Methodological and Technical Developments Methodological and Technical Developments
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Deformation of the Ancient Mole of Palairos (Western Greece) by Faulting and Liquefaction
Marine Geology 380 (2016) 106–112 Contents lists available at ScienceDirect Marine Geology journal homepage: www.elsevier.com/locate/margo Deformation of the ancient mole of Palairos (Western Greece) by faulting and liquefaction Stathis Stiros ⁎, Vasso Saltogianni Department of Civil Engineering, University of Patras, Patras, Greece article info abstract Article history: A submerged 2300 years-old mole or breakwater with a sigmoidal shape has been identified at the Palairos har- Received 8 March 2016 bor (Akarnania, SW Greece mainland). Different possible scenarios could be proposed to explain this enigmatic Received in revised form 26 July 2016 shape for an ancient breakwater, such as selective erosion of the original structure, construction above existing Accepted 3 August 2016 shoals or reefs, gravity sliding and post-construction offset due to strike-slip faulting, but all these scenarios Available online 05 August 2016 seem rather weak. Inspired by a large scale lateral offset of a retaining wall of a quay at the Barcelona harbor due to static liquefaction, by evidence of strike-slip earthquakes and of liquefaction potential in the study area, Keywords: Marine transgression as well as by recent evidence for long-duration steady, nearly uni-directional dynamic displacements in the Soil dynamics near-field of strike-slip faults, we propose an alternative scenario for this mole. An earthquake associated with Palaeoseismic/paleoseismic strike-slip faulting and high acceleration produced liquefaction of the mole foundations and long duration, nearly Sea-level rise unidirectional tectonic slip, while the later part of the steady slip produced additional secondary (surficial) slip on liquefied layers. © 2016 Elsevier B.V. -

SUSTAINABILITY REPORT 1 1 2 at a Glance Message 06 07 from the CEO
The best travel companion 2018 ANNUAL www.neaodos.gr SUSTAINABILITY REPORT 1 1 2 Message from the CEO 06 07At a glance Nea Odos11 21Awards Road Safety 25 37 Corporate Responsibility 51 High Quality Service Provision 3 69Human Resources Caring for the Enviment81 Collaboration with Local Communities 93 and Social Contribution 4 Sustainable Development Goals in103 our operation 107Report Profile GRI Content Index109 5 Message from the CEO Dear stakeholders, The publication of the 5th annual Nea Odos Corporate Responsibility Report constitutes a substantial, fully documented proof that the goal we set several years ago as regards integrating the principles, values and commitments of Corporate Responsibility into every aspect of our daily operations has now become a reality. The 2018 Report is extremely important to us, as 2018 signals the operational completion of our project, and during this year: A) Both the construction and the full operation of the Ionia Odos motorway have been completed, a project linking 2 Regions, 4 prefectures and 10 Municipalities, giving a boost to development not only in Western Greece and Epirus, but in the whole country, B) Significant infrastructure upgrade projects have also been designed, implemented and completed at the A.TH.E Motorway section from Metamorphosis in Attica to Scarfia, a section we operate, maintain and manage. During the first year of the full operation of the motorways - with 500 employees in management and operation, with more than 350 kilometres of modern, safe motorways in 7 prefectures of our country with a multitude of local communities - we incorporated in our daily operations actions, activities and programs we had designed, aiming at supporting and implementing the key strategic and development pillars of our company for the upcoming years. -

