Are Developers Fixing Their Own Bugs? Tracing Bug-Fixing and Bug-Seeding Committers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mozbackup 1.4.8) - Add: FS#152 - New Graphic for Mozbackup 1.4.8 - Fix: FS#143 - ZIP Version Should Contains Directory
Changelog (since MozBackup 1.4) ------------------------------- (MozBackup 1.4.8) - Add: FS#152 - New graphic for MozBackup 1.4.8 - Fix: FS#143 - ZIP version should contains directory (MozBackup 1.4.8 Beta) - Fix: FS#120 - Check Czech localization - Fix: FS#123 - language file hasn't applied correctry - Fix: FS#141 - Spelling error on component selection screen. (MozBackup 1.4.8 Alpha) - Add: FS#1 - Backup file urlbarhistory.sqlite from SeaMonkey 2.0 profile - Add: FS#6 - Add support for Netscape 9 - Add: FS#7 - Add support for logging - Add: FS#8 - Add support for SeaMonkey 2.0 - Add: FS#9 - Add support for Flock - Add: FS#10 - Add support for Sunbird - Add: FS#11 - Migrate to Nullsoft installer - Add: FS#13 - Add support for Firefox/Thunderbird portable - Add: FS#16 - Add option for disable password question dialog - Add: FS#22 - Option to save unsupported files from profile - Add: FS#18 - Enable extensions backup by default - Add: FS#38 - Add test if backup's file is ok after backup - Add: FS#39 - Rename Backup.exe to MozBackup.exe - Add: FS#45 - Backup file urlclassifier3.sqlite from profile - Add: FS#48 - backup.ini / fileformat: Add "Day of Week" (Monday, ...) - Add: FS#67 - Support for Netscape Messenger 9.0 - Add: FS#69 - Add license information to all source files - Add: FS#70 - Create profile for MozBackup - Add: FS#73 - Create documentation for compilation of MozBackup - Add: FS#75 - Add new bookmarks* files to backup process - Add: FS#77 - Backup new signons3.txt file. - Add: FS#81 - Backup file cert_override.txt - Add: FS#82 -

Oracle® Beehive Oracle Beehive Standards-Based Clients Help Release 2 (2.0)
Oracle® Beehive Oracle Beehive Standards-Based Clients Help Release 2 (2.0) November 2011 Last updated on November 4, 2011 This page contains configuration instructions and other related information for the following standards-based clients supported by Oracle Beehive: Hardware and Software Certification Managing your E-Mails ■ Apple Mail ■ Microsoft Outlook ■ Mozilla Thunderbird Managing Calendar and Task List ■ Apple iCal ■ Mozilla Lightning Using Instant Messaging ■ Apple iChat ■ Pidgin ■ Trillian Pro Accessing Documents (Web Clients and FTP Clients) ■ Browser-based Access ■ Desktop WebDAV Clients ■ Mac OS X Finder Web Access ■ Cadaver ■ Microsoft Windows Web Folders ■ Desktop FTP Clients ■ FileZilla ■ NCFTP ■ SmartFTP ■ Transmit RSS Clients Mobile Access Documentation Accessibility 1 Hardware and Software Certification The hardware and software requirements included in this installation guide were current at the time this guide was published. However, because new platforms and operating system software versions might be certified after this guide is published, review the certification matrix on the My Oracle Support Web site for the most up-to-date list of certified hardware platforms and operating system versions. My Oracle Support is available at the following URL: http://support.oracle.com/ You must register online before using My Oracle Support. Use the following steps to locate the certification information for your platform: 1. After logging in, click the Certifications tab. 2. In the Certification Search pane, on the Search tab, select the following information: ■ Product: Enter the product name or select from the drop-down list of Products. ■ Release: Select the release number of the product. ■ Platform: Select the target platform by choosing from the submenu list. -

