A Survey of RDF Stores & SPARQL Engines for Querying Knowledge
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Including Co-Referent Uris in a SPARQL Query
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Heriot Watt Pure Including Co-referent URIs in a SPARQL Query Christian Y A Brenninkmeijer1, Carole Goble1, Alasdair J G Gray1, Paul Groth2, Antonis Loizou2, and Steve Pettifer1 1 School of Computer Science, University of Manchester, UK. 2 Department of Computer Science, VU University of Amsterdam, The Netherlands. Abstract. Linked data relies on instance level links between potentially differing representations of concepts in multiple datasets. However, in large complex domains, such as pharmacology, the inter-relationship of data instances needs to consider the context (e.g. task, role) of the user and the assumptions they want to apply to the data. Such context is not taken into account in most linked data integration procedures. In this paper we argue that dataset links should be stored in a stand-off fashion, thus enabling different assumptions to be applied to the data links during query execution. We present the infrastructure developed for the Open PHACTS Discovery Platform to enable this and show through evaluation that the incurred performance cost is below the threshold of user perception. 1 Introduction A key mechanism of linked data is the use of equality links between resources across different datasets. However, the semantics of such links are often not triv- ial: as Halpin et al. have shown sameAs, is not always sameAs [12]; and equality is often context- and even task-specific, especially in complex domains. For ex- ample, consider the drug \Gleevec". A search over different chemical databases return records about two different chemical compounds { \Imatinib" and \Ima- tinib Mesylate" { which differ in chemical weight and other characteristics. -

Querying Wikidata: Comparing SPARQL, Relational and Graph Databases
Querying Wikidata: Comparing SPARQL, Relational and Graph Databases Daniel Hernández1, Aidan Hogan1, Cristian Riveros2, Carlos Rojas2, and Enzo Zerega2 Center for Semantic Web Research 1 Department of Computer Science, Universidad de Chile 2 Department of Computer Science, Pontificia Universidad Católica de Chile Resource type: Benchmark and Empirical Study Permanent URL: https://dx.doi.org/10.6084/m9.figshare.3219217 Abstract: In this paper, we experimentally compare the efficiency of various database engines for the purposes of querying the Wikidata knowledge-base, which can be conceptualised as a directed edge-labelled graph where edges can be annotated with meta-information called quali- fiers. We take two popular SPARQL databases (Virtuoso, Blazegraph), a popular relational database (PostgreSQL), and a popular graph database (Neo4J) for comparison and discuss various options as to how Wikidata can be represented in the models of each engine. We design a set of experiments to test the relative query performance of these representa- tions in the context of their respective engines. We first execute a large set of atomic lookups to establish a baseline performance for each test setting, and subsequently perform experiments on instances of more com- plex graph patterns based on real-world examples. We conclude with a summary of the strengths and limitations of the engines observed. 1 Introduction Wikidata is a new knowledge-base overseen by the Wikimedia foundation and collaboratively edited by a community of thousands of users [21]. The goal of Wikidata is to provide a common interoperable source of factual information for Wikimedia projects, foremost of which is Wikipedia. Currently on Wikipedia, articles that list entities – such as top scoring football players – and the info- boxes that appear on the top-right-hand side of articles – such as to state the number of goals scored by a football player – must be manually maintained. -

Mapping Spatiotemporal Data to RDF: a SPARQL Endpoint for Brussels
International Journal of Geo-Information Article Mapping Spatiotemporal Data to RDF: A SPARQL Endpoint for Brussels Alejandro Vaisman 1, * and Kevin Chentout 2 1 Instituto Tecnológico de Buenos Aires, Buenos Aires 1424, Argentina 2 Sopra Banking Software, Avenue de Tevuren 226, B-1150 Brussels, Belgium * Correspondence: [email protected]; Tel.: +54-11-3457-4864 Received: 20 June 2019; Accepted: 7 August 2019; Published: 10 August 2019 Abstract: This paper describes how a platform for publishing and querying linked open data for the Brussels Capital region in Belgium is built. Data are provided as relational tables or XML documents and are mapped into the RDF data model using R2RML, a standard language that allows defining customized mappings from relational databases to RDF datasets. In this work, data are spatiotemporal in nature; therefore, R2RML must be adapted to allow producing spatiotemporal Linked Open Data.Data generated in this way are used to populate a SPARQL endpoint, where queries are submitted and the result can be displayed on a map. This endpoint is implemented using Strabon, a spatiotemporal RDF triple store built by extending the RDF store Sesame. The first part of the paper describes how R2RML is adapted to allow producing spatial RDF data and to support XML data sources. These techniques are then used to map data about cultural events and public transport in Brussels into RDF. Spatial data are stored in the form of stRDF triples, the format required by Strabon. In addition, the endpoint is enriched with external data obtained from the Linked Open Data Cloud, from sites like DBpedia, Geonames, and LinkedGeoData, to provide context for analysis. -