The World View of the Anonymous Author of the Greek Chronicle of the Tocco
THE WORLD VIEW OF THE ANONYMOUS AUTHOR OF THE GREEK CHRONICLE OF THE TOCCO (14th-15th centuries) by THEKLA SANSARIDOU-HENDRICKX THESIS submitted in the fulfilment of the requirements for the degree DOCTOR OF ARTS in GREEK in the FACULTY OF ARTS at the RAND AFRIKAANS UNIVERSITY PROMOTER: DR F. BREDENKAMP JOHANNESBURG NOVEMBER 2000 EFACE When I began with my studies at the Rand Afrikaans University, and when later on I started teaching Modern Greek in the Department of Greek and Latin Studies, I experienced the thrill of joy and the excitement which academic studies and research can provide to its students and scholars. These opportunities finally allowed me to write my doctoral thesis on the world view of the anonymous author of the Greek Chronicle of the Tocco. I wish to thank all persons who have supported me while writing this study. Firstly, my gratitude goes to Dr Francois Bredenkamp, who not only has guided me throughout my research, but who has always been available for me with sound advice. His solid knowledge and large experience in the field of post-classical Greek Studies has helped me in tackling Byzantine Studies from a mixed, historical and anthropological view point. I also wish to render thanks to my colleagues, especially in the Modern Greek Section, who encouraged me to continue my studies and research. 1 am indebted to Prof. W.J. Henderson, who has corrected my English. Any remaining mistakes in the text are mine. Last but not least, my husband, Prof. B. Hendrickx, deserves my profound gratitude for his patience, encouragement and continuous support. -

Chapter 3 GREEK HISTORY
Chapter 3 GREEK HISTORY The French Academician Michel Déon has written: "In Greece contemporary man, so often disoriented, discovers a quite incredible joy; he discovers his roots.” GREECE - HELLAS [Greeks] denoted the inhabitants of 700 or more city-states in the Greek peninsula The roots of much of the Western world lie in including Epirus, Macedonia, Thrace, Asia the civilizations of the ancient Greece and Minor, and many of the shores of the Rome. This chapter is intended to bring you Mediterranean and the Black Seas. small pieces of those rich roots of our Greek past. The objectives of this chapter are: first, Life in Greece first appeared on the Halkidiki to enrich our consciousness with those bits of Peninsula dated to the Middle Paleolithic era information and to build an awareness of what (50.000 B.C). Highly developed civilizations it means to be connected with the Greek past; appeared from about 3000 to 2000 B.C. and second, to relate those parts of Greek During the Neolithic period, important history that affected the migrations of the cultural centers developed, especially in Greeks during the last few centuries. Thessaly, Crete, Attica, Central Greece and Knowledge of migration patterns may prove the Peloponnesus. to be very valuable in your search for your ancestors. The famous Minoan advanced prehistoric culture of 2800-1100 B.C. appeared in Crete. We see more artistic development in the Bronze Age (2000 BC), during which Crete was the center of a splendid civilization. It was a mighty naval power, wealthy and powerful. Ruins of great palaces with beautiful paintings were found in Knossos, Phaistos, and Mallia. -

The Best of Greece
05_165386 ch01.qxp 1/3/08 10:57 AM Page 7 1 The Best of Greece Greece is, of course, the land of ancient sites and architectural treasures—the Acropo- lis in Athens, the amphitheater of Epidaurus, and the reconstructed palace at Knossos among the best known. But Greece is much more: It offers age-old spectacular natu- ral sights, for instance—from Santorini’s caldera to the gray pinnacles of rock of the Meteora—and modern diversions ranging from elegant museums to luxury resorts. It can be bewildering to plan your trip with so many options vying for your attention. Take us along and we’ll do the work for you. We’ve traveled the country extensively and chosen the very best that Greece has to offer. We’ve explored the archaeological sites, visited the museums, inspected the hotels, reviewed the tavernas and ouzeries, and scoped out the beaches. Here’s what we consider the best of the best. 1 The Best Travel Experiences • Making Haste Slowly: Give yourself island boat schedules! See chapter 10, time to sit in a seaside taverna and “The Cyclades.” watch the fishing boats come and go. • Leaving the Beaten Path: Persist If you visit Greece in the spring, take against your body’s and mind’s signals the time to smell the flowers; the that “this may be pushing too far,” fields are covered with poppies, leave the main routes and major daisies, and other blooms. Even in attractions behind, and make your Athens, you’ll see hardy species grow- own discoveries of landscape, villages, ing through the cracks in concrete or activities. -