Printshop Mail Connect Installation and Activation Guide
Installation and Activation Guide Version: 2018.1 Installation and Activation Guide Version 2018.1 Last Revision: 2019-12-20 Objectif Lune, Inc. 2030 Pie-IX, Suite 500 Montréal, QC, Canada, H1V 2C8 +1 (514) 875-5863 www.objectiflune.com All trademarks displayed are the property of their respective owners. © Objectif Lune, Inc. 1994-2019. All rights reserved. No part of this documentation may be reproduced, transmitted or distributed outside of Objectif Lune Inc. by any means whatsoever without the express written permission of Objectif Lune Inc. Objectif Lune Inc. disclaims responsibility for any errors and omissions in this documentation and accepts no responsibility for damages arising from such inconsistencies or their further consequences of any kind. Objectif Lune Inc. reserves the right to alter the information contained in this documentation without notice. Table of Contents Table of Contents 4 System and Hardware Considerations 7 Antivirus Exclusions 7 Directories and folders 7 Database Considerations 9 Using the MySQL Instance from the Installer 9 Installing / Updating Connect Using an existing local MySQL instance 10 Installing Connect using an existing Microsoft SQL Server instance 11 Updating With No Local MySQL Product 12 When modifying Connect 12 Important 13 Environment considerations 14 Terminal Server/Service Support 14 Virtual Machine Support 14 Remote Desktop Support 15 32-bit or 64-bit Operating Systems? 15 Antivirus Considerations 15 Windows Search Indexing Service 16 Commandline switches and .ini entries 16 Language -
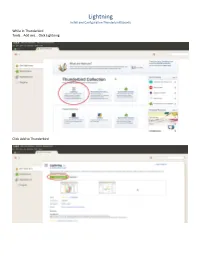
Lightning Install and Configuration Thunderbird/Ubuntu
Lightning Install and Configuration Thunderbird/Ubuntu While in Thunderbird Tools… Add ons… Click Lightning Click Add to Thunderbird Click Install Restart Now Download and Install DAVMail Go to http://sourceforge.net/projects/davmail/ Click to install Click Ok Click install package You may need to provide admin credentials Then click Close Create an Exchange calendar in Thunderbird Click File… hover over New… then click Calendar Then choose On the Network then Next Choose CalDav Enter http://localhost:1080/users/[email protected]/calendar Replace [email protected] with your email address. Then click Next Enter Exchange in the name field and click Next Click Finish Click the Calendar Tab Click Applications… hover over Internet then click DavMail You will see DavMail icon in top systray. Right click it and then click settings to configure Enter the settings circled Click Synchronize Enter username and password It may take a minute but you should start seeing existing appointments on your calendar. Lightning Notes… Many or all events are not showing up in one or multiple views If your events disappear during normal use with the calendar, close Thunderbird completely and reopen it. No events are lost or deleted with this bug--it's only an issue with the view. Other views (Day, Week, Multiweek, or Month) will often continue to work while one view is completely blank. Completely closing and reopening Thunderbird is the only reliable fix. Make sure you are running the latest versions of Thunderbird and Lightning. Do not use the Cache option in Lightning Choosing the Cache option with an account can cause the entire Thunderbird client to freeze completely for long periods of times while the cache file is being built and compared to the server. -

Flying Pigs QRP Club Bacon Bits Quarterly
Flying Pigs QRP Club Bacon Bits Quarterly Flying Pigs QRP Club International, W8PIG 1900 Pittsfield St, Kettering, Ohio 45420 E-mail: [email protected] Web Page: http://www.fpqrp.com FPQRP membership is open to all licensed QRP operators who reside within 12,000 nautical miles of Cincinnati, Ohio. The View from the Slop By Rob, W0JRM FP#-330 Greetings, salutations, and whatnot all you fine swine. Welcome to the September 2007 issue of Bacon Bits Quarterly. I'd like to thank everyone who contributed to our June 2007 issue, which by all comments was a great success! I'll start by issuing a congratulations to our own Anthony Luscre, K8ZT FP#- 254 on his new role as “What's New” editor for CQ Magazine. Make us proud! Or better yet... don't. This issue, we'll recap the Field Day efforts from around the pigs. We have a story about a man who was Ed Hare for a day, as told by the man who wore the crown and carried the scepter. We now have our own IRC channel, and we're going to tell you how to use it. We also have the final installment of “Hamming in the Hills and Hollows”. I'd like to use my editorial space this quarter to encourage everyone to participate in the weekly nets. As of this writing, they've again returned to a hiatus after being active for a few weeks. Is it the time of the net that dissuades us from checking in? Is it the day of the week? Is it just too hard for us to hear each other? We're a radio club, folks. -

