A Curriculum Learning Method for Improved Noise Robustness in Automatic Speech Recognition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Mathematical and Physical Analysis of Circuit Jitter with Application to Cryptographic Random Bit Generation
WJM-6500 BS2-0501 A Mathematical and Physical Analysis of Circuit Jitter with Application to Cryptographic Random Bit Generation A Major Qualifying Project Report: submitted to the Faculty of the WORCESTER POLYTECHNIC INSTITUTE in partial fulfillment of the requirements for the Degree of Bachelor of Science by _____________________________ Wayne R. Coppock _____________________________ Colin R. Philbrook Submitted April 28, 2005 1. Random Number Generator Approved:________________________ Professor William J. Martin 2. Cryptography ________________________ 3. Jitter Professor Berk Sunar 1 Abstract In this paper analysis of jitter is conducted to determine its suitability for use as an entropy source for a true random number generator. Efforts are taken to isolate and quantify jitter in ring oscillator circuits and to understand its relationship to design specifications. The accumulation of jitter via various methods is also investigated to determine whether there is an optimal accumulation technique for sampling the uncertainty of jitter events. Mathematical techniques are used to analyze the accumulation process and an attempt at modeling a signal with jitter is made. The physical properties responsible for the noise that causes jitter are also briefly investigated. 2 Acknowledgements We would like to thank our faculty advisors and our mentors at GD, without whom this project would not have been possible. Our advisors, Professor Bill martin and Professor Berk Sunar, were indispensable in keeping us focused on the tasks ahead as well as for providing background to help us explore new questions as they arose. Our mentors at GD were also key to the project’s success, and we owe them much for this. -

Improving Speech Quality for Hearing Aid Applications Based on Wiener Filter and Composite of Deep Denoising Autoencoders
signals Article Improving Speech Quality for Hearing Aid Applications Based on Wiener Filter and Composite of Deep Denoising Autoencoders Raghad Yaseen Lazim 1,2 , Zhu Yun 1,2 and Xiaojun Wu 1,2,* 1 Key Laboratory of Modern Teaching Technology, Ministry of Education, Shaanxi Normal University, Xi’an 710062, China; [email protected] (R.Y.L.); [email protected] (Z.Y.) 2 School of Computer Science, Shaanxi Normal University, No.620, West Chang’an Avenue, Chang’an District, Xi’an 710119, China * Correspondence: [email protected] Received: 10 July 2020; Accepted: 1 September 2020; Published: 21 October 2020 Abstract: In hearing aid devices, speech enhancement techniques are a critical component to enable users with hearing loss to attain improved speech quality under noisy conditions. Recently, the deep denoising autoencoder (DDAE) was adopted successfully for recovering the desired speech from noisy observations. However, a single DDAE cannot extract contextual information sufficiently due to the poor generalization in an unknown signal-to-noise ratio (SNR), the local minima, and the fact that the enhanced output shows some residual noise and some level of discontinuity. In this paper, we propose a hybrid approach for hearing aid applications based on two stages: (1) the Wiener filter, which attenuates the noise component and generates a clean speech signal; (2) a composite of three DDAEs with different window lengths, each of which is specialized for a specific enhancement task. Two typical high-frequency hearing loss audiograms were used to test the performance of the approach: Audiogram 1 = (0, 0, 0, 60, 80, 90) and Audiogram 2 = (0, 15, 30, 60, 80, 85). -

