CUDA and Opencl
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Other Apis What’S Wrong with Openmp?
Threaded Programming Other APIs What’s wrong with OpenMP? • OpenMP is designed for programs where you want a fixed number of threads, and you always want the threads to be consuming CPU cycles. – cannot arbitrarily start/stop threads – cannot put threads to sleep and wake them up later • OpenMP is good for programs where each thread is doing (more-or-less) the same thing. • Although OpenMP supports C++, it’s not especially OO friendly – though it is gradually getting better. • OpenMP doesn’t support other popular base languages – e.g. Java, Python What’s wrong with OpenMP? (cont.) Can do this Can do this Can’t do this Threaded programming APIs • Essential features – a way to create threads – a way to wait for a thread to finish its work – a mechanism to support thread private data – some basic synchronisation methods – at least a mutex lock, or atomic operations • Optional features – support for tasks – more synchronisation methods – e.g. condition variables, barriers,... – higher levels of abstraction – e.g. parallel loops, reductions What are the alternatives? • POSIX threads • C++ threads • Intel TBB • Cilk • OpenCL • Java (not an exhaustive list!) POSIX threads • POSIX threads (or Pthreads) is a standard library for shared memory programming without directives. – Part of the ANSI/IEEE 1003.1 standard (1996) • Interface is a C library – no standard Fortran interface – can be used with C++, but not OO friendly • Widely available – even for Windows – typically installed as part of OS – code is pretty portable • Lots of low-level control over behaviour of threads • Lacks a proper memory consistency model Thread forking #include <pthread.h> int pthread_create( pthread_t *thread, const pthread_attr_t *attr, void*(*start_routine, void*), void *arg) • Creates a new thread: – first argument returns a pointer to a thread descriptor. -

Opencl on Shared Memory Multicore Cpus
OpenCL on shared memory multicore CPUs Akhtar Ali, Usman Dastgeer and Christoph Kessler Book Chapter N.B.: When citing this work, cite the original article. Part of: Proceedings of the 5th Workshop on MULTIPROG -2012. E. Ayguade, B. Gaster, L. Howes, P. Stenström, O. Unsal (eds), 2012. Copyright: HiPEAC Network of Excellence Available at: Linköping University Electronic Press http://urn.kb.se/resolve?urn=urn:nbn:se:liu:diva-93951 Published in: Proc. Fifth Workshop on Programmability Issues for Multi-Core Computers (MULTIPROG-2012) at HiPEAC-2012 conference, Paris, France, Jan. 2012. OpenCL for programming shared memory multicore CPUs Akhtar Ali, Usman Dastgeer, and Christoph Kessler PELAB, Dept. of Computer and Information Science, Linköping University, Sweden [email protected] {usman.dastgeer,christoph.kessler}@liu.se Abstract. Shared memory multicore processor technology is pervasive in mainstream computing. This new architecture challenges programmers to write code that scales over these many cores to exploit the full compu- tational power of these machines. OpenMP and Intel Threading Build- ing Blocks (TBB) are two of the popular frameworks used to program these architectures. Recently, OpenCL has been defined as a standard by Khronos group which focuses on programming a possibly heteroge- neous set of processors with many cores such as CPU cores, GPUs, DSP processors. In this work, we evaluate the effectiveness of OpenCL for programming multicore CPUs in a comparative case study with OpenMP and Intel TBB for five benchmark applications: matrix multiply, LU decomposi- tion, 2D image convolution, Pi value approximation and image histogram generation. The evaluation includes the effect of compiler optimizations for different frameworks, OpenCL performance on different vendors’ plat- forms and the performance gap between CPU-specific and GPU-specific OpenCL algorithms for execution on a modern GPU. -

Heterogeneous Task Scheduling for Accelerated Openmp
Heterogeneous Task Scheduling for Accelerated OpenMP ? ? Thomas R. W. Scogland Barry Rountree† Wu-chun Feng Bronis R. de Supinski† ? Department of Computer Science, Virginia Tech, Blacksburg, VA 24060 USA † Center for Applied Scientific Computing, Lawrence Livermore National Laboratory, Livermore, CA 94551 USA [email protected] [email protected] [email protected] [email protected] Abstract—Heterogeneous systems with CPUs and computa- currently requires a programmer either to program in at tional accelerators such as GPUs, FPGAs or the upcoming least two different parallel programming models, or to use Intel MIC are becoming mainstream. In these systems, peak one of the two that support both GPUs and CPUs. Multiple performance includes the performance of not just the CPUs but also all available accelerators. In spite of this fact, the models however require code replication, and maintaining majority of programming models for heterogeneous computing two completely distinct implementations of a computational focus on only one of these. With the development of Accelerated kernel is a difficult and error-prone proposition. That leaves OpenMP for GPUs, both from PGI and Cray, we have a clear us with using either OpenCL or accelerated OpenMP to path to extend traditional OpenMP applications incrementally complete the task. to use GPUs. The extensions are geared toward switching from CPU parallelism to GPU parallelism. However they OpenCL’s greatest strength lies in its broad hardware do not preserve the former while adding the latter. Thus support. In a way, though, that is also its greatest weak- computational potential is wasted since either the CPU cores ness. To enable one to program this disparate hardware or the GPU cores are left idle. -