Versioning Linked Datasets
Master’s Thesis Versioning Linked Datasets Towards Preserving History on the Semantic Web Author Paul Meinhardt 744393 July 13, 2015 Supervisors Magnus Knuth and Dr. Harald Sack Semantic Technologies Research Group Internet Technologies and Systems Chair Abstract Linked data provides methods for publishing and connecting structured data on the web using standard protocols and formats, namely HTTP, URIs, and RDF. Much like on the web of documents, linked data resources continuously evolve over time, but for the most part only their most recent state is accessible. In or- der to investigate the evolution of linked datasets and understand the impact of changes on the web of data it is necessary to make prior versions of such re- sources available. The lack of a common “self-service” versioning platform in the linked data community makes it more difficult for dataset maintainers to preserve past states of their data themselves. By implementing such a platform which also provides a consistent interface to historic information, dataset main- tainers can more easily start versioning their datasets while application develop- ers and researchers instantly have the possibility of working with the additional temporal data without laboriously collecting it on their own. This thesis, researches the possibility of creating a linked data versioning plat- form. It describes a basic model view for linked datasets, their evolution and presents a service approach to preserving the history of arbitrary linked datasets over time. Zusammenfassung Linked Data beschreibt Methoden für die Veröffentlichung und Verknüpfung strukturierter Daten im Web mithilfe standardisierter Protokolle und Formate, nämlich HTTP, URIs und RDF. Ähnlich wie andere Dokumente im World Wide Web, verändern sich auch Linked-Data-Resourcen stetig mit der Zeit. -

Multiple-Aspect Analysis of Semantic Trajectories
Konstantinos Tserpes Chiara Renso Stan Matwin (Eds.) Multiple-Aspect Analysis LNAI 11889 of Semantic Trajectories First International Workshop, MASTER 2019 Held in Conjunction with ECML-PKDD 2019 Würzburg, Germany, September 16, 2019 Proceedings Lecture Notes in Artificial Intelligence 11889 Subseries of Lecture Notes in Computer Science Series Editors Randy Goebel University of Alberta, Edmonton, Canada Yuzuru Tanaka Hokkaido University, Sapporo, Japan Wolfgang Wahlster DFKI and Saarland University, Saarbrücken, Germany Founding Editor Jörg Siekmann DFKI and Saarland University, Saarbrücken, Germany More information about this series at http://www.springer.com/series/1244 Konstantinos Tserpes • Chiara Renso • Stan Matwin (Eds.) Multiple-Aspect Analysis of Semantic Trajectories First International Workshop, MASTER 2019 Held in Conjunction with ECML-PKDD 2019 Würzburg, Germany, September 16, 2019 Proceedings Editors Konstantinos Tserpes Chiara Renso Harokopio University ISTI-CNR Athens, Greece Pisa, Italy Stan Matwin Dalhousie University Halifax, NS, Canada ISSN 0302-9743 ISSN 1611-3349 (electronic) Lecture Notes in Artificial Intelligence ISBN 978-3-030-38080-9 ISBN 978-3-030-38081-6 (eBook) https://doi.org/10.1007/978-3-030-38081-6 LNCS Sublibrary: SL7 – Artificial Intelligence © The Editor(s) (if applicable) and The Author(s) 2020. This book is an open access publication. Open Access This book is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made. -

Semantics Developer's Guide
MarkLogic Server Semantic Graph Developer’s Guide 2 MarkLogic 10 May, 2019 Last Revised: 10.0-8, October, 2021 Copyright © 2021 MarkLogic Corporation. All rights reserved. MarkLogic Server MarkLogic 10—May, 2019 Semantic Graph Developer’s Guide—Page 2 MarkLogic Server Table of Contents Table of Contents Semantic Graph Developer’s Guide 1.0 Introduction to Semantic Graphs in MarkLogic ..........................................11 1.1 Terminology ..........................................................................................................12 1.2 Linked Open Data .................................................................................................13 1.3 RDF Implementation in MarkLogic .....................................................................14 1.3.1 Using RDF in MarkLogic .........................................................................15 1.3.1.1 Storing RDF Triples in MarkLogic ...........................................17 1.3.1.2 Querying Triples .......................................................................18 1.3.2 RDF Data Model .......................................................................................20 1.3.3 Blank Node Identifiers ..............................................................................21 1.3.4 RDF Datatypes ..........................................................................................21 1.3.5 IRIs and Prefixes .......................................................................................22 1.3.5.1 IRIs ............................................................................................22 -

