A Survey of Efficient Structures for Digital Geometry Processing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Algorithm for the Construction of Intrinsic Delaunay Triangulations with Applications to Digital Geometry Processing
An Algorithm for the Construction of Intrinsic Delaunay Triangulations with Applications to Digital Geometry Processing Matthew Fisher Boris Springborn Peter Schroder¨ Alexander I. Bobenko Caltech TU Berlin Caltech TU Berlin Abstract The discrete Laplace-Beltrami operator plays a prominent role in many Digital Geometry Processing applications ranging from de- noising to parameterization, editing, and physical simulation. The standard discretization uses the cotangents of the angles in the im- mersed mesh which leads to a variety of numerical problems. We advocate the use of the intrinsic Laplace-Beltrami operator. It sat- isfies a local maximum principle, guaranteeing, e.g., that no flipped triangles can occur in parameterizations. It also leads to better con- ditioned linear systems. The intrinsic Laplace-Beltrami operator is based on an intrinsic Delaunay triangulation of the surface. We detail an incremental algorithm to construct such triangulations to- gether with an overlay structure which captures the relationship be- tween the extrinsic and intrinsic triangulations. Using a variety of example meshes we demonstrate the numerical benefits of the in- trinsic Laplace-Beltrami operator. Figure 1: Left: carrier of the (cat head) surface as defined by the original embedded mesh. Right: the intrinsic Delaunay triangu- 1 Introduction lation of the same carrier. Delaunay edges which appear in the original triangulation are shown in white. Some of the original 2 Delaunay triangulations of domains in R play an important role edges are not present anymore (these are shown in black). In their in many numerical computing applications because of the quality stead we see red edges which appear as the result of intrinsic flip- guarantees they make, such as: among all triangulations of the con- ping. -

Finding Neighbors in a Forest: a B-Tree for Smoothed Particle Hydrodynamics Simulations
Finding Neighbors in a Forest: A b-tree for Smoothed Particle Hydrodynamics Simulations Aurélien Cavelan University of Basel, Switzerland [email protected] Rubén M. Cabezón University of Basel, Switzerland [email protected] Jonas H. M. Korndorfer University of Basel, Switzerland [email protected] Florina M. Ciorba University of Basel, Switzerland fl[email protected] May 19, 2020 Abstract Finding the exact close neighbors of each fluid element in mesh-free computational hydrodynamical methods, such as the Smoothed Particle Hydrodynamics (SPH), often becomes a main bottleneck for scaling their performance beyond a few million fluid elements per computing node. Tree structures are particularly suitable for SPH simulation codes, which rely on finding the exact close neighbors of each fluid element (or SPH particle). In this work we present a novel tree structure, named b-tree, which features an adaptive branching factor to reduce the depth of the neighbor search. Depending on the particle spatial distribution, finding neighbors using b-tree has an asymptotic best case complexity of O(n), as opposed to O(n log n) for other classical tree structures such as octrees and quadtrees. We also present the proposed tree structure as well as the algorithms to build it and to find the exact close neighbors of all particles. arXiv:1910.02639v2 [cs.DC] 18 May 2020 We assess the scalability of the proposed tree-based algorithms through an extensive set of performance experiments in a shared-memory system. Results show that b-tree is up to 12× faster for building the tree and up to 1:6× faster for finding the exact neighbors of all particles when compared to its octree form. -

