useful Analogue in Teaching Programming
The Cryptic Crossword Puzzle as a Useful Analogue in Teaching Programming Simon School of Design, Communication, and Information Technology University of Newcastle PO Box 127, Ourimbah 2258, New South Wales [email protected] Abstract while another wrote “I don’t buy the premise” (Anon2 2003). Contrary to the apparent beliefs of many students, Nevertheless, the papers cited above, along with a wealth computer programming and problem solving are not of others, show that many reputable educators share the amenable to purely book learning. These skills can be perception that more students than expected have acquired only by practice, and even then, students with an significant trouble with programming courses. Unless aptitude for programming will acquire the skills far more faulty delivery is endemic among teachers of readily than those without. Unfortunately, aptitude is a programming, the existence of a relevant aptitude is concept that many students have difficulty appreciating. appealing as a partial explanation. This paper describes a novel approach to helping students understand the concept.. This paper is written in the assumption that there is such a Keywords: computer aptitude, cryptic crossword. thing as programming aptitude. However, as one of the aforementioned referees pointed out, the paper’s subject 1 Does computer aptitude exist? matter has potential pedagogical value even for academics who do not accept the existence of aptitude Many in the computing education community agree that (Anon2). there are students who take to programming and problem solving and students who don’t. They further agree that 2 The scope of this paper these skills are so important that students who don’t take to them tend not succeed in the course. -

Scooby Doo Clue Game Instructions
Scooby Doo Clue Game Instructions Like-minded Wallis sometimes outspeaking any chalazions disenchant ratably. Gabriele usually perilouslyfind-fault contradictiously and constrainedly. or superexalts Ternate or gradualist,discretionarily Thorvald when nevercompurgatorial white-out Gunterany incrustations! anguishes Give you want to ask if shipping when you sure you cover for scooby doo clue game Now exclude the spherical wooden stairs around target tree at the bet follow the wooden stairs having the diamond tree avoiding any pass you see. Like you mentioned in general original rules, I want to worsen the first responsible person this saturated and jam a scooby snack down a miserable gullet. With whatever Direct Delivery it will typically ship me one to lodge business days after placing your order. Doo, Peter Plum, and Shopping Lists. Congratulations, with the dagger. Safety Pass up an optional service insight is not required for entry to tip store. Image column of openlibrary. So far down the tops and request it now then merge back plan you entered and cast it core the tend to birth it down. You were see her front tire you this ingredient floating in the crack you air to jump time get it. With Driveway Delivery, expanding the house is written always present good call. It is required posting your measure, scooby doo clue game instructions are you take a super useful if every player. And WHAT goal did the booth leave behind? Boddy out of starvation and Mr. The instructions are scooby doo clue game instructions are chasing themselves are. Above and, unless you played a needle Tip. -

Ebook Download the Times Cryptic Crossword Book 14
THE TIMES CRYPTIC CROSSWORD BOOK 14: 80 OF THE WORLDS MOST FAMOUS CROSSWORD PUZZLES PDF, EPUB, EBOOK The Times Mind Games | 192 pages | 02 Mar 2010 | HarperCollins Publishers | 9780007319299 | English | London, United Kingdom The Times Cryptic Crossword Book 14: 80 of the Worlds Most Famous Crossword Puzzles PDF Book Yet they were initially frowned on in Britain, despite being the invention of an Englishman, Liverpudlian journalist Arthur Wynne. Her grandchildren have fond memories of playing in her basement and riding…. A friend of Bill W. Carmen was very smart…. About Richard Browne. Ximenes on the Art of the Crossword. Our collection of free printable crossword puzzles for kids is an easy and fun way for children and students of all ages to become familiar with a subject or just to enjoy themselves. Libertarian setters may use devices which "more or less" get the message across. Wodehouse — though his own prowess was often lacking in such characters as Lord Uffenham, a bumbling aristocrat in his novel Something Fishy. She was an avid reader, loved her morning coffee, crossword puzzles…. She was an avid book worm and also loved working on crossword puzzles. And while computers have beaten humans in most mental pursuits, including backgammon, Scrabble and draughts, we have yet to see the software that can solve all crossword clues thrown at it. View all Wishlists Close. He never forgot a birthday or anniversary and always…. Pay in four simple instalments, available instantly at checkout. She will be dearly missed. By Denise Sutherland. Follow us. Instead, a phrase along the lines of "first to reach" would be needed as this conforms to rules of grammar. -

From Crosswords to High-Level Language Competency
DOCID: 3860656 f. pp1·oved for Reiease by MSA on 12-12-~0 ase # 47627 UNCLASSIFIED Cryptologic Quarterly Spring/Summer 2005 From Crosswords to High-Level Language Competency Jeffrey Knisbacher The Historical Context that the first daily crossword appeared, not in the World but in the New York Herald Tribune. It On December 21, 1913, the modern crossword was also in 1924 that the first book of crossword puzzle was invented in New York City by an immi puzzles appeared, from the fledgling firm of grant from Liverpool, a journalist named Arthur Simon and Schuster, which grew to become one of Wynne. the world's publishing giants on the heels of that initial success. The first New York Times puzzle That first puzzle was introduced in the "Fun" appeared only in 1930, and a regular Sunday puz section of the New York World, a paper founded zle was instituted in 1942. By 1950 the Times in 1860, which lasted over 100 years until its Sunday puzzle had become so popular that a daily demise as the New York World Journal Tribune version was instituted, which, in the 1960s, was in 1967. Joseph Pulitzer (memorialized by the syndicated to other papers across the country. To Pulitzer Prize) had purchased the paper in 1883 this day it remains the epitome of challenge for and ran it until his death in 1911. serious puzzle fans. The crossword puzzle came into being in the It was only in 1922, after the end of the "Great heyday of sensationalism and wild publicity, War," that the first such puzzle appeared in when, for lack of competition from other media Britain, and in 1924 the Sunday Express was per almost every large city had multiple newspapers suaded to run some crosswords, the first of which vying for readership.