Dithering and Quantization of Audio and Image
Dithering and Quantization of audio and image Maciej Lipiński - Ext 06135 1. Introduction This project is going to focus on issue of dithering. The main aim of assignment was to develop a program to quantize images and audio signals, which should add noise and to measure mean square errors, comparing the quality of the quantized images with and without noise. The program realizes fallowing: - quantize an image or audio signal using n levels (defined by the user); - measure the MSE (Mean Square Error) between the original and the quantized signals; - add uniform noise in [-d/2,d/2], where d is the quantization step size, using n levels; - quantify the signal (image or audio) after adding the noise, using n levels (user defined); - measure the MSE by comparing the noise-quantized signal with the original; - compare results. The program shows graphic result, presenting original image/audio, quantized image/audio and quantized with dither image/audio. It calculates and displays the values of MSE – mean square error. 2. DITHERING Dither is a form of noise, “erroneous” signal or data which is intentionally added to sample data for the purpose of minimizing quantization error. It is utilized in many different fields where digital processing is used, such as digital audio and images. The quantization and re-quantization of digital data yields error. If that error is repeating and correlated to the signal, the error that results is repeating. In some fields, especially where the receptor is sensitive to such artifacts, cyclical errors yield undesirable artifacts. In these fields dither is helpful to result in less determinable distortions. -

Pink Noise Generator
PINK NOISE GENERATOR K4301 Add a spectrum analyser with a microphone and check your audio system performance. H4301IP-1 VELLEMAN NV Legen Heirweg 33 9890 Gavere Belgium Europe www.velleman.be www.velleman-kit.com Features & Specifications To analyse the acoustic properties of a room (usually a living- room), a good pink noise generator together with a spectrum analyser is indispensable. Moreover you need a microphone with as linear a frequency characteristic as possible (from 20 to 20000Hz.). If, in addition, you dispose of an equaliser, then you can not only check but also correct reproduction. Features: Random digital noise. 33 bit shift register. Clock frequency adjustable between 30KHz and 100KHz. Pink noise filter: -3 dB per octave (20 .. 20000Hz.). Easily adaptable to produce "white noise". Specifications: Output voltage: 150mV RMS./ clock frequency 40KHz. Output impedance: 1K ohm. Power supply: 9 to 12VAC, or 12 to 15VDC / 5mA. 3 Assembly hints 1. Assembly (Skipping this can lead to troubles ! ) Ok, so we have your attention. These hints will help you to make this project successful. Read them carefully. 1.1 Make sure you have the right tools: A good quality soldering iron (25-40W) with a small tip. Wipe it often on a wet sponge or cloth, to keep it clean; then apply solder to the tip, to give it a wet look. This is called ‘thinning’ and will protect the tip, and enables you to make good connections. When solder rolls off the tip, it needs cleaning. Thin raisin-core solder. Do not use any flux or grease. A diagonal cutter to trim excess wires. -

1Õf Noise from Nonlinear Stochastic Differential Equations
PHYSICAL REVIEW E 81, 031105 ͑2010͒ 1Õf noise from nonlinear stochastic differential equations J. Ruseckas* and B. Kaulakys Institute of Theoretical Physics and Astronomy, Vilnius University, A. Goštauto 12, LT-01108 Vilnius, Lithuania ͑Received 20 October 2009; published 8 March 2010͒ We consider a class of nonlinear stochastic differential equations, giving the power-law behavior of the power spectral density in any desirably wide range of frequency. Such equations were obtained starting from the point process models of 1/ f noise. In this article the power-law behavior of spectrum is derived directly from the stochastic differential equations, without using the point process models. The analysis reveals that the power spectrum may be represented as a sum of the Lorentzian spectra. Such a derivation provides additional justification of equations, expands the class of equations generating 1/ f noise, and provides further insights into the origin of 1/ f noise. DOI: 10.1103/PhysRevE.81.031105 PACS number͑s͒: 05.40.Ϫa, 72.70.ϩm, 89.75.Da I. INTRODUCTION signals with 1/ f noise were obtained in Refs. ͓29,30͔͑see ͓ ͔͒ Power-law distributions of spectra of signals, including also recent papers 5,31 , starting from the point process / ͓ ͔ 1/ f noise ͑also known as 1/ f fluctuations, flicker noise, and model of 1 f noise 27,32–39 . pink noise͒, as well as scaling behavior in general, are ubiq- The purpose of this article is to derive the behavior of the uitous in physics and in many other fields, including natural power spectral density directly from the SDE, without using phenomena, human activities, traffics in computer networks, the point process model. -