Open Web Ontobud: an Open Source RDF4J Frontend
Open Web Ontobud: An Open Source RDF4J Frontend Francisco José Moreira Oliveira University of Minho, Braga, Portugal [email protected] José Carlos Ramalho Department of Informatics, University of Minho, Braga, Portugal [email protected] Abstract Nowadays, we deal with increasing volumes of data. A few years ago, data was isolated, which did not allow communication or sharing between datasets. We live in a world where everything is connected, and our data mimics this. Data model focus changed from a square structure like the relational model to a model centered on the relations. Knowledge graphs are the new paradigm to represent and manage this new kind of information structure. Along with this new paradigm, a new kind of database emerged to support the new needs, graph databases! Although there is an increasing interest in this field, only a few native solutions are available. Most of these are commercial, and the ones that are open source have poor interfaces, and for that, they are a little distant from end-users. In this article, we introduce Ontobud, and discuss its design and development. A Web application that intends to improve the interface for one of the most interesting frameworks in this area: RDF4J. RDF4J is a Java framework to deal with RDF triples storage and management. Open Web Ontobud is an open source RDF4J web frontend, created to reduce the gap between end users and the RDF4J backend. We have created a web interface that enables users with a basic knowledge of OWL and SPARQL to explore ontologies and extract information from them. -

A Performance Study of RDF Stores for Linked Sensor Data
Semantic Web 1 (0) 1–5 1 IOS Press 1 1 2 2 3 3 4 A Performance Study of RDF Stores for 4 5 5 6 Linked Sensor Data 6 7 7 8 Hoan Nguyen Mau Quoc a,*, Martin Serrano b, Han Nguyen Mau c, John G. Breslin d , Danh Le Phuoc e 8 9 a Insight Centre for Data Analytics, National University of Ireland Galway, Ireland 9 10 E-mail: [email protected] 10 11 b Insight Centre for Data Analytics, National University of Ireland Galway, Ireland 11 12 E-mail: [email protected] 12 13 c Information Technology Department, Hue University, Viet Nam 13 14 E-mail: [email protected] 14 15 d Confirm Centre for Smart Manufacturing and Insight Centre for Data Analytics, National University of Ireland 15 16 Galway, Ireland 16 17 E-mail: [email protected] 17 18 e Open Distributed Systems, Technical University of Berlin, Germany 18 19 E-mail: [email protected] 19 20 20 21 21 Editors: First Editor, University or Company name, Country; Second Editor, University or Company name, Country 22 Solicited reviews: First Solicited Reviewer, University or Company name, Country; Second Solicited Reviewer, University or Company name, 22 23 Country 23 24 Open reviews: First Open Reviewer, University or Company name, Country; Second Open Reviewer, University or Company name, Country 24 25 25 26 26 27 27 28 28 29 Abstract. The ever-increasing amount of Internet of Things (IoT) data emanating from sensor and mobile devices is creating 29 30 new capabilities and unprecedented economic opportunity for individuals, organisations and states. -