Geometry-Aware Topological Decompositions of Meshes
UC Irvine UC Irvine Electronic Theses and Dissertations Title Geometry-aware topological decompositions of meshes Permalink https://escholarship.org/uc/item/3vh0q7wn Author Chen, Jia Publication Date 2019 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA, IRVINE Geometry-aware topological decompositions of meshes DISSERTATION submitted in partial satisfaction of the requirements for the degree of DOCTOR OF PHILOSOPHY in Computer Science by Jia Chen Dissertation Committee: Professor Gopi Meenakshisundaram, Chair Professor Aditi Majumder Professor Shuang Zhao 2019 Chapter3 c 2016 ACM New York, NY, USA Chapter3 c 2018 ACM New York, NY, USA All other materials c 2019 Jia Chen DEDICATION To my family \. a man who keeps company with glaciers comes to feel tolerably insignificant by and by." { Mark Twain, A Tramp Abroad ii TABLE OF CONTENTS Page LIST OF FIGURESv LIST OF TABLESx LIST OF ALGORITHMS xi ACKNOWLEDGMENTS xii CURRICULUM VITAE xiii ABSTRACT OF THE DISSERTATION xiv 1 Introduction1 1.1 Cycles of topological properties.........................2 1.2 Topological decompositions of meshes......................4 2 Definitions and Background7 2.1 Surfaces and their topological classification...................7 2.2 Primal graph and dual graph embedded on a surface.............8 2.3 Paths and cycles.................................9 2.4 Tunnel and handle cycles............................. 11 3 Iterative localization of handle and tunnel cycles 13 3.1 Related work................................... 14 3.2 Problem formulation............................... 15 3.3 Localizing handle and tunnel cycles....................... 16 3.3.1 Iterative tree-cotree algorithm...................... 16 3.3.2 Cycle tightening.............................. 20 3.3.3 Decoupling composite fundamental cycles............... -
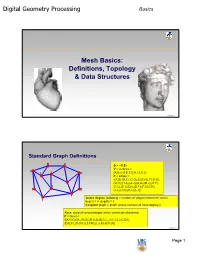
Digital Geometry Processing Mesh Basics
Digital Geometry Processing Basics Mesh Basics: Definitions, Topology & Data Structures 1 © Alla Sheffer Standard Graph Definitions G = <V,E> V = vertices = {A,B,C,D,E,F,G,H,I,J,K,L} E = edges = {(A,B),(B,C),(C,D),(D,E),(E,F),(F,G), (G,H),(H,A),(A,J),(A,G),(B,J),(K,F), (C,L),(C,I),(D,I),(D,F),(F,I),(G,K), (J,L),(J,K),(K,L),(L,I)} Vertex degree (valence) = number of edges incident on vertex deg(J) = 4, deg(H) = 2 k-regular graph = graph whose vertices all have degree k Face: cycle of vertices/edges which cannot be shortened F = faces = {(A,H,G),(A,J,K,G),(B,A,J),(B,C,L,J),(C,I,L),(C,D,I), (D,E,F),(D,I,F),(L,I,F,K),(L,J,K),(K,F,G)} © Alla Sheffer Page 1 Digital Geometry Processing Basics Connectivity Graph is connected if there is a path of edges connecting every two vertices Graph is k-connected if between every two vertices there are k edge-disjoint paths Graph G’=<V’,E’> is a subgraph of graph G=<V,E> if V’ is a subset of V and E’ is the subset of E incident on V’ Connected component of a graph: maximal connected subgraph Subset V’ of V is an independent set in G if the subgraph it induces does not contain any edges of E © Alla Sheffer Graph Embedding Graph is embedded in Rd if each vertex is assigned a position in Rd Embedding in R2 Embedding in R3 © Alla Sheffer Page 2 Digital Geometry Processing Basics Planar Graphs Planar Graph Plane Graph Planar graph: graph whose vertices and edges can Straight Line Plane Graph be embedded in R2 such that its edges do not intersect Every planar graph can be drawn as a straight-line plane graph © -