Noise by the Nonlinear Stochastic Differential Equations
Modeling scaled processes and 1/f β noise by the nonlinear stochastic differential equations B Kaulakys and M Alaburda Institute of Theoretical Physics and Astronomy of Vilnius University, Goˇstauto 12, LT-01108 Vilnius, Lithuania E-mail: [email protected] Abstract. We present and analyze stochastic nonlinear differential equations generating signals with the power-law distributions of the signal intensity, 1/f β noise, power-law autocorrelations and second order structural (height-height correlation) functions. Analytical expressions for such characteristics are derived and the comparison with numerical calculations is presented. The numerical calculations reveal links between the proposed model and models where signals consist of bursts characterized by the power-law distributions of burst size, burst duration and the inter- burst time, as in a case of avalanches in self-organized critical (SOC) models and the extreme event return times in long-term memory processes. The presented approach may be useful for modeling the long-range scaled processes exhibiting 1/f noise and power-law distributions. Keywords: 1/f noise, stochastic processes, point processes, power-law distributions, nonlinear stochastic equations arXiv:1003.1155v1 [nlin.AO] 4 Mar 2010 Modeling scaled processes and 1/f β noise 2 1. Introduction The inverse power-law distributions, autocorrelations and spectra of the signals, including 1/f noise (also known as 1/f fluctuations, flicker noise and pink noise), as well as scaling behavior in general, are ubiquitous in physics and in many other fields, counting natural phenomena, spatial repartition of faults in geology, human activities such as traffic in computer networks and financial markets. -

Human Cognition and 1/F Scaling
Journal of Experimental Psychology: General Copyright 2005 by the American Psychological Association 2005, Vol. 134, No. 1, 117–123 0096-3445/05/$12.00 DOI: 10.1037/0096-3445.134.1.117 Human Cognition and 1/f Scaling Guy C. Van Orden John G. Holden Arizona State University and the National Science Foundation California State University, Northridge Michael T. Turvey University of Connecticut and Haskins Laboratories Ubiquitous 1/f scaling in human cognition and physiology suggests a mind–body interaction that contradicts commonly held assumptions. The intrinsic dynamics of psychological phenomena are interaction dominant (rather than component dominant), and the origin of purposive behavior lies with a general principle of self-organization (rather than a special neurocognitive mechanism). E.-J. Wagen- makers, S. Farrell, and R. Ratcliff (2005) raised concerns about the kinds of data and analyses that support generic 1/f scaling. This reply is a defense that furthermore questions the model that Wagen- makers and colleagues endorse and their strategy for addressing complexity. As science turns to complexity one must realize that complexity Can We Rule Out Transient Correlations? demands attitudes quite different from those heretofore common . each complex system is different; apparently there are no general laws The backbone of the commentary of Wagenmakers et al. (2005) for complexity. Instead, one must reach for “lessons” that might, with is whether transient short-range correlations adequately character- insight and understanding, be learned in one system and applied to ize the data from Van Orden et al. (2003). The hypothesis of another. (Goldenfeld & Kadanoff, 1999, p. 89) transient short-range correlations, however, carries the burden of proof because it asserts something readily observable, a short- In a previous article (Van Orden, Holden, & Turvey, 2003), we range upper bound to visibly scale-free behavior. -
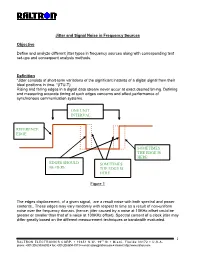
Jitter and Signal Noise in Frequency Sources
Jitter and Signal Noise in Frequency Sources Objective Define and analyze different jitter types in frequency sources along with corresponding test set-ups and consequent analysis methods. Definition “Jitter consists of short-term variations of the significant instants of a digital signal from their ideal positions in time. “(ITU-T) Rising and falling edges in a digital data stream never occur at exact desired timing. Defining and measuring accurate timing of such edges concerns and affect performance of synchronous communication systems. ONE UNIT INTERVAL REFERENCE EDGE SOMETIMES THE EDGE IS HERE EDGES SHOULD SOMETIMES BE HERE THE EDGE IS HERE Figure 1 The edges displacement, of a given signal, are a result noise with both spectral and power contents.. These edges may vary randomly with respect to time as a result of non-uniform noise over the frequency domain. (hence; jitter caused by a noise at 10KHz offset could be greater or smaller than that of a noise at 100KHz offset). Spectral content of a clock jitter may differ greatly based on the different measurement techniques or bandwidth evaluated. 1 RALTRON ELECTRONICS CORP. ! 10651 N.W. 19th St ! Miami, Florida 33172 ! U.S.A. phone: +001(305) 593-6033 ! fax: +001(305)594-3973 ! e-mail: [email protected] ! internet: http://www.raltron.com System Disruptions caused by Jitter Clock recovery mechanisms, in network elements, are used to sample the digital signal using the recovered bit clock. If the digital signal and the clock have identical jitter, the constant jitter error will not affect the sampling instant and therefore no bit errors will arise. -