Storage, Indexing, Query Processing, And
Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 23 May 2020 doi:10.20944/preprints202005.0360.v1 STORAGE,INDEXING,QUERY PROCESSING, AND BENCHMARKING IN CENTRALIZED AND DISTRIBUTED RDF ENGINES:ASURVEY Waqas Ali Department of Computer Science and Engineering, School of Electronic, Information and Electrical Engineering (SEIEE), Shanghai Jiao Tong University, Shanghai, China [email protected] Muhammad Saleem Agile Knowledge and Semantic Web (AKWS), University of Leipzig, Leipzig, Germany [email protected] Bin Yao Department of Computer Science and Engineering, School of Electronic, Information and Electrical Engineering (SEIEE), Shanghai Jiao Tong University, Shanghai, China [email protected] Axel-Cyrille Ngonga Ngomo University of Paderborn, Paderborn, Germany [email protected] ABSTRACT The recent advancements of the Semantic Web and Linked Data have changed the working of the traditional web. There is a huge adoption of the Resource Description Framework (RDF) format for saving of web-based data. This massive adoption has paved the way for the development of various centralized and distributed RDF processing engines. These engines employ different mechanisms to implement key components of the query processing engines such as data storage, indexing, language support, and query execution. All these components govern how queries are executed and can have a substantial effect on the query runtime. For example, the storage of RDF data in various ways significantly affects the data storage space required and the query runtime performance. The type of indexing approach used in RDF engines is key for fast data lookup. The type of the underlying querying language (e.g., SPARQL or SQL) used for query execution is a key optimization component of the RDF storage solutions. -
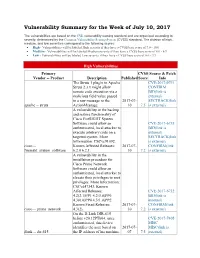
Vulnerability Summary for the Week of July 10, 2017
Vulnerability Summary for the Week of July 10, 2017 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 High Vulnerabilities Primary CVSS Source & Patch Vendor -- Product Description Published Score Info The Struts 1 plugin in Apache CVE-2017-9791 Struts 2.3.x might allow CONFIRM remote code execution via a BID(link is malicious field value passed external) in a raw message to the 2017-07- SECTRACK(link apache -- struts ActionMessage. 10 7.5 is external) A vulnerability in the backup and restore functionality of Cisco FireSIGHT System Software could allow an CVE-2017-6735 authenticated, local attacker to BID(link is execute arbitrary code on a external) targeted system. More SECTRACK(link Information: CSCvc91092. is external) cisco -- Known Affected Releases: 2017-07- CONFIRM(link firesight_system_software 6.2.0 6.2.1. 10 7.2 is external) A vulnerability in the installation procedure for Cisco Prime Network Software could allow an authenticated, local attacker to elevate their privileges to root privileges. More Information: CSCvd47343. Known Affected Releases: CVE-2017-6732 4.2(2.1)PP1 4.2(3.0)PP6 BID(link is 4.3(0.0)PP4 4.3(1.0)PP2. -

Chainsys-Platform-Technical Architecture-Bots
Technical Architecture Objectives ChainSys’ Smart Data Platform enables the business to achieve these critical needs. 1. Empower the organization to be data-driven 2. All your data management problems solved 3. World class innovation at an accessible price Subash Chandar Elango Chief Product Officer ChainSys Corporation Subash's expertise in the data management sphere is unparalleled. As the creative & technical brain behind ChainSys' products, no problem is too big for Subash, and he has been part of hundreds of data projects worldwide. Introduction This document describes the Technical Architecture of the Chainsys Platform Purpose The purpose of this Technical Architecture is to define the technologies, products, and techniques necessary to develop and support the system and to ensure that the system components are compatible and comply with the enterprise-wide standards and direction defined by the Agency. Scope The document's scope is to identify and explain the advantages and risks inherent in this Technical Architecture. This document is not intended to address the installation and configuration details of the actual implementation. Installation and configuration details are provided in technology guides produced during the project. Audience The intended audience for this document is Project Stakeholders, technical architects, and deployment architects The system's overall architecture goals are to provide a highly available, scalable, & flexible data management platform Architecture Goals A key Architectural goal is to leverage industry best practices to design and develop a scalable, enterprise-wide J2EE application and follow the industry-standard development guidelines. All aspects of Security must be developed and built within the application and be based on Best Practices. -

Graph Databases – Are They Really So New
International Journal of Advances in Science Engineering and Technology, ISSN: 2321-9009 Volume- 4, Issue-4, Oct.-2016 GRAPH DATABASES – ARE THEY REALLY SO NEW 1MIRKO MALEKOVIC, 2KORNELIJE RABUZIN, 3MARTINA SESTAK 1,2,3Faculty of Organization and Informatics Varaždin, University of Zagreb, Croatia E-mail: [email protected], [email protected], [email protected] Abstract- Even though relational databases have been (and still are) the most widely used database solutions for many years, there were other database solutions in use before the era of relational databases. One of those solutions were network databases with the underlying network model, whose characteristics will be presented in detail in this paper. The network model will be compared to the graph data model used by graph databases, the relatively new category of NoSQL databases with a growing share in the database market. The similarities and differences will be shown through the implementation of a simple database using network and graph data model. Keywords- Network data model, graph data model, nodes, relationships, records, sets. I. INTRODUCTION ● Hierarchical databases This type of databases is based on the hierarchical The relational databases were introduced by E. G. data model, whose structure can be represented as a Codd in his research papers in 1970s. In those papers layered tree in which one data table represents the he discussed relational model as the underlying data root of that tree (top layer), and the others represent model for the relational databases, which was based tree branches (nodes) emerging from the root of the on relational algebra and first-order predicate logic.