AMD Accelerated Parallel Processing Opencl Programming Guide
AMD Accelerated Parallel Processing OpenCL Programming Guide November 2013 rev2.7 © 2013 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, AMD Accelerated Parallel Processing, the AMD Accelerated Parallel Processing logo, ATI, the ATI logo, Radeon, FireStream, FirePro, Catalyst, and combinations thereof are trade- marks of Advanced Micro Devices, Inc. Microsoft, Visual Studio, Windows, and Windows Vista are registered trademarks of Microsoft Corporation in the U.S. and/or other jurisdic- tions. Other names are for informational purposes only and may be trademarks of their respective owners. OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. The information contained herein may be of a preliminary or advance nature and is subject to change without notice. No license, whether express, implied, arising by estoppel or other- wise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as compo- nents in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other application in which the failure of AMD’s product could create a situation where personal injury, death, or severe property or envi- ronmental damage may occur. -

Energy-Efficient VLSI Architectures for Next
UNIVERSITY OF CALIFORNIA Los Angeles Energy-Efficient VLSI Architectures for Next- Generation Software-Defined and Cognitive Radios A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Electrical Engineering by Fang-Li Yuan 2014 c Copyright by Fang-Li Yuan 2014 ABSTRACT OF THE DISSERTATION Energy-Efficient VLSI Architectures for Next- Generation Software-Defined and Cognitive Radios by Fang-Li Yuan Doctor of Philosophy in Electrical Engineering University of California, Los Angeles, 2014 Professor Dejan Markovic,´ Chair Dedicated radio hardware is no longer promising as it was in the past. Today, the support of diverse standards dictates more flexible solutions. Software-defined radio (SDR) provides the flexibility by replacing dedicated blocks (i.e. ASICs) with more general processors to adapt to various functions, standards and even allow mutable de- sign changes. However, such replacement generally incurs significant efficiency loss in circuits, hindering its feasibility for energy-constrained devices. The capability of dy- namic and blind spectrum analysis, as featured in the cognitive radio (CR) technology, makes chip implementation even more challenging. This work discusses several design techniques to achieve near-ASIC energy effi- ciency while providing the flexibility required by software-defined and cognitive radios. The algorithm-architecture co-design is used to determine domain-specific dataflow ii structures to achieve the right balance between energy efficiency and flexibility. The flexible instruction-set-architecture (ISA), the multi-scale interconnects, and the multi- core dynamic scheduling are also proposed to reduce the energy overhead. We demon- strate these concepts on two real-time blind classification chips for CR spectrum anal- ysis, as well as a 16-core processor for baseband SDR signal processing. -

Implementing FPGA Design with the Opencl Standard
Implementing FPGA Design with the OpenCL Standard WP-01173-3.0 White Paper Utilizing the Khronos Group’s OpenCL™ standard on an FPGA may offer significantly higher performance and at much lower power than is available today from hardware architectures such as CPUs, graphics processing units (GPUs), and digital signal processing (DSP) units. In addition, an FPGA-based heterogeneous system (CPU + FPGA) using the OpenCL standard has a significant time-to-market advantage compared to traditional FPGA development using lower level hardware description languages (HDLs) such as Verilog or VHDL. 1 OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos. Introduction The initial era of programmable technologies contained two different extremes of programmability. As illustrated in Figure 1, one extreme was represented by single core CPU and digital signal processing (DSP) units. These devices were programmable using software consisting of a list of instructions to be executed. These instructions were created in a manner that was conceptually sequential to the programmer, although an advanced processor could reorder instructions to extract instruction-level parallelism from these sequential programs at run time. In contrast, the other extreme of programmable technology was represented by the FPGA. These devices are programmed by creating configurable hardware circuits, which execute completely in parallel. A designer using an FPGA is essentially creating a massively- fine-grained parallel application. For many years, these extremes coexisted with each type of programmability being applied to different application domains. However, recent trends in technology scaling have favored technologies that are both programmable and parallel. Figure 1. -