Evolution of the Graphical Processing Unit
University of Nevada Reno Evolution of the Graphical Processing Unit A professional paper submitted in partial fulfillment of the requirements for the degree of Master of Science with a major in Computer Science by Thomas Scott Crow Dr. Frederick C. Harris, Jr., Advisor December 2004 Dedication To my wife Windee, thank you for all of your patience, intelligence and love. i Acknowledgements I would like to thank my advisor Dr. Harris for his patience and the help he has provided me. The field of Computer Science needs more individuals like Dr. Harris. I would like to thank Dr. Mensing for unknowingly giving me an excellent model of what a Man can be and for his confidence in my work. I am very grateful to Dr. Egbert and Dr. Mensing for agreeing to be committee members and for their valuable time. Thank you jeffs. ii Abstract In this paper we discuss some major contributions to the field of computer graphics that have led to the implementation of the modern graphical processing unit. We also compare the performance of matrix‐matrix multiplication on the GPU to the same computation on the CPU. Although the CPU performs better in this comparison, modern GPUs have a lot of potential since their rate of growth far exceeds that of the CPU. The history of the rate of growth of the GPU shows that the transistor count doubles every 6 months where that of the CPU is only every 18 months. There is currently much research going on regarding general purpose computing on GPUs and although there has been moderate success, there are several issues that keep the commodity GPU from expanding out from pure graphics computing with limited cache bandwidth being one. -

Skip-Webs: Efficient Distributed Data Structures for Multi-Dimensional Data Sets
Skip-Webs: Efficient Distributed Data Structures for Multi-Dimensional Data Sets Lars Arge David Eppstein Michael T. Goodrich Dept. of Computer Science Dept. of Computer Science Dept. of Computer Science University of Aarhus University of California University of California IT-Parken, Aabogade 34 Computer Science Bldg., 444 Computer Science Bldg., 444 DK-8200 Aarhus N, Denmark Irvine, CA 92697-3425, USA Irvine, CA 92697-3425, USA large(at)daimi.au.dk eppstein(at)ics.uci.edu goodrich(at)acm.org ABSTRACT name), a prefix match for a key string, a nearest-neighbor We present a framework for designing efficient distributed match for a numerical attribute, a range query over various data structures for multi-dimensional data. Our structures, numerical attributes, or a point-location query in a geomet- which we call skip-webs, extend and improve previous ran- ric map of attributes. That is, we would like the peer-to-peer domized distributed data structures, including skipnets and network to support a rich set of possible data types that al- skip graphs. Our framework applies to a general class of data low for multiple kinds of queries, including set membership, querying scenarios, which include linear (one-dimensional) 1-dim. nearest neighbor queries, range queries, string prefix data, such as sorted sets, as well as multi-dimensional data, queries, and point-location queries. such as d-dimensional octrees and digital tries of character The motivation for such queries include DNA databases, strings defined over a fixed alphabet. We show how to per- location-based services, and approximate searches for file form a query over such a set of n items spread among n names or data titles. -

Computer Graphics CMU 15-462/15-662 Scotty 3D Setup Recitation Today! Hunt Library Computer Lab 3:30-5Pm
Digital Geometry Processing Computer Graphics CMU 15-462/15-662 Scotty 3D setup recitation Today! Hunt Library Computer Lab 3:30-5pm CMU 15-462/662 Last time part 1: overview of geometry Many types of geometry in nature Geometry Demand sophisticated representations Two major categories: - IMPLICIT - “tests” if a point is in shape - EXPLICIT - directly “lists” points Lots of representations for both CMU 15-462/662 Last time part 2: Meshes & Manifolds Mathematical description of geometry - simplifying assumption: manifold - for polygon meshes: “fans, not fins” Data structures for surfaces - polygon soup - halfedge mesh - storage cost vs. access time, etc. Today: next how do we manipulate geometry? twin - face edge - geometry processing / resampling Halfedge vertex CMU 15-462/662 Today: Geometry Processing & Queries Extend traditional digital signal processing (audio, video, etc.) to deal with geometric signals: - upsampling / downsampling / resampling / filtering ... - aliasing (reconstructed surface gives “false impression”) Also ask some basic questions about geometry: - What’s the closest point? Do two triangles intersect? Etc. Beyond pure geometry, these are basic building blocks for many algorithms in graphics (rendering, animation...) CMU 15-462/662 Digital Geometry Processing: Motivation 3D Scanning 3D Printing CMU 15-462/662 Geometry Processing Pipeline scan print process CMU 15-462/662 Geometry Processing Tasks reconstruction filtering remeshing parameterization compression shape analysis CMU 15-462/662 Geometry Processing: Reconstruction -