Cahiers Balkaniques, 42 | 2014 the Attitude of the Beys of the Albanian Southern Provinces (Toskaria) Toward
Cahiers balkaniques 42 | 2014 Grèce-Roumanie : héritages communs, regards croisés The attitude of the Beys of the Albanian Southern Provinces (Toskaria) towards Ali Pasha Tepedelenli and the Sublime Porte (mid-18th-mid-19th centuries) The case of “der ’e madhe” [: Great House] of the Beys of Valona L’attitude des Beys des provinces méridionales albanaises (Toskaria) envers Ali Pacha de Tebelen et la Sublime Porte (mi-XVIIIe-mi-XIXe s.) : le cas des Beys de Valona Η συμπεριφορά των μπέηδων των νότιων αλβανικών περιοχών [Τοσκαριά] απέναντι στον Αλή Πασά Τεπελένης και την Υψηλή Πύλη, από την μέση του 18ου ως τη μέση του 19ου αιώνα:το παράδειγμα των μπέηδων της Βαλόνας Stefanos P. Papageorgiou Electronic version URL: https://journals.openedition.org/ceb/3520 DOI: 10.4000/ceb.3520 ISSN: 2261-4184 Publisher INALCO Electronic reference Stefanos P. Papageorgiou, “The attitude of the Beys of the Albanian Southern Provinces (Toskaria) towards Ali Pasha Tepedelenli and the Sublime Porte (mid-18th-mid-19th centuries)”, Cahiers balkaniques [Online], 42 | 2014, Online since 30 November 2012, connection on 07 July 2021. URL: http://journals.openedition.org/ceb/3520 ; DOI: https://doi.org/10.4000/ceb.3520 This text was automatically generated on 7 July 2021. Cahiers balkaniques est mis à disposition selon les termes de la Licence Creative Commons Attribution - Pas d’Utilisation Commerciale 4.0 International. The attitude of the Beys of the Albanian Southern Provinces (Toskaria) toward... 1 The attitude of the Beys of the Albanian Southern Provinces (Toskaria) -

The CHARIOTEER an Annual Review of Modern Greek Culture
The CHARIOTEER An Annual Review of Modern Greek Culture NUMBER 28 1986 GENERAL MAKRIY ANNIS: Excerpts from his MEMOIRS Translated by RICK M. NEWTON D.N. MARONITIS: AND POLITICAL ETHICS Translated by C. CAPRI-KARKA TITOS PATRIKIOS: A Selection of Poems Translated by C. CAPRI-KARKA GEORGE IOANNOU: Ten Short Stories from OUT OF SELF-RESPECT and THE SOLE INHERITANCE Translated by RICK M. NEWTON THE POETRY OF ANDONIS DECAVALLES by GEORGE THANIEL $15.00 I I I I I I I I I I THE CHARIOTEER AN ANNUAL REVIEW OF MODERN GREEK CULTURE Formerly published by PARNASSOS Greek Cultural Society of New York NuMBER 28 1986 Publisher: LEANDROS PAPATHANASIOU Editor: c. CAPRI-KARKA Managing Editor: SusAN ANASTASAKOS Copy Editor: PAUL KACHUR THE CHARIOTEER is published by PELLA PUBLISHING COMPANY, INC. Editorial and subscription address: Pella Publishing Company, 337 West 36th Street, New York, NY 10018. One year subscription $15; Two-year subscription $28; Three-year subscription $40. Copyright 1986 by Pella Publishing Company, Inc. All rights reserved. Printed in U.S.A. by Athens Printing Co., 337 West 36th Street, New York, NY 10018.-THE CHARIOTEER solicits essays on and English translations from works of modern Greek writers. Translations should be accompanied by a copy of the original Greek text. Manuscripts will not be returned unless accompanied by a stamped self-addressed envelope. No responsibility can be assumed for theft, loss or damage. ISBN 0-933824-20-3 ISSN 0:577-:5574 ACKNOWLEDGMENT The CHARIOTEER wishes to express its sincere thanks to Mrs. Dimitra Miliaraki, sister of the late George Ioannou, for permission to translate her brother's short stories, to Mr. -