Programming Graphics Hardware Overview of the Tutorial: Afternoon
Tutorial 5 ProgrammingProgramming GraphicsGraphics HardwareHardware Randy Fernando, Mark Harris, Matthias Wloka, Cyril Zeller Overview of the Tutorial: Morning 8:30 Introduction to the Hardware Graphics Pipeline Cyril Zeller 9:30 Controlling the GPU from the CPU: the 3D API Cyril Zeller 10:15 Break 10:45 Programming the GPU: High-level Shading Languages Randy Fernando 12:00 Lunch Tutorial 5: Programming Graphics Hardware Overview of the Tutorial: Afternoon 12:00 Lunch 14:00 Optimizing the Graphics Pipeline Matthias Wloka 14:45 Advanced Rendering Techniques Matthias Wloka 15:45 Break 16:15 General-Purpose Computation Using Graphics Hardware Mark Harris 17:30 End Tutorial 5: Programming Graphics Hardware Tutorial 5: Programming Graphics Hardware IntroductionIntroduction toto thethe HardwareHardware GraphicsGraphics PipelinePipeline Cyril Zeller Overview Concepts: Real-time rendering Hardware graphics pipeline Evolution of the PC hardware graphics pipeline: 1995-1998: Texture mapping and z-buffer 1998: Multitexturing 1999-2000: Transform and lighting 2001: Programmable vertex shader 2002-2003: Programmable pixel shader 2004: Shader model 3.0 and 64-bit color support PC graphics software architecture Performance numbers Tutorial 5: Programming Graphics Hardware Real-Time Rendering Graphics hardware enables real-time rendering Real-time means display rate at more than 10 images per second 3D Scene = Image = Collection of Array of pixels 3D primitives (triangles, lines, points) Tutorial 5: Programming Graphics Hardware Hardware Graphics Pipeline -

GPU-Based Deep Learning Inference
Whitepaper GPU-Based Deep Learning Inference: A Performance and Power Analysis November 2015 1 Contents Abstract ......................................................................................................................................................... 3 Introduction .................................................................................................................................................. 3 Inference versus Training .............................................................................................................................. 4 GPUs Excel at Neural Network Inference ..................................................................................................... 5 Inference Optimizations in Caffe and cuDNN 4 ........................................................................................ 5 Experimental Setup and Testing Methodology ........................................................................................ 7 Inference on Small and Large GPUs .......................................................................................................... 8 Conclusion ................................................................................................................................................... 10 References .................................................................................................................................................. 10 2 Abstract Deep learning methods are revolutionizing various areas of machine perception. On a -
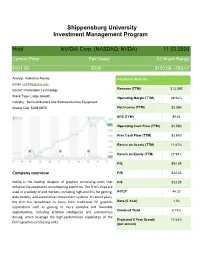
Shippensburg University Investment Management Program
Shippensburg University Investment Management Program Hold NVIDIA Corp. (NASDAQ: NVDA) 11.03.2020 Current Price Fair Value 52 Week Range $501.36 $300 $180.68 - 589.07 Analyst: Valentina Alonso Key Stock Statistics Email: [email protected] Sector: Information Technology Revenue (TTM) $13.06B Stock Type: Large Growth Operating Margin (TTM) 28.56% Industry: Semiconductors and Semiconductors Equipment Market Cap: $309.697B Net Income (TTM) $3.39B EPS (TTM) $5.44 Operating Cash Flow (TTM) $5.58B Free Cash Flow (TTM) $3.67B Return on Assets (TTM) 11.67% Return on Equity (TTM) 27.94% P/E $92.59 Company overview P/B $22.32 Nvidia is the leading designer of graphics processing units that P/S $23.29 enhance the experience on computing platforms. The firm's chips are used in a variety of end markets, including high-end PCs for gaming, P/FCF 44.22 data centers, and automotive infotainment systems. In recent years, the firm has broadened its focus from traditional PC graphics Beta (5-Year) 1.54 applications such as gaming to more complex and favorable Dividend Yield 0.13% opportunities, including artificial intelligence and autonomous driving, which leverage the high-performance capabilities of the Projected 5 Year Growth 17.44% firm's graphics processing units. (per annum) Contents Executive Summary ....................................................................................................................................................3 Company Overview ....................................................................................................................................................4 -