Octree Generating Networks: Efficient Convolutional Architectures for High-Resolution 3D Outputs
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Maxim Tatarchenko1 Alexey Dosovitskiy1,2 Thomas Brox1 [email protected] [email protected] [email protected] 1University of Freiburg 2Intel Labs Abstract Octree Octree Octree dense level 1 level 2 level 3 We present a deep convolutional decoder architecture that can generate volumetric 3D outputs in a compute- and memory-efficient manner by using an octree representation. The network learns to predict both the structure of the oc- tree, and the occupancy values of individual cells. This makes it a particularly valuable technique for generating 323 643 1283 3D shapes. In contrast to standard decoders acting on reg- ular voxel grids, the architecture does not have cubic com- Figure 1. The proposed OGN represents its volumetric output as an octree. Initially estimated rough low-resolution structure is gradu- plexity. This allows representing much higher resolution ally refined to a desired high resolution. At each level only a sparse outputs with a limited memory budget. We demonstrate this set of spatial locations is predicted. This representation is signifi- in several application domains, including 3D convolutional cantly more efficient than a dense voxel grid and allows generating autoencoders, generation of objects and whole scenes from volumes as large as 5123 voxels on a modern GPU in a single for- high-level representations, and shape from a single image. ward pass. large cell of an octree, resulting in savings in computation 1. Introduction and memory compared to a fine regular grid. At the same 1 time, fine details are not lost and can still be represented by Up-convolutional decoder architectures have become small cells of the octree. -

Creating and Processing 3D Geometry
Creating and processing 3D geometry Marie-Paule Cani [email protected] Cédric Gérot [email protected] Franck Hétroy [email protected] http://evasion.imag.fr/Membres/Franck.Hetroy/Teaching/Geo3D/ Context: computer graphics ● We want to represent objects – Real objects – Virtual/created objects ● Several ways for virtual object creation – Interactive by graphists – Automatic from real data ● 3D scanner, medical angiography, ... – Procedural (on the fly) ● Complex scenes, terrain, ... ● Different uses – Display, animation, ph ysical simulation, ... Course overview 1.Objects representations – Volume/surface, implicit/explicit, ... Real-time triangulation of implicit surfaces Course overview 1.Objects representations – Volume/surface, implicit/explicit, ... 2.Geometry processing – Simplify, smooth, ... Interactive multiresolution surface exploration Course overview 1.Objects representations – Volume/surface, implicit/explicit, ... 2.Geometry processing – Simplify, smooth, ... 3.Virtual object creation – Surface reconstruction, interactive modeling Shape modeling by sketching Planning (provisional) Part I – Geometry representations ● Lecture 1 – Oct 9th – FH – Introduction to the lectures; point sets, meshes, discrete geometry. ● Lecture 2 – Oct 16th – MPC – Parametric curves and surfaces; subdivision surfaces. ● Lecture 3 – Oct 23rd - MPC – Implicit surfaces. Planning (provisional) Part II – Geometry processing ● Lecture 4 – Nov 6th – FH – Discrete differential geometry; mesh smoothing and simplification (paper presentations). -