Eddies Reflections on Fisheries Conservation Departments Headwaters 3 American Fishes 10 Watermarks 4 Meanders 30 Eddies Pioneers 8 Vol
U.S. Fish and Wildlife Service Summer/Fall 2010 Eddies Reflections on Fisheries Conservation Departments Headwaters 3 American Fishes 10 Watermarks 4 Meanders 30 Eddies Pioneers 8 Vol. 3, No. 2 Publisher Features Bryan Arroyo, Assistant Director Invasive Species in our “Rock Snot” Poses U.S. Fish and Wildlife Service Fisheries and Habitat Conservation Waters–12 Problems for Fisheries Susan Jewell Conservation–22 Executive Editor John Bryan Stuart Leon, Ph.D. Deputy Editor Giant Salvinia–16 Conservation in a Richard Christian Bob Pitman Quagga-mire–26 David Britton, Ph.D. Editor Craig Springer Associate Editor Kenai’s Most Lauren Merriam Unwanted–20 Contributing writers Jeffry Anderson Jeffry Anderson Ken Peters David Britton, Ph.D. Bob Pitman John Bryan Randi Sue Smith Ricky Campbell Joe Starinchak Jason Goldberg Aaron Woldt Susan Jewell Bradley A. Young. Ph.D. Thomas McCoy Editorial Advisors Mark Brouder, U.S. Fish and Wildlife Service Ryck Lydecker, Boat Owners Association of the United States Mark Maskill, U.S. Fish and Wildlife Service Hal Schramm, Ph.D., U.S. Geological Survey Michael Smith, U.S. Fish and Wildlife Service (retired) Denise Wagner, U.S. Fish and Wildflife Service Assistant Regional Directors – Fisheries Julie Collins (Acting), Pacific Region Robert Clarke (Acting), Pacific Southwest Region Jaime Geiger, Ph.D., Northeast Region Linda Kelsey, Southeast Region Mike Oetker, Southwest Region Steve Klosiewski (Acting), Alaska Region Service Sharon Rose (Acting), Mountain–Prairie Region Mike Weimer, Midwest Region Park Contact For subscriptions, visit National www.fws.gov/eddies, email [email protected] Pythons have invaded the Florida Everglades. Read about call 505 248-6867, or write to: one man’s snake experience, returning home to Florida in Craig Springer this issue’s Meanders, page 30. -

Here.Is.Only.Xul
Who am I? Alex Olszewski Elucidar Software Co-founder Lead Developer What this presentation is about? I was personally assigned to see how XUL and the Mozilla way measured up to RIA application development standards. This presentation will share my journey and ideas and hopefully open your minds to using these concepts for application development. RIA and what it means Different to many “Web Applications” that have features and functions of “Desktop” applications Easy install (generally requires only application install) or one-time extra(plug in) Updates automatically through network connections Keeps UI state on desktop and application state on server Runs in a browser or known “Sandbox” environment but has ability to access native OS calls to mimic desktop applications Designers can use asynchronous communication to make applications more responsive RIA and what it means(continued) Success of RIA application will ultimately be measured by how will it can match user’s needs, their way of thinking, and their behaviour. To review RIA applications take advantage of the “best” of both web and desktop apps. Sources: http://www.keynote.com/docs/whitepapers/RichInternet_5.pdf http://en.wikipedia.org/wiki/Rich_Internet_application My First Steps • Find working examples Known Mozilla Applications Firefox Thunderbird Standalone Applications Songbird Joost Komodo FindthatFont Prism (formerly webrunner) http://labs.mozilla.com/featured- projects/#prism XulMine-demo app http://benjamin.smedbergs.us/XULRunner/ Mozilla -