Numerical Behavior of NVIDIA Tensor Cores
Numerical behavior of NVIDIA tensor cores Massimiliano Fasi1, Nicholas J. Higham2, Mantas Mikaitis2 and Srikara Pranesh2 1 School of Science and Technology, Örebro University, Örebro, Sweden 2 Department of Mathematics, University of Manchester, Manchester, UK ABSTRACT We explore the floating-point arithmetic implemented in the NVIDIA tensor cores, which are hardware accelerators for mixed-precision matrix multiplication available on the Volta, Turing, and Ampere microarchitectures. Using Volta V100, Turing T4, and Ampere A100 graphics cards, we determine what precision is used for the intermediate results, whether subnormal numbers are supported, what rounding mode is used, in which order the operations underlying the matrix multiplication are performed, and whether partial sums are normalized. These aspects are not documented by NVIDIA, and we gain insight by running carefully designed numerical experiments on these hardware units. Knowing the answers to these questions is important if one wishes to: (1) accurately simulate NVIDIA tensor cores on conventional hardware; (2) understand the differences between results produced by code that utilizes tensor cores and code that uses only IEEE 754-compliant arithmetic operations; and (3) build custom hardware whose behavior matches that of NVIDIA tensor cores. As part of this work we provide a test suite that can be easily adapted to test newer versions of the NVIDIA tensorcoresaswellassimilaracceleratorsfromothervendors,astheybecome available. Moreover, we identify a non-monotonicity issue -

Manycore GPU Architectures and Programming, Part 1
Lecture 19: Manycore GPU Architectures and Programming, Part 1 Concurrent and Mul=core Programming CSE 436/536, [email protected] www.secs.oakland.edu/~yan 1 Topics (Part 2) • Parallel architectures and hardware – Parallel computer architectures – Memory hierarchy and cache coherency • Manycore GPU architectures and programming – GPUs architectures – CUDA programming – Introduc?on to offloading model in OpenMP and OpenACC • Programming on large scale systems (Chapter 6) – MPI (point to point and collec=ves) – Introduc?on to PGAS languages, UPC and Chapel • Parallel algorithms (Chapter 8,9 &10) – Dense matrix, and sorng 2 Manycore GPU Architectures and Programming: Outline • Introduc?on – GPU architectures, GPGPUs, and CUDA • GPU Execuon model • CUDA Programming model • Working with Memory in CUDA – Global memory, shared and constant memory • Streams and concurrency • CUDA instruc?on intrinsic and library • Performance, profiling, debugging, and error handling • Direc?ve-based high-level programming model – OpenACC and OpenMP 3 Computer Graphics GPU: Graphics Processing Unit 4 Graphics Processing Unit (GPU) Image: h[p://www.ntu.edu.sg/home/ehchua/programming/opengl/CG_BasicsTheory.html 5 Graphics Processing Unit (GPU) • Enriching user visual experience • Delivering energy-efficient compung • Unlocking poten?als of complex apps • Enabling Deeper scien?fic discovery 6 What is GPU Today? • It is a processor op?mized for 2D/3D graphics, video, visual compu?ng, and display. • It is highly parallel, highly multhreaded mulprocessor op?mized for visual -

Compressed Modes User's Guide
Drivers for Windows Compressed Modes User’s Guide Version 2.0 NVIDIA Corporation August 27, 2002 NVIDIA Drivers Compressed Modes User’s Guide Version 2.0 Published by NVIDIA Corporation 2701 San Tomas Expressway Santa Clara, CA 95050 Copyright © 2002 NVIDIA Corporation. All rights reserved. This software may not, in whole or in part, be copied through any means, mechanical, electromechanical, or otherwise, without the express permission of NVIDIA Corporation. Information furnished is believed to be accurate and reliable. However, NVIDIA assumes no responsibility for the consequences of use of such information nor for any infringement of patents or other rights of third parties, which may result from its use. No License is granted by implication or otherwise under any patent or patent rights of NVIDIA Corporation. Specifications mentioned in the software are subject to change without notice. NVIDIA Corporation products are not authorized for use as critical components in life support devices or systems without express written approval of NVIDIA Corporation. NVIDIA, the NVIDIA logo, GeForce, GeForce2 Ultra, GeForce2 MX, GeForce2 GTS, GeForce 256, GeForce3, Quadro2, NVIDIA Quadro2, Quadro2 Pro, Quadro2 MXR, Quadro, NVIDIA Quadro, Vanta, NVIDIA Vanta, TNT2, NVIDIA TNT2, TNT, NVIDIA TNT, RIVA, NVIDIA RIVA, NVIDIA RIVA 128ZX, and NVIDIA RIVA 128 are registered trademarks or trademarks of NVIDIA Corporation in the United States and/or other countries. Intel and Pentium are registered trademarks of Intel. Microsoft, Windows, Windows NT, Direct3D, DirectDraw, and DirectX are registered trademarks of Microsoft Corporation. CDRS is a trademark and Pro/ENGINEER is a registered trademark of Parametric Technology Corporation. OpenGL is a registered trademark of Silicon Graphics Inc.