Exploring the Cultural Identity of Messolonghi- Aetoliko Area for the Creation of the Eco- Museum «Port Museum of Aetoliko»
EXPLORING THE CULTURAL IDENTITY OF MESSOLONGHI- AETOLIKO AREA FOR THE CREATION OF THE ECO- MUSEUM «PORT MUSEUM OF AETOLIKO» The content of this publication is the sole responsibility of ERFC (European Regional Framework for Co-operation) and can in no way be taken to reflect the views of the European Union. The document is published for the project MUSE (Development and valorization of port museums as natural and cultural heritage sites). This project is co-funded be the European Union, the European Regional Development Fund (E.R.D.F) and the national contribution of Greece and Italy, Interreg project V-A GREECE-ITALY 2014 – 2020. Author- Organization of focus groups: Panagiota Koutsoukou Research team support - focus groups: Niki Iatrou Layout editing - Project coordinator: Ioannis Papagiannopoulos Publication: April 2019, draft 1.0 Project partners Mediterranean European Regional Municipality of Agronomic Institute of Framework for Municipality of Port Authority of Tricase [IT] Bari Cooperation Messolonghi [GR] Corfu [GR] CIHEAM IAMB [IT] ERFC [GR] Aetoloakarnania: profile of the area FIRST CHAPTER 1 The cities of the lagoon complex: profile, history SECOND SECOND CHAPTER 2 Human – Society – Place CHAPTER 3 THIRD Local culture - Tradition – Past and present CHAPTER 4 FOURTH Contents Preface _________________________________________________ 5 Introduction _____________________________________________ 6 Methodological Framework ______________________________________ 6 Special Thanks _______________________________________________ 7 Aetoloakarnania: -

IONIAN DOLPHIN PROJECT By
IONIAN DOLPHIN PROJECT By Information for Participants www.ioniandolphinproject.org Dear friend, Dolphins have permeated the Greek culture since ancient times. Countless artwork and several myths celebrate their strong and intimate bond with humans. For centuries, dolphins have been at the core of the Hellenic civilization and they are vividly portrayed in iconography throughout Greece. In recent times, however, dolphins have almost fallen into oblivion—their remnant iconic role being confined to tourist jewellery and postcards. While today's abundance of dolphins is likely only a fragment of what it was a century ago, important populations still live and reproduce in the Greek seas. Join the Ionian Dolphin Project and help us to ensure the long-term viability of dolphins living in coastal waters of the eastern Ionian Sea. For 30 years years, 1,500+ non-specialist participants from 40+ nations, encompassing the five continents, have participated in the IDP. They have provided us deeply needed support and helped us obtain crucial data. YOU will fuel science-based conservation action aimed towards a respectful management of the local resources, for the benefit of both dolphins and humans. During your stay with us, you will be part of a scientific team focused on the study and conservation of these amazing creatures in the beautiful coastal waters of western Greece. Here, you will work side-by-side with experienced researchers and conduct daily surveys at sea. You will see lots of dolphins, get to know them, actively contribute to field data collection and, back at the field station, help us download the data and process digital photos and scientific information. -