Gauging the Fractal Dimension of Response Times from Cognitive Tasks
CHAPTER 6 Gauging the Fractal Dimension of Response Times from Cognitive Tasks John G. Holden Department of Psychology California State University, Northridge Northridge, CA 91330-8255 U. S. A. E-mail: [email protected] Holden An unexpected and exotic brand of variability resides in the trial-by-trial fluctuations of human judgments of passing time. The pattern, called 1/ƒ or pink noise, is a construct from fractal geometry. Pink noise is associated with complex systems whose components interact on multiple time scales to self-organize their behavior (Bassingthwaighte, Liebovitch, & West, 1994; Jensen, 1998; Van Orden, Holden, & Turvey, 2003; see also Aks, Chapter 7). This chapter describes the phenomenon of pink noise, and explains how to conduct statistical analyses that identify it in response time data from elementary cognitive tasks. It was Gilden, Thorton, and Mallon (1995) who first reported pink noise in response time variability during the fundamentally cognitive task of estimating fixed intervals of time. Gilden et al.’s temporal estimation task required participants to repeatedly estimate fixed intervals of time—in essence to “become a clock”—by pressing a button at each instant they believed a specific time interval had elapsed. Separate laboratory sessions were administered for each of several fixed target time-interval conditions. In each session 1000 time- interval judgments were collected in succession. The time-interval conditions ranged from 1/3 s up to 10 s. Of course, no participant’s succession of time-interval judgments was exactly the same on every trial. Instead they varied from trial to trial. Lining up the series of successive time estimates in the strict order in which they were collected (i.e., trial 1, 2, … 1000) yielded a trial series of response times, which was treated very much like a standard time series in Gilden et al.’s statistical analyses. -

A Case Study in Analog Co-Processing for Solving Stochastic Differential Equations
A Case Study in Analog Co-Processing for Solving Stochastic Differential Equations Yipeng Huang, Ning Guo, Simha Sethumadhavan, Mingoo Seok, Yannis Tsividis Department of Computer Science and Department of Electrical Engineering Columbia University [email protected] Abstract—Stochastic differential equations (SDEs) are an im- multipliers, and mixed-signal components for converting ana- portant class of mathematical models for areas such as physics log variables into digital chip inputs and outputs. The chip and finance. Usually the model outputs are in the form of statistics encodes data as analog current, so the chip can sum variables of the dependent variables, generated from many solutions of the SDE using different samples of the random variables. Challenges by simply joining circuit branches; fanout current mirrors in in using existing conventional digital computer architectures the chip copy variables to different branches. A reconfigurable for solving SDEs include: rapidly generating the random input crossbar of switches allows us to chain analog operations variables for the SDE solutions, and having to use numerical end-to-end as needed for a given equation. Circuit design integration to solve the differential equations. Recent work by details of the prototypes, implemented at the 65nm technology our group has explored using hybrid analog-digital computing to solve differential equations. In the hybrid computing model, we node, are in papers by Guo et al. [1], [2]. The prototypes are solve differential equations by encoding variables as continuous successors to an earlier design built by Cowan et al. [3], [4]; values, which evolve in continuous time. In this paper we review the newer prototypes have features that permit calibration for the prior work, and study using the architecture, in conjunction more accurate results and easier interfacing with conventional with analog noise, to solve a canonical SDE, the Black-Scholes digital architectures. -