Evaluation of Spatial Trees for Simulation of Biological Tissue
Evaluation of spatial trees for simulation of biological tissue Ilya Dmitrenok∗, Viktor Drobnyy∗, Leonard Johard and Manuel Mazzara Innopolis University Innopolis, Russia ∗ These authors contributed equally to this work. Abstract—Spatial organization is a core challenge for all large computation time. The amount of cells practically simulated on agent-based models with local interactions. In biological tissue a single computer generally stretches between a few thousands models, spatial search and reinsertion are frequently reported to a million, depending on detail level, hardware and simulated as the most expensive steps of the simulation. One of the main methods utilized in order to maintain both favourable algorithmic time range. complexity and accuracy is spatial hierarchies. In this paper, we In center-based models, movement and neighborhood de- seek to clarify to which extent the choice of spatial tree affects tection remains one of the main performance bottlenecks [2]. performance, and also to identify which spatial tree families are Performances in these bottlenecks are deeply intertwined with optimal for such scenarios. We make use of a prototype of the the spatial structure chosen for the simulation. new BioDynaMo tissue simulator for evaluating performances as well as for the implementation of the characteristics of several B. BioDynaMo different trees. The BioDynaMo project [3] is developing a new general I. INTRODUCTION platform for computer simulations of biological tissue dynam- The high pace of neuroscientific research has led to a ics, with a brain development as a primary target. The platform difficult problem in synthesizing the experimental results into should be executable on hybrid cloud computing systems, effective new hypotheses. -

The Peano Software—Parallel, Automaton-Based, Dynamically Adaptive Grid Traversals
The Peano software|parallel, automaton-based, dynamically adaptive grid traversals Tobias Weinzierl ∗ December 4, 2018 Abstract We discuss the design decisions, design alternatives and rationale behind the third generation of Peano, a framework for dynamically adaptive Cartesian meshes derived from spacetrees. Peano ties the mesh traversal to the mesh storage and supports only one element-wise traversal order resulting from space-filling curves. The user is not free to choose a traversal order herself. The traversal can exploit regular grid subregions and shared memory as well as distributed memory systems with almost no modifications to a serial application code. We formalize the software design by means of two interacting automata|one automaton for the multiscale grid traversal and one for the application- specific algorithmic steps. This yields a callback-based programming paradigm. We further sketch the supported application types and the two data storage schemes real- ized, before we detail high-performance computing aspects and lessons learned. Special emphasis is put on observations regarding the used programming idioms and algorith- mic concepts. This transforms our report from a \one way to implement things" code description into a generic discussion and summary of some alternatives, rationale and design decisions to be made for any tree-based adaptive mesh refinement software. 1 Introduction Dynamically adaptive grids are mortar and catalyst of mesh-based scientific computing and thus important to a large range of scientific and engineering applications. They enable sci- entists and engineers to solve problems with high accuracy as they invest grid entities and computational effort where they pay off most. -

The Skip Quadtree: a Simple Dynamic Data Structure for Multidimensional Data
The Skip Quadtree: A Simple Dynamic Data Structure for Multidimensional Data David Eppstein† Michael T. Goodrich† Jonathan Z. Sun† Abstract We present a new multi-dimensional data structure, which we call the skip quadtree (for point data in R2) or the skip octree (for point data in Rd , with constant d > 2). Our data structure combines the best features of two well-known data structures, in that it has the well-defined “box”-shaped regions of region quadtrees and the logarithmic-height search and update hierarchical structure of skip lists. Indeed, the bottom level of our structure is exactly a region quadtree (or octree for higher dimensional data). We describe efficient algorithms for inserting and deleting points in a skip quadtree, as well as fast methods for performing point location and approximate range queries. 1 Introduction Data structures for multidimensional point data are of significant interest in the computational geometry, computer graphics, and scientific data visualization literatures. They allow point data to be stored and searched efficiently, for example to perform range queries to report (possibly approximately) the points that are contained in a given query region. We are interested in this paper in data structures for multidimensional point sets that are dynamic, in that they allow for fast point insertion and deletion, as well as efficient, in that they use linear space and allow for fast query times. Related Previous Work. Linear-space multidimensional data structures typically are defined by hierar- chical subdivisions of space, which give rise to tree-based search structures. That is, a hierarchy is defined by associating with each node v in a tree T a region R(v) in Rd such that the children of v are associated with subregions of R(v) defined by some kind of “cutting” action on R(v).