Fortimail Calendar Sharing in Thunderbird (5.2)
FortiMail Calendar Sharing in Thunderbird (5.2) FortiMail supports calendar sharing over a variety of mail clients, making it easier for you to schedule meetings and organize your daily routine. This recipe overviews calendar sharing for Mozilla Thunderbird. It provides detailed instructions on how to configure FortiMail to enable sharing, how to set-up Thunderbird to publish your calendar, how to set-up your Free/Busy settings and how to subscribe to other people’s calendars. Users can skip the initial steps and go to the Publishing Your Calendar section. Note: Two add-ons for Thunderbird are required for these steps to work: Lightning and Free/Busy. Configuring FortMail and Webmail for Sharing Before publishing your calendar in Thunderbird, configure FortiMail to enable calendar sharing and then create a calendar resource for sharing: 1. Select Mail Settings from the FortiMail menu bar and select Calendar. 2. In the Settings tab, you’ll see two checkboxes. Select and enable both WebDav and CalDav. 3. Select the Resources tab and select New. 4. Enter the required information. 5. N ow that FortiMail is properly configured for sharing, you need to acquire some important information before you can begin publishing your calendar. Open your FortiMail webmail account. 6. Select the Preferences button. 7. Under the service URL header, click on the CalDAV URL and the WebDAV URL and copy both URLs to notepad. Both URLs are required for future procedures. Publishing Your Calendar Thunderbird users can publish their calendar and subscribe to other people’s calendars from the FortiMail WebDAV server. 1. Select the Events and Tasks menu in the menu bar and select Calendar. -

LTS2005® Lightning Tracking Software USER's GUIDE
LTS2005® Lightning Tracking Software USER’S GUIDE Version 4.0 May 2011 M210672EN-D PUBLISHED BY Vaisala Oyj Tel. +358 9 8949 1 P.O. Box 26 Fax +358 9 8949 2227 FIN-00421 Helsinki Finland Visit our Internet pages at http://www.vaisala.com/ FOR TECHNICAL INFORMATION Vaisala Inc. Tel. +011 520 294 2145 Tucson Operations Fax: +011 520 741 2848 2705 E. Medina Rd. Toll free (US) 1 800 221 9779 Tucson, AZ 85756 USA © Vaisala 2011 No part of this manual may be reproduced in any form or by any means, electronic or mechanical (including photocopying), nor may its contents be communicated to a third party without prior written permission of the copyright holder. The contents are subject to change without prior notice. Please observe that this manual does not create any legally binding obligations for Vaisala towards the customer or end user. All legally binding commitments and agreements are included exclusively in the applicable supply contract or Conditions of Sale. ________________________________________________________________________________ Table of Contents Chapter 1 GENERAL INFORMATION............................................................................1 About This Manual...................................................................1 Contents of This Manual .......................................................1 Document Conventions...........................................................3 Safety ........................................................................................3 General Safety Considerations .............................................3 -

Outlook Integration Implementation Guide
Outlook Integration Implementation Guide Salesforce, Winter ’22 @salesforcedocs Last updated: August 30, 2021 © Copyright 2000–2021 salesforce.com, inc. All rights reserved. Salesforce is a registered trademark of salesforce.com, inc., as are other names and marks. Other marks appearing herein may be trademarks of their respective owners. CONTENTS Outlook Integration . 1 Outlook Integration System Requirements . 2 Set Up the Integration with Outlook . 4 Guidelines for Setting Up the Outlook Integration . 5 Microsoft Exchange Server Setup for the Outlook Integration . 7 Turn On the Outlook Integration in Salesforce . 8 Deploy the Outlook Integration to Users . 9 Enable Event Type Selections to Log Events from Outlook or Gmail . 10 Enhanced Email and the Outlook Integration . 11 Add Salesforce Inbox Features to the Outlook Integration . 12 OUTLOOK INTEGRATION The Salesforce integration with Outlook is one of a suite of products that give sales reps the power to work from their email applications, while keeping Salesforce data up to date. The integration provides Salesforce data directly within Outlook, and the ability to log emails and events to Salesforce records. Add Einstein Activity Capture to automate email and event logging and to sync contacts and calendar events between Salesforce and Outlook. To learn more about other products available, see Salesforce Help. For security considerations for the Outlook integration, see Salesforce Email Integration Security Guide. For security considerations for Einstein Activity Capture, see the Einstein Activity Capture Security Guide. This guide discusses the Exchange server settings, Salesforce setup, and a short client-side procedure required to set up the integration. The initial setup requires a Salesforce administrator, the IT pro who maintains your Microsoft Exchange server, and the sales reps running the integration in Outlook. -