Understanding Noise in the Signal Chain
Understanding Noise in the Signal Chain Introduction: What is the Signal Chain? A signal chain is any a series of signal-conditioning components that receive an input, passes the signal from component to component, and produces an output. Signal Chain Voltage Ref V in Amp ADC DSP DAC Amp Vout 2 Introduction: What is Noise? • Noise is any electrical phenomenon that is unwelcomed in the signal chain Signal Chain Ideal Signal Path, Gain (G) Voltage V V Ref int ext Internal Noise External Noise V in + Amp ADC DSP DAC Amp + G·(Vin + Vext) + Vint • Our focus is on the internal sources of noise – Noise in semiconductor devices in general – Noise in data converters in particular 3 Noise in Semiconductor Devices 1. How noise is specified a. Noise amplitude b. Noise spectral density 2. Types of noise a. White noise sources b. Pink noise sources 3. Reading noise specifications a. Time domain specs b. Frequency domain specs 4. Estimating noise amplitudes a. Creating a noise spectral density plot b. Finding the noise amplitude 4 Noise in Semiconductor Devices 1. How noise is specified a. Noise amplitude b. Noise spectral density 2. Types of noise a. White noise sources b. Pink noise sources 3. Reading noise specifications a. Time domain specs b. Frequency domain specs 4. Estimating noise amplitudes a. Creating a noise spectral density plot b. Finding the noise amplitude 5 Noise in Semiconductor Devices How Noise is Specified: Amplitude Noise Amplitude Semiconductor noise results from random processes and thus the instantaneous amplitude is unpredictable. Amplitude exhibits a Gaussian (Normal) distribution. -

Evaluation of Green Walls As a Passive Acoustic Insulation System for Buildings ⇑ Z
Applied Acoustics 89 (2015) 46–56 Contents lists available at ScienceDirect Applied Acoustics journal homepage: www.elsevier.com/locate/apacoust Evaluation of green walls as a passive acoustic insulation system for buildings ⇑ Z. Azkorra a,b, G. Pérez c, J. Coma c, L.F. Cabeza c, S. Bures d, J.E. Álvaro e, A. Erkoreka a,b, M. Urrestarazu f, a Department of Thermal Engineering, University of the Basque Country (UPV/EHU), Alameda Urquijo s/n, 48013 Bilbao, Spain b ENEDI Research Group, Spain c GREA Innovació Concurrent, Edifici CREA, Universitat de Lleida, Pere de Cabrera s/n, 25001 Lleida, Spain d Buresinnova S. A. Barcelona, Spain e Pontificia Universidad Católica de Valparaíso, Escuela de Agronomía, Chile f Departamento de Agronomía, Universidad de Almería, Almería 04120, Spain article info abstract Article history: Greenery on buildings is being consolidated as an interesting way to improve the quality of life in urban Received 22 May 2014 environments. Among the benefits that are associated with greenery systems for buildings, such as Received in revised form 18 August 2014 energy savings, biodiversity support, and storm-water control, there is also noise attenuation. Despite Accepted 11 September 2014 the fact that green walls are one of the most promising building greenery systems, few studies of their Available online 28 September 2014 sound insulation potential have been conducted. In addition, there are different types of green walls; therefore, available data for this purpose are not only sparse but also scattered. To gather knowledge Keywords: about the contribution of vertical greenery systems to noise reduction, especially a modular-based green Vertical greenery systems wall, two different standardised laboratory tests were conducted.