The West Coast of Greece and the Ionian Sea
“He likes to enjoy the sea from up here. How much wider it is, that much more it steals the heart. So much that your mind chokes.” Aristotelis Valaoritis Welcome to the west coast of Greece and the Ionian sea Crystal clear waters and pure natural beauty are the symbols of the Ionian Sea. The sea was named after Io who, according to Greek mythology, was a priestess of the goddess Hera. Io had an affair with Zeus, king of the gods, and Hera’s husband. When Hera learned of the affair she transformed Io into a cow. Io fled around Europe trying to escape Hera’s wrath. Finally, Io plunged into the sea, which was named Ionian, after her. MAP OF EUROPE MAP OF PALEROS MUNICIPALITY MAP OF GREECE Welcome to Paleros Paleros, a picturesque town located on the west coast of mainland Greece, is evocatively situated in a breathtaking backdrop of beautiful and serene vistas and the crystal-clear waters of the Ionian Sea. Olive trees, vineyards and pine trees extend down to the spectacular sandy beaches. Beachfront bars, restaurants and cafes are within walking distance. Ancient Paleros is a place of unrivalled beauty and grace, situated high in the mountains overlooking the Ionian sea and Vourkaria lake. The city had a population of over 10,000 people and was the location of one of the most important battles of antiquity. At nearby Aktio, Antony and Cleopatra were defeated in a sea battle by Octavius, who built the city of Nikopolis to commemorate his victory and moved the population of Paleros to his new city in 31 B.C. -
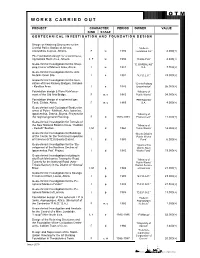
Geotechnical Investigation En 2018
O T M WORKS CARRIED OUT PROJECT CHARACTER PERIOD OWNER VALUE KIND STAGE GEOTECHNICAL INVESTIGATION AND FOUNDATION DESIGN Design of Retaining Structures for the Central Police Station of Athens, “Hellenic Alexandras Avenue, Athens. F w 1976 Foundation Co.” 4.000(+) Pile Foundation design for a warehouse, Ag.Ioannis Renti Area, Athens. I, F w 1980 “D.KALYVA” 4.600(+) Geotechnical Investigation for the Shop- “E. BARBALIAS” ping Center of Marousi Area, Attica. I w 1981 S.A. 7.700(+) Geotechnical Investigation for the Arta Metallic Grain Silo. I e 1982 “K.Y.D.E.P.” 23.000(+) Geotechnical Investigation for the foun- dation of three Railway Bridges, Sofades “Greek Railway - Karditsa Area. I e 1983 Organization” 26.000(+) Foundation design & Piers Reinforce- “Ministry of ment of the Old Arta Bridge. F w, c 1983 Public Works” 34.000(+) Foundation design of a spherical gas “PETROLINA” Tank, Elefsis, Attica. F w, c 1983 S.A. 4.000(+) Geotechnical and Geological Studies for areas of Pylos - Methoni, Arta, Ioannina, Igoumenitsa, Drama, Skyros, Projects for “Ministry of the regional general Planning. F d 1983-1984 Environment” 11.500(+) Geotechnical Investigation for Tunnels of the New National Road in Crete, “Kolibari “Ministry of - Kastelli” Section. I, M d 1984 Public Works” 18.000(+) Geotechnical Investigation for Buildings “Boetia District of the Center for the Technical Inspection Public Works of Vehicles (KTEO) Boetia District. I d 1985 Fund” 6.000(+) Geotechnical Investigation for the “De- “Igoumenitsa velopment of the Northern Section of District Navy Igoumenitsa Port” Project. I d 1985 Works Fund” 19.000(+) Geotechnical Investigation including in situ Rock Mechanics Testing for Road “Ministry of Tunnels for the National Road (Arta - Public Works” Trikala Section) in the District of “Gouras” District Service River. -

Investment Profile of the Region of Western Greece
Region of Western Greece ‐ Investment Profile January 2012 0 Contents 1. Profile of the Region of Western Greece 2. Western Greece’s competitive advantages 3. Investment opportunities 1 1. Profile of the Region of Western Greece 2 Region of Western Greece : Quick facts Investment incentives quick facts Operational Program‘ Western Greece 2007‐ 2013 ‘: € 1,315 b New Investment law: Subsidies of up to 50% for business plans. Jessica Holding Fund: €15m • Western Greece is one of the thirteen regions of Greece. It comprises the western part of continental Greece and the northwestern part of the Peloponnese. • Main economic activities include agriculture and tourism services. Demographics and Workforce quick facts Population: 621,000 • As in many other Regions of Greece, production of wine and olive oil is significant. Dairy products are also important to the local GDP per Capita: 68.4% of the EU average economy as well as fish farming, unique to the area and a Contribution to Greek GDP: 5.12% (2008) traditional source of income. Total workforce: 316,000 • Western Greece is quickly becoming one of the top tourism destinations in Greece. The emergence of new hotel units and Unemployment rate: 16,1% new investments in the area have strengthened the local economy and are currently changing the overall profile of economic activity. Source: economics.gr, statistics.gr 3 2. Western Greece ’s competitive advantages 4 Western Greece has a breathtaking geography to offer •The Region of Western Greece is privileged in terms of the natural environment. The region accommodates many, various and significantly sensitive ecosystems. It is characteristic, that from the eleven wetlands of international importance that exist in Greece and who have also joined in the Ramsar agreement , the three are located in Western Greece Region.