Mozilla and Software Freedom Dwaraka Nath Arun Prakash Harvish Sekar
Mozilla And Software Freedom Dwaraka Nath Arun Prakash Harvish Sekar 17th September 2011, SFD Chennai. About Mozilla •Mozilla is a global community of volunteers, contributors and like – minded people who work towards the same goal Openness, Innovation and Opportunity of the Web and associated Software •Formed on 23rd February of 1998 by Netscape Communications as Mozilla Organization •Mozilla Foundation launched on July 15, 2003. What We Do •We are a non – profit organization who see success with People than with Share and Stake holders. •We try to achieve our goal by building and promoting software like Firefox and movements like Drumbeat •We want to see the Power and potential of Internet and want to see it thrive for everyone, everywhere. Mozilla’s Projects • Mozilla’s Projects have been one of the most successful open—source movements in the recent years. • Some of them are Firefox Internet Browser for Desktop and Mobile Platforms, Thunderbird Email Client, SkSeamonkey (formerl y k nown as th e M ozill a app lica tion suite), Lightning and Sunbird—Calendaring applications and Camino. • We also promote WebFWD and Rainbow as a part of the Mozilla Labs Initiative. Not to mention the CouchDB, ZK, Gecko and the XUL Runner. The Firefox • World’s most advanced and secure Internet Browser. • Accounts for more than a quarter of world’s browser market share[1] • Some of the cool features in Firefox include Tabbed Browsing, Tabbed Browsing, Countless extensions and addons, Built—in RSS, Firefox Sync, Panorama and the awesome bar ☺ • Above all, its free ! [1] – Source : Wikipedia -http://en.wikipedia.org/wiki/Usage_share_of_web_browsers as on 16th September 2011 Firefox – Tech Specs • Crash protection support across multiple OS for Silverlight, Flash, QuickTime plugins • Full WebGL, WebM and HTML5 support (for controls and the new parser) and partial support for CSS Transitions. -
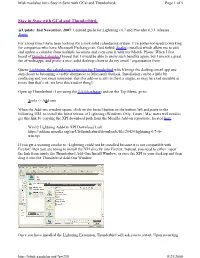
Stay in Sync with Gcal and Thunderbird. Page 1 of 5
bfish.xaedalus.net » Stay in Sync with GCal and Thunderbird. Page 1 of 5 Stay in Sync with GCal and Thunderbird. @Update: 2nd November, 2007: Updated guide for Lightning v0.7 and Provider 0.3.1 releases — Jonny For a long time I have been looking for a rock solid calendaring system. I’ve gotten too used to working for companies who have Microsoft Exchange (or, God forbid, Scalix) installed which allow me to edit and update a calendar from multiple locations and even sync it with my Mobile Phone. When I first heard of Google Calendar I hoped that I would be able to enjoy such benefits again, but I am not a great fan of web-apps, and prefer a nice, solid desktop client to do my email / organisation from. Queue Lightning, the calendaring extension for Thunderbird which brings the desktop email app one step closer to becoming a viable alternative to Microsoft Outlook. Installation can be a little bit confusing and you must remember that this add-on is still in the 0.x stages, so may be a tad unstable at times (but that’s ok, we love this kind of thing!) Open up Thunderbird (I am using the 2.0.0.6 release) and on the Top Menu, go to: Tools -> Add-ons When the Add-ons window opens, click on the Install button on the bottom left and paste in the following URL to install the latest release of Lightning (Windows Only, Linux / Mac users will need to get this link by copying the XPI download path from the Mozilla Add-on repository, located here.